CNN---卷积神经网络
为什么CNN常用于图像的识别?

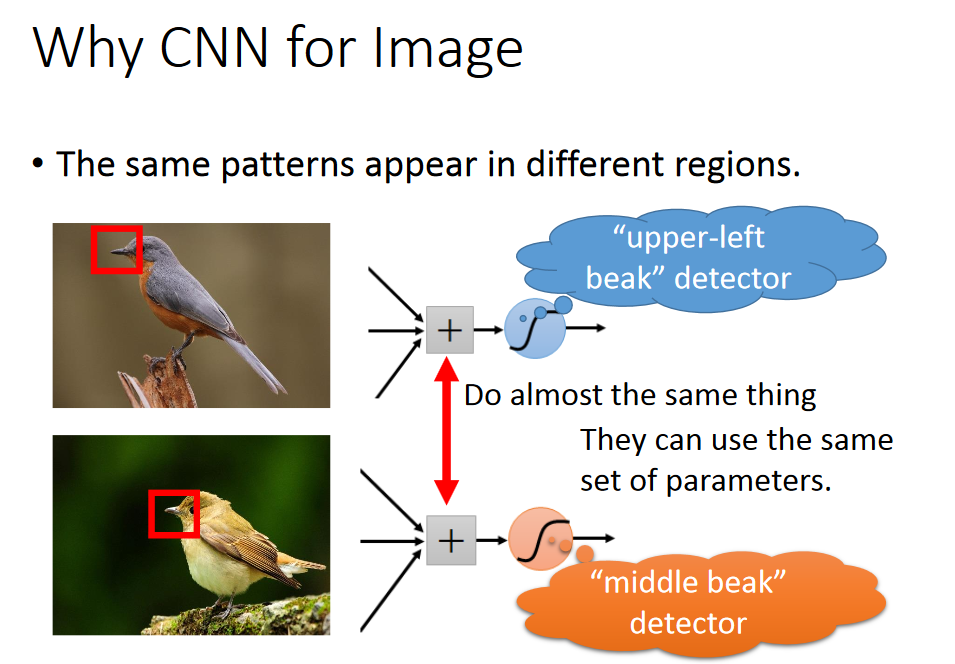
同样的pattern,在image里面,他可能会出现在image不同的部分,但是它们代表的是同样的含义,同样的形状,也有同样的neural,同样的参数,detector就可以侦测出来。
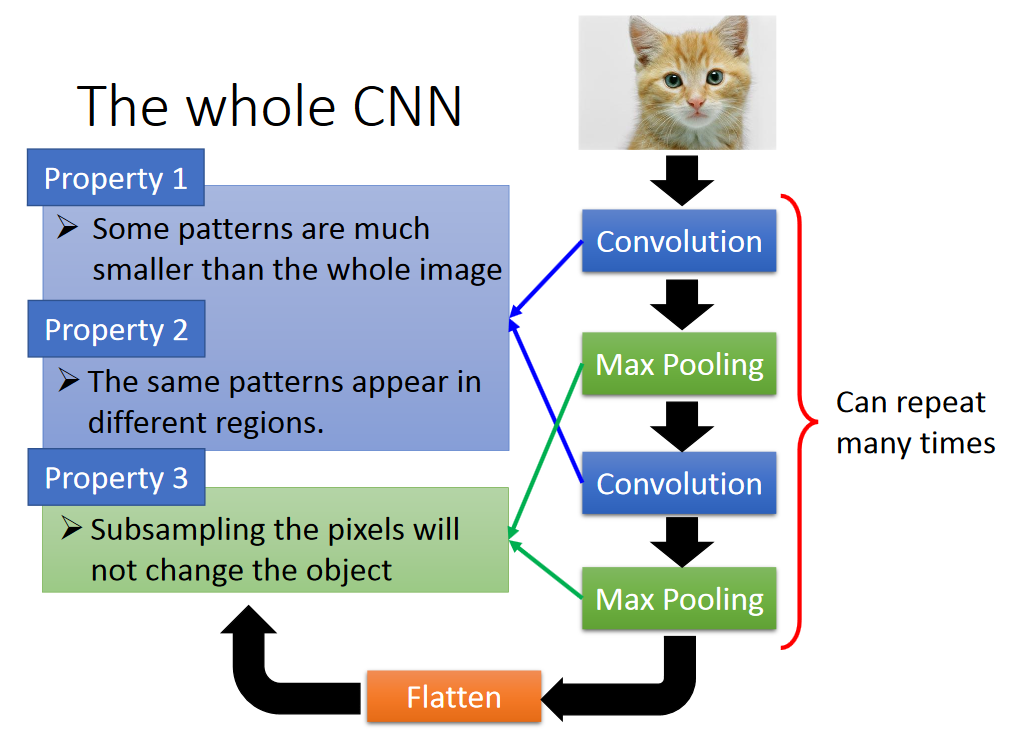
做Subsampling使图片变小对影响辨识没什么影响

