python--批量下载豆瓣图片之升级版本
周末下雨没法出门,刷刷豆瓣看看妹子,本想拿以前脚本下载点图片,结果发现运行失败,之前版本为《python--批量下载豆瓣图片》,报错HTTP Error 403: Forbidden,网上一堆的文章都是写在request的header中添加User-Agent模拟浏览器请求就可以解决,但毫无卵用!
在调试过程中无意发现,及时在浏览器地址栏中手动输入图片地址,也出现430 Forbidden的提示,百度一上午没找到答案,略微郁闷,考虑到手动能点击链接能显示图片,于是想通过模拟浏览器操作的方式来自动保存图片,百度一下午Selenium WebDriver,发现图片也显示出来了,就是没法右键保存,百度又是人云亦云的那些东西,折腾很久也没成功。
今天灵光一线,既然手动点击链接变可以,为啥通过地址栏输入的链接就不行呢,两种方式的地址完全相同,不存在手动点击链接后链接变化的问题,那问题会不会就出在两种请求所附带的请求数据上,由于是get方式,请求数据都存放请求头和URL链接中,通过Firefox的开发者工具>>开发者工具栏>>网络选项可以看到请求头内容:

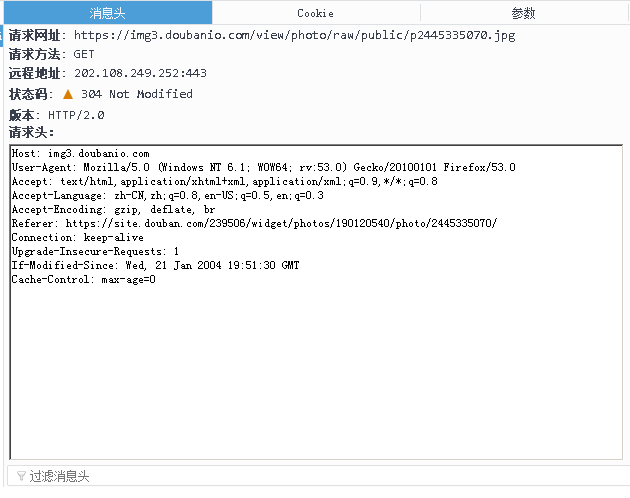
尝试在脚本中也增加请求头中添加Referer项,发现程序顺利通过,看来豆瓣通过这一项来判断,就跟空手去人家婚礼蹭饭一样,不弄个红包装一下,很可能会被打出来!
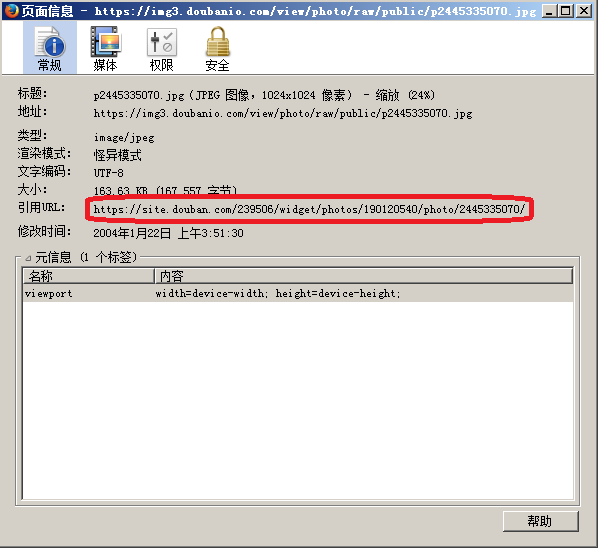
在图片显示窗口,右键“查看页面信息”,也可以很容易找到引用URL一项:
代码附上:
# -*- coding:utf8 -*- import urllib2, urllib, socket import re import requests from lxml import etree import os, time, random DEFAULT_DOWNLOAD_TIMEOUT = 30 def check_save_path(save_path): if not os.path.exists(save_path): os.makedirs(save_path) def get_image_name(image_link): file_name = os.path.basename(image_link) return file_name def get_image_id(file_name): file_id = file_name[0: file_name.rindex('.')] return file_id def save_image(image_link, save_path): file_name = get_image_name(image_link) file_id = get_image_id(file_name) file_path = save_path + "\\" + file_name print("准备下载{0} 到{1}".format(image_link, file_path)) try: headers = {} headers["User-Agent"] = 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0' headers["Referer"] = 'https://site.douban.com/239506/widget/photos/190120540/photo/{0}/'.format(file_id) file_handler = open(file_path, "wb") req = urllib2.Request(url=image_link, headers=headers) opener = urllib2.build_opener() image_handler = opener.open(req).read() file_handler.write(image_handler) return True except Exception, ex: print(ex.args) print("下载文件出错:{0}".format(ex.message)) return False def get_thumb_picture_link(thumb_page_link): try: html_content = urllib2.urlopen(url=thumb_page_link, timeout=DEFAULT_DOWNLOAD_TIMEOUT).read() html_tree = etree.HTML(html_content) # print(str(html_tree)) link_tmp_list = html_tree.xpath('//div[@class="photo-item"]/a/img/@src') page_link_list = [] for link_tmp in link_tmp_list: page_link_list.append(link_tmp) return page_link_list except Exception, ex: print(ex.message) return [] def download_pictures(album_link, min_page_id, max_page_id, picture_count_per_page, save_path): check_save_path(save_path) min_page_id = 0 while min_page_id < max_page_id: thumb_page_link = album_link + "?start={0}".format(min_page_id * picture_count_per_page) thumb_picture_links = get_thumb_picture_link(thumb_page_link) for thumb_picture_link in thumb_picture_links: full_picture_link = thumb_picture_link.replace("photo/thumb", "photo/raw") print('<img src="{0}"/>'.format(full_picture_link)) print("thumb:" + thumb_picture_link) full_picture_link = thumb_picture_link.replace("photo/thumb", "photo/raw") save_flag = save_image(image_link=full_picture_link, save_path=save_path) if not save_flag: full_picture_link = thumb_picture_link.replace("photo/thumb", "photo/photo") save_image(image_link=full_picture_link, save_path=save_path) time.sleep(1) min_page_id += 1 print("下载完成") # 设置图片保存的本地文件夹 save_path = "E:\\PIC\\douban_11\\" # 设置相册地址,注意以反斜杠结尾 album_link = "https://site.douban.com/239506/widget/photos/190120540/" # 设置相册总页数 max_page_id = 20 # 设置每页图片数量,默认为18张 picture_count_per_page = 30 download_pictures(album_link=album_link, min_page_id=1, max_page_id=max_page_id, picture_count_per_page=picture_count_per_page, save_path=save_path)
##====================================================================##
感叹下,以前学html以及做网页开发的时候,很少关心请求头,顶多就知道GET和POST的区别,白白浪费一个周末研究,可惜!
幸好失败是成功它妈妈,吃一堑长一智!
##====================================================================##
没点好图你们是不会罢休的,哇咔咔!



 浙公网安备 33010602011771号
浙公网安备 33010602011771号