mysql
mysql : https://www.processon.com/mindmap/5f744e1ce0b34d0711f04da3
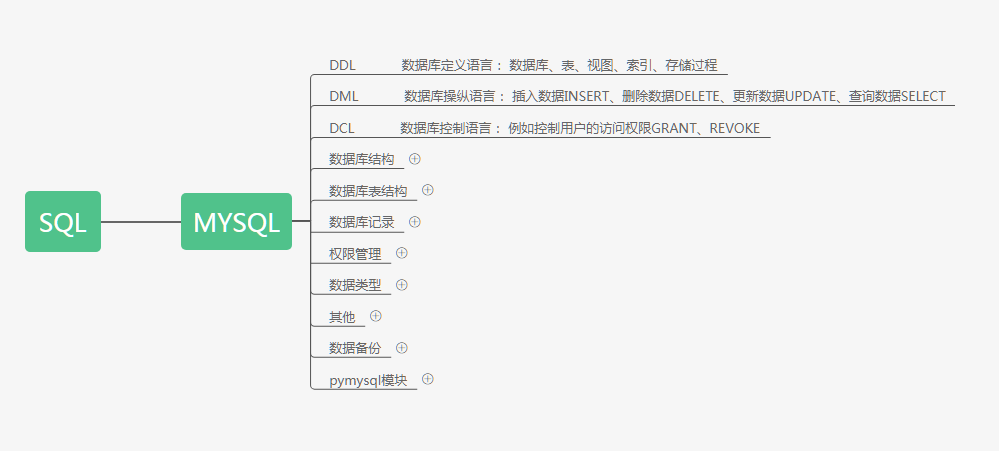
#### 数据库管理软件分类 关系型:如sqllite,db2,oracle,access,sql server,MySQL,注意:sql语句通用 非关系型:mongodb,redis,memcache 可以简单的理解为:关系型数据库需要有表结构,非关系型数据库是key-value存储的,没有表结构


存储引擎
InnoDB (安全)
是MySQL5.5版本及之后默认的存储引擎,存储数据更加的安全。
InnoDB 支持事务,事务:用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。
InnoDB 支持外键和行级锁,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包括很多更新和删除操作,那么InnoDB存储引擎是比较合适的。
创建表会生成两个文件
表结构文件
表数据文件
MyISAM (访问速度快)
是MySQL5.5版本之前默认的存储引擎
MyISAM既不支持事务、也不支持外键、其优势是访问速度快,但是表级别的锁定限制了它在读写负载方面的性能,因此它经常应用于只读或者以读为主的数据场景。
创建表会生成三个文件
表结构文件
表数据文件
表索引文件
Memory
在内存中存储所有数据,应用于对非关键数据由快速查找的场景。Memory类型的表访问数据非常快,因为它的数据是存放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失
临时数据存储
创建表会生成一个文件
表结构文件
BLACKHOLE
黑洞存储引擎,可以应用于主备复制中的分发主库。
创建表会生成一个文件
表结构文件
查询当前数据库支持的存储引擎
mysql> show engines \G;
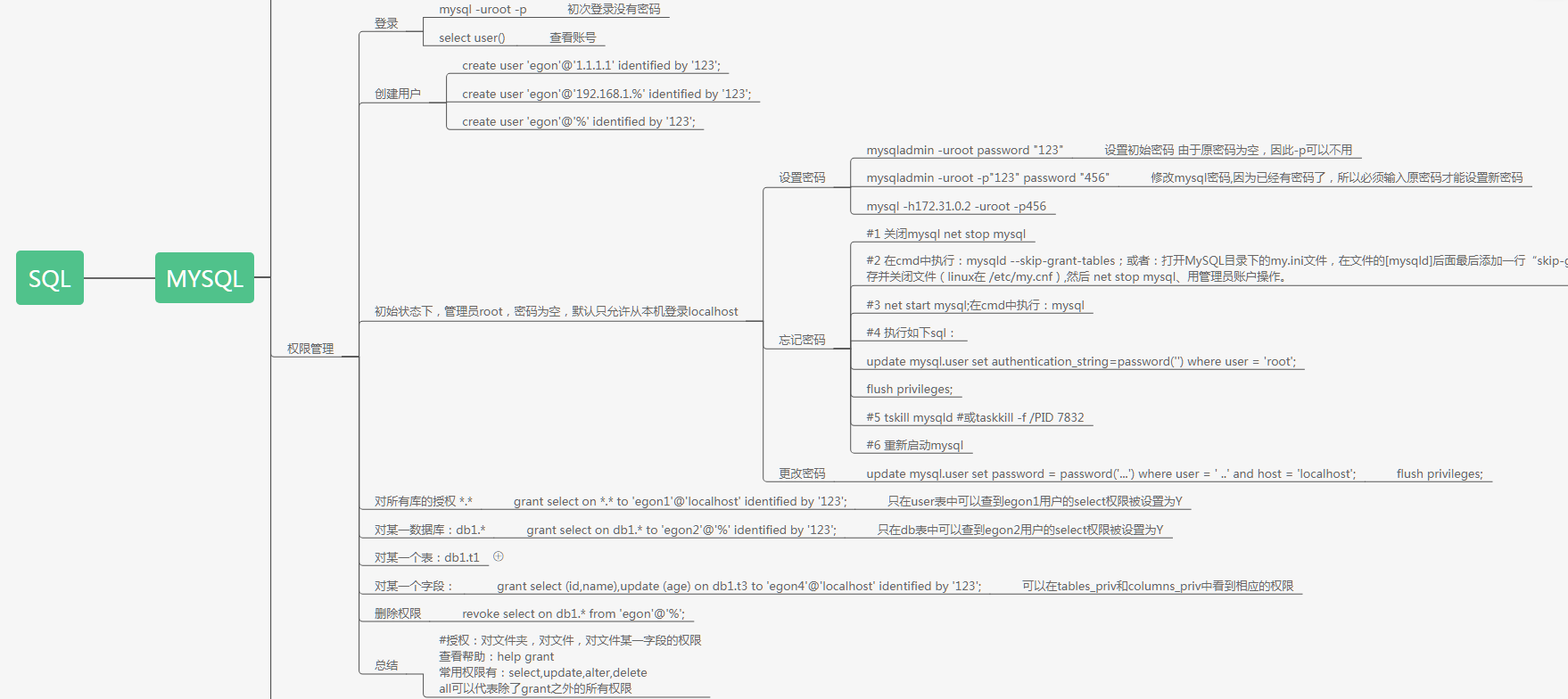
#### 操作库 增:create database db1 charset utf8; 删:drop database db1; 改:alter database db1 charset utf8; 查:show databases; show create database db1; select database(); 操作表的话,把database该成table
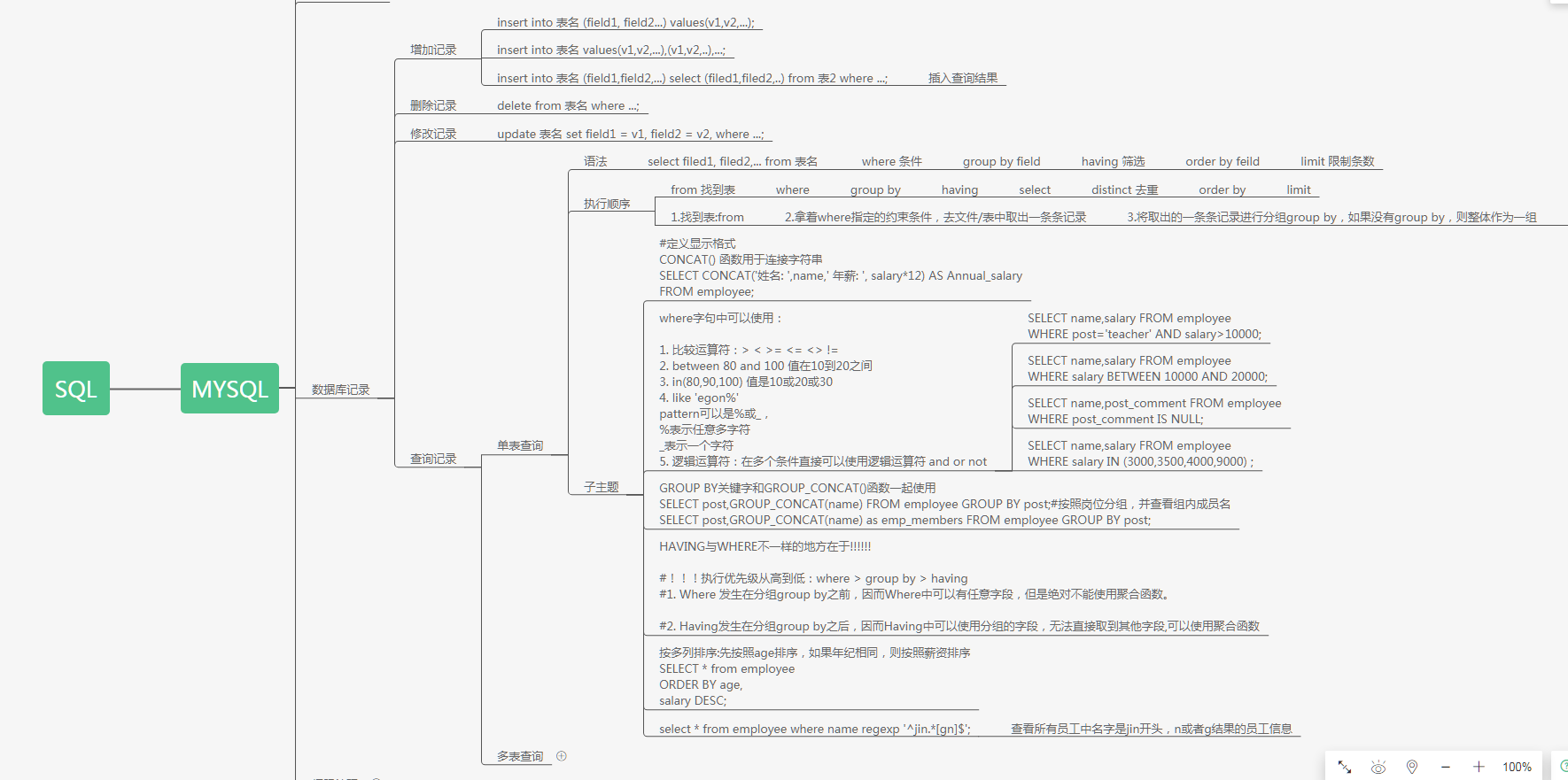
#### 操作文件中的内容/记录 增:insert into t1 values(1,'egon1'),(2,'egon2'),(3,'egon3'); insert into t2(id,name) values(1,'jason'); 查:select * from t1; # 当表字段特别多 展示的时候错乱 可以使用\G分行展示 select * from emp\G; 个别同学的电脑在插入中文的时候还是会出现乱码或者空白的现象 你可以将字符编码统一设置成GBK 改:update t1 set name='sb' where id=2; 删:delete from t1 where id=1;
#### 关键字的执行优先级 from where group by having select distinct order by limit 1.