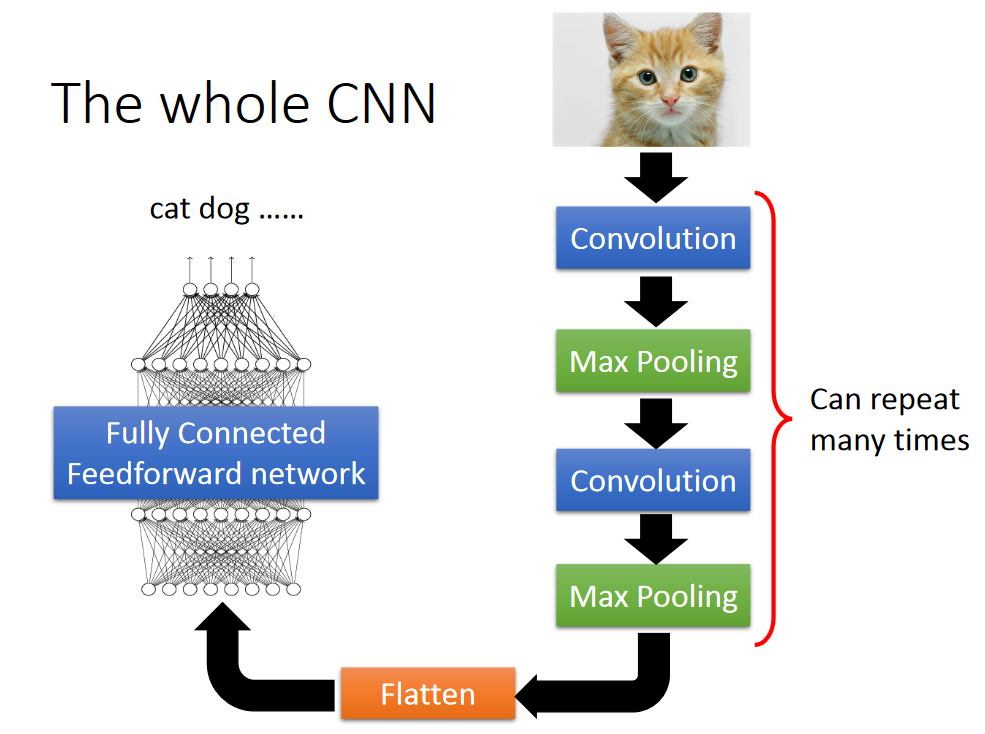
整个CNN实现的过程为:
CNN---Convolution
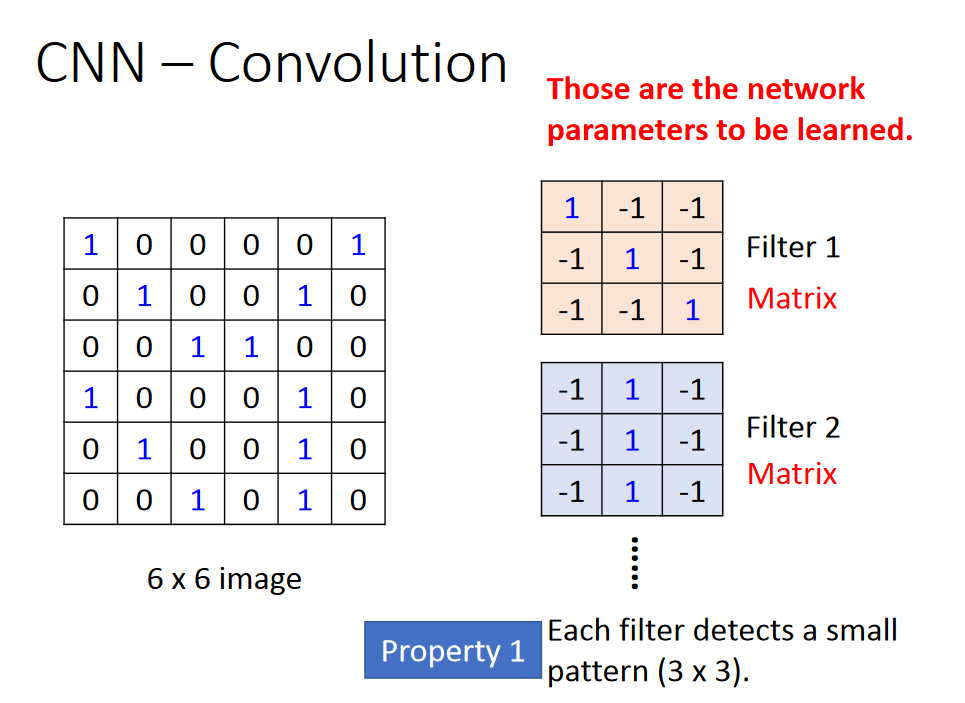
用3*3的矩阵,从左上角开始,与filter1做内积,得到一个值,然后根据stride参数移动相应的距离,然后接着做内积,直到3*3的矩阵移到右下角。
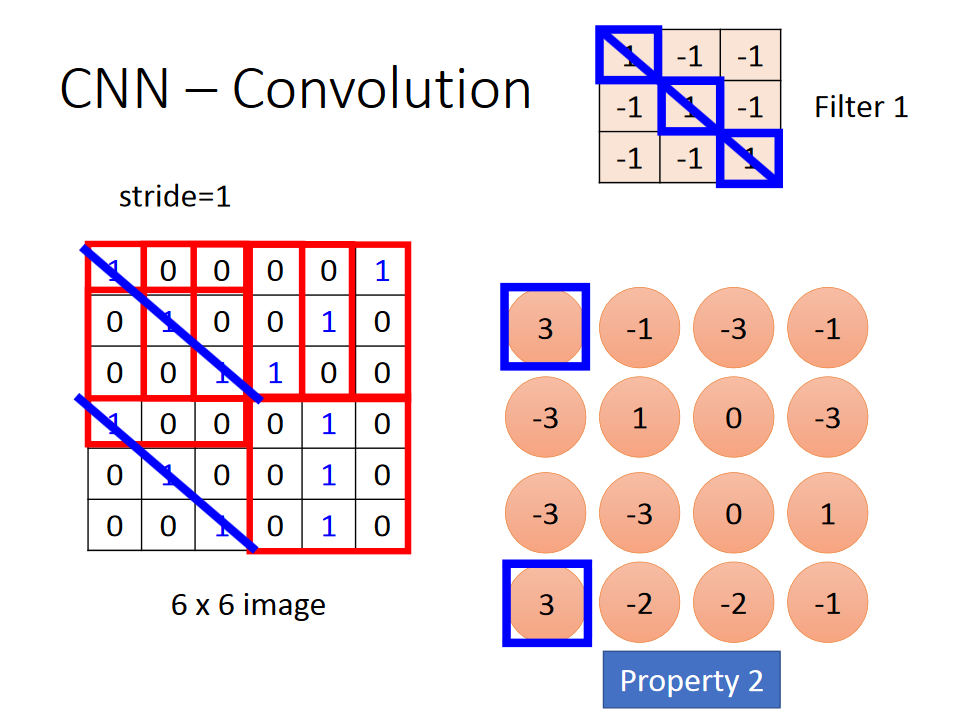
