

python程序设计(三):python高阶
python高阶
python的可变类型和不可变类型
可变类型:
-
列表[]
-
集合
-
字典
不可变类型
-
数字(整型,浮点型等)
-
字符串
-
元组:()
可变和不可变的实质: 可变数据和不可变数据是相对于引用地址来说的,不可变数据类型不允许变量的值发生变化,如果改变了的变量的值,相当于新建了一个对象,而对于相同的值的对象,内部会有一个引用计数来记录有多少个变量引用了这个对象。可变数据类型允许变量的值发生变化。对变量进行修改操作只会改变变量的值,不会新建对象,变量引用的地址也不会发生变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
简单地讲,可变数据和不可变数据的“变”是相对于引用地址来说的,不是不能改变其数据,而是改变数据的时候会不会改变变量的引用地址。
比如:
python中可以使用id()函数查看变量的引用地址
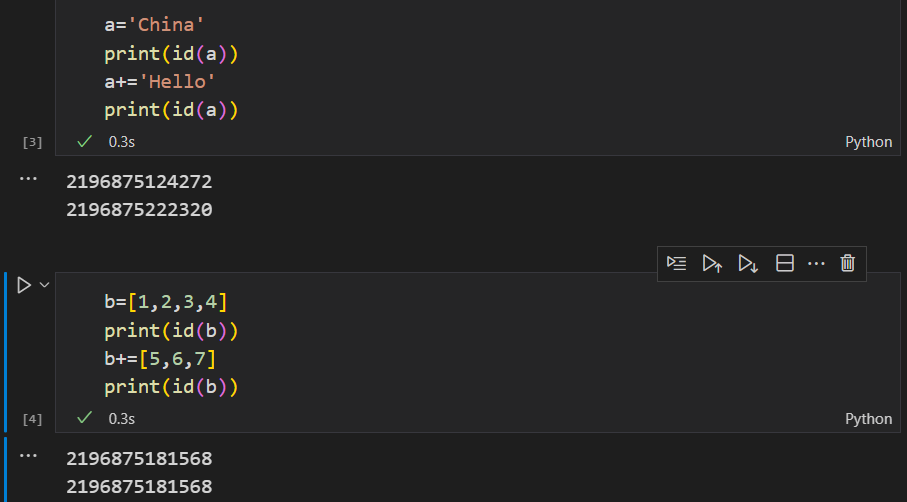
可以看到,字符串虽然值改变了,但它的引用地址也发生了变化,在内存中实际是
a='China'
a->str1->'China'
a+='hello'
a->str2->'China hello'
而可变类型如列表不需要开辟新空间,还是曾经的引用地址
小数据池
a=3
b=3
print(id(a)==id(b))
True
python将-5~256的整数进行了缓存,当将这些整数赋值给变量时并不会创建新的对象
a=300
b=300
print(id(a)==id(b))
False
对于字符串变量,当字符串变量的长度为0或1时,也缓存
a=' '
b=' '
print(id(a)==id(b))
True
a='a'
b='a'
print(id(a)==id(b))
True
当字符串长度>1,且字符串中只有字母数字和下划线时,也会缓存
a='adawFF1__aawd3444___1ffa'
b='adawFF1__aawd3444___1ffa'
print(id(a)==id(b))
True
最后还有bool变量也适用小数据池
a=True
b=True
print(id(a)==id(b))
True
其他情况不缓存
a='a '
b='a '
print(id(a)==id(b))
False
迭代器和生成器
生成器generator:也叫生成器函数,含有yield修饰的表达式.每次执行到yield语句时会返回一个值然后暂停或挂起后面代码的执行.下次通过生成器对象的__next__()方法,内置函数next(),for循环遍历生成器对象元素或其他方法显示'索要'数据时恢复执行.
普通函数
def fun():
i=0
while i<10:
print(i,end=" ")
i=i+1
fun()
0 1 2 3 4 5 6 7 8 9
添加yield修饰变量,变成生成器
def fun():
i=0
while i<10:
yield i
print('i=',i,end=" ")
i=i+1
a=fun()
print(a)
<generator object fun at 0x000001DCA95B5900>
a就是一个生成器对象
通过内置函数next()生成下一个a
next(a)
next(a)
next(a)
next(a)
next(a)
i= 0 i= 1 i= 2 i= 3
4
可以看到前三个是i=,最后一个是直接一个数字,也就是说,程序顺序执行,执行到yield时,后面的print()不执行,返回i的值,就是直接输出i,下次执行时先执行print(),所以出现了三个print()
断点调试:

所以yield并不是return那种返回值,而是输出
或使用生成器对象方法__next__()
a.__next__()
i=: 4
5
def fun():
i=0
while i<10:
yield i
i=i+1
a=fun()
而且可以用for遍历出来
[i for i in a]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
迭代器Iterator:是一种可作用于next()函数的对象,表示一个惰性计算的序列.
惰性计算就是执行到yield就暂停,每调用一次next,就再执行一次,不像其他函数直接执行完
可迭代类型Iterable:凡是可以作用于for循环的对象都是可迭代的,其内部实现了__iter__()函数或__getitem()__函数.list,dict,str等都是Iterable的,但不是Iterator.可以通过iter()函数来获得一个Iterator
range()对象也不是Iterator,range()实际是一个Sequence
x=range(10)
type(x)
range
next(x)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
c:\Users\Tenerome\Desktop\python\lesson.ipynb Cell 35 in <cell line: 1>()
----> <a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#X61sZmlsZQ%3D%3D?line=0'>1</a> next(x)
TypeError: 'range' object is not an iterator
在python中for语句真正的含义是迭代,while语句才是真正的循环.for类似于java中的foreach语句
循环可以通过增加条件跳过不需要的元素,而迭代只能一个一个往后取数.迭代有固定的格式:for ... in ....
在for语句内部,会通过iter()方法将可迭代对象转换成迭代器,然后重复调用next()方法实现.for语句会自动捕捉StopIteration异常,并在捕捉异常后终止迭代
闭包和装饰器
万物皆为对象,函数也是
def fun():
pass
print(type(fun))
<class 'function'>
所有的函数都是function类的实例
①内嵌函数
如果一个函数的内部还有一个函数,该如何去调用?