找到表:from 2.拿着where指定的约束条件,去文件/表中取出一条条记录 3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组 4.将分组的结果进行having过滤 5.执行select 6.去重 7.将结果按条件排序:order by 8.限制结果的显示条数
#### WHERE约束 1.比较运算符:> <> = <= <> != 2.between 80 and 100 值在10到20之间 3.in(80,90,100) 值是10或20或30 4.like 'egon%' 5.pattern可以是%或_, 6.%表示任意多字符 7._表示一个字符 8.逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not # 9.针对null不用等号 用is select name,post from emp where post_comment = NULL; select name,post from emp where post_comment is NULL; #### having与where的区别 1.执行优先级从高到低:where > group by > having 2.Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。 3.Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数
#### mysql 内置功能 视图:视图是一个虚拟表(非真实存在),其本质是【根据SQL语句获取动态的数据集,并为其命名】, 用户使用时只需使用【名称】即可获取结果集,可以将该结果集当做表来使用。 触发器:使用触发器可以定制用户对表进行【增、删、改】操作时前后的行为,注意:没有查询 事务:用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。 存储过程:存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql 优点:1.用于替代程序写的SQL语句,实现程序与sql解耦 2.基于网络传输,传别名的数据量小,而直接传sql数据量大 缺点: 程序员扩展功能不方便
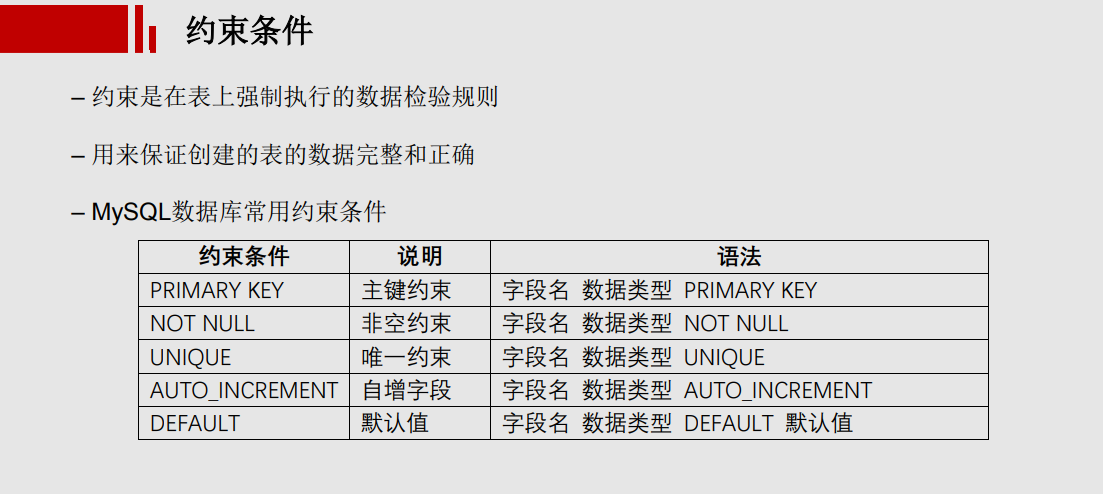
#### 表完整性约束 unsigned:设置某一个数字无符号 age int unsigned NOT NULL default 20, zerofill:使用0填充 default:给字段设置默认值 not null:字段不允许为空,必须赋值,或者也可以自动添加默认值 not null defalut 2 auto_increment: 标识该字段的值自动增长(整数类型,而且为主键,默认就有not null 的功能) primary key auto_increment一般一起使用 设置条件 int unique 外键: foreign key 是否是key: 主键: primary key 约束作用:非空 + 唯一 (not null+unique) 一张表只能设置一个主键,一张表最好设置一个主键, 你指定的第一个非空且唯一的字段会被定义成主键 #联合主键 primary key(teacher_id,grade_id) ,两个字段不能为空,并且两个字段联合唯一 索引:(index,) 没有约束作用 #联合索引 