

python常用模块
常用模块:
一、time模块
import time
# s = time.time()
# print(s)
# time.sleep(2)
# 拿到format string的方式
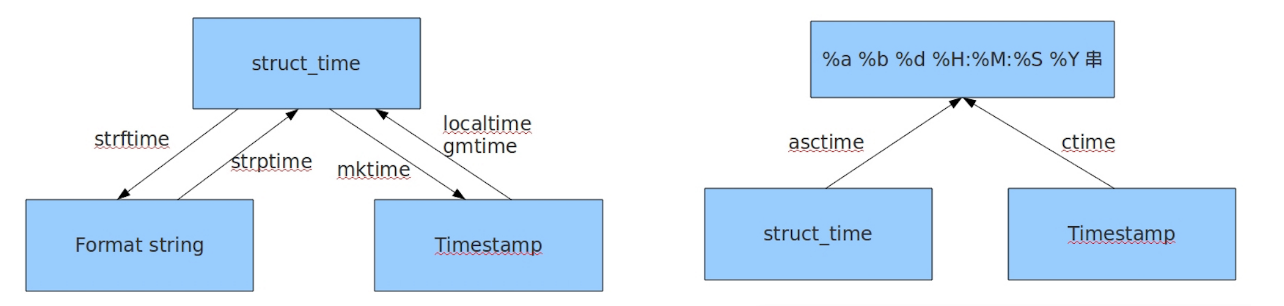
# print(time.ctime(s)) # time.ctime(float) ----> format string in local time
# print(time.asctime(time.localtime(s))) # time.asctime(tuple) ----> format string in local time
# print(time.asctime()) # 如果不传值,默认的就会用当前的时间戳
# print(time.ctime()) # 如果不传值,默认的就会用当前的struct time
# print(time.localtime())
# print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())) # 按照给定的格式 将 tuple---> string。 strptime 是 string parse time 的缩写,就是将字符串解析成元组的意思。
Commonly used format codes:
%Y Year with century as a decimal number.
%m Month as a decimal number [01,12].
%d Day of the month as a decimal number [01,31].
%H Hour (24-hour clock) as a decimal number [00,23].
%M Minute as a decimal number [00,59].
%S Second as a decimal number [00,61].
%z Time zone offset from UTC.
%a Locale's abbreviated weekday name.
%A Locale's full weekday name.
%b Locale's abbreviated month name.
%B Locale's full month name.
%c Locale's appropriate date and time representation.
%I Hour (12-hour clock) as a decimal number [01,12].
%p Locale's equivalent of either AM or PM.
# 拿到时间戳 float 类型
# tu = time.localtime()
# print(tu)
# s = time.mktime(tu) # time.mktime() 将 tuple----> float
# print(time.time())
# 拿到struct time 类型
# s = time.time()
# print(time.localtime(s)) # 北京时间 接受float ---> tuple
# print(time.gmtime(s)) # 天文台时间 接受float ---> tuple
The other representation is a tuple of 9 integers giving local time.
The tuple items are:
year (including century, e.g. 1998)
month (1-12)
day (1-31)
hours (0-23)
minutes (0-59)
seconds (0-59)
weekday (0-6, Monday is 0)
Julian day (day in the year, 1-366)
DST (Daylight Savings Time) flag (-1, 0 or 1)
If the DST flag is 0, the time is given in the regular time zone;
if it is 1, the time is given in the DST time zone;
if it is -1, mktime() should guess based on the date and time.