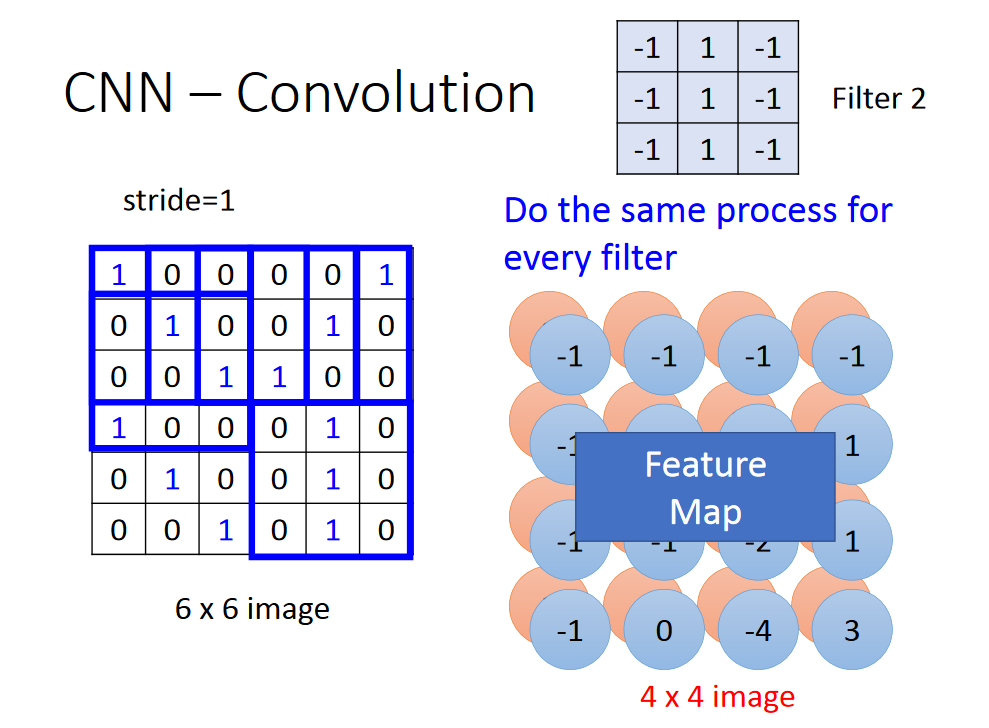
会有很多的filter,当通过很多的filter以后,我们把它叫做 feature map。
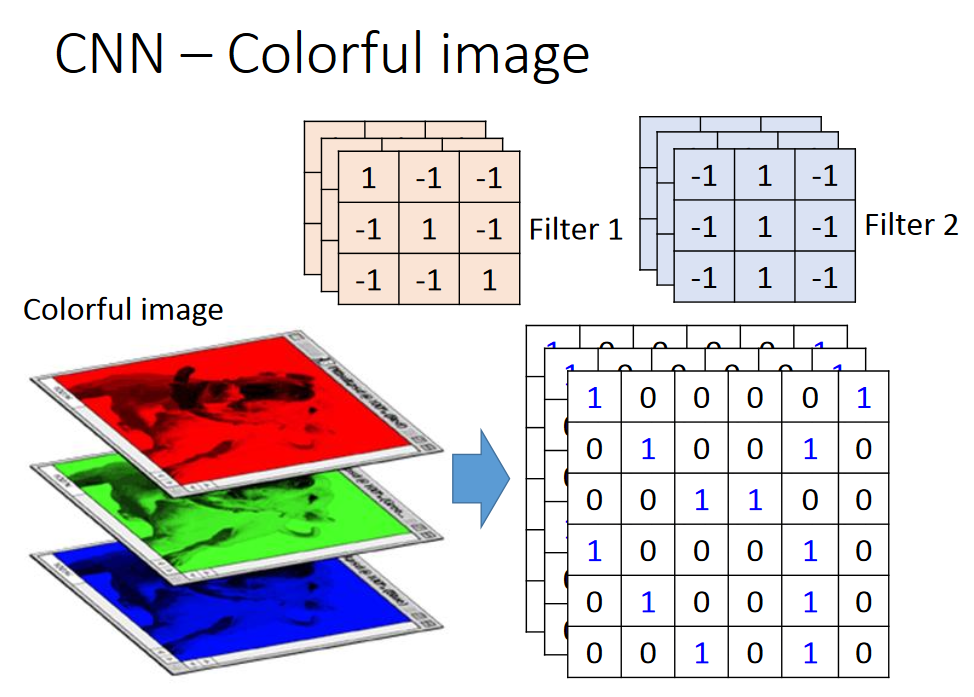
上边介绍的都是灰度图像,那么对于彩色图像呢?彩色图像就是由RGB组成的,是一个立方体,所以此时filter也是一个立方体。
