机器学习---导学
一 机器学习的定义
1.1 机器学习概述
机器学习这个词是让人疑惑的,首先它是英文名称Machine Learning(简称ML)的直译,在计算界Machine一般指计算机。这个名字使用了拟人的手法,说明了这门技术是让机器“学习”的技术。但是计算机是死的,怎么可能像人类一样“学习”呢?
传统上如果我们想让计算机工作,我们给它一串指令,然后它遵照这个指令一步步执行下去。有因有果,非常明确。但这样的方式在机器学习中行不通。机器学习根本不接受你输入的指令,相反,它接受你输入的数据!
也就是说,机器学习是一种让计算机利用数据而不是指令来进行各种工作的方法。这听起来非常不可思议,但结果上却是非常可行的。“统计”思想将在你学习“机器学习”相关理念时无时无刻不伴随,相关而不是因果的概念将是支撑机器学习能够工作的核心概念。你会颠覆对你以前所有程序中建立的因果无处不在的根本理念。
机器学习与人类思考的经验过程是类似的(如下图所示),不过它能考虑更多的情况,执行更加复杂的计算。事实上,机器学习的一个主要目的就是把人类思考归纳经验的过程转化为计算机通过对数据的处理计算得出模型的过程。经过计算机得出的模型能够以近似于人的方式解决很多灵活复杂的问题。
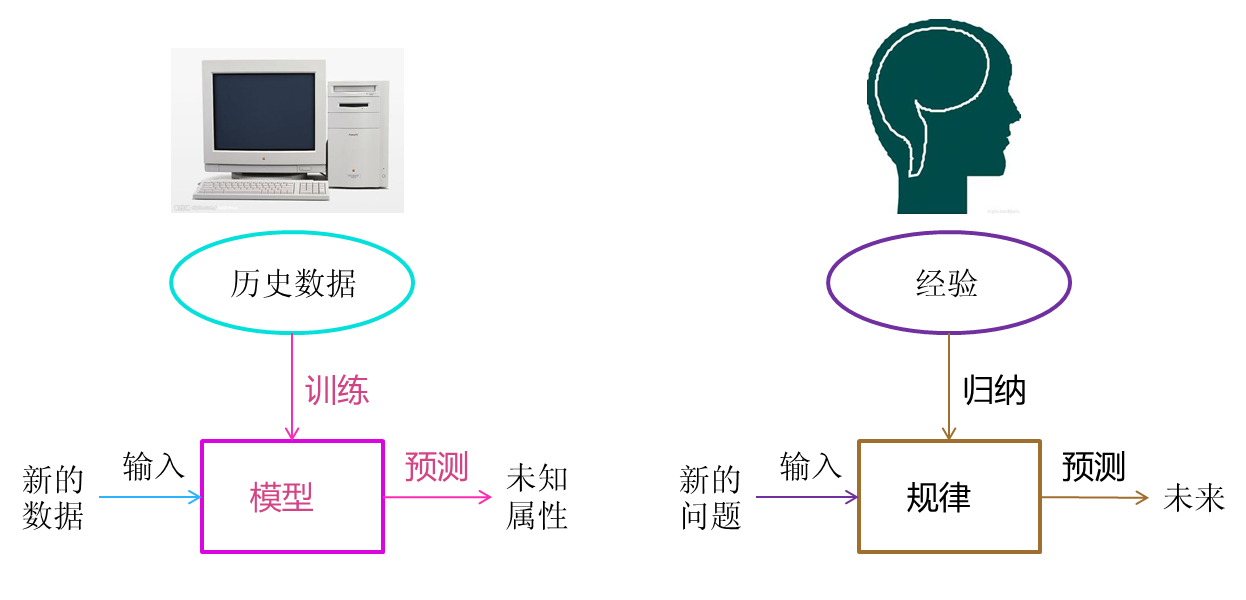
1.2 机器学习的定义
从广义上来说,机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。但从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。
二 机器学习范围
上文虽然说明了机器学习是什么,但是并没有给出机器学习的范围。其实,机器学习跟模式识别,统计学习,数据挖掘,计算机视觉,语音识别,自然语言处理等领域有着很深的联系。从范围上来说,机器学习跟模式识别,统计学习,数据挖掘是类似的,同时,机器学习与其他领域的处理技术的结合,形成了计算机视觉、语音识别、自然语言处理等交叉学科。因此,一般说数据挖掘时,可以等同于说机器学习。同时,我们平常所说的机器学习应用,应该是通用的,不仅仅局限在结构化数据,还有图像,音频等应用。下图是机器学习所牵扯的一些相关范围的学科与研究领域。

模式识别
模式识别=机器学习。两者的主要区别在于前者是从工业界发展起来的概念,后者则主要源自计算机学科。在著名的《Pattern
Recognition And Machine Learning》这本书中,Christopher M.