def outer():
print('this is outer function')
def inner():
print('this is inner function')
这样的结构是不完整的,想要调用内函数,必须在外函数内return内函数名
def outer():
print('this is outer function')
def inner():
print('this is inner function')
return inner
outer()()
this is outer function
this is inner function
这里outer()=inner
即f=outer(),f()=inner()
②闭包
如果内嵌函数使用了外函数的资源,则称内嵌函数和它引用的资源为闭包
def line_conf(a):
b=1
def line(x):
return a*x+b
return line
a=line_conf(2)
print(a(3))
7
a=line_conf(2),就相当于:
a(x){
return 2*x +1}
就是把外函数的参数和用到的资源都传到内函数中,返回这个内函数
如果想要在内内函数中修改用到的外函数的资源,就要用nonlocal声明
def line_conf(a):
b=1
def line(x):
nonlocal b
b=3
return a*x+b
return line
a=line_conf(2)
print(a(3))
9
③装饰器(decorator):
封闭-开放原则:封闭已经实现的功能代码块,开放对扩展开发
如现有一个函数f(),编写一个装饰器,计算f()运行时间
import time
def f():
print('Hello')
time.sleep(1)
print('world')
装饰器函数
def deco(f):
def wrapper():
start_time=time.time()
f()
end_time=time.time()
exec_time=(end_time-start_time)*1000
print(exec_time)
return wrapper
要在f()前一行添加@deco,装饰器函数名
@deco
def f():
print('Hello')
time.sleep(1)
print('world')
运行的时候可以直接用f(),系统会自动加载装饰器函数
f()
Hello
world
1004.9920082092285
带参数且有返回值装饰器,被装饰的函数有几个参数,装饰器内部的inner函数就有几个.返回值先在内函数中返回给内函数inner(),再由return inner返回给outer()
def yanzheng(func):
def inner(a,b):#func有两个参数,inner就有两个参数
print('开始验证')
if type(a)==int and type(b)==int:
return func(a,b)#返回给inner()
else:
print('必须输入整数')
return inner#返回给yanzheng()
@yanzheng
def add_num(a,b):
return a+b
print(add_num(4,5))
开始验证
9
赋值,深拷贝和浅拷贝
浅拷贝:copy.copy()或者用切片切出来的也是浅拷贝
深拷贝:copy.deepcopy()
①不可变类型
赋值:
python中的所有赋值,都是引用赋值,类似c语言中的指针的赋值
a=100
b=a
print(id(a),id(b))
2491268879824 2491268879824
此时a和b指向同一个内存
b=200
print(id(a),id(b))
2491268879824 2491268883088
因为a,b是number类,不可原地改变,b=200,是把一个新的内存赋给了b,所以a is not b
对于不可变类型,赋值,浅拷贝,深拷贝的结果都一样:原变量改变,复制变量不变
拷贝需要导入库 copy
浅拷贝
import copy
a=100
b=copy.copy(a)
print(id(a),id(b))
b=200
print(id(a),id(b))
2491268879824 2491268879824
2491268879824 2491268883088
深拷贝:
import copy
a=100
b=copy.deepcopy(a)
print(id(a),id(b))
b=200
print(id(a),id(b))
2491268879824 2491268879824
2491268879824 2491268883088
总结:对于不可变类型,赋值,浅拷贝,深拷贝后指向同一个内存空间,但是改变值会指向新的空间,所以两个值互补影响
②可变类型的内部只包含简单的数据类型
赋值
a=[100,200,300]
b=a
print(id(a),id(b))
a.append(400)
print(id(a),id(b))
2491907542016 2491907542016
2491907542016 2491907542016
浅拷贝
import copy
a=[100,200,300]
b=copy.copy(a)
print(id(a),id(b))
a.append(400)
print(id(a),id(b))
2491907815104 2491907524864
2491907815104 2491907524864
深拷贝
import copy
a=[100,200,300]
b=copy.deepcopy(a)
print(id(a),id(b))
a.append(400)
print(id(a),id(b))
2491907555136 2491907692544
2491907555136 2491907692544
总结:可变类型中只包含简单的数据类型的话,对其赋值操作,两个变量指向同一个空间,一起改变.浅拷贝和深拷贝相同都是创建了新的空间
③可变类型中还包含复杂的可变类型
赋值
a=[[1,2,3],[4,5,6],7,8]
b=a
a.append(9)
print(id(a),id(b))
a[3]=100
print(id(a[3]),id(b[3]))
a[0].append(200)
print(id(a[0]),id(b[0]))
2491907952960 2491907952960
2491268879824 2491268879824
2491907955584 2491907955584
浅拷贝
a=[[1,2,3],[4,5,6],7,8]
b=copy.copy(a)
a.append(9)
print(id(a),id(b))
a[2]=100
print(id(a[2]),id(b[2]))
a[0].append(200)
print(id(a[0]),id(b[0]))
2491907954624 2491908235328
2491268879824 2491268688368
2491907619776 2491907619776
深拷贝:
a=[[1,2,3],[4,5,6],7,8]
b=a
a.append(9)
print(id(a),id(b))
a[2]=100
print(id(a[2]),id(b[2]))
a[0].append(200)