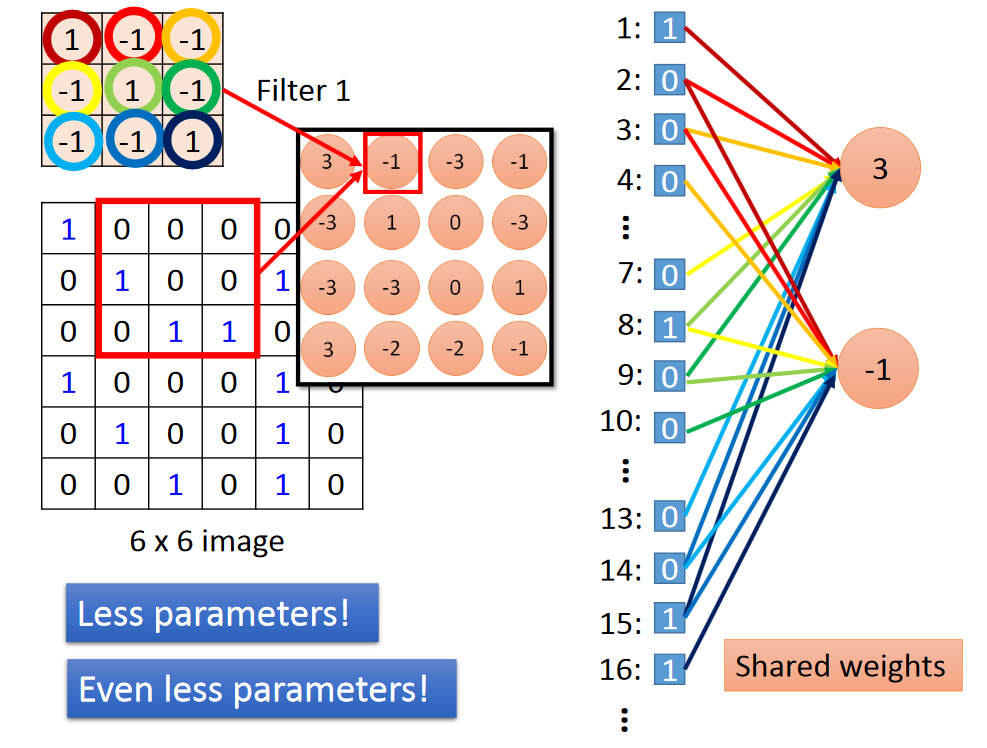
convolution 其实就是fully connected 去掉一些weight的结果。

filter内部的数值即为connect对应的权值weight。

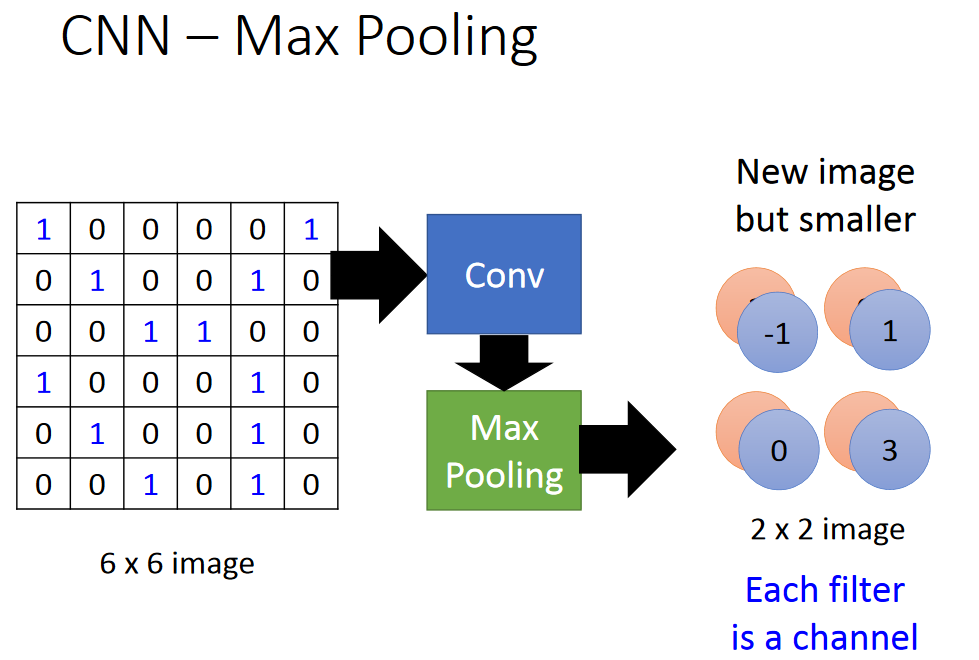
CNN – Max Pooling
将image缩小,分区,选取最大的。


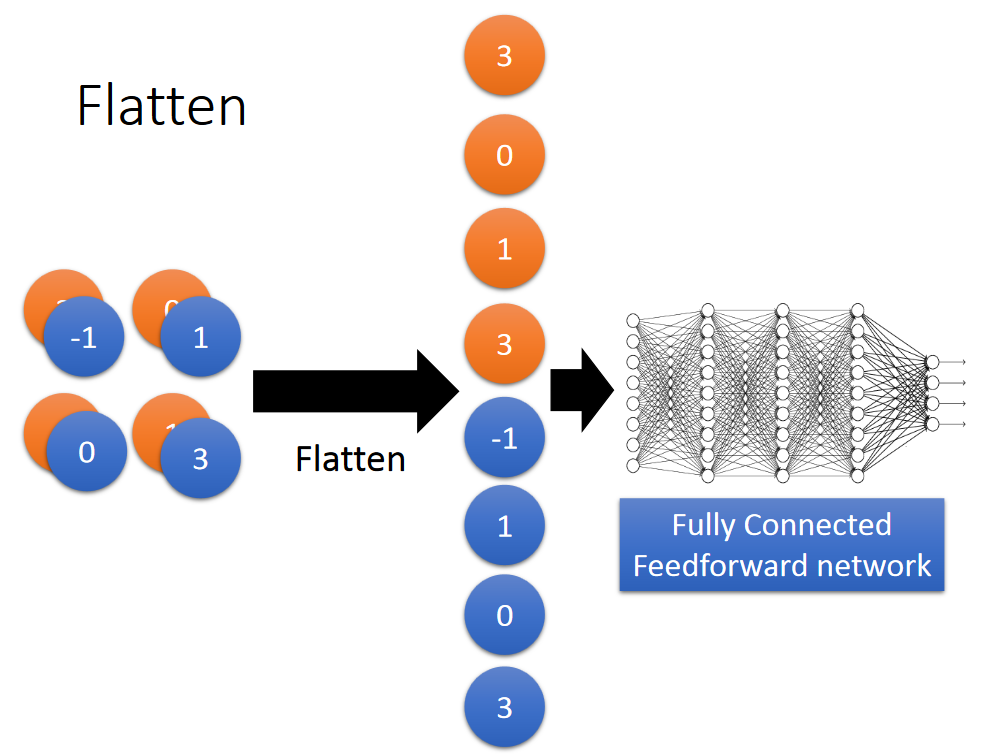
