目标检测简介
1 什么是目标检测
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观,形状,姿态,加上成像时光照,遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
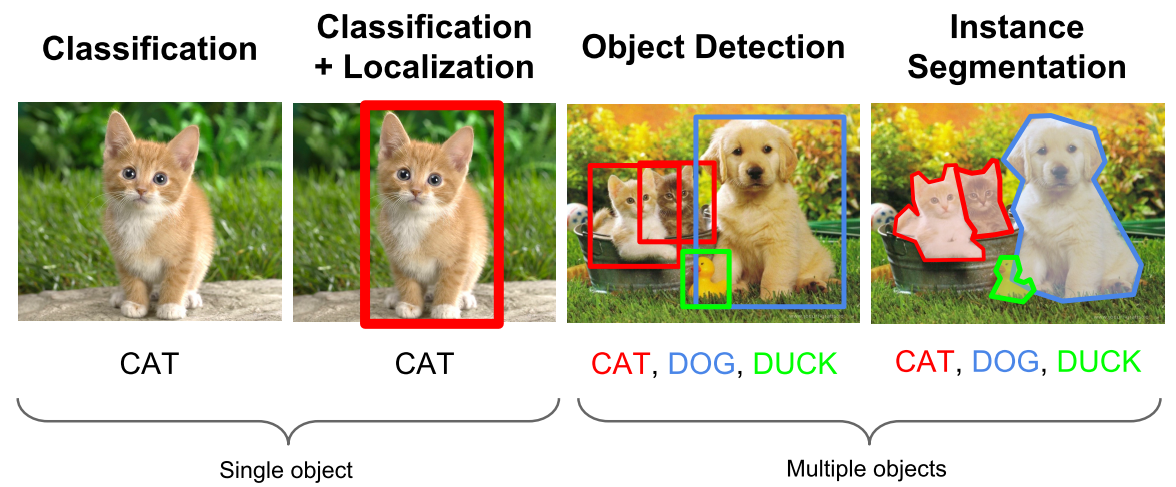
计算机视觉中关于图像识别有四大类任务:
分类-Classification:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
定位-Location:解决“在哪里?”的问题,即定位出这个目标的的位置。
检测-Detection:解决“是什么?在哪里?”的问题,即定位出这个目标的的位置并且知道目标物是什么。
分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标物或场景”的问题。
2 目标检测要解决的核心问题
除了图像分类之外,目标检测要解决的核心问题是:
1.目标可能出现在图像的任何位置。
2.目标有各种不同的大小。
3.目标可能有各种不同的形状。
如果用矩形框来定义目标,则矩形有不同的宽高比。由于目标的宽高比不同,因此采用经典的滑动窗口+图像缩放的方案解决通用目标检测问题的成本太高。
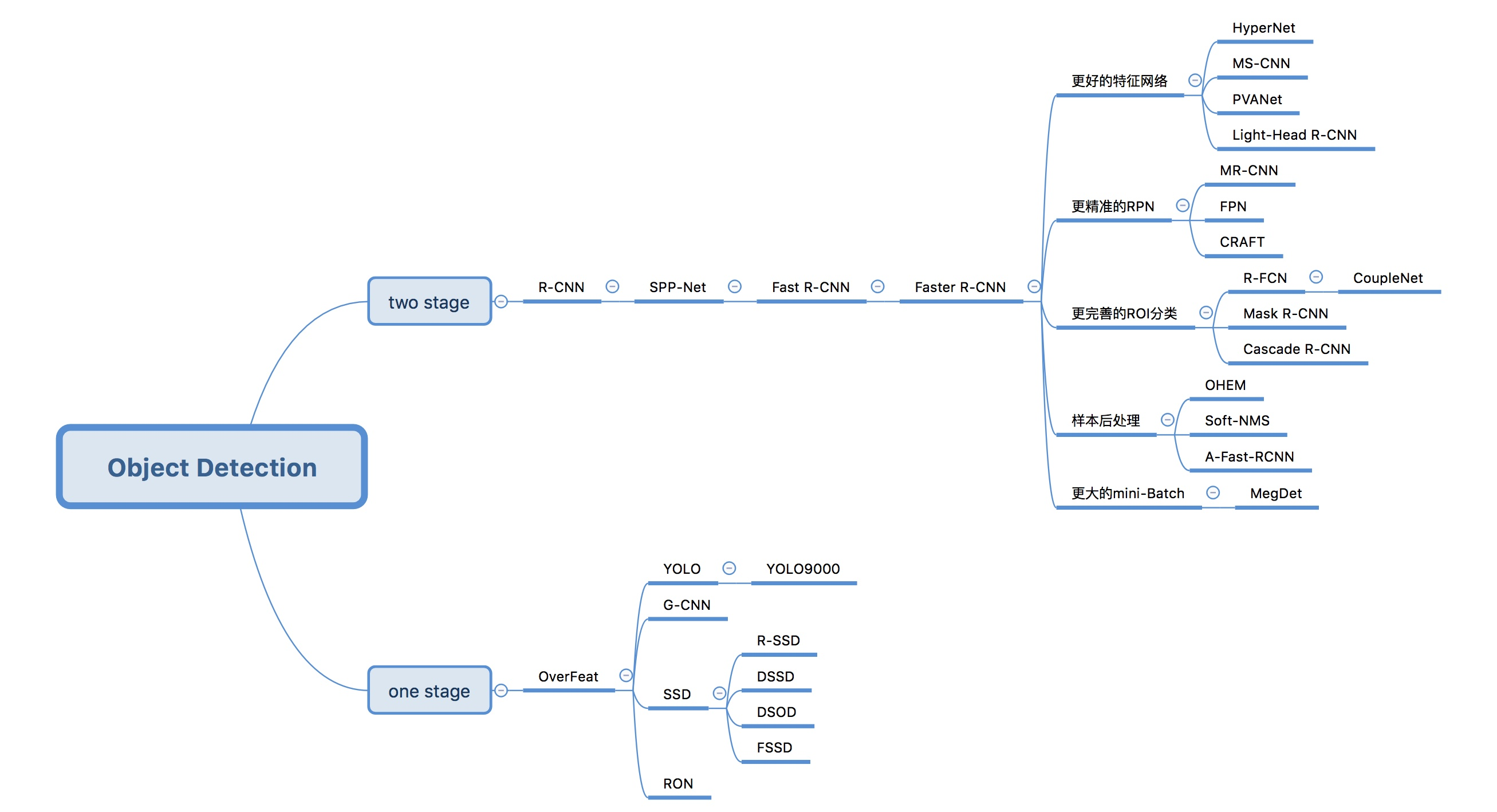
3 目标检测算法分类
基于深度学习的目标检测算法主要分为两类:
1.Two stage目标检测算法
先进行区域生成(region proposal,RP)(一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。
任务:特征提取—>生成RP—>分类/定位回归。
常见的two stage目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和R-FCN等。
2.One stage目标检测算法
不用RP,直接在网络中提取特征来预测物体分类和位置。
任务:特征提取—>分类/定位回归。
常见的one stage目标检测算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号