# print(time.strptime(time.ctime())) # 接受 string ---> tuple。 strftime 是 string format time 的缩写 就是转成字符串时间的意思
# print(time.strptime(time.asctime())) # 接受 string ---> tuple
二、datetime模块
在python文档中,time是归类在常规操作系统服务中,它提供的功能更加接近于操作系统层面。其所能表述的日期范围被限定在1970-2038之间,如果需要表述范围之外的日期,可能需要考虑使用datetime模块更好。
datetime比time高级了不少,可以理解为datetime基于time进行了封装,提供了更多实用的函数,主要包含一下几类:
- timedelta:主要用于计算时间跨度
- tzinfo:时区相关
- time:只关注时间
- date:只关注日期
- datetime:同时有时间和日期
在实际使用中,用得比较多的是datetime.datetime和datetime.timedelta,另外两个datetime.date和datetime.time实际使用和datetime.datetime并无太大差别。datetime.datetime 主要会有以下属性及常用方法:
datetime.datetime.ctime() 将datetime.datetime类型转化成str类型,输出:Sun Jul 28 15:47:51 2019
datetime.datetime.now():返回当前系统时间:2019-07-28 15:42:24.765625
datetime.datetime.now().date():返回当前日期时间的日期部分:2019-07-28
datetime.datetime.now().time():返回当前日期时间的时间部分:15:42:24.750000
datetime.datetime.fromtimestamp()
datetime.datetime.replace()
datetime.datetime.strftime():由日期格式转化为字符串格式
datetime.datetime.now().strftime('%b-%d-%Y %H:%M:%S')
'Apr-16-2017 21:01:35'
datetime.datetime.strptime():由字符串格式转化为日期格式
datetime.datetime.strptime('Apr-16-2017 21:01:35', '%b-%d-%Y %H:%M:%S')
2017-04-16 21:01:35
除了实例本身具有的方法,类本身也提供了很多好用的方法:
- datetime.strptime(date_string,format): 给定时间格式解析字符串
- datetime.now([tz]):当前时间默认 localtime
- datetime.today():当前时间
datetime.timedelta用来计算两个datetime.datetime或者datetime.date类型之间的时间差。
>>> a=datetime.datetime.now()
>>> b=datetime.datetime.now()
>>> a
datetime.datetime(2017, 4, 16, 21, 21, 20, 871000)
>>> b
datetime.datetime(2017, 4, 16, 21, 21, 29, 603000)
>>> b-a
datetime.timedelta(0, 8, 732000)
>>> (b-a).seconds
8
或者
time1 = datetime.datetime(2016, 10, 20)
time2 = datetime.datetime(2015, 11, 2)
"""计算天数差值"""
print(time1-time2).days
"""计算两个日期之间相隔的秒数"""
print (time1-time2).total_seconds()
import datetime, time # 用于时间加减
print(datetime.datetime.now()) # 返回 2020-08-01 16:15:58.512076
print(datetime.date.fromtimestamp(time.time())) # 时间戳直接转成日期格式 2019-01-01
print(datetime.datetime.now() + datetime.timedelta(3)) # 当前时间+3天 2019-01-04 00:56:58.771296
print(datetime.datetime.now() + datetime.timedelta(-3)) # 当前时间-3天 2018-12-29 00:56:58.771296
print(datetime.datetime.now() + datetime.timedelta(hours=3)) # 当前时间+3小时 2019-01-01 03:56:58.771296
print(datetime.datetime.now() + datetime.timedelta(minutes=30)) # 当前时间+30分 2019-01-01 01:26:58.771296
c_time = datetime.datetime.now()
print(c_time.replace(minute=3, hour=2)) # 时间替换 2019-01-01 02:03:58.771296
打印进度条
import time
def progress(percent):
'''打印进度条'''
if percent > 1:
percent = 1
res = int(50 * percent) * 'I'
print('\r[%-50s] %d%%' % (res, int(100 * percent)), end='')
recv_size=0
total_size=1025
while recv_size < total_size:
time.sleep(0.01) # 下载了1024个字节的数据
recv_size+=1024 # recv_size=2048
# 打印进度条
percent = recv_size / total_size # 1024 / 333333
progress(percent)
三、sys 模块
import sys sys.argv #在命令行参数是一个空列表,在其他中第一个列表元素中程序本身的路径 sys.exit(0) #退出程序,正常退出时exit(0) sys.version #获取python解释程序的版本信息 sys.path #返回模块的搜索路径,初始化时使用python PATH环境变量的值 sys.platform #返回操作系统平台的名称 sys.stdin #输入相关 standard input 标准输入 sys.stdout #输出相关 standard output 标注输出 sys.stderror #错误相关 sys.getrecursionlimit() #获取最大递归层数 1000 sys.setrecursionlimit(5000) #设置最大递归层数
四、os 模块
控制操作系统
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
print(os.path.join("D:\\python\\wwww","aaa")) #做路径拼接用的 #D:\python\wwww\aaa
print(os.path.join(r"D:\python\wwww","aaa")) #做路径拼接用的 #D:\python\wwww\aaa
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
在Linux和Mac平台上,该函数会原样返回path,在windows平台上会将路径中所有字符转换为小写,并将所有斜杠转换为反斜杠。
>>> os.path.normcase('c:/windows\\system32\\')
'c:\\windows\\system32\\'
规范化路径,如..和/
>>> os.path.normpath('c://windows\\System32\\../Temp/')
'c:\\windows\\Temp'
>>> a='/Users/jieli/test1/\\\a1/\\\\aa.py/../..'