Flatten
flatten就是将数据拉直。
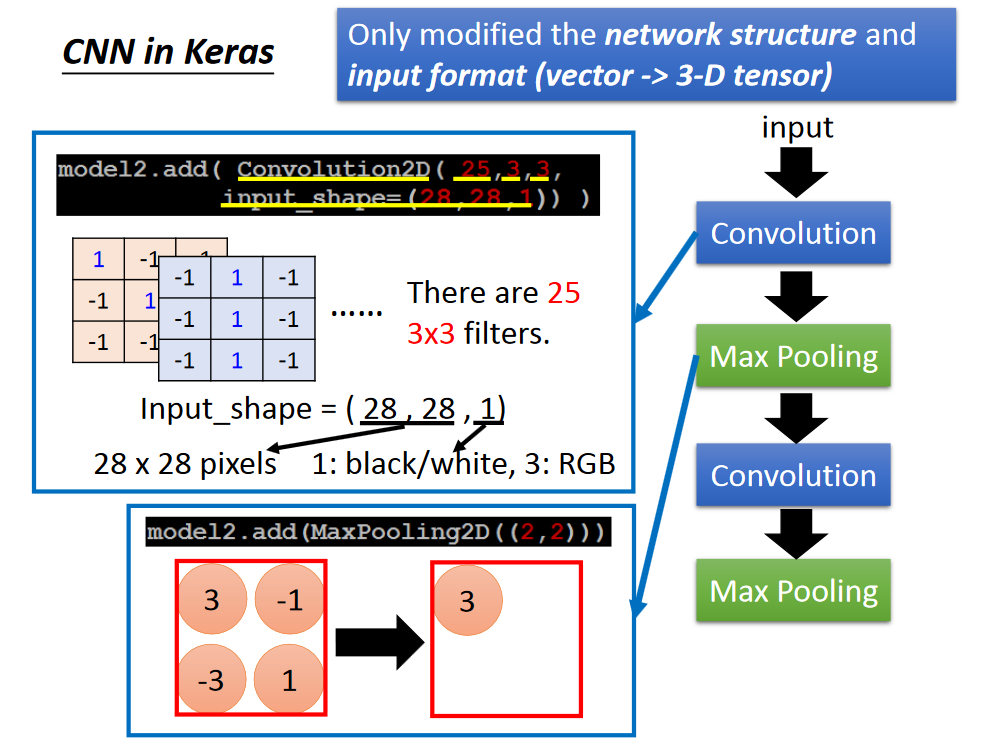
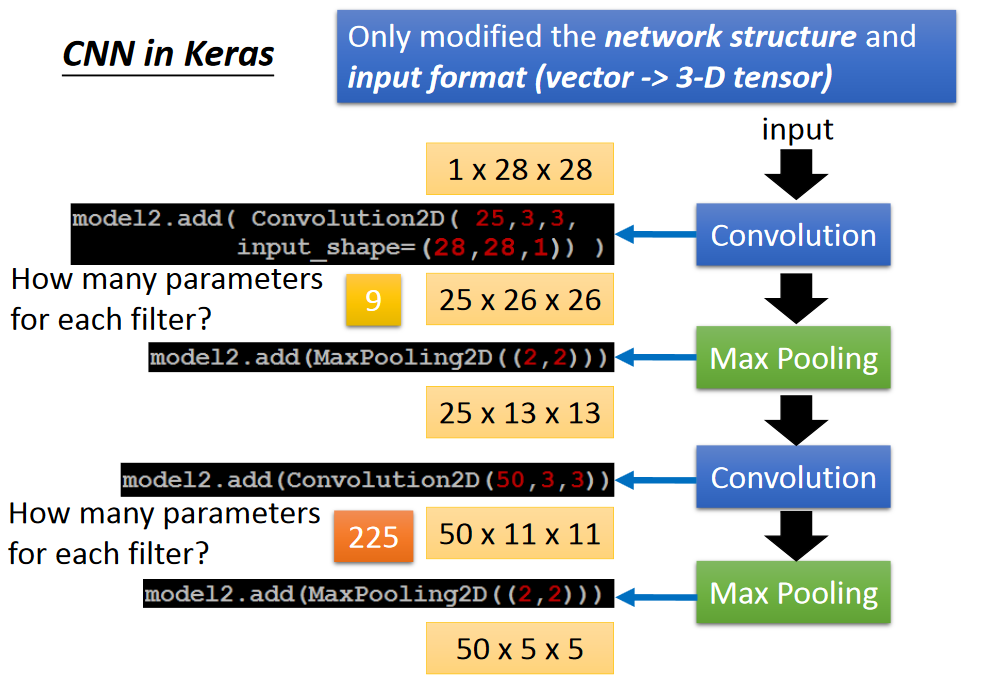
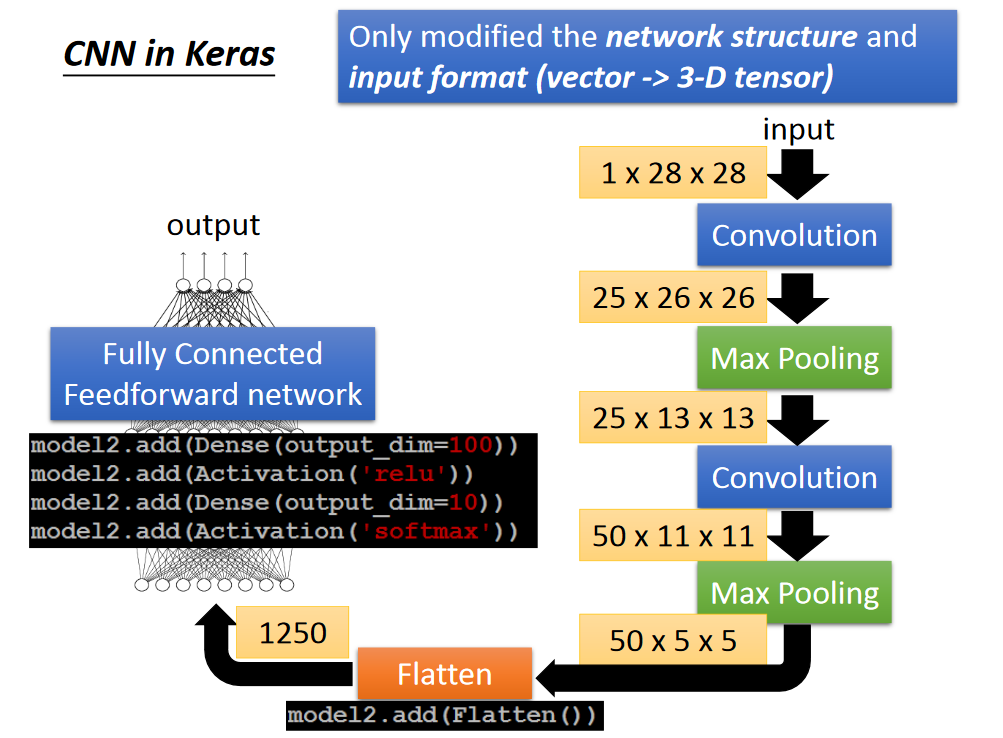
CNN in Keras
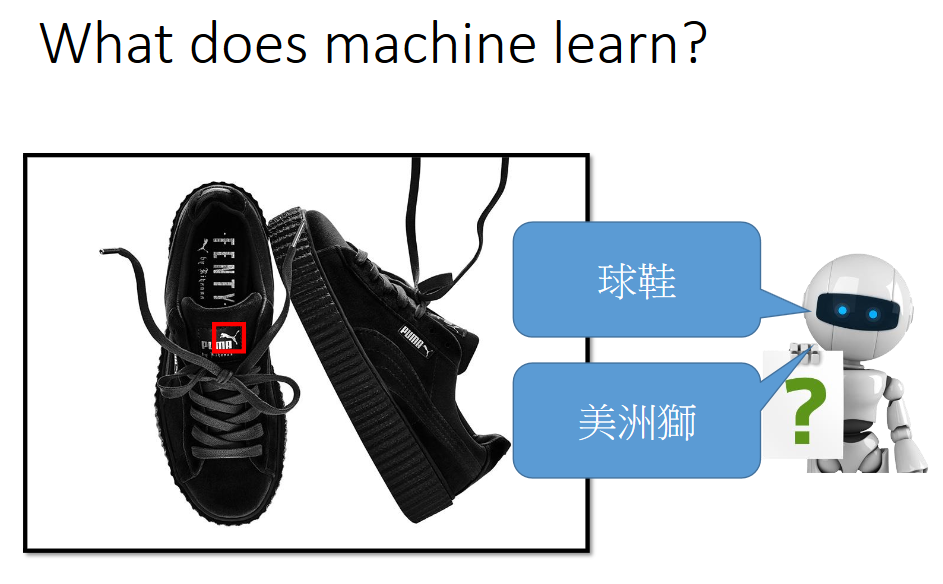
What does machine learn?