唯一:unique key (uk) 约束作用:唯一 #联合唯一
#### 聚合函数(常用于GROUP BY从句的SELECT查询中) AVG(col)返回指定列的平均值 COUNT(col)返回指定列中非NULL值的个数 MIN(col)返回指定列的最小值 MAX(col)返回指定列的最大值 SUM(col)返回指定列的所有值之和 #### 程序与数据库结合使用的三种方式 方式1:程序:调用存储过程 方式2:程序:纯SQL语句 方式3:程序:类和对象,即ORM(本质还是纯SQL语句)
#### 正确使用索引(索引是否命中) 并不是说我们创建了索引就一定会加快查询速度,若想利用索引达到预想的提高查询速度的效果,我们在添加索引时,必须遵循以下问题 1.范围问题,或者说条件不明确,条件中出现这些符号或关键字:>、>=、<、<=、!= 、between...and...、like、 2.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录 3.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式 4.索引列不能参与计算,保持列“干净”,id*200 比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’) 5.最左前缀匹配原则 其他注意事项: - 避免使用select * - count(1)或count(列) 代替 count(*) - 创建表时尽量时 char 代替 varchar - 表的字段顺序固定长度的字段优先 - 组合索引代替多个单列索引(经常使用多个条件查询时) - 尽量使用短索引 短索引说的是 某个字段内容特别多,但是比如前面20个文字就可以做一个区分了,那么就用前面20个字符进行索引,这样可以节约索引空间。 知道有这些概念,用的不那么多,因为很少会给内容特别长的字段加索引。 索引一般加在区分度特别大的地方,比如id 身份证,昵称,用户名 这些字段,这些字段本身内容也不会特别多。 - 使用连接(JOIN)来代替子查询(Sub-Queries) - 连表时注意条件类型需一致 - 索引散列值(重复少)不适合建索引,例:性别不适合
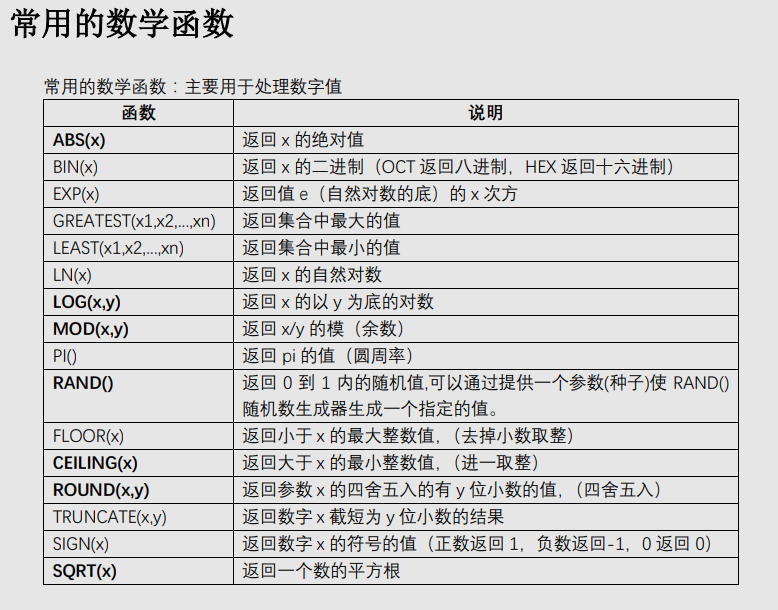
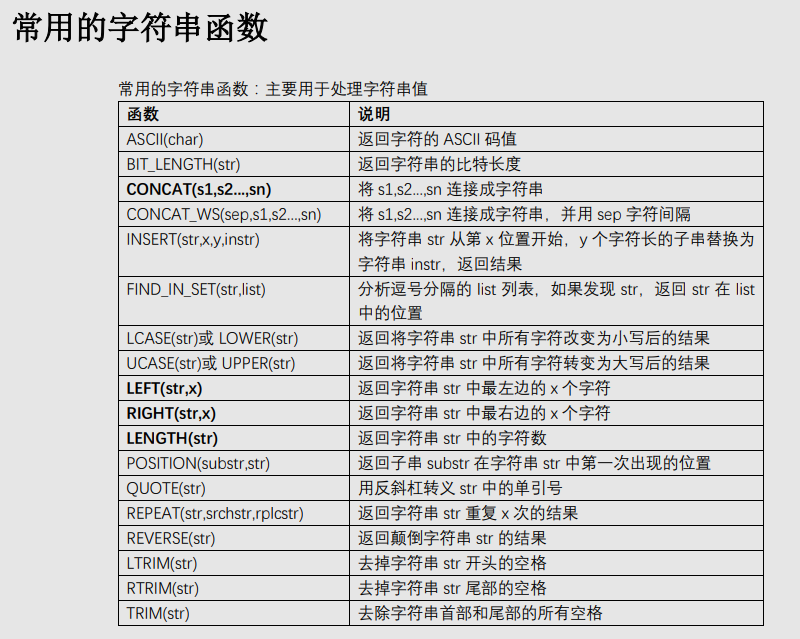
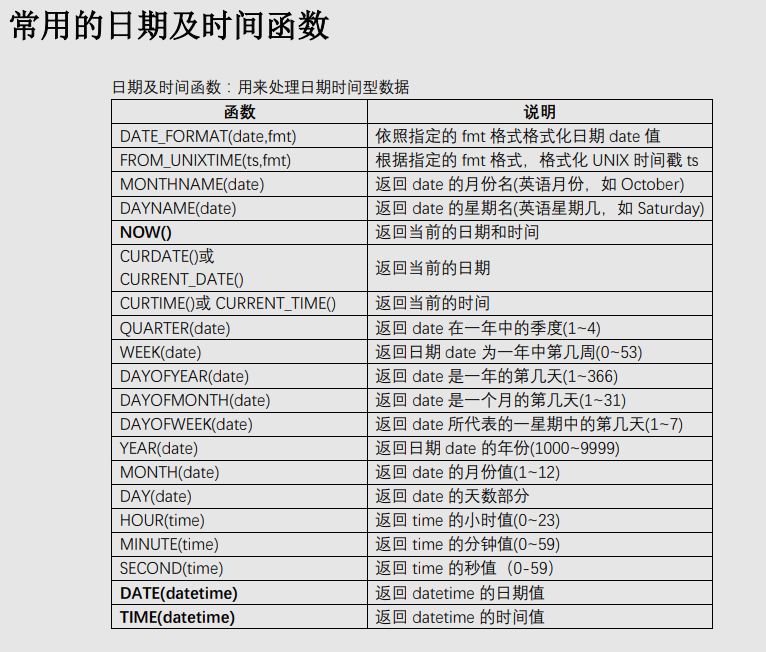
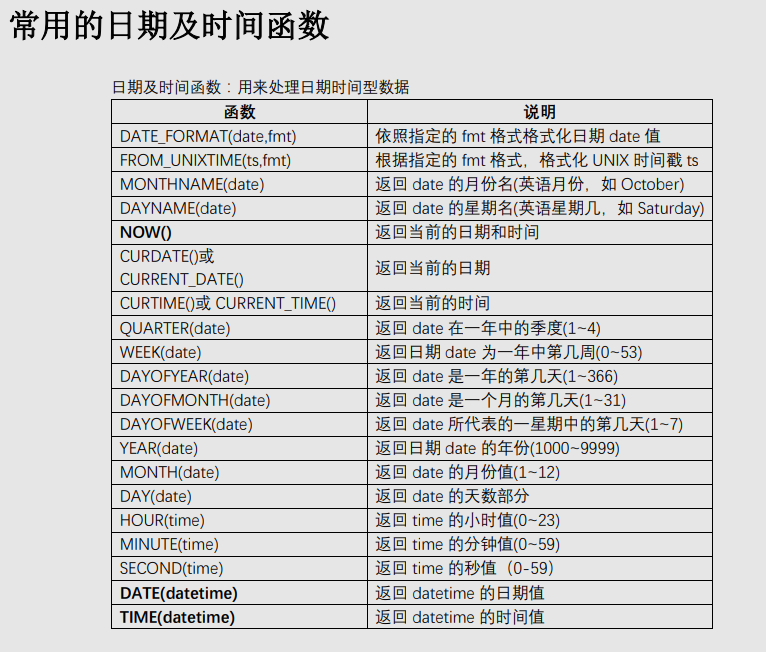
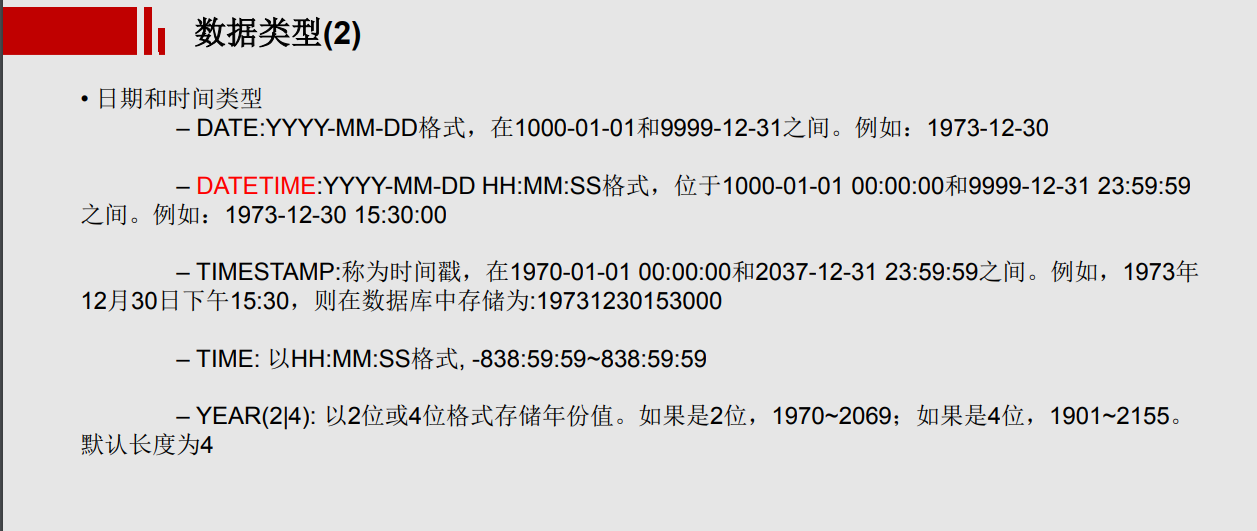
一、数学函数 ABS(x) 返回x的绝对值 BIN(x) 返回x的二进制(OCT返回八进制,HEX返回十六进制) CEILING(x) 返回大于x的最小整数值 EXP(x) 返回值e(自然对数的底)的x次方 FLOOR(x) 返回小于x的最大整数值 GREATEST(x1,x2,...,xn)返回集合中最大的值 LEAST(x1,x2,...,xn) 返回集合中最小的值 LN(x) 返回x的自然对数 LOG(x,y)返回x的以y为底的对数 MOD(x,y) 返回x/y的模(余数) PI()返回pi的值(圆周率) RAND()返回0到1内的随机值,可以通过提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。 