python---面向对象
一 概述
1.1 编程方式
首先介绍三种编程方式:
- 面向过程:根据业务逻辑从上到下写垒代码
- 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
- 面向对象:对函数进行分类和封装,让开发“更快更好更强...”
面向过程编程最易被初学者接受,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,即:将之前实现的代码块复制到现需功能处。随着时间的推移,开始使用了函数式编程,增强代码的重用性和可读性。今天我们来学习一种新的编程方式:面向对象编程(Object Oriented Programming,OOP,面向对象程序设计)。
注:java和c#只支持面向对象编程,而python比较灵活即支持面向对象编程也支持函数式编程。
1.2 创建类和对象
面向对象编程需要使用 “类” 和 “对象” 来实现,因此,面向对象编程其实就是对 “类” 和 “对象” 的使用。
- 类就是一个模板,模板里可以包含多个函数,函数里实现一些功能
- 对象则是根据模板创建的实例,通过实例对象可以执行类中的函数
创建类和对象格式如下:

注意点:
- class是关键字,表示类
- 创建对象,类名称后加括号即可
- 类中的函数第一个参数必须是self(详细见:类的三大特性之封装),类中定义的函数叫做方法
例子:
# 创建类 class Foo: def Bar(self): print ('Bar') def Hello(self, name): print ('i am %s' %name) # 根据类Foo创建对象obj obj = Foo() obj.Bar() #执行Bar方法 obj.Hello('Terry') #执行Hello方法 >>>Bar >>>i am Terry
当写完上述的代码,你是不是有这样的疑问?利用面向对象编程方式来执行一个“方法”时比使用函数式编程要复杂,即:
- 面向对象:【创建对象】【通过对象执行方法】
- 函数编程:【执行函数】
既然这样,那我们为什么要使用面向对象编程呢?那是因为不同的编程方式适合不同的场景,当应用于某一场景时,面向对象相对于函数式编程要简单的多(见封装的例子)。
总结:函数式编程的应用场景 --> 各个函数之间是独立且无共用的数据
二 面向对象的三大特性
封装、继承和多态是面向对象的三大特性,下边详细介绍:
2.1 封装
封装,顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容。所以,在使用面向对象的封装特性时,需要:(1)将内容封装到某处(2)从某处调用被封装的内容
(1)将内容封装到某处
#创建类 class foo: def __init__(self,name,age): #称为构造方法,当根据类创造对象时自动执行 self.name=name self.age=age #根据类foo创建对象 #自动执行foo类的__init__方法 obj1=foo("liuxiaohui",18) #将liuxiaohui和18分别封装到obj1和self的name,age中 #根据类foo创建对象 #自动执行foo类的__init__方法 obj2=foo("Terry",18) #将liuxiaohui和18分别封装到obj2和self的name,age中
self 是一个形式参数,当执行 obj1 = Foo('liuxiaohui', 18 ) 时,self 等于 obj1
当执行 obj2 = Foo('Terry', 18 ) 时,self 等于 obj2
所以,内容其实被封装到了对象 obj1 和 obj2 中,每个对象中都有 name 和 age 属性,在内存里类似于下图来保存。
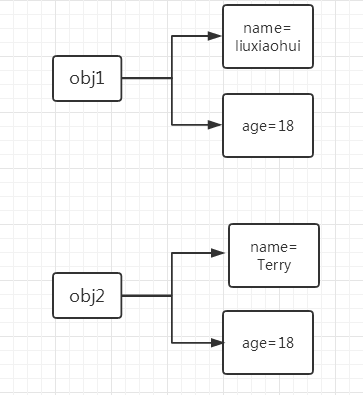
(2)从某处调用被封装的内容
调用被封装的内容时,有两种方法: 1.通过对象直接调用 2.通过self间接调用
1 通过对象直接调用
上图展示了对象 obj1 和 obj2 在内存中保存的方式,根据保存格式可以如此调用被封装的内容:对象.属性名。
#创建类 class foo: def __init__(self,name,age): #称为构造方法,当根据类创造对象时自动执行 self.name=name self.age=age #根据类foo创建对象 #自动执行foo类的__init__方法 obj1=foo("liuxiaohui",18) #将liuxiaohui和18分别封装到obj1和self的name,age中 #根据类foo创建对象 #自动执行foo类的__init__方法 obj2=foo("Terry",18) #将liuxiaohui和18分别封装到obj2和self的name,age中 print(obj1.name,obj1.age) print(obj2.name,obj2.age) >>>liuxiaohui 18 >>>Terry 18
2.通过self间接调用
class Foo: def __init__(self, name, age): self.name = name self.age = age def detail(self): print (self.name) print (self.age) obj1 = Foo('liuxiaohui', 18) obj1.detail() # Python默认会将obj1传给self参数,即:obj1.detail(obj1),所以,此时方法内部的 self = obj1,即:self.name 是 liuxiaohui ;self.age 是 18 obj2 = Foo('Terry', 18) obj2.detail() # Python默认会将obj2传给self参数,即:obj1.detail(obj2),所以,此时方法内部的 self = obj2,即:self.name 是 Terry ; self.age 是 18 >>>liuxiaohui >>>18 >>>Terry >>>18
总结:对于面向对象的封装来说,其实就是使用构造方法将内容封装到 对象 中,然后通过对象直接或者self间接获取被封装的内容。
例子:在终端输出如下信息
- 小明,10岁,男,上山去砍柴
- 小明,10岁,男,开车去东北
- 小明,10岁,男,最爱大保健
- 老李,90岁,男,上山去砍柴
- 老李,90岁,男,开车去东北
- 老李,90岁,男,最爱大保健
- 老张...


