神经网络中的感受野(Receptive Field)
在机器视觉领域的深度神经网络中有一个概念叫做感受野,用来表示网络内部的不同位置的神经元对原图像的感受范围的大小。神经元之所以无法对原始图像的所有信息进行感知,是因为在这些网络结构中普遍使用卷积层和pooling层,在层与层之间均为局部相连(通过sliding filter)。神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着他可能蕴含更为全局、语义层次更高的特征;而值越小则表示其所包含的特征越趋向于局部和细节。因此感受野的值可以大致用来判断每一层的抽象层次。
那么这个感受野要如何计算呢?我们先看下面这个例子。
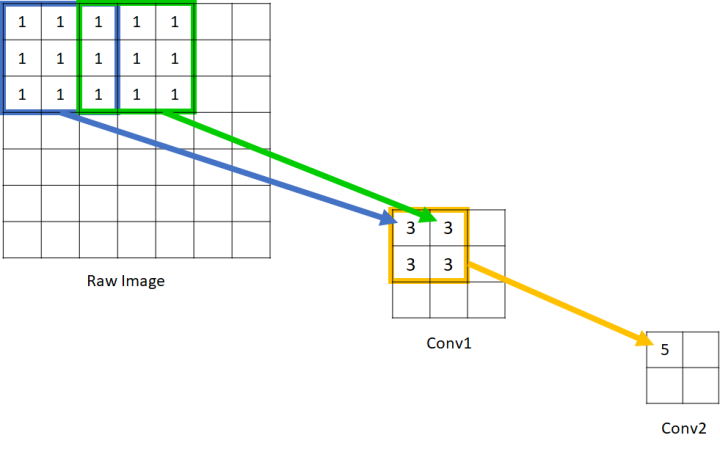
可以看到在Conv1中的每一个单元所能看到的原始图像范围是3*3,而由于Conv2的每个单元都是由 范围的Conv1构成,因此回溯到原始图像,其实是能够看到
的原始图像范围的。因此我们说Conv1的感受野是3,Conv2的感受野是5. 输入图像的每个单元的感受野被定义为1,这应该很好理解,因为每个像素只能看到自己。
通过上图这种图示的方式我们可以“目测”出每一层的感受野是多大,但对于层数过多、过于复杂的网络结构来说,用这种办法可能就不够聪明了。因此我们希望能够归纳出这其中的规律,并用公式来描述,这样就可以对任意复杂的网络结构计算其每一层的感受野了。那么我们下面看看这其中的规律为何。
由于图像是二维的,具有空间信息,因此感受野的实质其实也是一个二维区域。但业界通常将感受野定义为一个正方形区域,因此也就使用边长来描述其大小了。在接下来的讨论中,本文也只考虑宽度一个方向。我们先按照下图所示对输入图像的像素进行编号。

接下来我们使用一种并不常见的方式来展示CNN的层与层之间的关系(如下图,请将脑袋向左倒45°观看>_<),并且配上我们对原图像的编号。

图中黑色的数字所构成的层为原图像或者是卷积层,数字表示某单元能够看到的原始图像像素。我们用 来表示第
个卷积层中,每个单元的感受野(即数字序列的长度);蓝色的部分表示卷积操作,用
和
分别表示第
个卷积层的kernel_size和stride。
对Raw Image进行kernel_size=3, stride 2的卷积操作所得到的fmap1 (fmap为feature map的简称,为每一个conv层所产生的输出)的结果是显而易见的。序列[1 2 3]表示fmap1的第一个单元能看见原图像中的1,2,3这三个像素,而第二个单元则能看见3,4,5。这两个单元随后又被kernel_size=2,stride 1的Filter 2进行卷积,因而得到的fmap2的第一个单元能够看见原图像中的1,2,3,4,5共5个像素(即取[1 2 3]和[3 4 5]的并集)。
接下来我们尝试一下如何用公式来表述上述过程。可以看到,[1 2 3]和[3 4 5]之间因为Filter 1的stride 2而错开(偏移)了两位,而3是重叠的。对于卷积两个感受野为3的上层单元,下一层最大能获得的感受野为 ,但因为有重叠,因此要减去(kernel_size - 1)个重叠部分,而重叠部分的计算方式则为感受野减去前面所说的偏移量,这里是2. 因此我们就得到
继续往下一层看,我们会发现[1 2 3 4 5]和[3 4 5 6 7]的偏移量仍为2,并不简单地等于上一层的 ,这是因为之前的stride对后续层的影响是永久性的,而且是累积相乘的关系(例如,在fmap3中,偏移量已经累积到4了),也就是说
应该这样求

以此类推,
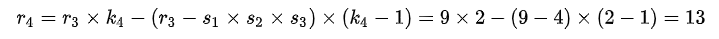
于是我们就可以得到关于计算感受野的抽象公式了:
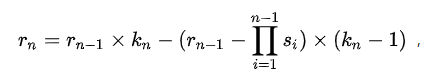
经过简单的代数变换之后,最终形式为:
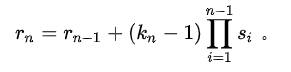
转:知乎 蓝荣祎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号