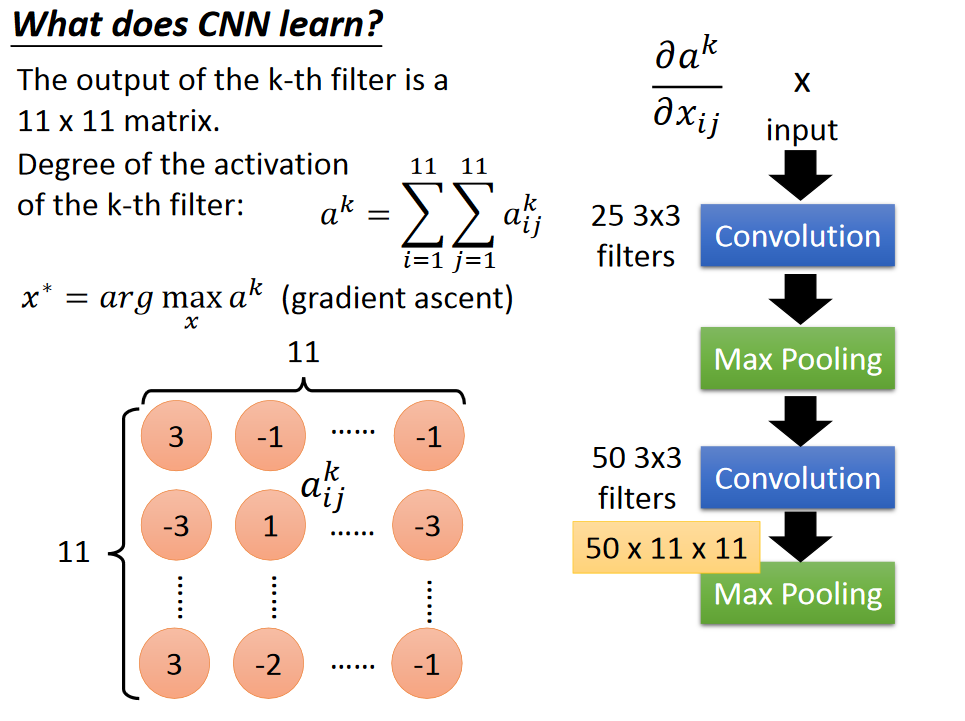
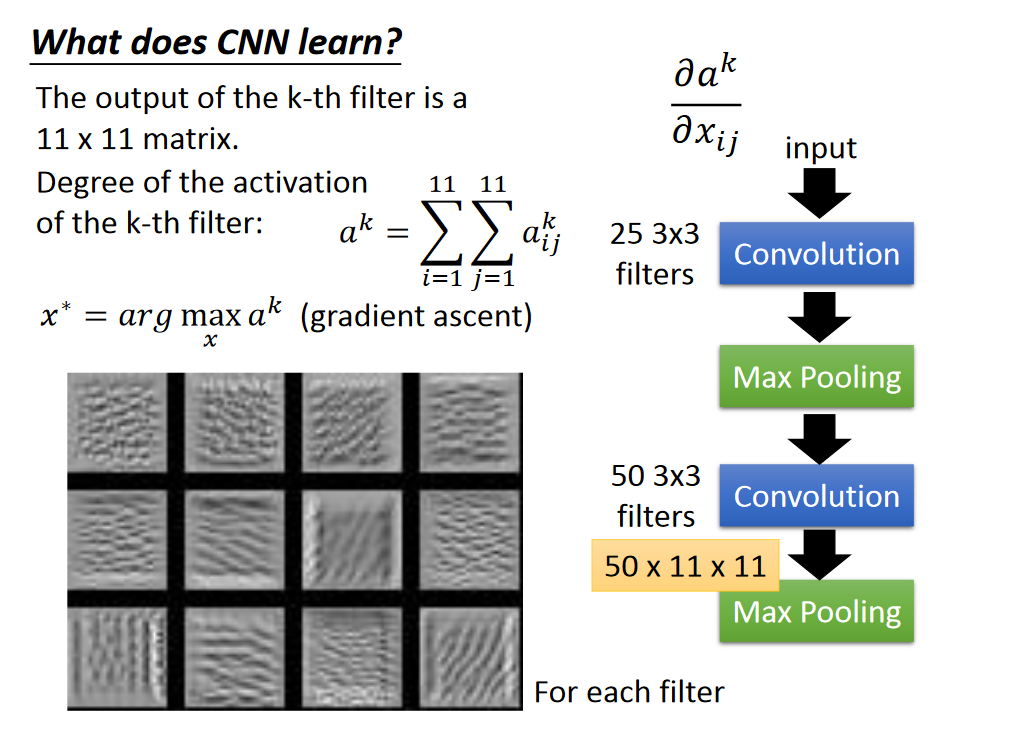
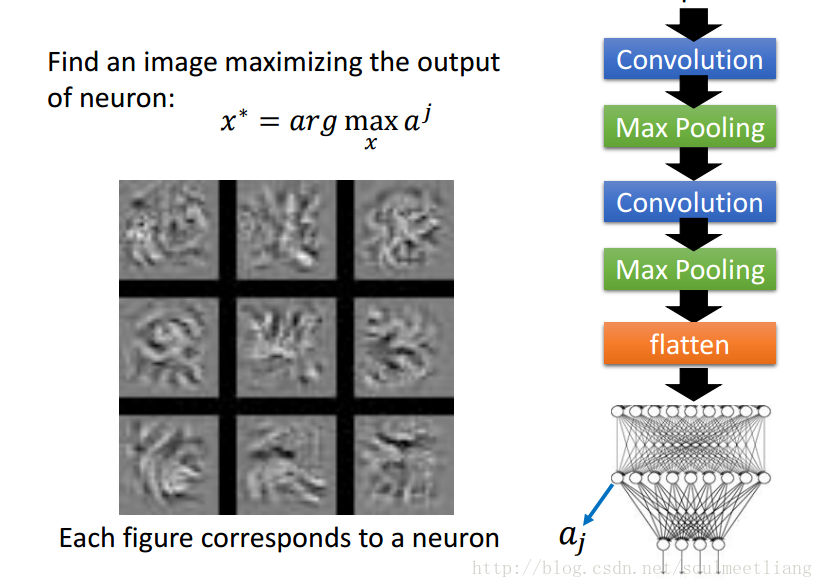
What does CNN learn?