def kanchai(name, age, gender): print ("%s,%s岁,%s,上山去砍柴" %(name, age, gender)) def qudongbei(name, age, gender): print ("%s,%s岁,%s,开车去东北" %(name, age, gender)) def dabaojian(name, age, gender): print ("%s,%s岁,%s,最爱去追梦" %(name, age, gender)) kanchai('小明', 10, '男') qudongbei('小明', 10, '男') dabaojian('小明', 10, '男') kanchai('老李', 90, '男') qudongbei('老李', 90, '男') dabaojian('老李', 90, '男') >>>小明,10岁,男,上山去砍柴 >>>小明,10岁,男,开车去东北 >>>小明,10岁,男,最爱去追梦 >>>老李,90岁,男,上山去砍柴 >>>老李,90岁,男,开车去东北 >>>老李,90岁,男,最爱去追梦
class Foo: def __init__(self, name, age ,gender): self.name = name self.age = age self.gender = gender def kanchai(self): print ("%s,%s岁,%s,上山去砍柴" %(self.name, self.age, self.gender)) def qudongbei(self): print ("%s,%s岁,%s,开车去东北" %(self.name, self.age, self.gender)) def dabaojian(self): print ("%s,%s岁,%s,最爱去追梦" %(self.name, self.age, self.gender)) xiaoming = Foo('小明', 10, '男') xiaoming.kanchai() xiaoming.qudongbei() xiaoming.dabaojian() laoli = Foo('老李', 90, '男') laoli.kanchai() laoli.qudongbei() laoli.dabaojian() >>>小明,10岁,男,上山去砍柴 >>>小明,10岁,男,开车去东北 >>>小明,10岁,男,最爱去追梦 >>>老李,90岁,男,上山去砍柴 >>>老李,90岁,男,开车去东北 >>>老李,90岁,男,最爱去追梦
通过上述对比可以看出,如果使用函数式编程,需要在每次执行函数时传入相同的参数,如果参数多的话,又需要粘贴复制了... ;而对于面向对象只需要在创建对象时,将所有需要的参数封装到当前对象中,之后再次使用时,通过self间接去当前对象中取值即可。
2.2 继承
2.2.1 概述
面向对象中的继承和现实生活中的继承相同,即:子可以继承父的内容。其实质就是将多个类共有的方法提取到父类中,子类仅需继承父类而不必一一实现每个方法。除了子类和父类的称谓,你可能看到过 派生类 和 基类 ,他们与子类和父类只是叫法不同而已。
简单继承的伪代码如图所示:

例子:
class Animal: def eat(self): print ("%s 吃 " %self.name) def drink(self): print ("%s 喝 " %self.name) def shit(self): print ("%s 拉 " %self.name) def pee(self): print ("%s 撒 " %self.name) class Cat(Animal): def __init__(self, name): self.name = name self.breed ='猫' def cry(self): print ('喵喵叫') class Dog(Animal): def __init__(self, name): self.name = name self.breed = '狗' def cry(self): print ('汪汪叫') c1 = Cat('小黑猫') c1.eat() c2 = Cat('小白猫') c2.drink() c2.cry() d1 = Dog('二哈') d1.eat() d1.cry() >>>小黑猫 吃 >>>小白猫 喝 >>>喵喵叫 >>>二哈 吃 >>>汪汪叫
2.2.2 多继承
在讲多继承时,先思考两个问题:
- 是否可以继承多个类
- 如果继承的多个类每个类中都定了相同的函数,那么那一个会被使用呢?