ROUND(x,y)返回参数x的四舍五入的有y位小数的值 SIGN(x) 返回代表数字x的符号的值 SQRT(x) 返回一个数的平方根 TRUNCATE(x,y) 返回数字x截短为y位小数的结果 二、聚合函数(常用于GROUP BY从句的SELECT查询中) AVG(col)返回指定列的平均值 COUNT(col)返回指定列中非NULL值的个数 MIN(col)返回指定列的最小值 MAX(col)返回指定列的最大值 SUM(col)返回指定列的所有值之和 GROUP_CONCAT(col) 返回由属于一组的列值连接组合而成的结果 三、字符串函数 ASCII(char)返回字符的ASCII码值 BIT_LENGTH(str)返回字符串的比特长度 CONCAT(s1,s2...,sn)将s1,s2...,sn连接成字符串 CONCAT_WS(sep,s1,s2...,sn)将s1,s2...,sn连接成字符串,并用sep字符间隔 INSERT(str,x,y,instr) 将字符串str从第x位置开始,y个字符长的子串替换为字符串instr,返回结果 FIND_IN_SET(str,list)分析逗号分隔的list列表,如果发现str,返回str在list中的位置 LCASE(str)或LOWER(str) 返回将字符串str中所有字符改变为小写后的结果 LEFT(str,x)返回字符串str中最左边的x个字符 LENGTH(s)返回字符串str中的字符数 LTRIM(str) 从字符串str中切掉开头的空格 POSITION(substr,str) 返回子串substr在字符串str中第一次出现的位置 QUOTE(str) 用反斜杠转义str中的单引号 REPEAT(str,srchstr,rplcstr)返回字符串str重复x次的结果 REVERSE(str) 返回颠倒字符串str的结果 RIGHT(str,x) 返回字符串str中最右边的x个字符 RTRIM(str) 返回字符串str尾部的空格 STRCMP(s1,s2)比较字符串s1和s2 TRIM(str)去除字符串首部和尾部的所有空格 UCASE(str)或UPPER(str) 返回将字符串str中所有字符转变为大写后的结果 四、日期和时间函数 CURDATE()或CURRENT_DATE() 返回当前的日期 CURTIME()或CURRENT_TIME() 返回当前的时间 DATE_ADD(date,INTERVAL int keyword)返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化),如:SELECTDATE_ADD(CURRENT_DATE,INTERVAL 6 MONTH); DATE_FORMAT(date,fmt) 依照指定的fmt格式格式化日期date值 DATE_SUB(date,INTERVAL int keyword)返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化),如:SELECTDATE_SUB(CURRENT_DATE,INTERVAL 6 MONTH); DAYOFWEEK(date) 返回date所代表的一星期中的第几天(1~7) DAYOFMONTH(date) 返回date是一个月的第几天(1~31) DAYOFYEAR(date) 返回date是一年的第几天(1~366) DAYNAME(date) 返回date的星期名,如:SELECT DAYNAME(CURRENT_DATE); FROM_UNIXTIME(ts,fmt) 