print(id(a[0]),id(b[0]))
2491908213376 2491908213376
2491268879824 2491268879824
2491907955584 2491907955584
总结:可变类型含有可变类型时,赋值操作后指向同一块内存,深拷贝操作指向不同的内存.浅拷贝特殊,其中的不可变类型指向不同的空间,可变类型指向相同的空间
总结:
赋值:不管怎么操作都指向同一空间
深拷贝:不可变类型指向同一空间,可变类型指向不同空间
浅拷贝:不可变类型指向同一空间
可变类型中的不可变类型:指向不同的空间
可变类型中的可变类型:指向相同的空间
记忆:赋值操作,不可变类型 和 浅拷贝可变类型中的可变类型 指向同一块空间
其他都是不同的空间
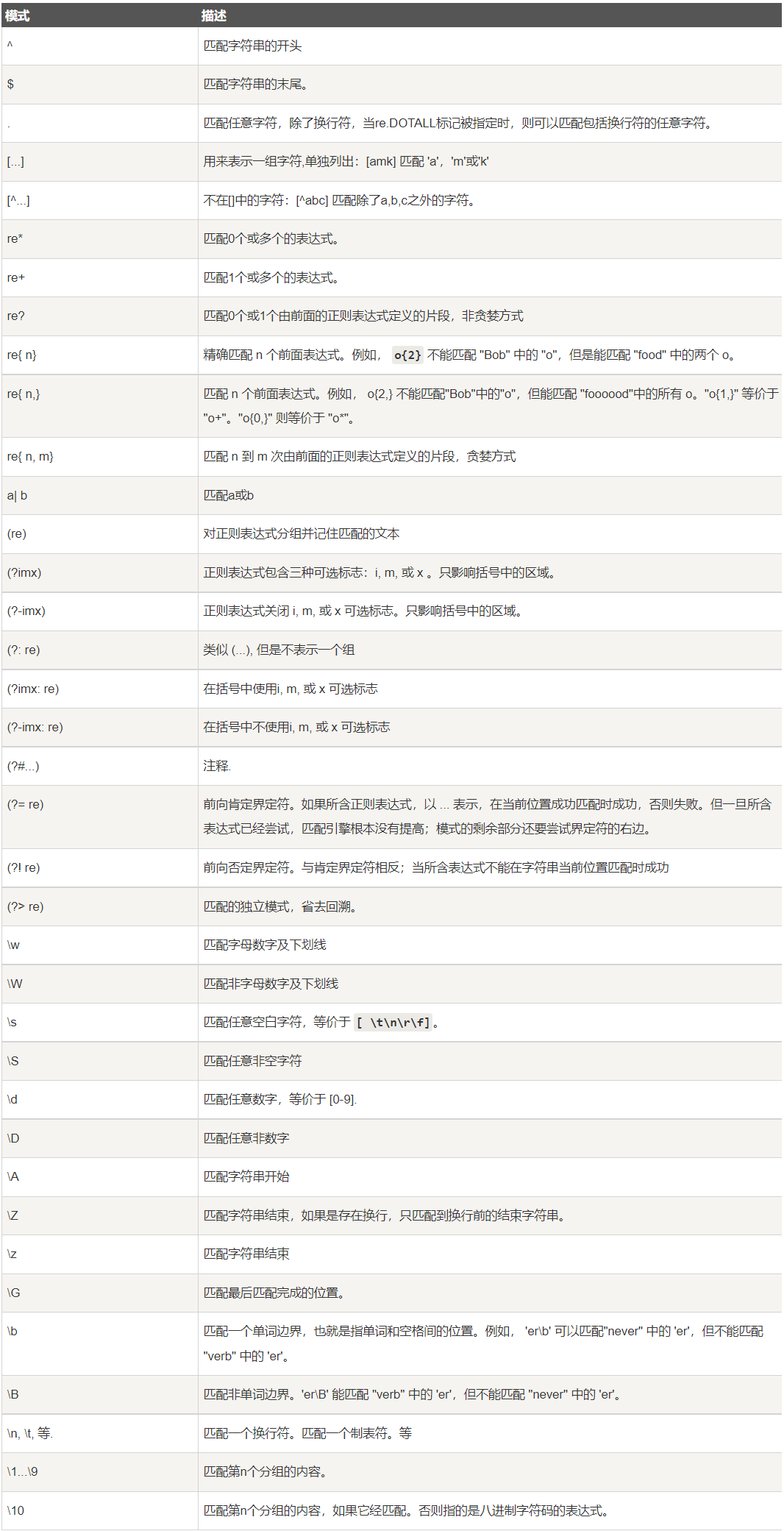
正则表达式
RE语法:
import re
①,提取邮编
s='学校邮编是:150028,请牢记150028'
p='[1-9]\d{5}'
re.search(p,s).group(0)
'150028'
p:[1-9]第一个字符,是1-9的任意一个字符,因为邮编不能以0开始
\d:表示任意数字,0-9任意一个字符
{5}:重复5次
所以它匹配的是以1-9开始的六位数字
re.search(pattern,string,flag=0),pattern正则语法.
re.search()方法扫描整个string,并返回第一个成功匹配的对象.如果匹配失败,则返回none.成功匹配后返回一个re.match对象,可以通过对象的group()获得匹配结果,如果pattern指定要返回多个结果,可以通过group(num)获取不同的匹配位置
re.match和re.search的区别:
re.search并不要求从字符串开头进行匹配,re.match必须从开头匹配,若开头匹配失败,整个就失败了,返回none
print(re.match(p,s))
None
②,提取python,cython,jython
s='python的解释器包括cython,jython等'
p='.*([cjp]ython).*([cjp]ython).*([cjp]ython).*'
m=re.search(p,s)
print(m.groups())
for i in range(1,4):
print(m.group(i))
('python', 'cython', 'jython')
python
cython
jython
p='.*([cjp]ython).*([cjp]ython).*([cjp]ython).*'
.表示任意字符,*表示任意个,所以就把句子中的所有ython提取出来了
groups()返回一个元组,group(num)返回第num个匹配字符串
第二种方法:使用re.findall(p,s):
s='python的解释器包括cython,jython等'
p='[cjp]ython'
l=re.findall(p,s)
print(l)
['python', 'cython', 'jython']
re.findall()和search的区别就是search只返回第一个匹配结果,所以想匹配多个要重复多次模式.findall()就是返回所有的匹配对象,且返回结果是一个列表
用r''形式的字符串,中的\不转义
③,提取姓名和电话
s='''
张三,手机号码13945678823
李四,手机号码18943215634
王五,手机号码12456236671
'''
p=re.compile(r'^(.+),.+(\d{11})',re.M)
for i in p.findall(s):
print(i)
('张三', '13945678823')
('李四', '18943215634')
('王五', '12456236671')
re.compile(pattern,flag)方法将正则表达式编译为re.pattern对象,flag参数指定匹配方式,常见标志有:
1,re.I:忽略大小写
2,re.M多行匹配:当pattern中出现和$时,默认匹配第一行最开始和最后一行的末尾,如果想让和&匹配每一行的开始和末尾,则需要加上re.M
3,re.S :使pattern中.匹配任意字符,包括换行,常配合(.*?)
python用''' .....'''定义多行字符串
r'^(.+),.+(\d{11})':
^表示从开头,re.M表示每一行都从开头匹配
():表示要匹配的内容
.:任意字符,+表示任意1和或多个字符,*表示0个或多个
所以^(.+), :表示从开头到,之间的字符,且不能为空
接着.+表示任意字符,(\d)表示要匹配的是数字,{11}表示重复11次
re.I忽略大小写
s='abc,Abc,aBC,ABC,aabc'
re.findall('abc',s,re.I)
['abc', 'Abc', 'aBC', 'ABC', 'abc']
④,非贪婪匹配(.*?)
import re
s='''
abc,c
Abc,abc,ABC
Harbin University of Commerce
'''
print(re.findall('a(.*)c',s))
print(re.findall('a(.*?)c',s))
['bc,', 'b', 'rbin University of Commer']
['b', 'b', 'rbin University of Commer']
a(.*)c默认贪婪匹配,当第一行abc,c的a匹配到时,它会从后面匹配c,使中间的.*尽可能更长.
?表示非贪婪匹配,匹配到a后继续向后搜索,遇到第一个c就返回
re.findall()默认从第一行第1个字符到最后一行最后一个字符进行全文搜索,不需要用re.M
⑤,去除字符串中的重复项
s="It's a very good good goood idea"
#可以用set集合的不重复性
' '.join(set(s.split()))
"idea It's goood a good very"
但是集合还有一个无序性,所以输出是无序的
用re.sub(pat,repl,string):将字符串中所有与pat匹配的项用repl替换,返回新的字符串.
re.sub(r'(\b\w+\s)\1+',r'\1',s)
"It's a very good goood idea"
\b表示边界,\w任意字母数字下划线,\s表示空格,(\b\w\s)\1,这个\1是重复前面()的内容,+表示一次或多次,所以第一个参数就是用来匹配重复的项的:good good good,然后用第二个参数替换.
\num表示第num个括号匹配的内容,如'.*([hv]ello).*([cb]nmk).*'
\1就表示[hv]ello,\2表示[cb]nmk
⑥匹配字符串中的汉字
s="not 404 found 33.4 张三 99 哈尔滨"
s=re.sub('\d+\.?\d*|[a-zA-Z]+','',s)
s=s.split()
res=' '.join(s)
print(res)
张三 哈尔滨
用sub匹配到所有数字和单词,并用null,""替换.
\d任意数字,+正闭包,一个或多个; .?0个或1个点,就能匹配整数和小数;\d*,0个或多个数字,就能匹配所有的整数和小数
然后|上所有字母组成的单词,就只剩汉字了
string.join(iterable),将string插入序列s除了第一个和最后一个元素之间,然后返回join之后的字符串.