>>> print(os.path.normpath(a))
/Users/jieli/test1
os路径处理
#方式一:推荐使用
import os
#具体应用
import os,sys
possible_topdir = os.path.normpath(os.path.join(
os.path.abspath(__file__),
os.pardir, #上一级
os.pardir,
os.pardir
))
sys.path.insert(0,possible_topdir)
#方式二:不推荐使用
os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
五、random 模块
# 随机生成
import random
print(random.random()) # (0,1)----float 大于0且小于1之间的小数
print(random.randint(1, 3)) # [1,3] 大于等于1且小于等于3之间的整数
print(random.randrange(1, 3)) # [1,3) 大于等于1且小于3之间的整数
print(random.choice([1, '23', [4, 5]])) # 1或者23或者[4,5]
print(random.sample([1, '23', [4, 5]], 2)) # 列表元素任意2个组合
print(random.uniform(1, 3)) # 大于1小于3的小数,如1.927109612082716
item = [1, 3, 5, 7, 9]
random.shuffle(item) # 打乱item的顺序,相当于"洗牌"
print(item)
# 随机生成验证码
import random
def make_code(n):
res = ''
for i in range(n):
alf = chr(random.randint(65, 90))
num = str(random.randint(0, 9))
res += random.choice([alf, num])
return res
print(make_code(6))
------------------------------------------------------------->
import random, string
source = string.digits + string.ascii_lowercase + string.ascii_uppercase + string.ascii_letters
print(source)
# 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
print("".join(random.sample(source, 6)))
六、shutil 模块
高级的 文件,文件夹,压缩包处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
shutil.copyfile(src, dst)
拷贝文件,
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copystat(src, dst)
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copy(src, dst)
拷贝文件和权限
shutil.copy2(src, dst)
拷贝文件和状态信息
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
"""
shutil.copyfileobj(open('xmltest.xml','r'), open('new.xml', 'w'))
shutil.copyfile('b.txt', 'bnew.txt')#目标文件无需存在
shutil.copymode('f1.log', 'f2.log') #目标文件必须存在
shutil.copystat('f1.log', 'f2.log') #目标文件必须存在
shutil.copy('f1.log', 'f2.log')
shutil.copy2('f1.log', 'f2.log')
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) #目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除
'''
通常的拷贝都把软连接拷贝成硬链接,即对待软连接来说,创建新的文件
'''
#拷贝软连接
shutil.copytree('f1', 'f2', symlinks=True, ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
shutil.move('folder1', 'folder3')
"""
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/
format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
root_dir: 要压缩的文件夹路径(默认当前目录)
owner: 用户,默认当前用户
group: 组,默认当前组
logger: 用于记录日志,通常是logging.Logger对象
"""
# 将 /data 下的文件打包放置当前程序目录
import shutil
ret = shutil.make_archive("data_bak", 'gztar', root_dir='/data')
# 将 /data下的文件打包放置 /tmp/目录
import shutil
ret = shutil.make_archive("/tmp/data_bak", 'gztar', root_dir='/data')
#shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
#zipfile压缩解压缩
import zipfile
# 压缩
z = zipfile.ZipFile('laxi.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close()
# 解压
z = zipfile.ZipFile('laxi.zip', 'r')
z.extractall(path='.')
z.close()
#tarfile压缩解压缩
import tarfile
# 压缩
t=tarfile.open('/tmp/egon.tar','w')
t.add('/test1/a.py',arcname='a.bak')
t.add('/test1/b.py',arcname='b.bak')
t.close()
# 解压
t=tarfile.open('/tmp/egon.tar','r')
t.extractall('/egon')
t.close()
七、json, pickle 模块
1.什么是序列化?
序列化指的是把内存的数据类型转换成一个特定的格式的内容
该格式的内容可以用于存储或者传输给其他平台使用
与序列化想对应的逆操作是返序列化。
内存中的数据类型 -----》 序列化 ------》特定的格式 (json 或者pickle格式)
内存中的数据类型《----- 反序列化《------ 特定的格式 (json 或者pickle格式)
{‘a':111} -----》 序列化 str({‘a':111}) ------》"{‘a':111} "
{‘a':111}《----- 反序列化 eval("{‘a':111} ")《------ "{‘a':111} "
3.为何要有序列化?