根据指定的fmt格式,格式化UNIX时间戳ts HOUR(time) 返回time的小时值(0~23) MINUTE(time) 返回time的分钟值(0~59) MONTH(date) 返回date的月份值(1~12) MONTHNAME(date) 返回date的月份名,如:SELECT MONTHNAME(CURRENT_DATE); NOW() 返回当前的日期和时间 QUARTER(date) 返回date在一年中的季度(1~4),如SELECT QUARTER(CURRENT_DATE); WEEK(date) 返回日期date为一年中第几周(0~53) YEAR(date) 返回日期date的年份(1000~9999) 一些示例: 获取当前系统时间:SELECT FROM_UNIXTIME(UNIX_TIMESTAMP()); SELECT EXTRACT(YEAR_MONTH FROM CURRENT_DATE); SELECT EXTRACT(DAY_SECOND FROM CURRENT_DATE); SELECT EXTRACT(HOUR_MINUTE FROM CURRENT_DATE); 返回两个日期值之间的差值(月数):SELECT PERIOD_DIFF(200302,199802); 在Mysql中计算年龄: SELECT DATE_FORMAT(FROM_DAYS(TO_DAYS(NOW())-TO_DAYS(birthday)),'%Y')+0 AS age FROM employee; 这样,如果Brithday是未来的年月日的话,计算结果为0。 下面的SQL语句计算员工的绝对年龄,即当Birthday是未来的日期时,将得到负值。 SELECT DATE_FORMAT(NOW(), '%Y') - DATE_FORMAT(birthday, '%Y') -(DATE_FORMAT(NOW(), '00-%m-%d') <DATE_FORMAT(birthday, '00-%m-%d')) AS age from employee 五、加密函数 AES_ENCRYPT(str,key) 返回用密钥key对字符串str利用高级加密标准算法加密后的结果,调用AES_ENCRYPT的结果是一个二进制字符串,以BLOB类型存储 AES_DECRYPT(str,key) 返回用密钥key对字符串str利用高级加密标准算法解密后的结果 DECODE(str,key) 使用key作为密钥解密加密字符串str ENCRYPT(str,salt) 使用UNIXcrypt()函数,用关键词salt(一个可以惟一确定口令的字符串,就像钥匙一样)加密字符串str ENCODE(str,key) 使用key作为密钥加密字符串str,调用ENCODE()的结果是一个二进制字符串,它以BLOB类型存储 MD5() 计算字符串str的MD5校验和 PASSWORD(str) 返回字符串str的加密版本,这个加密过程是不可逆转的,和UNIX密码加密过程使用不同的算法。 SHA() 计算字符串str的安全散列算法(SHA)校验和 示例: SELECT ENCRYPT('root','salt'); SELECT ENCODE('xufeng','key'); SELECT DECODE(ENCODE('xufeng','key'),'key');#加解密放在一起 SELECT AES_ENCRYPT('root','key'); SELECT AES_DECRYPT(AES_ENCRYPT('root','key'),'key'); SELECT MD5('123456'); SELECT SHA('123456'); 六、控制流函数 MySQL有4个函数是用来进行条件操作的,这些函数可以实现SQL的条件逻辑,允许开发者将一些应用程序业务逻辑转换到数据库后台。 