⑦分割字符串
s="info:zhangsan 22 Harbin"
re.split(':|\s',s)
['info', 'zhangsan', '22', 'Harbin']
re.split()的第一个参数是分隔的符号,默认空格,这里指定:或空格
⑧列表元素的匹配
email_list=['xiaodaaw@163.com','xiddddaodaaw@163.comaaa','xiaodaaw@qq.com','xiaodaaw@163.ccom']
p='\w+@163\.com$'
def email_check(x):
if re.match(p,x):
return True
res=filter(email_check,email_list)
print(list(res))
['xiaodaaw@163.com']
或用lambda表达式
email_list=['xiaodaaw@163.com','xiddddaodaaw@163.comaaa','xiaodaaw@qq.com','xiaodaaw@163.ccom']
p='\w+@163\.com$'
res=filter(lambda x: re.match(p,x),email_list)
print(list(res))
['xiaodaaw@163.com']
⑨匹配中文
s='你好,hello,2022,好的'
p=re.compile('[\u4e00-\u9fa5]+')
res=p.findall(s)
print(res)
['你好', '好的']
\u4e00-\u8fa5是unicode所有的中文
全局解释器锁GIL
GIL:全局解释器锁,当多个线程并行执行时,每个线程在执行前都要先获取GIL锁,保证同一时刻只有一个python线程在运行,目的时解决多线程同时竞争程序中的全局变量而出现的线程安全问题.
所以在python中的多线程执行效率会被GIL大大限制
在过去单核及其上,不能真正的并行,而是并发处理的,所以会有资源竞争问题,也就有了GIL锁,现在的机器都是多线程的了,但GIL仍存在与cpython解释器中.想要使用python多线程,就要想办法绕过GIL
释放GIL的情况:
1,在IO操作等可能会引起阻塞的system call之前,可以暂时释放GIL锁,但在执行完毕后,必须重新获取锁
2,python 3.x使用计时器,执行时间达到阈值后,当前线程释放GIL锁.或python2中,tickets计数达到100时,释放GIL锁
解决GIL问题的方案:
1,使用其他语言:c,java等
2,使用其他解释器,如java的jython
3,使用多进程,python中的多进程是可以利用cpu资源的
虽然有GIL限制,多线程爬取还是比单线程性能高的,因为遇到IO阻塞时会自动释放GIL锁
线程
进程,线程和协程的区别:
(1)进程是资源分配的单位,线程是操作系统系统任务调度的单位,协程是1个线程内的多任务
(2)进程之间不共享全局变量,线程和协程可以共享全局变量
(3)计算密集型任务适合多进程,I/O密集型任务适合多线程或多协程
(4)进程消耗资源大,线程消耗资源少,协程消耗资源最少
(5)使用线程池或进程池可以提高效率减少资源消耗
①单线程-顺序执行方式
import time
def sing():
for i in range(3):
print("唱歌")
time.sleep(1)
def dance():
for i in range(3):
print("跳舞")
time.sleep(1)
if __name__=='__main__':
start_time=time.perf_counter()
sing()
dance()
end_time=time.perf_counter()
print('total time is {}'.format(end_time-start_time))
唱歌
唱歌
唱歌
跳舞
跳舞
跳舞
total time is 6.0794796
计算程序执行时间的几种方式:
time.time()会将sleep()的时间也算进去
time.perf_counter() 具有最高可用分辨率的时钟,包含sleep()时间,适合测量短持续时间
time.process_time()不包括sleep()时间,其他与time.perf_counter类似
此外python3.7后提供了三个方法精确到纳秒的计时:
time.perf_counter_ns()
time.time_ns()
time.clock()
②多线程
import time
import threading
def sing():
for i in range(3):
print("唱歌")
time.sleep(1)
def dance():
for i in range(3):
print("跳舞")
time.sleep(1)
if __name__=='__main__':
start_time=time.perf_counter()