序列化得到结果---》特定的格式的内容有两种用途 (可以用于存储,可以传输给其他平台使用)
pickle 只能识别Python的数据格式,如果只是存档的话,建议使用pickle
json是通用的,json格式兼容的是所有语言通用的数据类型,不能识别某一语言的所独有的类型,跨平台数据交互的话可用json
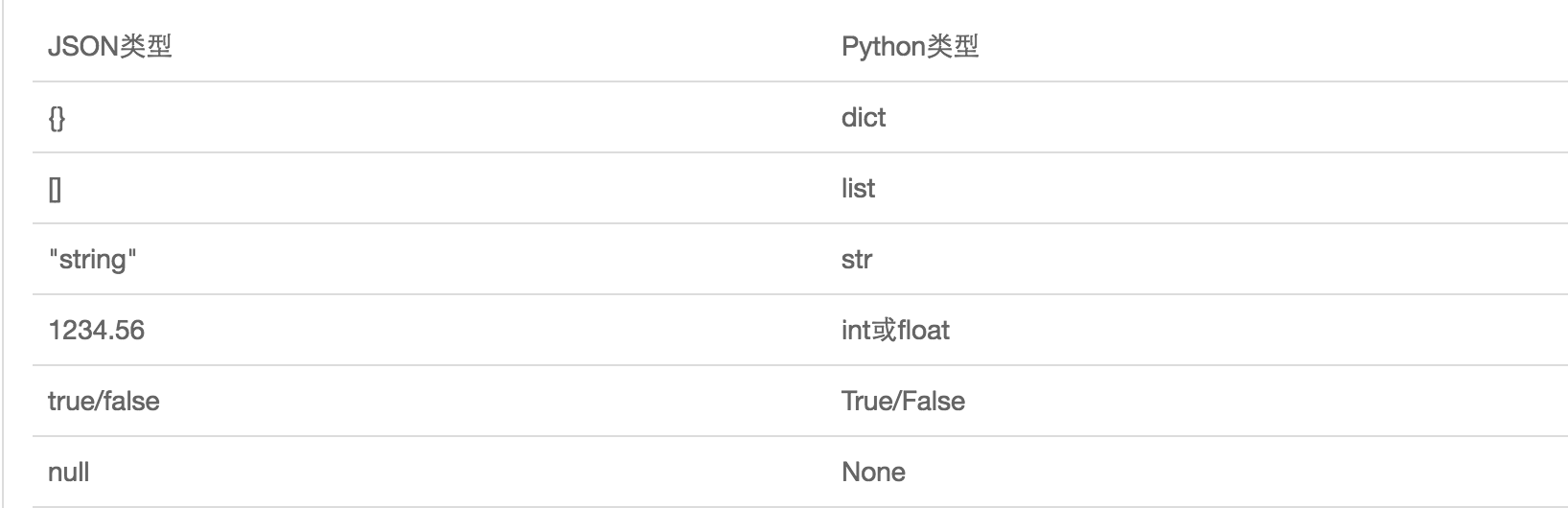
- JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
4.如何实现序列化
import json
# 序列化
json_res=json.dumps([1,'aaa',True,False])
# print(json_res,type(json_res)) # "[1, "aaa", true, false]"
# 反序列化
l=json.loads(json_res)
print(l,type(l))
# 序列化的结果写入文件的复杂方法
json_res=json.dumps([1,'aaa',True,False])
with open('test.json',mode='wt',encoding='utf-8') as f:
f.write(json_res)
# 将序列化的结果写入文件的简单方法
with open('test.json',mode='wt',encoding='utf-8') as f:
json.dump([1,'aaa',True,False],f)
# 从文件读取json格式的字符串进行反序列化操作的复杂方法
with open('test.json',mode='rt',encoding='utf-8') as f:
json_res=f.read()
l=json.loads(json_res)
print(l,type(l))
# 从文件读取json格式的字符串进行反序列化操作的简单方法
with open('test.json',mode='rt',encoding='utf-8') as f:
l=json.load(f)
print(l,type(l))
# 4、猴子补丁
# 在入口处打猴子补丁
import json
import ujson
def monkey_patch_json():
json.__name__ = 'ujson'
json.dumps = ujson.dumps # 在自己写好的 ujson 模块中,有更好的dumps 方法,以后调用json.dumps 其实就是在引用ujson.dump
json.loads = ujson.loads
monkey_patch_json() # 在入口文件出运行
print(json.loads)
json.loads = 'bbb'
print(json.loads)
import pickle
pickle 和 json 用法一样
dic = {'name': 'tom', 'age': 23, 'sex': 'male'}
print(type(dic)) # <class 'dict'>
j = pickle.dumps(dic)
print(type(j)) # <class 'bytes'>
f = open('序列化对象_pickle', 'wb') # 注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-等价于pickle.dump(dic,f)
f.close()
# 反序列化
import pickle
f = open('序列化对象_pickle', 'rb')
data = pickle.loads(f.read()) # 等价于data=pickle.load(f)
print(data['age'])
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的
import shelve
f=shelve.open(r'sheve.txt')
#存
# f['stu1_info']={'name':'rose','age':18,'hobby':['sing','talk','swim']}
# f['stu2_info']={'name':'tom','age':53}
#取
print(f['stu1_info']['hobby'])
f.close()
八、xml 模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data> xml数据
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
# print(root.iter('year')) #全文搜索
# print(root.find('country')) #在root的子节点找,只找一个
# print(root.findall('country')) #在root的子节点找,找所有


import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print('========>',child.tag,child.attrib,child.attrib['name'])
for i in child:
print(i.tag,i.attrib,i.text)
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
#---------------------------------------
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter('year'):
new_year=int(node.text)+1
node.text=str(new_year)
node.set('updated','yes')
node.set('version','1.0')
tree.write('test.xml')
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
#在country内添加(append)节点year2
import xml.etree.ElementTree as ET
tree = ET.parse("a.xml")
root=tree.getroot()
for country in root.findall('country'):
