

pandas 级联 追加 合并 pd.concat| pd.append| pd.merge
numpy.concatenate((a1,a2,...),axis=0) 数组的拼接,一维数组 与axis值无关,都往横向拼接。多维数组 与axis有关,0是纵向,1是横向
pandas.concat((a,b,c...),axis=0,join='outter',sort=True, ignore_index=True)
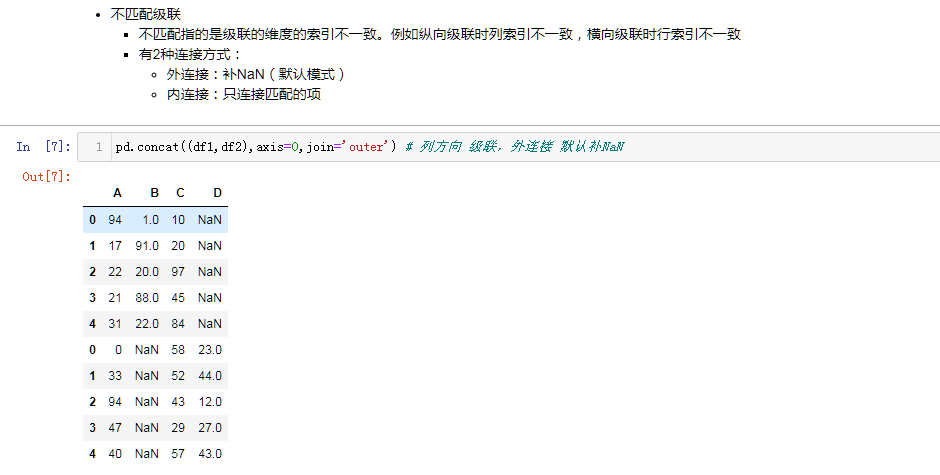
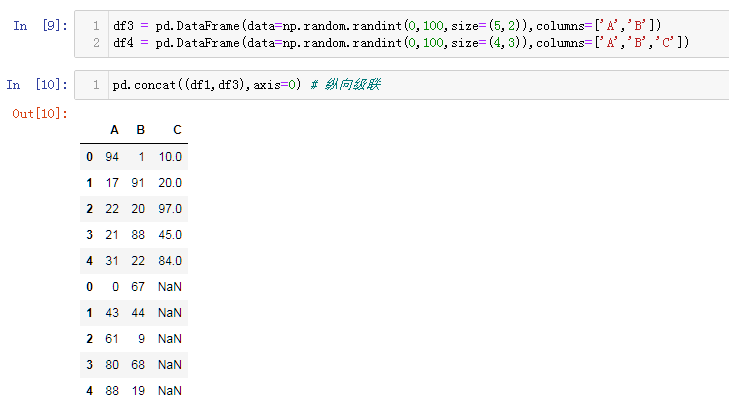
表格行列索引都一致叫做匹配级联
表格维度不一致,叫做不匹配级联。包括行方向布置,列方向不一致。这个时候有两种连接方式,inner (只连接匹配的项)和 outter(默认模式,不一致的补NaN)
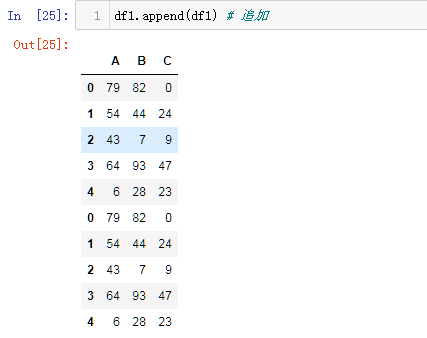
df1.append(df1) 追加,在表格后面追加行
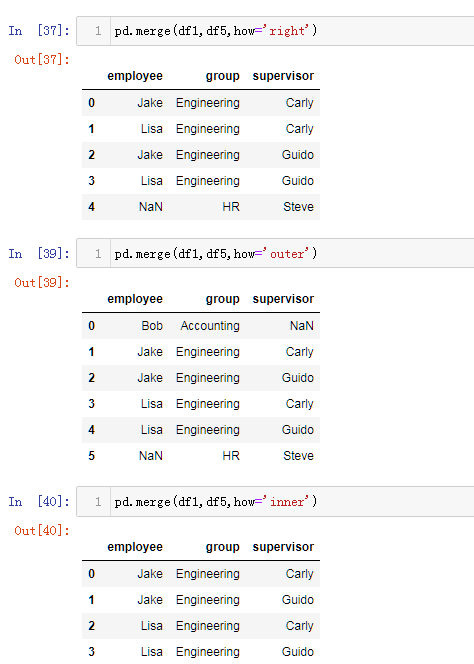
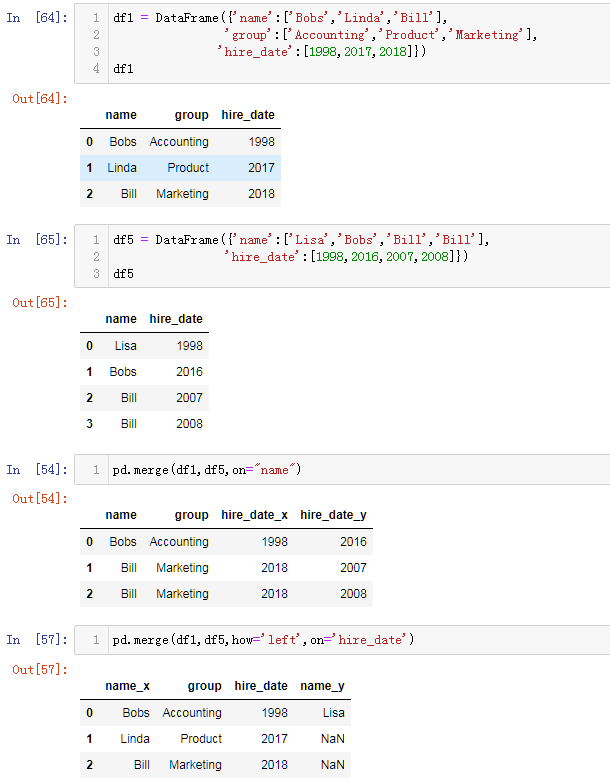
pd.merge(df1,df2,on='name') 合并,根据‘name’列 合并两张表格, 分为一对一,一对多,多对多的合并
当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列
pd.merge(df1,df5,how='outer',left_on='employee',right_on='name')