t1=threading.Thread(target=sing)
t2=threading.Thread(target=dance)
t1.start()
t2.start()
end_time=time.perf_counter()
print(f'total time is {end_time-start_time}')
唱歌
跳舞
total time is 0.0035195000000385335
跳舞唱歌
跳舞唱歌
t1=threading.Thread(),在主线程下创建子线程t1
target=sing,为子线程t1分配任务sing
t1.start()开启子线程
运行程序,主线程开始执行,执行到t1,t2start(),创建子线程,接着主线程继续执行,输出了执行时间,主线程的代码执行完毕,但程序并不结束,而是等待子线程t1,t2执行,t1,t2执行完剩下的迭代,程序结束
如图示
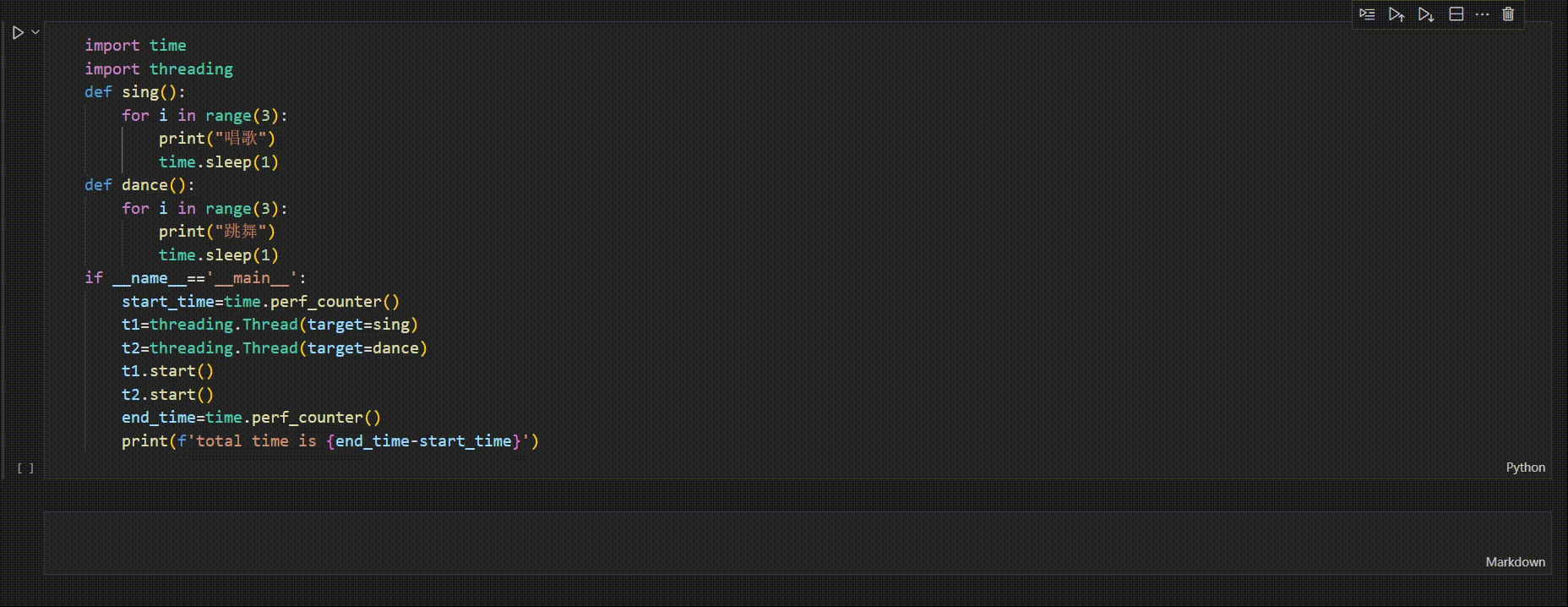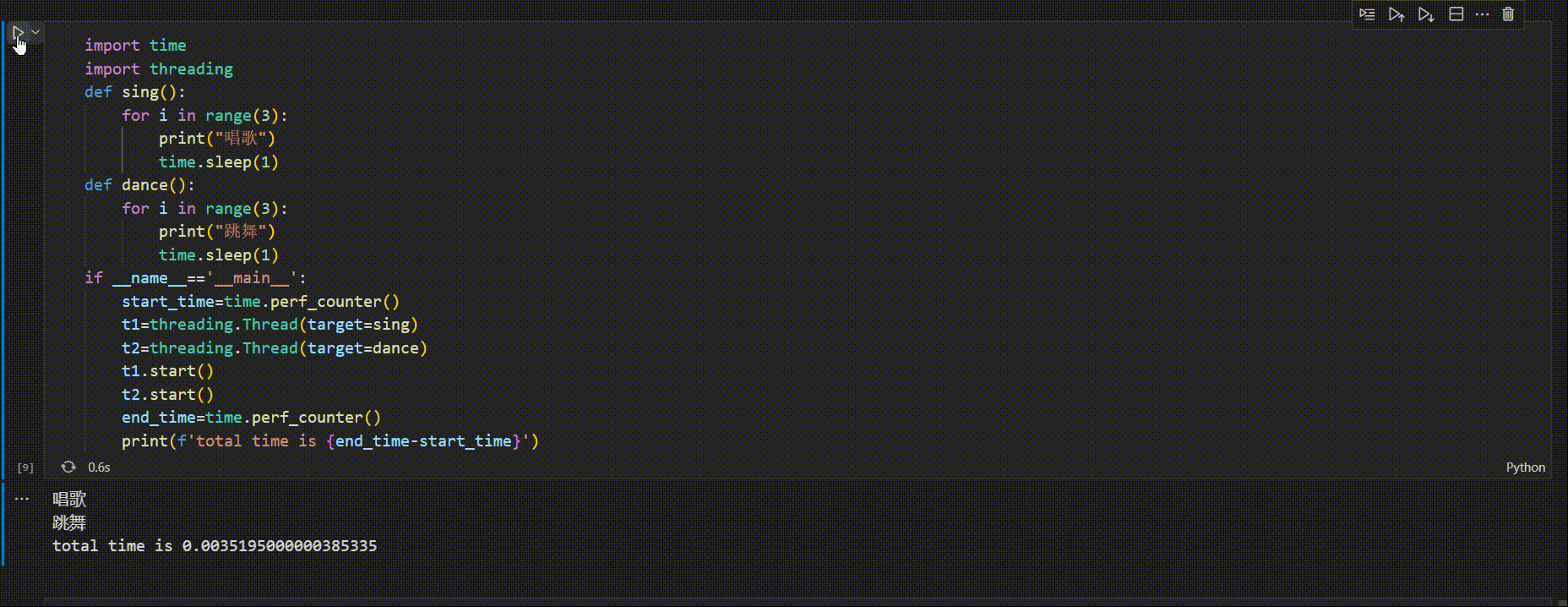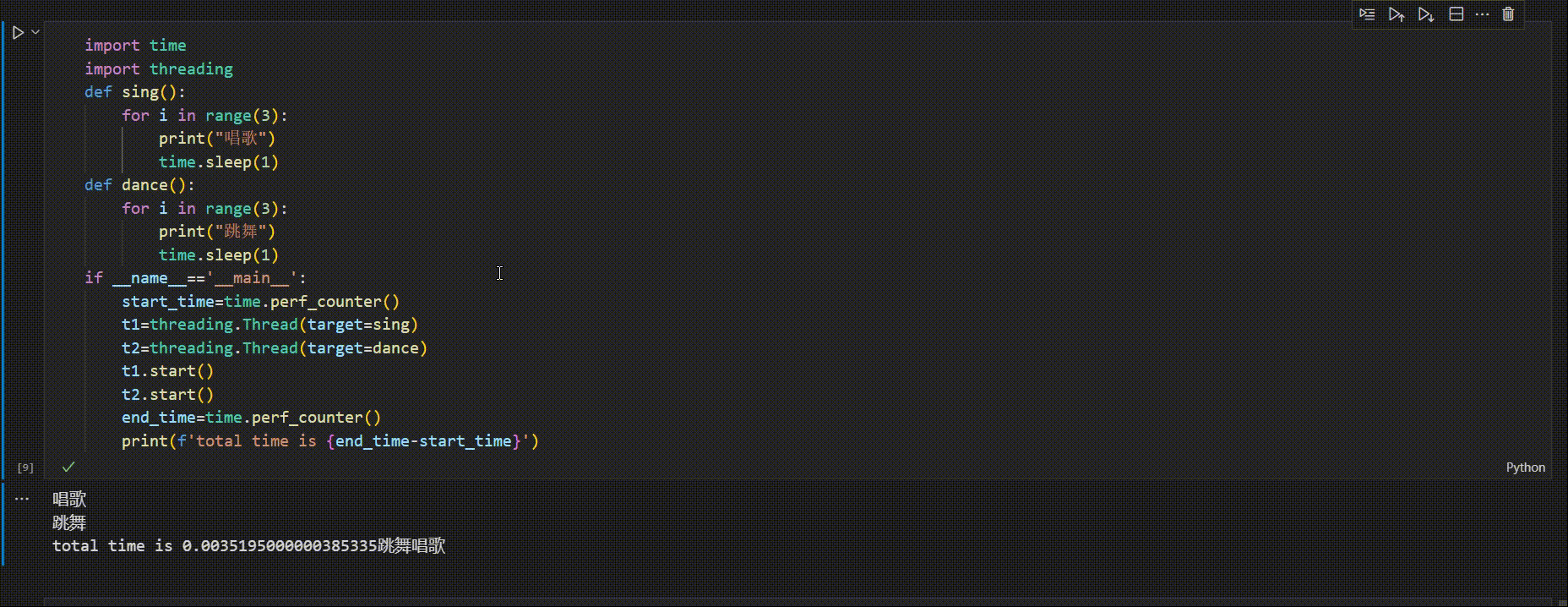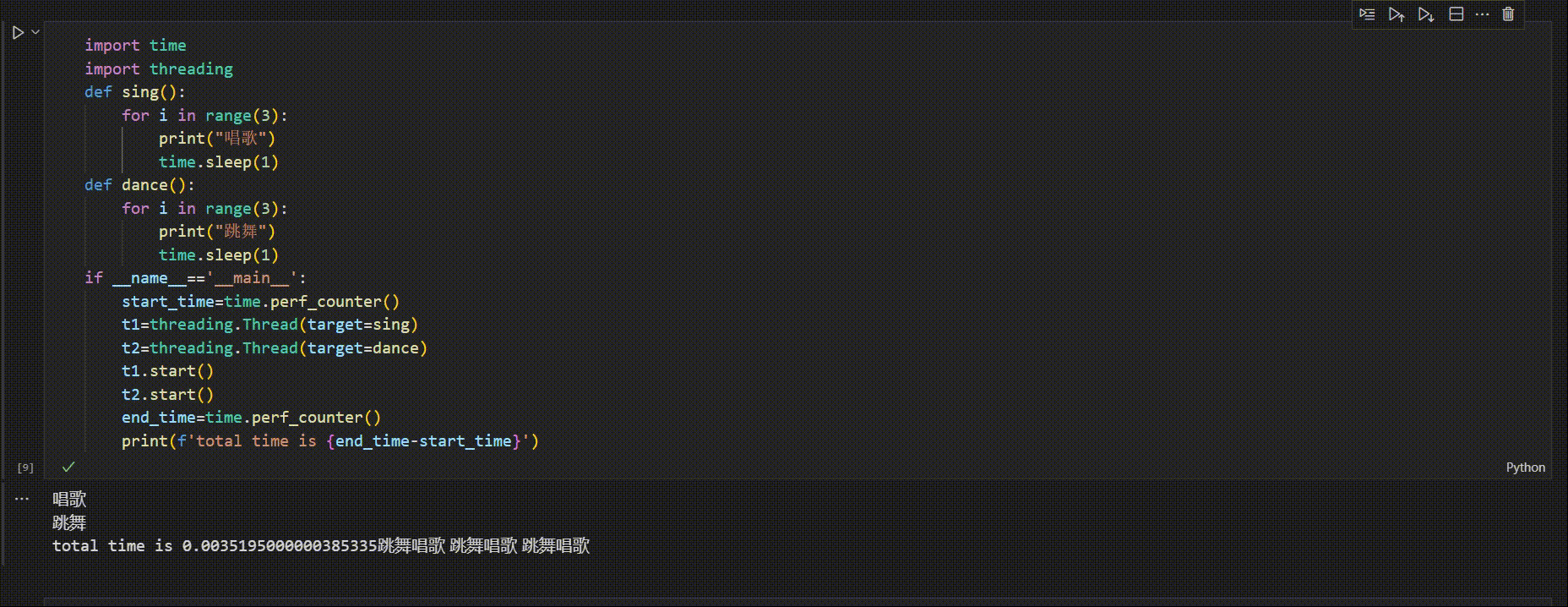
主线程执行完,若子线程未执行完,主线程会等待子线程结束后才退出程序
子线程是因为sleep()才晚于主线程,如果没有slee()
import time
import threading
def sing():
for i in range(3):
print("唱歌")
# time.sleep(1)
def dance():
for i in range(3):
print("跳舞")
# time.sleep(1)
if __name__=='__main__':
start_time=time.perf_counter()
t1=threading.Thread(target=sing)
t2=threading.Thread(target=dance)
t1.start()
t2.start()
end_time=time.perf_counter()
print(f'total time is {end_time-start_time}')
唱歌
唱歌
唱歌
跳舞
跳舞
跳舞
total time is 0.00368129999969824
或者给主线程加上等待时间,也能看到并发执行完
import time
import threading
def sing():
for i in range(3):
print("唱歌")
time.sleep(1)
def dance():
for i in range(3):
print("跳舞")
time.sleep(1)
if __name__=='__main__':
start_time=time.perf_counter()
t1=threading.Thread(target=sing)
t2=threading.Thread(target=dance)
t1.start()
t2.start()
time.sleep(4)
end_time=time.perf_counter()
print(f'total time is {end_time-start_time}')
唱歌
跳舞
跳舞唱歌
跳舞唱歌
total time is 4.0054009999998925
统计多线程运行时间的正确方法:
import time
import threading
def sing():
for i in range(3):
print("唱歌")
time.sleep(1)
def dance():
for i in range(3):
print("跳舞")
time.sleep(1)
if __name__=='__main__':
start_time=time.perf_counter()
t1=threading.Thread(target=sing)
t2=threading.Thread(target=dance)
t1.start()
t2.start()
t1.join()
t2.join()
end_time=time.perf_counter()
print(f'total time is {end_time-start_time}')
唱歌
跳舞
跳舞
唱歌
唱歌跳舞
total time is 3.041722899999968
join函数会等待子线程结束,或者说要判断汇合点,都汇合后主线程才继续执行
③统计线程数 (在独立文件中运行)
import threading
import time
#查看线程数
def sing():
for i in range(3):
print("唱歌")
time.sleep(1)
def dance():
for i in range(3):
print("跳舞")
time.sleep(1)
if __name__=='__main__':