for year in country.findall('year'):
if int(year.text) > 2000:
year2=ET.Element('year2')
year2.text='新年'
year2.attrib={'update':'yes'}
country.append(year2) #往country节点下添加子节点
tree.write('a.xml.swap')
自己创建xml文档:
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = '33'
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = '19'
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #打印生成的格式
xml教程的:点击
九、configparser 模块
configparser用于处理特定格式的文件,本质上是利用open来操作文件,主要用于配置文件分析用的
该模块适用于配置文件的格式与windows ini文件类似,可以包含一个或多个节(section),每个节可以有多个参数(键=值)。
# 注释1 ; 注释2 [section1] k1 = v1 k2:v2 user=egon age=18 is_admin=true salary=31 [section2] k1 = v1
""" 读取 """ import configparser config = configparser.ConfigParser() config.read('a.cfg') # 查看所有的标题 res = config.sections() # ['section1', 'section2'] print(res) # 查看标题section1下所有key=value的key options = config.options('section1') print(options) # ['k1', 'k2', 'user', 'age', 'is_admin', 'salary'] # 查看标题section1下所有key=value的(key,value)格式 item_list = config.items('section1') print( item_list) # [('k1', 'v1'), ('k2', 'v2'), ('user', 'egon'), ('age', '18'), ('is_admin', 'true'), ('salary', '31')] # 查看标题section1下user的值=>字符串格式 val = config.get('section1', 'user') print(val) # egon # 查看标题section1下age的值=>整数格式 val1 = config.getint('section1', 'age') print(val1) # 18 # 查看标题section1下is_admin的值=>布尔值格式 val2 = config.getboolean('section1', 'is_admin') print(val2) # True # 查看标题section1下salary的值=>浮点型格式 val3 = config.getfloat('section1', 'salary') print(val3) # 31.0 """ 改写 """ import configparser config = configparser.ConfigParser() config.read('a.cfg', encoding='utf-8') # 删除整个标题section2 config.remove_section('section2') # 删除标题section1下的某个k1和k2 config.remove_option('section1', 'k1') config.remove_option('section1', 'k2') # 判断是否存在某个标题 print(config.has_section('section1')) # 判断标题section1下是否有user print(config.has_option('section1', '')) # 添加一个标题 config.add_section('egon') # 在标题egon下添加name=egon,age=18的配置 config.set('egon', 'name', 'egon') # config.set('egon','age',18) #报错,必须是字符串 # 最后将修改的内容写入文件,完成最终的修改 config.write(open('a.cfg', 'w')) """ 基于上述方法添加一个ini文档 """ import configparser config = configparser.ConfigParser() config["DEFAULT"] = {'ServerAliveInterval': '45', 'Compression': 'yes', 'CompressionLevel': '9'} config['bitbucket.org'] = {} config['bitbucket.org']['User'] = 'hg' config['topsecret.server.com'] = {} topsecret = config['topsecret.server.com'] topsecret['Host Port'] = '50022' # mutates the parser topsecret['ForwardX11'] = 'no' # same here config['DEFAULT']['ForwardX11'] = 'yes' with open('example.ini', 'w') as configfile: config.write(configfile)