answer:
1 Python的类可以继承多个类,Java和C#中则只能继承一个类
2 Python的类如果继承了多个类,那么其寻找方法的方式有两种,分别是:深度优先和广度优先

- 当类是经典类时,多继承情况下,会按照深度优先方式查找
- 当类是新式类时,多继承情况下,会按照广度优先方式查找
经典类和新式类,从字面上可以看出一个老一个新,新的必然包含了跟多的功能,也是之后推荐的写法,从写法上区分的话,如果 当前类或者父类继承了object类,那么该类便是新式类,否则便是经典类。

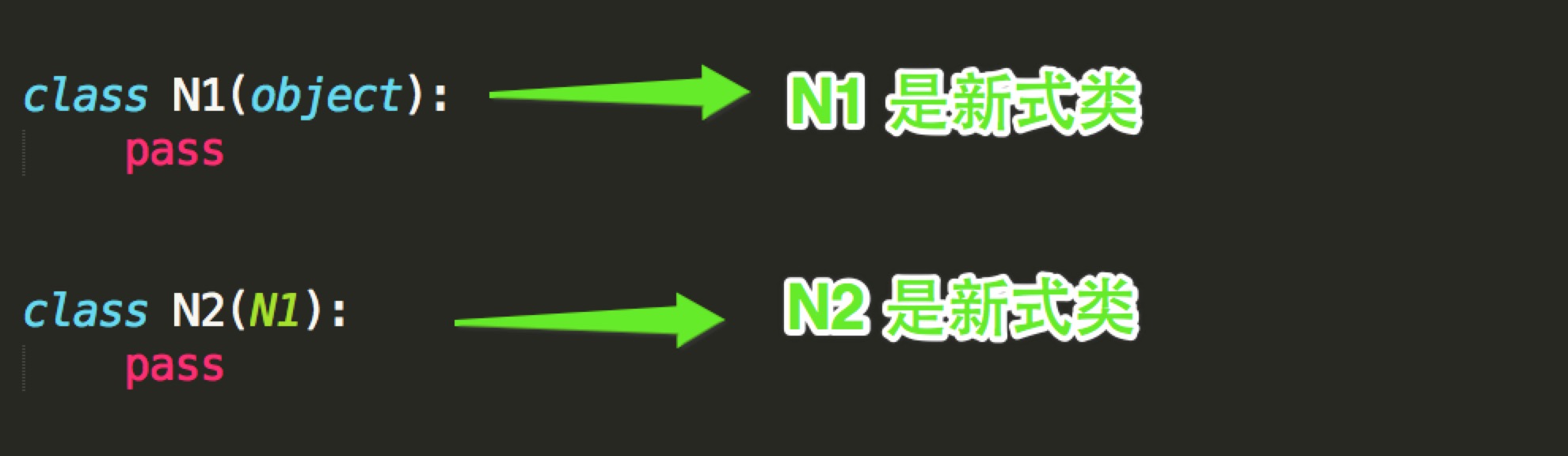
注意:在上述查找过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
2.3 多态
Pyhon原生多态,不支持Java和C#这一类强类型语言中多态的写法。
三 类的成员
类的成员可以分为三大类:字段、方法和属性。
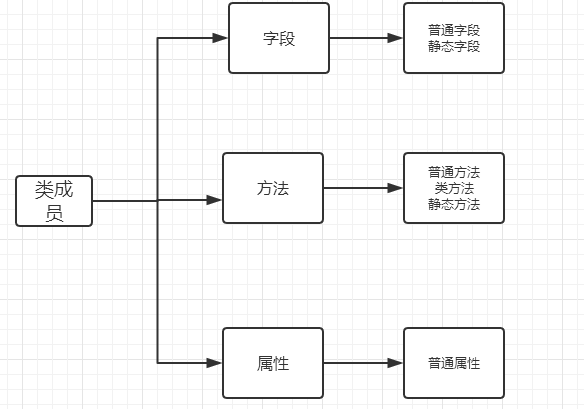
注:所有成员中,只有普通字段的内容保存对象中,即:根据此类创建了多少对象,在内存中就有多少个普通字段。而其他的成员,则都是保存在类中,即:无论对象的多少,在内存中只创建一份。
3.1 字段
字段包括:普通字段和静态字段,他们在定义和使用中不同,最本质的区别是在内存中保存的位置不同,
- 普通字段属于对象
- 静态字段属于类
class Province: # 静态字段 country = '中国' def __init__(self, name): # 普通字段 self.name = name # 直接访问普通字段 obj = Province('河北省') print (obj.name) # 直接访问静态字段 print(Province.country) >>>河北省 >>>中国
通过上述代码可以看出【普通字段需要通过对象来访问】【静态字段通过类访问】,在使用上可以看出普通字段和静态字段的归属是不同的。其内容的存储方式类似如下图: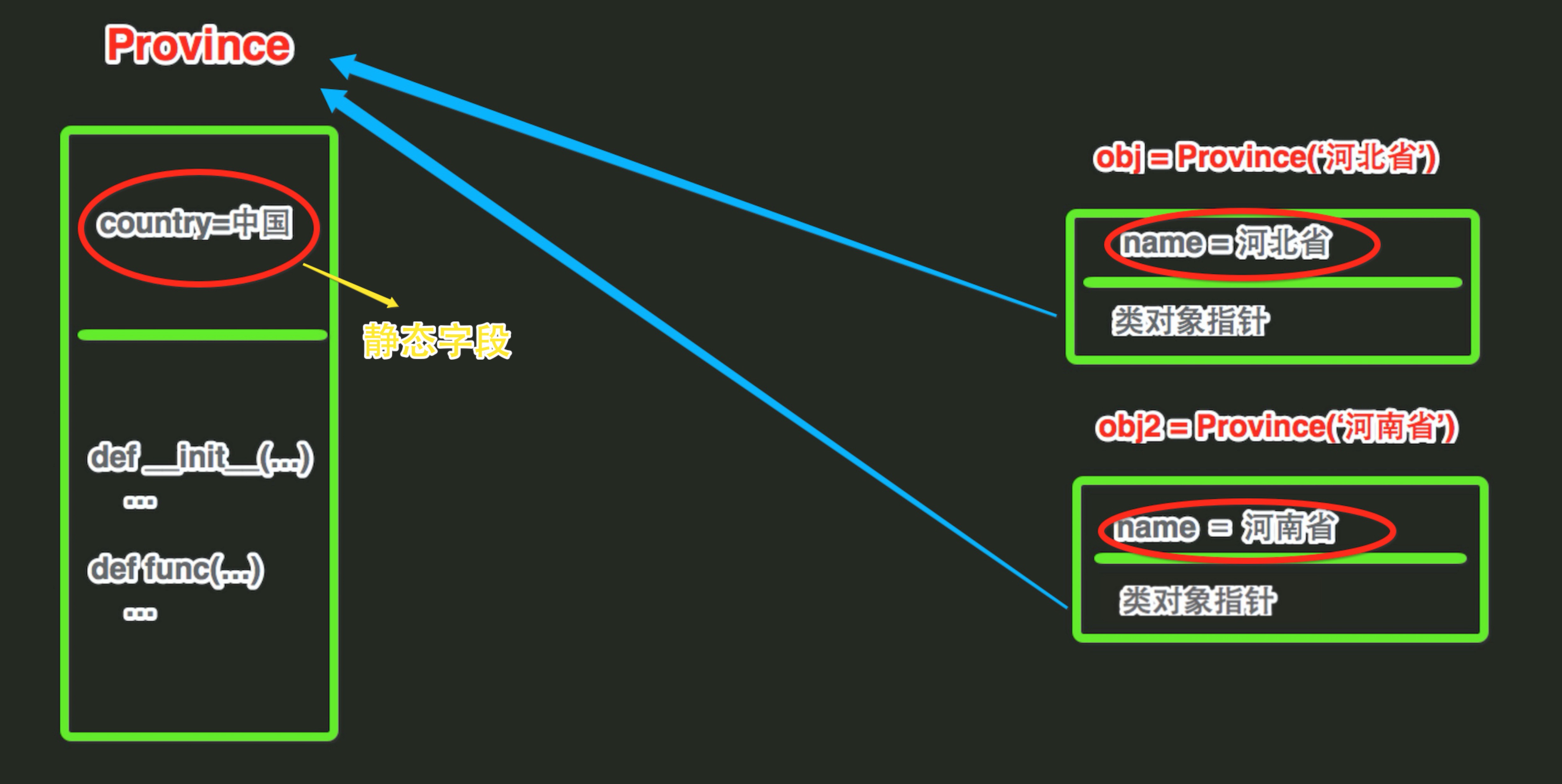
由上图可以看出:
- 静态字段在内存中只保存一份
- 普通字段在每个对象中都要保存一份
应用场景: 通过类创建对象时,如果每个对象都具有相同的字段,那么就使用静态字段
3.2 方法
类成员中的方法包括:普通方法、类方法和静态方法,三种方法在内存中都归属于类,区别在于调用方式不同。
- 普通方法:由对象调用;至少一个self参数;执行普通方法时,自动将调用该方法的对象赋值给self;
- 类方法:由类调用; 至少一个cls参数;执行类方法时,自动将调用该方法的类复制给cls;
- 静态方法:由类调用;无默认参数;
class Foo: def __init__(self, name): self.name = name def ord_func(self): #定义普通方法,至少有一个self参数 print (self.name) print ('普通方法') @classmethod def class_func(cls): #定义类方法,至少有一个cls参数 print ('类方法') @staticmethod def static_func(): #定义静态方法 ,无默认参数 print ('静态方法') # 调用普通方法 f = Foo('Terry') f.ord_func() # 调用类方法 Foo.class_func() # 调用静态方法 Foo.static_func() >>>Terry >>>普通方法 >>>类方法 >>>静态方法
总结:
相同点:对于所有的方法而言,均属于类(非对象)中,所以,在内存中也只保存一份。
不同点:方法调用者不同、调用方法时自动传入的参数不同。
3.3 属性
如果你已经了解python类中的方法,那么属性就非常简单了,因为Python中的属性其实是普通方法的变种。