sing_t=threading.Thread(target=sing)
dance_t=threading.Thread(target=dance)
sing_t.start()
dance_t.start()
while True:
length=len(threading.enumerate())
print('当前运行的线程数为:%d' %length)
time.sleep(2)
if length <=1:
print("主线程运行结束")
input()
break
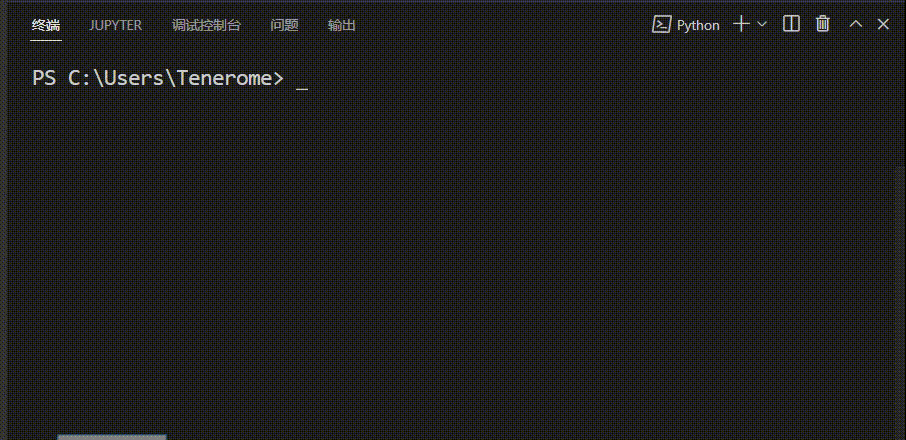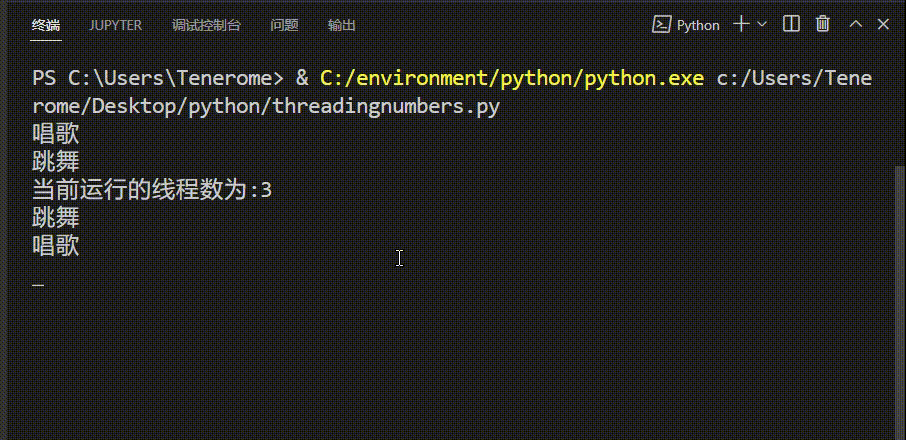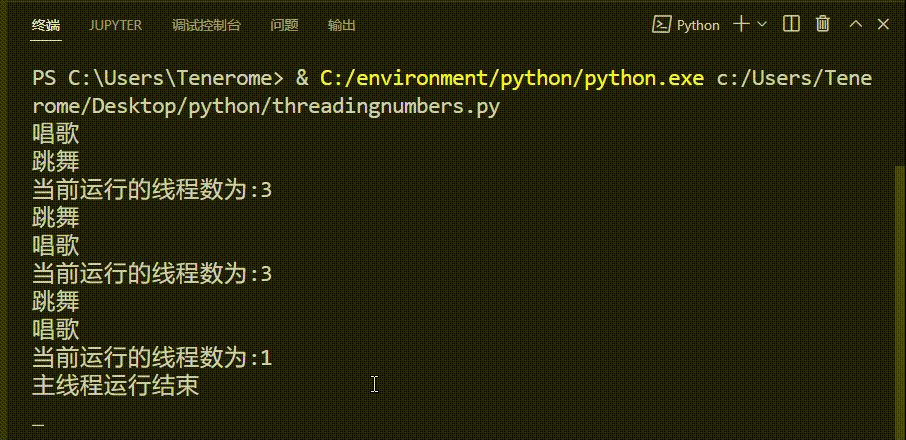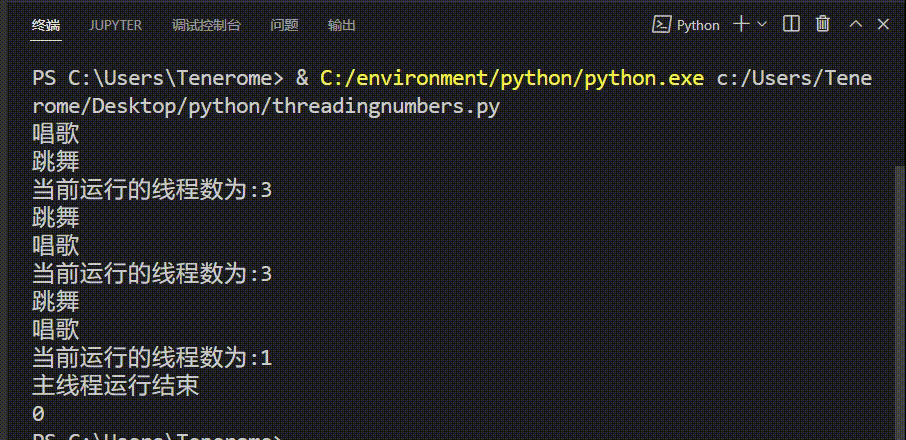
④线程类
除了通过Threading.Thread()函数创建线程对象外,话可以通过继承threading.Thread类在类中创建多个函数
Thread派生类中必须由一个run()函数
class MyThread(threading.Thread):
def run(self):
for i in range(5):
time.sleep(1)
print("线程名:%s" %(self.name + "-"+str(i)))
if __name__=="__main__":
threads=[]
for i in range(3):
t=MyThread()
threads.append(t)
for t in threads:
t.start()
线程名:Thread-69-0
线程名:Thread-68-0
线程名:Thread-70-0
线程名:Thread-70-1
线程名:Thread-68-1
线程名:Thread-69-1
线程名:Thread-70-2线程名:Thread-69-2
线程名:Thread-68-2
线程名:Thread-69-3线程名:Thread-70-3
线程名:Thread-68-3
线程名:Thread-69-4线程名:Thread-70-4
线程名:Thread-68-4
三个线程分别是Thread-41,40,39.分别做输出0-4的任务,三个线程并发执行,看着是同时执行的,实际是cpu快速切换,如果给线程执行后添加sleep(),就能看到实际还是一次只有一个线程执行
class MyThread(threading.Thread):
def run(self):
for i in range(5):
time.sleep(1)
print("线程名:%s" %(self.name + "-"+str(i)))
if __name__=="__main__":
threads=[]
for i in range(3):
t=MyThread()
threads.append(t)
for t in threads:
t.start()
time.sleep(6)#要让线程等待的时间大于每个线程的总执行时间,即6>5*1
线程名:Thread-79-0
线程名:Thread-79-1
线程名:Thread-79-2
线程名:Thread-79-3
线程名:Thread-79-4
线程名:Thread-80-0
线程名:Thread-80-1
线程名:Thread-80-2
线程名:Thread-80-3
线程名:Thread-80-4
线程名:Thread-81-0
线程名:Thread-81-1
线程名:Thread-81-2
线程名:Thread-81-3
线程名:Thread-81-4
⑤守护线程
如果一个线程别设置为守护线程,那么意味着这个线程是不重要的.如果主线程结束了,守护线程还没有运行完,那么它会被强制结束,在python中可以使用setDaemon方法来将某个线程设置为守护线程
(复制到独立文件运行)
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print("%s say hello" %name)
input()
if __name__=="__main__":
t=Thread(target=sayhi,args=('Tom',))#传参数是用元组传的
t.setDaemon(True)
t.start()
print("主线程")
print(t.is_alive())
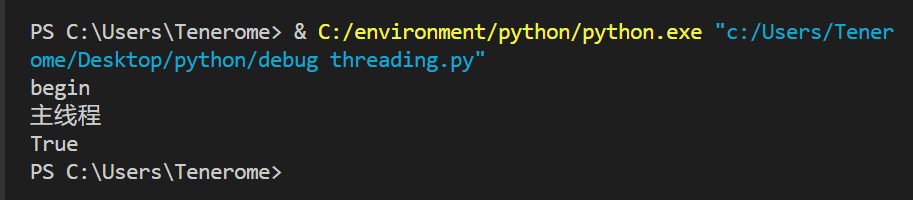
可以看到,程序开始执行,创建子线程t,子线程t启动并打印begin,然后休眠2秒,同时主线程打印"主线程",并输出子线程的状态仍alive,主线程结束,子线程也被结束掉了
⑥线程共享全局变量
from concurrent.futures import thread
import threading
import time
num=100
def test1():
global num
num+=100