Bishop在开头是这样说的“模式识别源自工业界,而机器学习来自于计算机学科。不过,它们中的活动可以被视为同一个领域的两个方面,同时在过去的10年间,它们都有了长足的发展”。
数据挖掘
数据挖掘=机器学习+数据库。这几年数据挖掘的概念实在是太耳熟能详。几乎等同于炒作。但凡说数据挖掘都会吹嘘数据挖掘如何如何,例如从数据中挖出金子,以及将废弃的数据转化为价值等等。但是,我尽管可能会挖出金子,但我也可能挖的是“石头”啊。这个说法的意思是,数据挖掘仅仅是一种思考方式,告诉我们应该尝试从数据中挖掘出知识,但不是每个数据都能挖掘出金子的,所以不要神话它。一个系统绝对不会因为上了一个数据挖掘模块就变得无所不能(这是IBM最喜欢吹嘘的),恰恰相反,一个拥有数据挖掘思维的人员才是关键,而且他还必须对数据有深刻的认识,这样才可能从数据中导出模式指引业务的改善。大部分数据挖掘中的算法是机器学习的算法在数据库中的优化。
统计学习
统计学习近似等于机器学习。统计学习是个与机器学习高度重叠的学科。因为机器学习中的大多数方法来自统计学,甚至可以认为,统计学的发展促进机器学习的繁荣昌盛。例如著名的支持向量机算法,就是源自统计学科。但是在某种程度上两者是有分别的,这个分别在于:统计学习者重点关注的是统计模型的发展与优化,偏数学,而机器学习者更关注的是能够解决问题,偏实践,因此机器学习研究者会重点研究学习算法在计算机上执行的效率与准确性的提升。
计算机视觉
计算机视觉=图像处理+机器学习。图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责从图像中识别出相关的模式。计算机视觉相关的应用非常的多,例如百度识图、手写字符识别、车牌识别等等应用。这个领域是应用前景非常火热的,同时也是研究的热门方向。随着机器学习的新领域深度学习的发展,大大促进了计算机图像识别的效果,因此未来计算机视觉界的发展前景不可估量。
语音识别
语音识别=语音处理+机器学习。语音识别就是音频处理技术与机器学习的结合。语音识别技术一般不会单独使用,一般会结合自然语言处理的相关技术。目前的相关应用有苹果的语音助手siri等。
自然语言处理
自然语言处理=文本处理+机器学习。自然语言处理技术主要是让机器理解人类的语言的一门领域。在自然语言处理技术中,大量使用了编译原理相关的技术,例如词法分析,语法分析等等,除此之外,在理解这个层面,则使用了语义理解,机器学习等技术。作为唯一由人类自身创造的符号,自然语言处理一直是机器学习界不断研究的方向。按照百度机器学习专家余凯的说法“听与看,说白了就是阿猫和阿狗都会的,而只有语言才是人类独有的”。如何利用机器学习技术进行自然语言的的深度理解,一直是工业和学术界关注的焦点。
可以看出机器学习在众多领域的外延和应用。机器学习技术的发展促使了很多智能领域的进步,改善着我们的生活。
三 机器学习的分类
从机器学习解决的问题上分类
(1)分类:二分类,多分类,多标签分类
(2)回归:一般情况下,回归任务可以简化成分类任务
从机器学习的算法上分类
(1)监督学习:k近邻,线性回归....
(2)非监督学习
聚类分析:对没有标记的数据进行分类。
降维处理:特征提取,特征压缩(了解pca)----降维处理的意义:方便可视化
异常检查:
(3)半监督学习:一部分数据有标记或者答案,另一部分数据没有
更常见:各种原因产生的标记缺失
处理:先进行无监督的学习,然后通过监督学习建立模型
(4)增强学习:根据周围的环境情况,采取行动,根据采取行动的结果学习行动方式
应用:无人驾驶,机器人.....
机器学习的其他分类
(1)批量学习(batch learning)与在线学习(online learning)
批量学习又叫离线学习:
优点:简单
缺点:
- 每次重新批量学习,运算量巨大
- 在某些环境变化非常快的情况下,甚至是不可能的
问题:如何适应新环境的变化?
解决方案:定时批量学习。
在线学习:
优点:及时反映新的环境变化
问题:新的数据带来不好的变化?
解决方案:需要加强对数据进行监控(非监督学习的异常处理)
其他:也合适数据量巨大,完全无法批量学习的环境
(2)参数学习与非参数学习
参数学习:一旦学到了参数,就不在需要原有的数据集
非参数学习:不对模型进行过多的假设。
注:非参数学习不等于没有参数。
参考:https://www.cnblogs.com/subconscious/p/4107357.html#eight

 浙公网安备 33010602011771号
浙公网安备 33010602011771号