3.3.1 属性的定义
属性的定义有两种方式:
- 装饰器 即:在类的普通方法上应用装饰器
- 静态字段 即:在类中定义值为property对象的静态字段
(1)装饰器方式
经典类,具有一种@property装饰器。
class Goods: @property def price(self): return "Terry" # ############### 调用 ############### obj = Goods() result = obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值 print(result) >>>Terry
新式类,具有三种@property装饰器。
class Goods(object): @property def price(self): print ('@property') @price.setter def price(self, value): print ('@price.setter') @price.deleter def price(self): print ('@price.deleter') # ############### 调用 ############### obj = Goods() obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值 obj.price = 123 # 自动执行 @price.setter 修饰的 price 方法,并将 123 赋值给方法的参数 del obj.price # 自动执行 @price.deleter 修饰的 price 方法 >>>@property >>>@price.setter >>>@price.deleter
注:
- 经典类中的属性只有一种访问方式,其对应被 @property 修饰的方法
- 新式类中的属性有三种访问方式,并分别对应了三个被@property、@方法名.setter、@方法名.deleter修饰的方法
(2)静态字段方式
当使用静态字段的方式创建属性时,经典类和新式类无区别。
简单的例子:
class Foo: def get_bar(self): return 'Terry' BAR = property(get_bar) obj = Foo() reuslt = obj.BAR # 自动调用get_bar方法,并获取方法的返回值 print (reuslt) >>>Terry
property的构造方法中有个四个参数
- 第一个参数是方法名,调用
对象.属性时自动触发执行方法 - 第二个参数是方法名,调用
对象.属性 = XXX时自动触发执行方法 - 第三个参数是方法名,调用
del 对象.属性时自动触发执行方法 - 第四个参数是字符串,调用
对象.属性.__doc__,此参数是该属性的描述信息
class Foo: def get_bar(self): return 'Terry' # 必须两个参数 def set_bar(self, value): return 'set value' + value def del_bar(self): return 'Terrt' BAR = property(get_bar, set_bar, del_bar, 'description...') obj = Foo() ret=obj.BAR # 自动调用第一个参数中定义的方法:get_bar print(ret) obj.BAR = "haha" # 自动调用第二个参数中定义的方法:set_bar方法,并将“haha”当作参数传入 del obj.BAR # 自动调用第三个参数中定义的方法:del_bar方法 obj.BAR.__doc__ # 自动获取第四个参数中设置的值:description...
