(三.3)聚簇索引、非聚簇索引
转自: https://zhuanlan.zhihu.com/p/62018452
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。具体的细节依赖于其实现方式,但InnoDB的聚族索引实际上在同一个结构中保存了B-Tree索引和数据行。当表有聚族索引时,它的数据行存放在索引的叶子页中。术语“聚族”表示数据行和相邻的键值紧凑的存储在一起。因为无法同时把数据行放在两个不同的地方,所以一个表只能有一个聚族索引。
因为是存储引擎负责实现索引,因此不是所有的存储引擎都支持聚族索引。这里我们主要关注InnoDB,但是这里讨论的原理对于任何支持聚族索引的存储引擎都是适用的。
先来一张带主键的表,如下所示,pId是主键

画出该表的结构图如下:

如上图所示,分为上下两个部分,上半部分是由主键形成的B+树,下半部分就是磁盘上真实的数据!那么,当我们, 执行下面的语句:
select * from table where pId='11'那么,执行过程如下:

如上图所示,从根开始,经过3次查找,就可以找到真实数据。如果不使用索引,那就要在磁盘上,进行逐行扫描,直到找到数据位置。显然,使用索引速度会快。但是在写入数据的时候,需要维护这颗B+树的结构,因此写入性能会下降! OK,接下来引入非聚簇索引!我们执行下面的语句:
create index index_name on table(name);此时结构图如下所示:

大家注意看,会根据你的索引字段生成一颗新的B+树。因此, 我们每加一个索引,就会增加表的体积, 占用磁盘存储空间。然而,注意看叶子节点,非聚簇索引的叶子节点并不是真实数据,它的叶子节点依然是索引节点,存放的是该索引字段的值以及对应的主键索引(聚簇索引)。 如果我们执行下列语句
select * from table where name='lisi'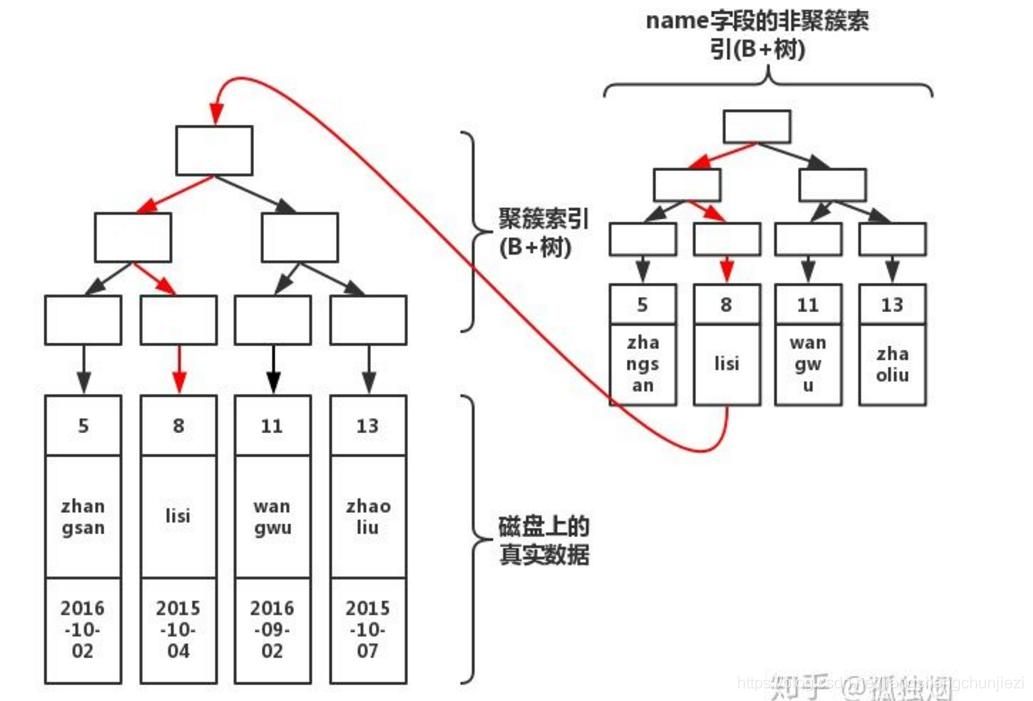
通过上图红线可以看出,先从非聚簇索引树开始查找,然后找到聚簇索引后。根据聚簇索引,在聚簇索引的B+树上,找到完整的数据!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号