MySQL控制流函数: CASE WHEN[test1] THEN [result1]...ELSE [default] END如果testN是真,则返回resultN,否则返回default CASE [test] WHEN[val1] THEN [result]...ELSE [default]END 如果test和valN相等,则返回resultN,否则返回default IF(test,t,f) 如果test是真,返回t;否则返回f IFNULL(arg1,arg2) 如果arg1不是空,返回arg1,否则返回arg2 NULLIF(arg1,arg2) 如果arg1=arg2返回NULL;否则返回arg1 这些函数的第一个是IFNULL(),它有两个参数,并且对第一个参数进行判断。如果第一个参数不是NULL,函数就会向调用者返回第一个参数;如果是NULL,将返回第二个参数。 如:SELECT IFNULL(1,2), IFNULL(NULL,10),IFNULL(4*NULL,'false'); NULLIF()函数将会检验提供的两个参数是否相等,如果相等,则返回NULL,如果不相等,就返回第一个参数。 如:SELECT NULLIF(1,1),NULLIF('A','B'),NULLIF(2+3,4+1); 和许多脚本语言提供的IF()函数一样,MySQL的IF()函数也可以建立一个简单的条件测试,这个函数有三个参数,第一个是要被判断的表达式,如果表达式为真,IF()将会返回第二个参数,如果为假,IF()将会返回第三个参数。 如:SELECTIF(1<10,2,3),IF(56>100,'true','false'); IF()函数在只有两种可能结果时才适合使用。然而,在现实世界中,我们可能发现在条件测试中会需要多个分支。在这种情况下,MySQL提供了CASE函数,它和PHP及Perl语言的switch-case条件例程一样。 CASE函数的格式有些复杂,通常如下所示: CASE [expression to be evaluated] WHEN [val 1] THEN [result 1] WHEN [val 2] THEN [result 2] WHEN [val 3] THEN [result 3] ...... WHEN [val n] THEN [result n] ELSE [default result] END 这里,第一个参数是要被判断的值或表达式,接下来的是一系列的WHEN-THEN块,每一块的第一个参数指定要比较的值,如果为真,就返回结果。所有的WHEN-THEN块将以ELSE块结束,当END结束了所有外部的CASE块时,如果前面的每一个块都不匹配就会返回ELSE块指定的默认结果。如果没有指定ELSE块,而且所有的WHEN-THEN比较都不是真,MySQL将会返回NULL。 CASE函数还有另外一种句法,有时使用起来非常方便,如下: CASE WHEN [conditional test 1] THEN [result 1] WHEN [conditional test 2] THEN [result 2] ELSE [default result] END 这种条件下,返回的结果取决于相应的条件测试是否为真。 