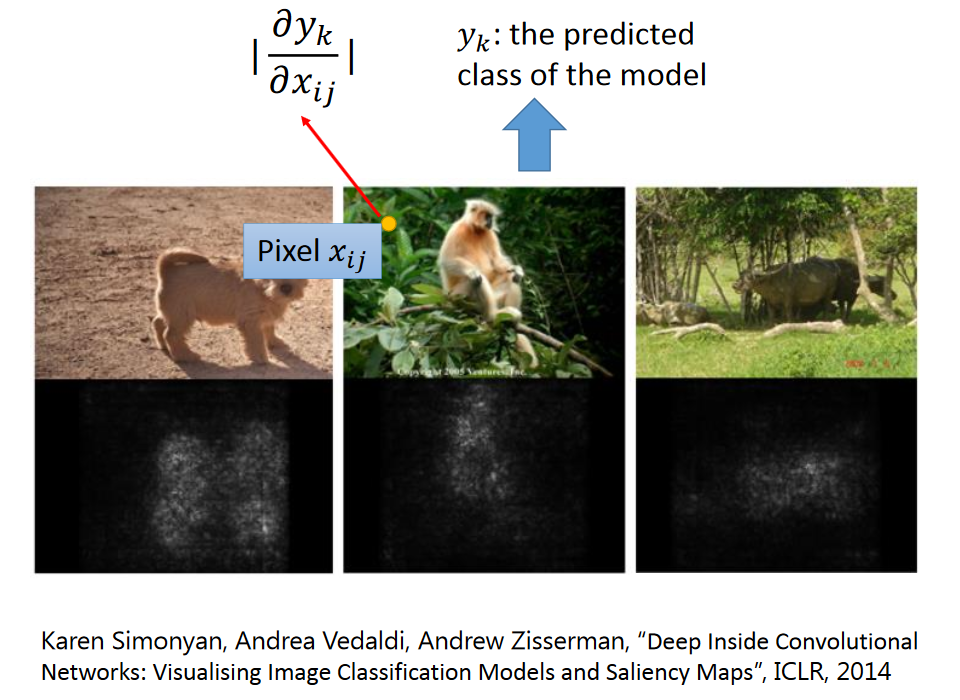

Deep Dream

将原本像某物的地方更加夸大。

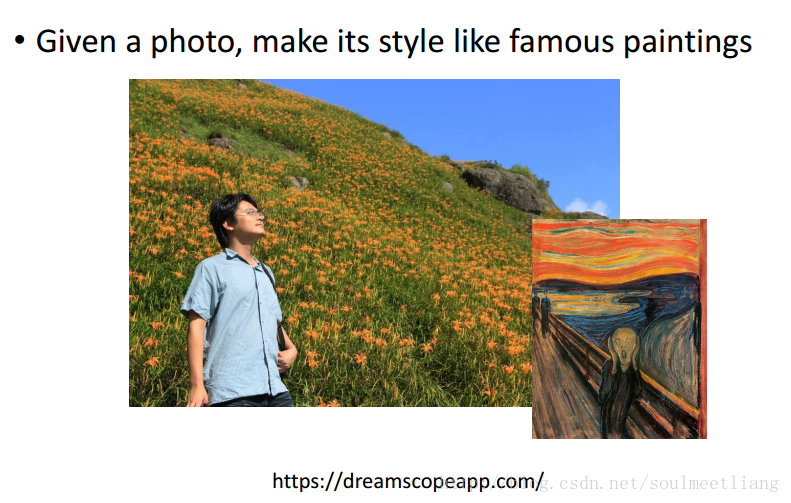
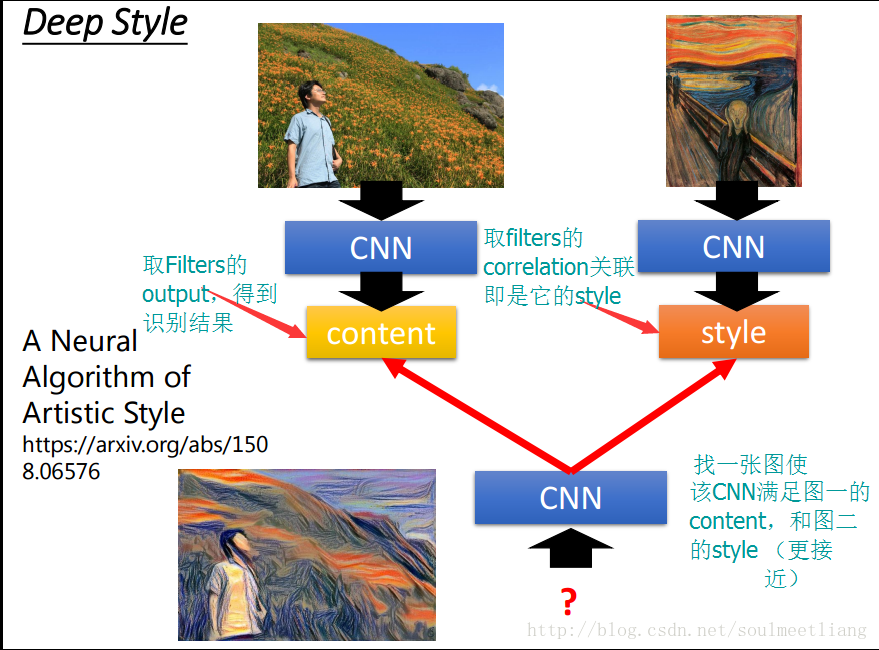
Deep style

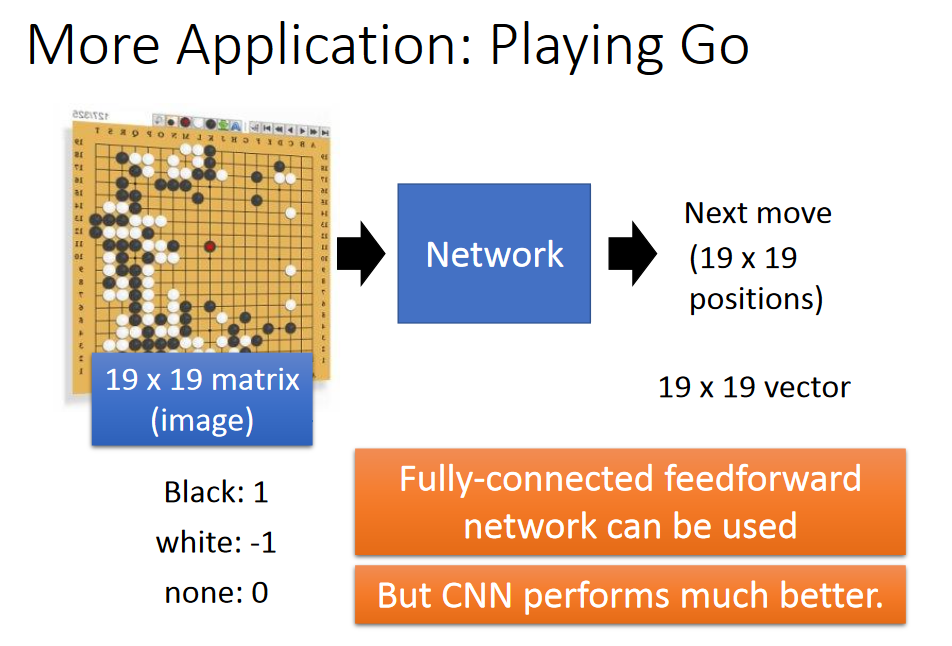
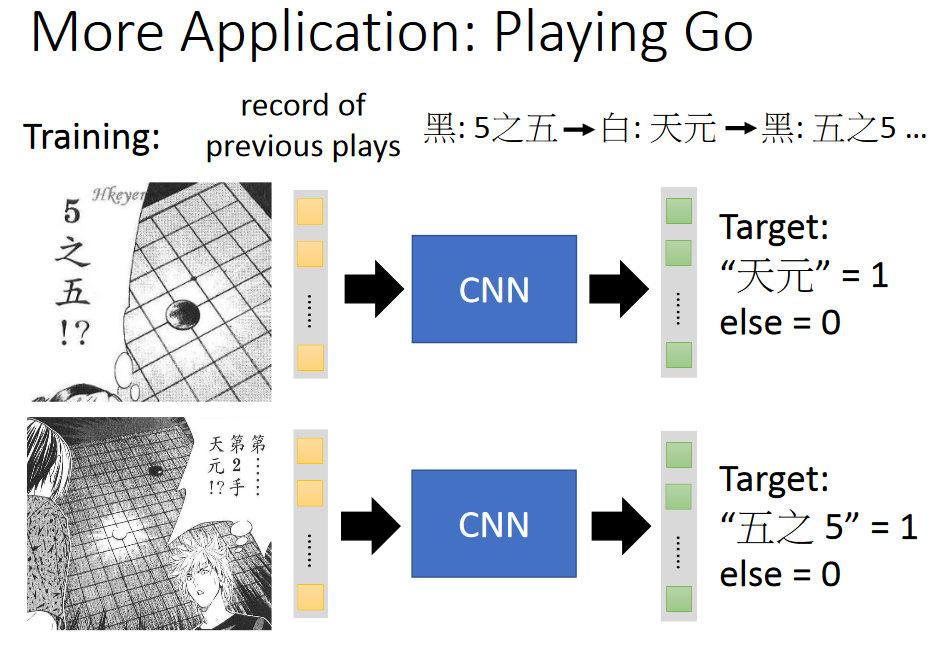