注:Python WEB框架 Django 的视图中 request.POST 就是使用的静态字段的方式创建的属性。
四 成员修饰符
我们在第三章已经对类的每一个成员都做了详细的介绍,对其中每一个类的成员而言都有两种形式:
- 公有成员,在任何地方都能访问
- 私有成员,只有在类的内部才能方法
4.1 定义的不同
私有成员命名时,前两个字符是下划线。(特殊成员除外,例如:__init__、__call__、__dict__等)
class C: def __init__(self): self.name = '公有字段' self.__foo = "私有字段"
4.2 访问限制不同
静态字段
- 公有静态字段:类可以访问;类内部可以访问;派生类中可以访问。
- 私有静态字段:仅类内部可以访问。
class C: name = "公有静态字段" def func(self): print (C.name) class D(C): def show(self): print (C.name) ret=C.name # 类访问 print(ret) obj = C() obj.func() # 类内部可以访问 obj_son = D() obj_son.show() # 派生类中可以访问 >>>公有静态字段 >>>公有静态字段 >>>公有静态字段
class C: __name = "私有静态字段" def func(self): print (C.__name) class D(C): def show(self): print (C.__name) C.__name # 类访问 obj = C() obj.func() # 类内部可以访问 obj_son = D() obj_son.show() # 派生类访问 >>>AttributeError: type object 'C' has no attribute '__name' >>>私有静态字段 >>>AttributeError: type object 'C' has no attribute '_D__name'
普通字段
- 公有普通字段:对象可以访问;类内部可以访问;派生类中可以访问。
- 私有普通字段:仅类内部可以访问。
class C: def __init__(self): self.foo = "公有字段" def func(self): print (self.foo) # 类内部访问 class D(C): def show(self): print (self.foo) #派生类的访问 obj = C() #实例化对象 ret=obj.foo # 通过对象访问 print(ret) obj.func() # 类内部访问 obj_son = D() obj_son.show() # 派生类中访问 公有字段 公有字段 公有字段
class C: def __init__(self): self.__foo = "私有字段" def func(self): print (self.__foo) # 类内部访问 class D(C): def show(self): print (self.__foo) #派生类的访问 obj = C() #实例化对象 ret=obj.foo # 通过对象访问 print(ret) obj.func() # 类内部访问 obj_son = D() obj_son.show() # 派生类中访问 >>>AttributeError: 'C' object has no attribute 'foo' >>>私有字段 >>>AttributeError: 'D' object has no attribute '_D__foo'
注:(1)方法、属性的访问于上述方式相似,即:私有成员只能在类内部使用。
(2)如果想要强制访问私有字段,可以通过 【对象._类名__私有字段明 】访问(如:obj._C__foo),不建议强制访问私有成员。
(3)非要访问私有属性的话,可以通过 对象._类__属性名。
五 类的特殊成员
上文介绍了Python的类成员以及成员修饰符,从而了解到类中有字段、方法和属性三大类成员,并且成员名前如果有两个下划线,则表示该成员是私有成员,私有成员只能由类内部调用。无论人或事物往往都有不按套路出牌的情况,Python的类成员也是如此,存在着一些具有特殊含义的成员,详情如下:
1. __doc__
表示类的描述信息
class Foo: "这是类的描述信息" def func(self): pass print (Foo.__doc__) >>>这是类的描述信息
2. __module__ 和 __class__
__module__ 表示当前操作的对象在那个模块
__class__ 表示当前操作的对象的类是什么
#test1文件下: class C: def __init__(self): self.name = 'Terry'