示例: mysql>SELECT CASE 'green' WHEN 'red' THEN 'stop' WHEN 'green' THEN 'go' END; SELECT CASE 9 WHEN 1 THEN 'a' WHEN 2 THEN 'b' ELSE 'N/A' END; SELECT CASE WHEN (2+2)=4 THEN 'OK' WHEN(2+2)<>4 THEN 'not OK' END ASSTATUS; SELECT Name,IF((IsActive = 1),'已激活','未激活') AS RESULT FROMUserLoginInfo; SELECT fname,lname,(math+sci+lit) AS total, CASE WHEN (math+sci+lit) < 50 THEN 'D' WHEN (math+sci+lit) BETWEEN 50 AND 150 THEN 'C' WHEN (math+sci+lit) BETWEEN 151 AND 250 THEN 'B' ELSE 'A' END AS grade FROM marks; SELECT IF(ENCRYPT('sue','ts')=upass,'allow','deny') AS LoginResultFROM users WHERE uname = 'sue';#一个登陆验证 七、格式化函数 DATE_FORMAT(date,fmt) 依照字符串fmt格式化日期date值 FORMAT(x,y) 把x格式化为以逗号隔开的数字序列,y是结果的小数位数 INET_ATON(ip) 返回IP地址的数字表示 INET_NTOA(num) 返回数字所代表的IP地址 TIME_FORMAT(time,fmt) 依照字符串fmt格式化时间time值 其中最简单的是FORMAT()函数,它可以把大的数值格式化为以逗号间隔的易读的序列。 示例: SELECT FORMAT(34234.34323432,3); SELECT DATE_FORMAT(NOW(),'%W,%D %M %Y %r'); SELECT DATE_FORMAT(NOW(),'%Y-%m-%d'); SELECT DATE_FORMAT(19990330,'%Y-%m-%d'); SELECT DATE_FORMAT(NOW(),'%h:%i %p'); SELECT INET_ATON('10.122.89.47'); SELECT INET_NTOA(175790383); 八、类型转化函数 为了进行数据类型转化,MySQL提供了CAST()函数,它可以把一个值转化为指定的数据类型。类型有:BINARY,CHAR,DATE,TIME,DATETIME,SIGNED,UNSIGNED 示例: SELECT CAST(NOW() AS SIGNED INTEGER),CURDATE()+0; SELECT 'f'=BINARY 'F','f'=CAST('F' AS BINARY); 九、系统信息函数 DATABASE() 返回当前数据库名 BENCHMARK(count,expr) 将表达式expr重复运行count次 CONNECTION_ID() 返回当前客户的连接ID FOUND_ROWS() 返回最后一个SELECT查询进行检索的总行数 USER()或SYSTEM_USER() 返回当前登陆用户名 VERSION() 返回MySQL服务器的版本 示例: SELECT DATABASE(),VERSION(),USER(); SELECTBENCHMARK(9999999,LOG(RAND()*PI()));#该例中,MySQL计算LOG(RAND()*PI())表达式9999999次。