import configparser config = configparser.ConfigParser() config["DEFAULT"] = {'ServerAliveInterval': '45', 'Compression': 'yes', 'CompressionLevel': '9'} config['bitbucket.org'] = {} config['bitbucket.org']['User'] = 'hg' config['topsecret.server.com'] = {} topsecret = config['topsecret.server.com'] topsecret['Host Port'] = '50022' # mutates the parser topsecret['ForwardX11'] = 'no' # same here config['DEFAULT']['ForwardX11'] = 'yes' with open('example.ini', 'w') as configfile: config.write(configfile)
十、hashlib 模块
hash是一种算法(3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法),该算法接受传入的内容,经过运算得到一串hash值
hash值的特点是
- 只要传入的内容一样,得到的hash值必然一样
- 不能由hash值返解成内容,不应该在网络传输明文密码
- 只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的
1、算法介绍
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。
2、摘要算法应用
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:
name | password
--------+----------
michael | 123456
bob | abc999
alice | alice2008
如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数据库的,也就是能获取到所有用户的口令。正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,比如MD5:
username | password
---------+---------------------------------
michael | e10adc3949ba59abbe56e057f20f883e
bob | 878ef96e86145580c38c87f0410ad153
alice | 99b1c2188db85afee403b1536010c2c9
考虑这么个情况,很多用户喜欢用123456,888888,password这些简单的口令,于是,黑客可以事先计算出这些常用口令的MD5值,得到一个反推表:
'e10adc3949ba59abbe56e057f20f883e': '123456'
'21218cca77804d2ba1922c33e0151105': '888888'
'5f4dcc3b5aa765d61d8327deb882cf99': 'password'
这样,无需破解,只需要对比数据库的MD5,黑客就获得了使用常用口令的用户账号。
对于用户来讲,当然不要使用过于简单的口令。但是,我们能否在程序设计上对简单口令加强保护呢?
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
hashlib.md5("salt".encode("utf8"))
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个用户的口令是一样的。有没有办法让使用相同口令的用户存储不同的MD5呢?
如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储不同的MD5。
摘要算法在很多地方都有广泛的应用。要注意摘要算法不是加密算法,不能用于加密(因为无法通过摘要反推明文),只能用于防篡改,但是它的单向计算特性决定了可以在不存储明文口令的情况下验证用户口令。
''' 注意:把一段很长的数据update多次,与一次update这段长数据,得到的结果一样 ''' import hashlib m = hashlib.md5() # m=hashlib.sha256() m.update('hello'.encode('utf8')) print(m.hexdigest()) # 5d41402abc4b2a76b9719d911017c592 m.update('world'.encode('utf8')) print(m.hexdigest()) # fc5e038d38a57032085441e7fe7010b0 m2 = hashlib.md5() m2.update('helloworld'.encode('utf8')) print(m2.hexdigest()) # fc5e038d38a57032085441e7fe7010b0 hashlib
def get_md5_doc(file, size): obj = hashlib.md5('+Yan'.encode('utf8')) # 密码加盐 with open(file, 'rb') as f: while size: content = f.read(10) obj.update(content) size -= len(content) return obj.hexdigest()
十一、re 模块
正则表达式是用来---->匹配 字符串
字符串提供的方法是完全匹配,模糊匹配没办法处理。
python 通过import re模块来实现。调用正则表达式的方法,实现模糊匹配
字符匹配(普通字符,元字符):
普通字符:大多数字符和字母都会和自身匹配
元字符:
. 点,占一位,代指所有字符,除了换行符。 ^ 尖角号,只从字符串开头 开始匹配。 $ dollar符,只从字符串结尾 开始匹配。 * 星号,把前一个(普通字符、一个或者几个元字符)重复匹配0到无穷次。 + 加号,把前一个(普通字符、一个或者几个元字符)重复匹配1到无穷次。 ? 问号,把前一个(普通字符、一个或者几个元字符)重复匹配0到1次。 {} {3}指定匹配前一个元素重复3次。{1,3}指定匹配前一个元素重复1/2/3次 [] 字符集,[cd]匹配两者之一。[a-z]匹配26个字母之一。[a*]把元字符变成普通字符 | 管道,符号两边取或 () 分组,把正则表达式中需要返回的值括起来。 \ 反斜杠后边跟元字符是去除特殊功能的。反斜杠后面跟普通字符可以实现特殊功能: \d 匹配任何十进制数;它相当于类[0-9] \D 匹配任何非数字字符;它相当于类[^0-9] \s 匹配任何空白字符;它相当于类[\t\n\r\f\v] \S 匹配任何非空白字符;它相当于类[^\t\n\r\f\v] \w 匹配任何字母数字字符;它相当于类[a-zA-Z0-9_] \W 匹配任何非字母数字字符;它相当于类[^a-zA-Z0-9_] \b 匹配任何一个特殊字符边界。