#test文件下 from test1 import C obj = C() print (obj.__module__) # 输出test1,即:输出模块 print (obj.__class__) # 输出 test1.C,即:输出类 >>>test1 >>><class 'test1.C'>
3. __init__
构造方法,通过类创建对象时,自动触发执行。
class Foo: def __init__(self, name): self.name = name self.age = 18 print(self.name,self.age) obj = Foo('Terry') # 自动执行类中的 __init__ 方法 Terry 18
4. __del__
析构方法,当对象在内存中被释放时,自动触发执行。
注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以,析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。
class Foo: def __del__(self): pass
5. __call__
对象后面加括号,触发执行。
注:构造方法的执行是由创建对象触发的,即:对象 = 类名() ;而对于 __call__ 方法的执行是由对象后加括号触发的,即:对象() 或者 类()()
class Foo: def __init__(self): print('__init__') def __call__(self, *args, **kwargs): print ('__call__') obj = Foo() # 执行 __init__ obj() # 执行 __call__ >>>__init__ >>>__call__
6. __dict__
类或对象中的所有成员
class Province: country = 'China' def __init__(self, name, count): self.name = name self.count = count def func(self, *args, **kwargs): print ('func') # 获取类的成员,即:静态字段、方法、 print (Province.__dict__) # 输出:{'country': 'China', '__module__': '__main__', 'func': <function func at 0x10be30f50>, '__init__': <function __init__ at 0x10be30ed8>, '__doc__': None} obj1 = Province('HeBei',10000) print (obj1.__dict__) # 获取 对象obj1 的成员 # 输出:{'count': 10000, 'name': 'HeBei'} obj2 = Province('HeNan', 3888) print (obj2.__dict__) # 获取 对象obj1 的成员 # 输出:{'count': 3888, 'name': 'HeNan'}
7. __str__
如果一个类中定义了__str__方法,那么在打印 对象 时,默认输出该方法的返回值。
class Foo: def __str__(self): return 'Terry' obj = Foo() print (obj) >>>Terry
8、__getitem__、__setitem__、__delitem__
用于索引操作,如字典。以上分别表示获取、设置、删除数据
class Foo(object): def __getitem__(self, key): print ('__getitem__',key) def __setitem__(self, key, value): print ('__setitem__',key,value) def __delitem__(self, key): print ('__delitem__',key) obj = Foo() result = obj['k1'] # 自动触发执行 __getitem__ obj['k2'] = 'Terry' # 自动触发执行 __setitem__ del obj['k1'] # 自动触发执行 __delitem__ >>>__getitem__ k1 >>>__setitem__ k2 Terry >>>__delitem__ k1
9、__getslice__、__setslice__、__delslice__
该三个方法用于分片操作,如:列表。