完整语法 函数名([字段]) over(partition by 字段名 order by 字段名) 聚合函数:sum count avg max min 排名函数 row_number rank dense_rank ntile 其他:lag lead first_value last_value 聚合开窗的用法 -- 题目1 计算每个学生的及格科目数 select *,count(sname) over(partition by sname) 及格的个数 from stu where num>=60 order by sname; -- 每个人的成绩与自己总的平均分的差距 select *, avg(num) over(partition by cname order by cname) as avg_score from stu where num>0; 排名开窗函数 select s.sid,s1.sname,s1.gender,c.cname,s.num, row_number() over (partition by c.cname order by num desc) as row_number排名, rank() over (partition by c.cname order by num desc) as rank排名, dense_rank() over (partition by c.cname order by num desc) as dense_rank排名, ntile(6) over (partition by c.cname order by num desc) as ntile排名 from score s join student s1 on s.student_id = s1.sid left join course c on s.course_id = c.cid; 作弊次数的案例 select uid,count(uid) 作弊次数 from (select *,lead(login_time,1) over(partition by uid order by login_time) as new_time, TIMESTAMPDIFF(SECOND,login_time,(lead(login_time,1) over(partition by uid order by login_time) ))/60 相差秒数 from lag_table) as e where 相差秒数<=2 group by uid; 统计窗口上移1行 select *,lead(login_time,1) over(partition by uid order by login_time last_value select s.sid,s1.sname,s1.gender,c.cname,s.num, last_value(num) over(partition by c.cname order by c.cname) as last_value用法 from score s join student s1 on s.student_id = s1.sid left join course c on s.course_id = c.cid