FPN(feature pyramid networks)
多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而FPN不一样的地方在于预测是在不同特征层独立进行的。
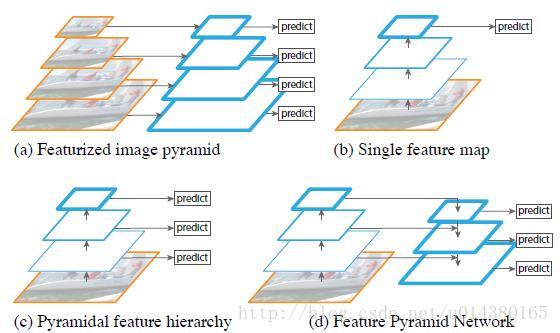
图 a 图像金字塔。将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的缺点在于增加了时间成本。有些算法会在测试时候采用图像金字塔。
图 b 仅采用网络最后一层的特征。对于识别任务,工程特征已经被深度卷积网络(ConvNets)计算的特征大部分所取代。除了能够表示更高级别的语义,ConvNets不同层的特征图尺度也不同,从而有助于从单一输入尺度上计算的特征识别。但是这种做法的缺陷在于只使用了高分辨率特征,因为不同层之间的语义差别很大,最后一层主要都是高分辨率的特征,所以对于低分辨率的特征表现力不足。
图 c 多尺度特征融合的方式。为了改善上面的做法,一个很简洁的改进就是对不同尺度的特征图都进行利用,这也是SSD算法中使用的方法。理想情况下,SSD风格的金字塔将重复使用正向传递中计算的不同层次的多尺度特征图。但为了避免使用低层次特征,SSD会从偏后的conv4_3开始构建特征金字塔,这种做法没有对conv4_3之前的层进行利用,而这些层对于检测小目标很重要。
图 d FPN方式。通过高层特征进行上采样和低层特征进行自顶向下的连接,而且每一层都会进行预测。
FPN的大致结构为:
一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。图中放大的区域就是横向连接,这里1*1的卷积核的主要作用是减少卷积核的个数,也就是减少了feature map的个数,并不改变feature map的尺寸大小。
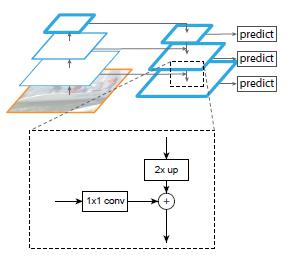
自底向上其实就是网络的前向过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
自顶向下的过程采用上采样(upsampling)进行。而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号