class Foo(object): def __getslice__(self, i, j): print ('__getslice__',i,j) def __setslice__(self, i, j, sequence): print ('__setslice__',i,j) def __delslice__(self, i, j): print ('__delslice__',i,j) obj = Foo() obj[-1:1] # 自动触发执行 __getslice__ obj[0:1] = [11,22,33,44] # 自动触发执行 __setslice__ del obj[0:2] # 自动触发执行 __delslice__
10. __iter__
用于迭代器,之所以列表、字典、元组可以进行for循环,是因为类型内部定义了 __iter__
class Foo(object): pass obj = Foo() for i in obj: print i # 报错:TypeError: 'Foo' object is not iterable
class Foo(object): def __iter__(self): pass obj = Foo() for i in obj: print (i) # 报错:TypeError: iter() returned non-iterator of type 'NoneType'
class Foo(object): def __init__(self, sq): self.sq = sq def __iter__(self): return iter(self.sq) obj = Foo([11,22,33,44]) for i in obj: print (i,end=' ') >>>11 22 33 44
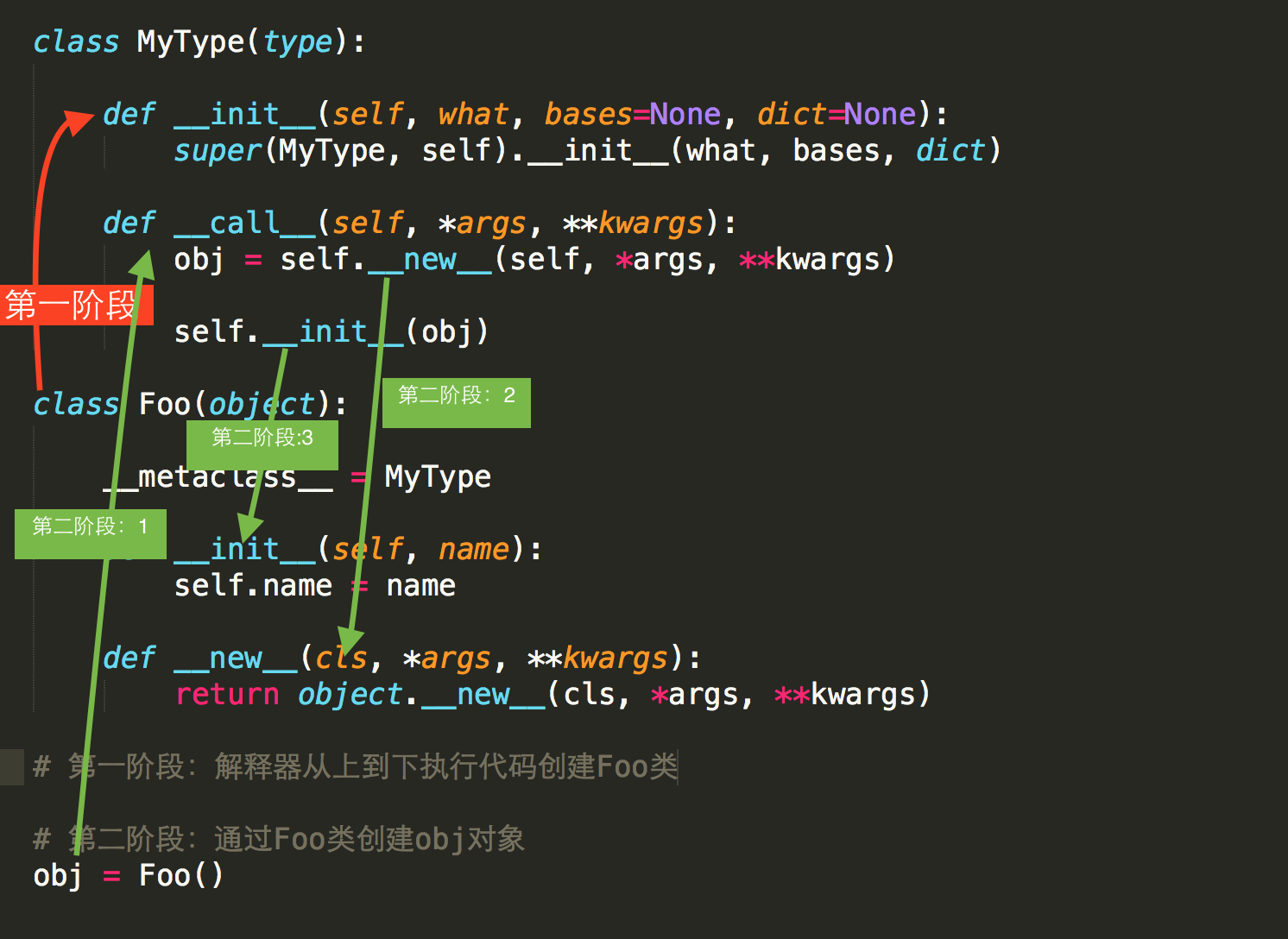
11. __new__ 和 __metaclass__
阅读以下代码:
class Foo(object): def __init__(self): pass obj = Foo() # obj是通过Foo类实例化的对象
上述代码中,obj 是通过 Foo 类实例化的对象,其实,不仅 obj 是一个对象,Foo类本身也是一个对象,因为在Python中一切事物都是对象。如果按照一切事物都是对象的理论:obj对象是通过执行Foo类的构造方法创建,那么Foo类对象应该也是通过执行某个类的 构造方法 创建。
print type(obj) # 输出:<class '__main__.Foo'> 表示,obj 对象由Foo类创建 print type(Foo) # 输出:<type 'type'> 表示,Foo类对象由 type 类创建
所以,obj对象是Foo类的一个实例,Foo类对象是 type 类的一个实例,即:Foo类对象 是通过type类的构造方法创建。那么,创建类就可以有两种方式:
a). 普通方式
class Foo(object): def func(self): print ('hello Terry')
b).特殊方式(type类的构造函数)
def func(self): print ('hello wupeiqi') Foo = type('Foo',(object,), {'func': func}) #type第一个参数:类名 #type第二个参数:当前类的基类 #type第三个参数:类的成员产生
那么问题来了,类默认是由 type 类实例化产生,type类中如何实现的创建类?类又是如何创建对象?
答:类中有一个属性 __metaclass__,其用来表示该类由 谁 来实例化创建,所以,我们可以为 __metaclass__ 设置一个type类的派生类,从而查看 类 创建的过程。
六 异常处理
6.1 异常概述
在编程过程中为了增加友好性,在程序出现bug时一般不会将错误信息显示给用户,而是现实一个提示的页面,通俗来说就是不让用户看见大黄页!!!
try: pass #代码块,逻辑 except Exception as e: pass #上述代码块出错,自动执行当前块的内容 else: pass #没有出错会执行该段代码块 finally: pass #不管有没有出错,均执行 注:else,finally可以写可以不写
例子:将用户输入的两个数字相加
while True: num1 = input('num1:') num2 = input('num2:') try: num1 = int(num1) num2 = int(num2) result = num1 + num2 print(result) except Exception as e: print ('出现异常,信息如下:') print (e)
6.2 异常种类
python中的异常种类非常多,每个异常专门用于处理某一项异常!!!
AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x IOError 输入/输出异常;基本上是无法打开文件 ImportError 无法引入模块或包;基本上是路径问题或名称错误 IndentationError 语法错误(的子类) ;代码没有正确对齐 IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5] KeyError 试图访问字典里不存在的键 KeyboardInterrupt Ctrl+C被按下 NameError 使用一个还未被赋予对象的变量 SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了) TypeError 传入对象类型与要求的不符合 UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量, 导致你以为正在访问它 ValueError 传入一个调用者不期望的值,即使值的类型是正确的
异常类只能用来处理指定的异常情况,如果非指定异常则无法处理。
s1 = 'hello' try: int(s1) except IndexError as e: print (e) >>>报错:ValueError: invalid literal for int() with base 10: 'hello'
所以,写程序时需要考虑到try代码块中可能出现的任意异常,可以这样写:
s1 = 'hello' try: int(s1) except IndexError as e: print (e) except KeyError as e: print (e) except ValueError as e: print (e) #不报错,直接输出: >>>invalid literal for int() with base 10: 'hello'
在python的异常中,有一个万能异常:Exception,他可以捕获任意异常,即:
s1 = 'hello' try: int(s1) except Exception as e: print (e) #不报错,直接输出: >>>invalid literal for int() with base 10: 'hello'
接下来你可能要问了,既然有这个万能异常,其他异常是不是就可以忽略了!
答:当然不是,对于特殊处理或提醒的异常需要先定义,最后定义Exception来确保程序正常运行。
s1 = 'hello' try: int(s1) except KeyError as e: print ('键错误') except IndexError as e: print ('索引错误') except Exception as e: print ('错误') >>>错误
6.3 主动触发异常
try: raise Exception('我错了。。。') except Exception as e: print (e) >>>我错了。。。
6.4 自定义异常
class TerryException(Exception): def __init__(self, msg): self.message = msg def __str__(self): return self.message try: raise TerryException('我的异常') except TerryException as e: print (e) >>>我的异常
6.5 断言
用于用户强制服从,不服从则报错,可捕获,但一般不捕获
# assert 条件 assert 1 == 1 assert 1 == 2
七 反射
python中的反射功能是由以下四个内置函数提供:hasattr、getattr、setattr、delattr,这四个函数分别用于对对象内部执行检查是否含有某成员、获取成员、设置成员、删除成员操作。
class Foo(object): def __init__(self): self.name = 'Terry' def func(self): return 123 obj = Foo() # #### 检查是否含有成员 #### ret1=hasattr(obj, 'name') print(ret1) #True ret2=hasattr(obj, 'func') print(ret2) #True # #### 获取成员 #### ret3=getattr(obj, 'name') print(ret3) #Terry ret4=getattr(obj, 'func') print(ret4) #<bound method Foo.func of <__main__.Foo object at 0x028FFEB0>> # #### 设置成员 #### setattr(obj, 'age', 18) print(obj.age) #18 setattr(obj, 'show', lambda num: num + 1) print(obj.show(1)) #2 # #### 删除成员 #### delattr(obj, 'name') # obj.name #报错:AttributeError: 'Foo' object has no attribute 'name' delattr(obj, 'func') #AttributeError: func
当我们要获取obj对象中name变量指向内存中的值 “Terry”时,有三种方法:
(1)obj.name
(2)obj.__dict__['name']
(3)getattr(obj, 'name')
总结:反射是通过字符串的形式操作对象相关的成员,一切事物都是对象。
类也是对象
class Foo(object): staticField = "old boy" def __init__(self): self.name = 'Terry' def func(self): return 'func' @staticmethod def bar(): return 'bar' print (getattr(Foo, 'staticField')) print (getattr(Foo, 'func')) print (getattr(Foo, 'bar')) >>>old boy >>><function Foo.func at 0x02C26198> >>><function Foo.bar at 0x02C26108>
模块也是对象
def dev(): return 'dev'
import test1 as obj #obj.dev() func = getattr(obj, 'dev') ret=func() print(ret) >>>dev
八 单例模式
单例,顾名思义单个实例。
例子:创建对数据库操作的公共类(增,删,改,查)
# #### 定义类 #### class DbHelper(object): def __init__(self): self.hostname = '1.1.1.1' self.port = 3306 self.password = 'pwd' self.username = 'root' def fetch(self): # 连接数据库 # 拼接sql语句 # 操作 pass def create(self): # 连接数据库 # 拼接sql语句 # 操作 pass def remove(self): # 连接数据库 # 拼接sql语句 # 操作 pass def modify(self): # 连接数据库 # 拼接sql语句 # 操作 pass # #### 操作类 #### db = DbHelper() db.create()
对于上述实例,每个请求到来,都需要在内存里创建一个实例,再通过该实例执行指定的方法。那么问题来了...如果并发量大的话,内存里就会存在非常多功能上一模一样的对象。存在这些对象肯定会消耗内存,对于这些功能相同的对象可以在内存中仅创建一个,需要时都去调用,也是极好的!!!
单例模式的构造:
# ########### 单例类定义 ########### class Foo(object): __instance = None @staticmethod def singleton(): if Foo.__instance: return Foo.__instance else: Foo.__instance = Foo() return Foo.__instance # ########### 获取实例 ########### obj = Foo.singleton()
总结:单利模式存在的目的是保证当前内存中仅存在单个实例,避免内存浪费!!!
参考:https://www.cnblogs.com/wupeiqi/articles/5017742.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号