More Application--Playing Go


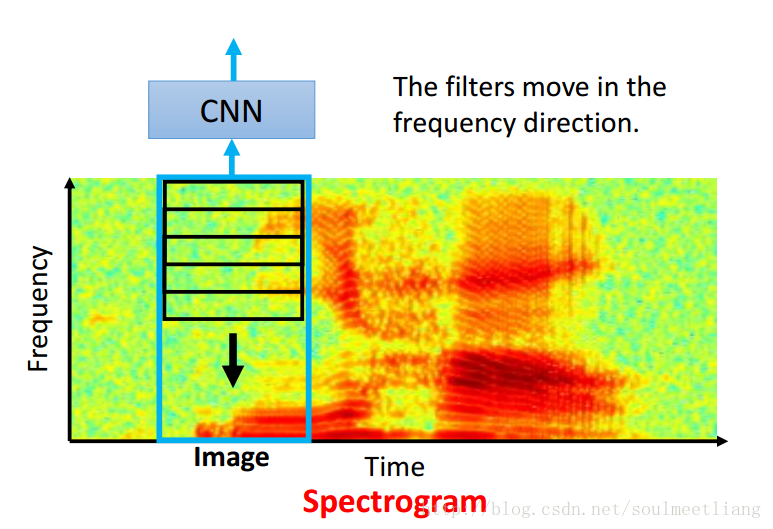
More Application---Speech
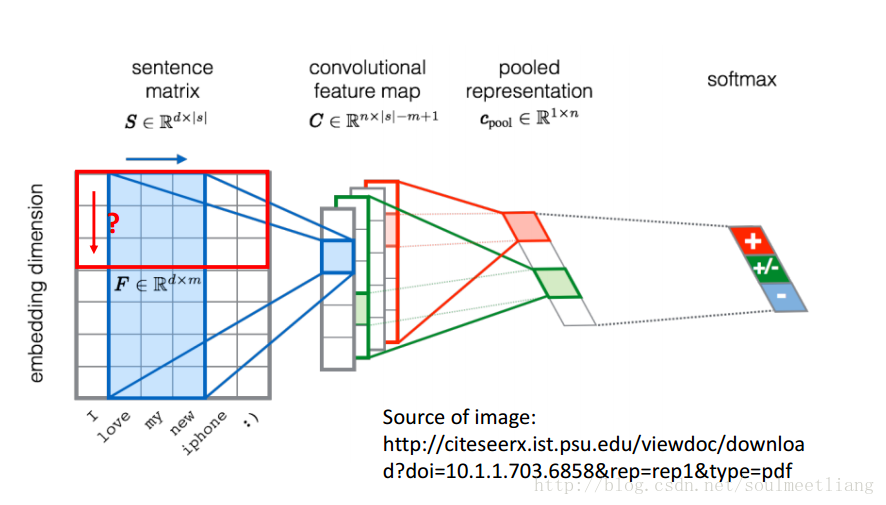
参考:https://blog.csdn.net/soulmeetliang/article/details/73188417

 浙公网安备 33010602011771号
浙公网安备 33010602011771号