re.findall() #匹配到 返回字符串组成的列表。没有结果返回空列表。 re.search().group() #找到第一个匹配值后就返回。返回结果是一个Match object。需要通过.group()提取数据。如果没有结果,返回None re.match().group() #同search,不过仅在字符串开始处进行匹配。 re.split("[ab]","abcd") #先按'a'分隔得到""和"bcd",再对""和"bcd"按照'b'分割 re.sub("\d","abc","alvin5yuan6",1) #第四位参数,指定替换几个值 re.finditer('\d',"acd3d4f5") #把匹配值放进迭代器
import re g = re.finditer('\d',"acd3d4f5") # 迭代器 print(next(g).group()) print(next(g).group()) u = re.sub("\d","abc","alvin5yuan6",1) # alvinabcyuan6 print(u) x1 = re.findall("i\\b","i like python") # ['i'] \b 捕捉特殊字符边界。 print(x1) x = re.findall("i\\b","i li$e python") # ['i', 'i'] \b 捕捉特殊字符边界。 print(x) z7 = re.findall("[^ab]","a*ba2ba2*b,a2a*") # ['*', '2', '2', '*', '2', '*'] 尖角号,取消特殊功能后,放在[]里头是取反的意思 print(z7) z6 = re.findall("a,b","a,ba2ba2,ba2a,") # ['a,b'] 逗号 print(z6) z5 = re.findall("a[2,]b","a,ba2ba2,ba2a,") # ['a,b', 'a2b'] 逗号与2 二取一 print(z5) z4 = re.findall("a[2*]b","a*ba2ba2*ba2a*") # ['a*b', 'a2b'] 星号与2 二取一。取消星号特殊功能 print(z4) z3 = re.findall("a[0-9]b","acbadbasdba2b") # ['a2b'] print(z3) z2 = re.findall("a[a-z]b","acbadbasdba2b") # ['acb', 'adb'] print(z2) z1 = re.findall("a[c,d]b","acbadbasdb") # ['acb', 'adb'] print(z1) s5 = re.findall("a{1,}b","aaaaabaababb") # ['aaaaab', 'aab', 'ab']相当于a+b print(s5) s4 = re.findall("a{0,}b","aaaaabaababb") # ['aaaaab', 'aab', 'ab', 'b'] 相当于a*b print(s4) s3 = re.findall("a{1,3}b","aaaaab") #['aaab'] 默认贪婪匹配 print(s3) s2 = re.findall("a{1,3}b","aaaaabaababb") #['aaab', 'aab', 'ab'] print(s2) s1 = re.findall("a{3}b","aaaaabaababb") #['aaab'] print(s1) ret_6 = re.findall("a.*?b","aaaaabaababb") #['aaaaab', 'aab', 'ab'] print(ret_6) ret_5 = re.findall("a.*b","aaaaabaababb") #['aaaaabaababb'] print(ret_5) ret_4 = re.findall("a*b","aaaaabaababb") #['aaaaab', 'aab', 'ab', 'b'] print(ret_4) ret_3 = re.findall("a+b","aaaaabaababb") # ['aaaaab', 'aab', 'ab'] print(ret_3) ret_3 = re.findall("如.*哈","如哈") print(ret_3) ret_2 = re.findall("a..x$","alexh") # [] $ dollar符要求只从字符串结尾开始匹配。 print(ret_2) ret_1 = re.findall("^h...0","hjsonhello") # [] ^尖角号要求只从字符串开头开始匹配, print(ret_1) ret = re.findall("w\w{2}l","hello world") print(ret) # ['worl']
练习 开发一个简单的python计算器
1.实现加减乘除及括号优先级解析
2.用户输入1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))等类似公式后,必须自己解析里面的(),+
,-,*,/符号和公式(不能调用eval()函数实现),然后得出结果。
十一、logging模块
CRITICAL = 50 #FATAL = CRITICAL ERROR = 40 WARNING = 30 #WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0 #不设置
默认级别为warning,默认打印到终端
最简单的日志文件