def test2():
print("num=",num)
if __name__=="__main__":
t1=threading.Thread(target=test1)
t2=threading.Thread(target=test2)
t1.start()
time.sleep(2)
t2.start()
time.sleep(1)
print("num=",num)
num= 200
num= 200
⑦实例
import threading
import time
import requests
#spyder
url_start='http://xinwen.hrbcu.edu.cn/jxky.htm'
urls=[f'http://xinwen.hrbcu.edu.cn/jxky{i}.htm' for i in range(7,0,-1)]
urls.insert(0,url_start)
def craw(url):
r=requests.get(url)
print(url,len(r.text))
#单线程
def single_t():
print("单线称爬取")
for url in urls:
craw(url)
#多线程爬取
def multi_t():
print("多线程爬取")
threads=[]
for url in urls:
threads.append(threading.Thread(target=craw,args=(url,)))
for thread in threads:
thread.start()
for thread in threads:
thread.join()
#main
if __name__=="__main__":
start_time=time.time()
single_t()
end_time=time.time()
print("单线程爬取总时间:",end_time-start_time)
start_time=time.time()
multi_t()
end_time=time.time()
print("多线程爬取总时间:",end_time-start_time)
单线称爬取
http://xinwen.hrbcu.edu.cn/jxky.htm 28180
http://xinwen.hrbcu.edu.cn/jxky7.htm 1693
http://xinwen.hrbcu.edu.cn/jxky6.htm 1693
http://xinwen.hrbcu.edu.cn/jxky5.htm 1693
http://xinwen.hrbcu.edu.cn/jxky4.htm 1693
http://xinwen.hrbcu.edu.cn/jxky3.htm 1693
http://xinwen.hrbcu.edu.cn/jxky2.htm 1693
http://xinwen.hrbcu.edu.cn/jxky1.htm 1693
单线程爬取总时间: 0.7621386051177979
多线程爬取
http://xinwen.hrbcu.edu.cn/jxky6.htm 1693
http://xinwen.hrbcu.edu.cn/jxky5.htm 1693
http://xinwen.hrbcu.edu.cn/jxky7.htm 1693
http://xinwen.hrbcu.edu.cn/jxky4.htm 1693
http://xinwen.hrbcu.edu.cn/jxky3.htm 1693
http://xinwen.hrbcu.edu.cn/jxky1.htm 1693
http://xinwen.hrbcu.edu.cn/jxky2.htm 1693
http://xinwen.hrbcu.edu.cn/jxky.htm 28180
多线程爬取总时间: 0.18289875984191895
进程
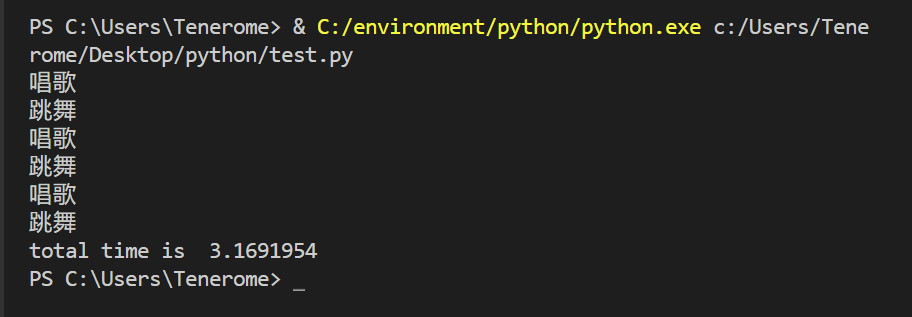
#在独立文件中运行
import multiprocessing
import time
def sing():
for i in range(3):
print("唱歌")
time.sleep(1)
def dance():
for i in range(3):
print("跳舞")
time.sleep(1)
if __name__=="__main__":
start_time=time.perf_counter()
processes=[]
p1=multiprocessing.Process(target=sing)
p2=multiprocessing.Process(target=dance)
processes.extend([p1,p2])
for p in processes:
p.start()
for p in processes:
p.join()
end_time=time.perf_counter()
