(三)TCP、UDP报文段
一、TCP报文段

源端口、目标端口:计算机上的进程要和其他进程通信是要通过计算机端口的,而一个计算机端口某个时刻只能被一个进程占用,所以通过指定源端口和目标端口,就可以知道是哪两个进程需要通信。源端口、目标端口是用16位表示的,可推算计算机的端口个数为2^16个。
序列号:表示本报文段所发送数据的第一个字节的编号。在TCP连接中所传送的字节流的每一个字节都会按顺序编号。由于序列号由32位表示,所以每2^32个字节,就会出现序列号回绕,再次从 0 开始。那如何区分两个相同序列号的不同TCP报文段就是一个问题了,后面会有答案,暂时可以不管。
确认号:表示接收方期望收到发送方下一个报文段的第一个字节数据的编号。也就是告诉发送发:我希望你(指发送方)下次发送的数据的第一个字节数据的编号是这个确认号。也就是告诉发送方:我希望你(指发送方)下次发送给我的TCP报文段的序列号字段的值是这个确认号。(TCP捎带确认机制)
TCP首部长度:由于TCP首部包含一个长度可变的选项部分,所以需要这么一个值来指定这个TCP报文段到底有多长。或者可以这么理解:就是表示TCP报文段中数据部分在整个TCP报文段中的位置。该字段的单位是32位字,即:4个字节。
URG:表示本报文段中发送的数据是否包含紧急数据。URG=1,表示有紧急数据。后面的紧急指针字段只有当URG=1时才有效。
ACK:表示是否前面的确认号字段是否有效。ACK=1,表示有效。只有当ACK=1时,前面的确认号字段才有效。TCP规定,连接建立后,ACK必须为1。
PSH:告诉对方收到该报文段后是否应该立即把数据推送给上层。如果为1,则表示对方应当立即把数据提交给上层,而不是缓存起来。
RST:只有当RST=1时才有用。如果你收到一个RST=1的报文,说明你与主机的连接出现了严重错误(如主机崩溃),必须释放连接,然后再重新建立连接。或者说明你上次发送给主机的数据有问题,主机拒绝响应。
SYN:在建立连接时使用,用来同步序号。当SYN=1,ACK=0时,表示这是一个请求建立连接的报文段;当SYN=1,ACK=1时,表示对方同意建立连接。SYN=1,说明这是一个请求建立连接或同意建立连接的报文。只有在前两次握手中SYN才置为1。
FIN:标记数据是否发送完毕。如果FIN=1,就相当于告诉对方:“我的数据已经发送完毕,你可以释放连接了”
窗口大小:通过窗口大小字段的值告知对方自己的接收窗口大小,用于实现TCP流量控制和差错恢复。该字段会随着接收方对TCP报文段的接收和确认而变化。
校验和:提供额外的可靠性。具体如何校验,参考其他资料。
紧急指针:标记紧急数据在数据字段中的位置。
选项部分:其最大长度可根据TCP首部长度进行推算。TCP首部长度用4位表示,那么选项部分最长为:(2^4-1)*4-20=40字节。
二、UDP报文段
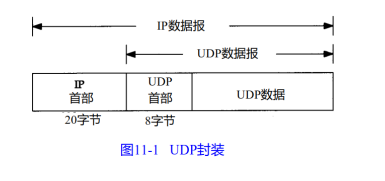

源端口:源端口号,在需要对方回信时选用,不需要时可全 0.
目的端口:目的端口号,在终点交付报文时必须要使用到。
长度:包含UDP首部和UDP数据的字节长度
检验和:检测 UDP 用户数据报在传输中是否有错,有错就丢弃。
三、TCP、UDP应用场景
TCP:当对网络通讯质量有要求的时候,比如:整个数据要准确无误的传递给对方,这往往用于一些要求可靠的应用,比如HTTP、HTTPS、FTP等传输文件的协议,POP3、SMTP等邮件传输的协议。
UDP:当对网络通讯质量要求不高的时候,要求网络通讯速度能尽量的快,这时就可以使用UDP。
QQ语音、QQ视频、DNS、RIP
四、面向报文、面向字节流
面向报文的传输方式是应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。因此,应用程序必须选择合适大小的报文。若报文太长,则IP层需要分片,降低效率。若太短,会是IP太小。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。这也就是说,应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。
(IP分片下面讲)
面向字节流的话,虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序看成是一连串的无结构的字节流。TCP有一个缓冲,当应用程序传送的数据块太长,TCP就可以把它划分短一些再传送。如果应用程序一次只发送一个字节,TCP也可以等待积累有足够多的字节后再构成报文段发送出去。
五、IP分片
- IP把MTU与数据报长度进行比较
- 如果需要进行分片。分片可以发生在原始发送端主机上,也可以发生在中间路由器上
- 把一份IP数据报分片之后只有到达目的地才进行重新组装
- 重新组装由目的端的IP层来完成,其目的是使分片和重新组装过程对传输层(TCP、UDP)是透明的
- 已经分片过的数据报有可能会再次进行分片(可能不止一次)

- 当IP数据报被分片后,每一片都是一个分组,具有自己的IP首部,并在选择路由时与其他分组独立。这样,当数据报的这些片到达目的地端时有可能会失序,但是在IP首部中有足够的信息让接收端能正确组装这些数据报片

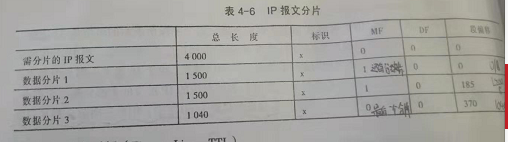
16位标识(Identification):标识所发送的IP报文。每发送一个报文,其标识字段就+1。一个报文在传输过程中被分成若干较小的数据字段,每个数据片必须携带其所属报文的标识,使接收方将其合并标识字段相同的数据片以便重新组装成报文。标识字段并没有标识作用,因为ip提供的是无连接服务,不对报文排序。
3位标志(flag):第1个bit尚未使用,第二个bit是DF(dont fragment),只有DF=0时,才允许分片(所以,若此报文不允许分片,但是此报文长度大于MTU,就会向源主机发送一个ICMP报文);第三个bit为MF(more fragment)用于说明该数据片是否为报文最后一个片段,MF=0表示为最后一个分片。
13位偏移(Freagment offerset):因为一个数据报要分片,此字段用于说明该数据片在整个报文中的位置
- 尽管IP分片过程看起来是透明的,但是有一点不想使用它:即使只丢失一片数据也要重传整个数据报
- IP层本身没有超时重传机制---由更高层来负责超时和重传(TCP有超时和重传,但UDP没有。一些UDP应用程序本身也执行超时和重传)。当来自TCP报文段的某一片丢失后,TCP在超时后会重传整个TCP报文段,该报文段对应于一份IP数据报。没有办法指重传数据报的一个数据分片
- 如果对数据报分片的是中间路由器,而不是起始端系统,那么起始端系统就无法知道数据报是如何分片的。就这个原因,经常要避免分片。
参考:https://blog.csdn.net/wilsonpeng3/article/details/12869233

 浙公网安备 33010602011771号
浙公网安备 33010602011771号