可在logging.basicConfig()函数中通过具体参数来更改logging模块默认行为,可用参数有 filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 #格式 %(name)s:Logger的名字,并非用户名,详细查看 %(levelno)s:数字形式的日志级别 %(levelname)s:文本形式的日志级别 %(pathname)s:调用日志输出函数的模块的完整路径名,可能没有 %(filename)s:调用日志输出函数的模块的文件名 %(module)s:调用日志输出函数的模块名 %(funcName)s:调用日志输出函数的函数名 %(lineno)d:调用日志输出函数的语句所在的代码行 %(created)f:当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d:输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s:字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d:线程ID。可能没有 %(threadName)s:线程名。可能没有 %(process)d:进程ID。可能没有 %(message)s:用户输出的消息 logging.basicConfig()
#========使用 import logging logging.basicConfig(filename='access.log', format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', level=10) logging.debug('调试debug') logging.info('消息info') logging.warning('警告warn') logging.error('错误error') logging.critical('严重critical') #========结果 access.log内容: 2017-07-28 20:32:17 PM - root - DEBUG -test: 调试debug 2017-07-28 20:32:17 PM - root - INFO -test: 消息info 2017-07-28 20:32:17 PM - root - WARNING -test: 警告warn 2017-07-28 20:32:17 PM - root - ERROR -test: 错误error 2017-07-28 20:32:17 PM - root - CRITICAL -test: 严重critical
#logger:产生日志的对象 #Filter:过滤日志的对象 #Handler:接收日志然后控制打印到不同的地方,FileHandler用来打印到文件中,StreamHandler用来打印到终端 #Formatter对象:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式 通过handler 给logger 对象 多个输出方式。fornatter为 logger 指定输出格式
import logging from logging import handlers # 生成logger对象 logger = logging.getLogger('web') logger.setLevel(logging.DEBUG) # 生成handler对象 ch = handlers.RotatingFileHandler('test.log',maxBytes=50,backupCount=2) fh = logging.FileHandler('web.log') # 把handler对象绑定到logger logger.addHandler(ch) logger.addHandler(fh) # 生成formatter对象 ch_formatter = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(message)s') ch.setLevel(logging.INFO) fh_formatter = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(levelno)s-%(message)s') fh.setLevel(logging.WARNING) # 把formatter对象绑定到logger ch.setFormatter(ch_formatter) fh.setFormatter(fh_formatter) logger.debug('debug') logger.info('info') logger.warning('warning') logger.critical('critical') logger.error('error')
def get_logger(): logger = logging.getLogger('ftp') # 创建一个logger对象 logger.setLevel(logging.INFO) # 设置日志级别 # handler ch = logging.StreamHandler() # 创建一个handler对象 filename = settings.LOGGING_DIR fh = logging.FileHandler(filename) # 创建一个handler对象 # formatter formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(filename)s - %(message)s') # bind formatter to handler ch.setFormatter(formatter) fh.setFormatter(formatter) # add handler to logger logger.addHandler(ch) logger.addHandler(fh) return logger get_logger().info('记录一下...')
需要注意的是filter的顺序。
logger的 日志级别是第一级过滤,
然后会给handler,
十三、subrocess 模块
import subprocess def for_shell(self,head_dic): """这个就是处理系统命令,拿到执行结果""" cmd = head_dic['cmd'] obj = subprocess.Popen(cmd,shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) stdout, stderr = obj.stdout.read().decode('GBK'),obj.stderr.read().decode('GBK') res_head_dic = {'res': stderr + stdout} return res_head_dic
