五、迭代器和生成器
一、迭代器
1、可迭代对象
- 序列观念的通用化:如果对象是实际保存的序列,或者可以在迭代工具环境中一次产生一个结果的对象,就看做是可迭代的。
- 迭代协议:实现了__next__方法的对象,被认为是可迭代的。
- 当for循环开始时,会通过它传递给iter内置函数,以便从可迭代对象中获得一个迭代器,返回的对象含有需要的next()方法。
- 可使用list一次性查看所有值

2、文件迭代器
- 文件对象就是自己的迭代器。有自己的__next__方法:

逐行读取文本的最佳方式就是不要去读取;替代办法是,使用for循环在每轮自动调用next从而前进到下一行。

3、手动迭代:iter和next
- 内置函数next():自动调用对象的__next__方法,即next(x)等价于x.__next__;
4、内置类型迭代器
- 列表及很多内置对象不是自身的 迭代器,因为它们支持多次打开迭代器。对这样的对象,必须调用iter启动迭代。

- 字典:有一个迭代器,在迭代环境中,会自动返回一个键。效果就是不再需要keys方法遍历字典键

- range迭代器:
-
- 返回迭代器,该迭代器根据需要产生范围中的数字,而不是在内存中构建一个结果列表。

- map、zip、filter返回可迭代对象

- 字典视图迭代器:keys()、values()、items()返回可迭代的视图对象
-
- 视图项保持和字典中的项相同的物理顺序,并且反应对底层的字典作出的修改。

- 字典有自己的迭代器,返回连续的键

5、多个迭代器 VS 单个迭代器
- 多个迭代器:通过针对iter调用返回一个新的对象;

- 单个迭代器:对象返回自身。map、zip、filter不支持相同结果上的多个活跃迭代的器

二、生成器
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
- 生成器函数:编写为常规的def语句,但是使用yield语句一次返回一个结果,在每个结果之间挂起和继续它们的状态;返回一个值后挂起,下次执行时从挂起处继续执行的函数。
- 生成器表达式:类似列表解析,但是返回按需产生结果的一个对象,而不是构建一个结果列表。
- list、dict、str等数据类型不是Iterator,因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
2、生成器函数:yield VS return
- 迭代协议整合
函数包含yield语句,该语句特别编译为生成器。调用时:返回一个迭代器对象,该对象支持用一个__next__的自动创建的方法继续执行的接口;生成器也可能用return语句,总在def语句块的末尾,直接终止值的生成。技术上,可以在任何常规函数退出执行后,引发StopIteration异常实现;调用者角度,生成器的__next__方法继续函数并且运行到下一个yield结果返回或引发StopIteration异常。

3、扩展生成器函数协议:send和next
- send
-
- 技术上,send是一个表达式,可以返回传入的元素而不是一个语句。表达式必须包含在括号中,除非它是赋值语句右边的唯一一项。
-
- 使用时,值可以通过调用G.send(value)发送给一个生成器G。之后恢复生成器的代码,并且生成器中的yield表达式返回了为了发送而传入的值。如果提前调用了正常的G.__next__()方法(或其对等的next(G)),yield返货None。

- next(),调用对象的x.__next__方法,但其他生成器方法必须直接作为生成器对象的方法调用(如G.send(x))
4、生成器表达式
- 返回生成器对象,使用list()调用中包含一个生成器表达式以迫使其一次生成列表中所有的结果。

5、生成器是单迭代器对象
- 生成器函数和生成器表达式自身都是迭代器,并由此只支持一次活跃迭代。
- 一个生成器的迭代器是生成器自身。一旦任何迭代器运行到完成,所有迭代器都将用尽。

- 在一个生成器上调用iter没有效果。

- 许多内置类型支持多个迭代器并且在一个活动迭代器中传递并反映它们的原处修改

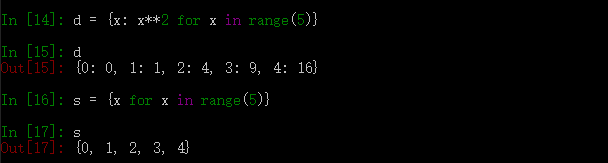
6、解析集合和字典解析
某种意义上,集合解析和字典解析只是把生成器表达式传递给类型名的语法糖。因此,二者都接受任何的可迭代对象。
7、函数陷阱
(1)本地变量是静态检测的,Python是静态检测Python的本地变量,当编译def代码时,不是通过发现赋值语句在运行时进行检测的。

编译时,Python确定x是本地变量,但当函数运行时 在print执行时赋值语句并没有发生,所以会提示使用未定义变量错误。实质,在函数体内的赋值将会使其成为一个本地变量名,如import、=、嵌套def、嵌套类等都会受这种行为的影响。
- 原因:在于被赋值的变量名在函数内部是当做本地变量来对待的,而不是仅在赋值一会的语句中才被当做本地变量。
(2)默认和可变对象
- 默认参数是在def语句运行时评估并保存的,而不是在这个函数调用时。
- 从内部来看,Python会将每一个默认参数保存成一个对象,附加在这个函数本身。必要情况下,它能够从整个作用域内保存至,但因为默认参数在调用之间都保存了一个对象,必须对修改可变的默认参数十分小心。

解决:1、在函数主体的开始对默认参数进行简单考本;2、将默认参数值的表达式移至函数体内部。

(3)没有return语句的函数
- 当函数没有精确的返回值时,函数在控制权从函数主体脱离是,函数将会退出。
- 技术上说,所有函数都返回了一个值,如果没有提供return语句,函数将自动返回None对象
- 没有return语句的函数与Python对应于一些语言中所谓的“过程”是等效的:它们被当做语句,并且None这个结果被忽略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号