numpy提供了numpy.concatenate((a1,a2,...), axis=0)函数。能够一次完成多个数组的拼接。其中a1,a2,...是数组类型的参数
>>> a=np.array([1,2,3])
>>> b=np.array([11,22,33])
>>> c=np.array([44,55,66])
>>> np.concatenate((a,b,c),axis=0) # 默认情况下,axis=0可以不写
array([ 1, 2, 3, 11, 22, 33, 44, 55, 66]) #对于一维数组拼接,axis的值不影响最后的结果
>>> a=np.array([[1,2,3],[4,5,6]])
>>> b=np.array([[11,21,31],[7,8,9]])
>>> np.concatenate((a,b),axis=0)
array([[ 1, 2, 3],
[ 4, 5, 6],
[11, 21, 31],
[ 7, 8, 9]])
>>> np.concatenate((a,b),axis=1) #axis=1表示对应行的数组进行拼接
array([[ 1, 2, 3, 11, 21, 31],
[ 4, 5, 6, 7, 8, 9]])
pandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
objs
axis=0
keys
join='outer' / 'inner':表示的是级联的方式,outer会将所有的项进行级联(忽略匹配和不匹配),而inner只会将匹配的项级联到一起,不匹配的不级联
ignore_index=False


append函数的使用
合并操作
-
merge与concat的区别在于,merge需要依据某一共同列来进行合并
-
使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
-
注意每一列元素的顺序不要求一致
一对一合并


一对多合并

多对多合并
key的规范化
当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列

内合并与外合并:out取并集 inner取交集