print("total time is ",end_time-start_time)
input()
①通过多进程演示计算密集型任务以及进程池
语法方面和线程差不多
#判断是否为素数
import math
import time
import numpy as np
def run_time(f):
def inner():
start=time.time()
f()
end=time.time()
print('执行时间为%.3f ms'%((end-start)*1000))
return inner
def is_prime(n):
if n<2:
return False
if n==2:
return True
if n%2==0:
return False
sqrt_n=math.floor(math.sqrt(n))
for i in range(3,sqrt_n+1,2):
if n%i==0:
return False
return True
data=np.random.randint(1e8,1e9,100)
#单线程
@run_time
def single_thread():
for i in data:
is_prime(i)
print("单线程",end="")
single_thread()
#多线程
import threading
@run_time
def multi_threads():
threads=[]
for i in data:
t=threading.Thread(target=is_prime,args=(i,))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
print("多线程",end="")
multi_threads()
#多进程
import multiprocessing
@run_time
def multi_processes():
processes=[]
for i in data:
p=multiprocessing.Process(target=is_prime,args=(i,))
processes.append(p)
for p in processes:
p.start()
for p in processes:
p.join()
if __name__=='__main__':
print("多进程",end="")
multi_processes()
单线程执行时间为7.996 ms
多线程执行时间为38.205 ms
多进程执行时间为1405.988 ms
计算密集型任务,多线程比单线慢,因为多线程会交换使用GIL锁,而多进程更慢,因为进程的资源开销比线程大很多
传统进程池
#在独立文件中运行
from multiprocessing import Pool
@run_time
def pool_multi_processes():
pool=Pool(processes=4)
for i in data:
pool.apply_async(is_prime,(i,))
pool.close()
pool.join()
if __name__=='__main__':
print("进程池",end="")
pool_multi_processes()
进程池执行时间为437.055 ms
进程池的定义用Pool(),并可以用参数processes指定核心数.然后使用apply_async(func,args)来分配任务.进程池使用完需要关闭close(),最后一步的join()是等待pool中的所有进程执行完毕,才能继续后面的操作,它必须放在close()后面
新版进程池
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
@run_time
def multi_process():
with ProcessPoolExecutor(max_workers=4) as pool:
pool.map(is_prime,data)
print("新版进程池",end="")
multi_process()
新版进程池执行时间为198.224 ms
新版线程池
@run_time
def multi_thread():
with ThreadPoolExecutor() as pool:
pool.map(is_prime,data)
print("线程池",end="")
multi_thread()
线程池执行时间为18.909 ms
协程Coroutine
协程:可以在一个子程序中 中断,去执行其他子程序.这和函数调用不同,因为不会用到栈,而是类似cpu中断
比如A,B两个函数
def A():
print('1')
print('2')
print('3')
def B():
print('x')
print('y')
print('z')
假设由协程执行,在执行A的过程中,可以随时中断去执行B,B也可能在执行中随时中断,去执行A,就可能是这样的结果
1 2 x y 3 z
这样看起来有点像多线程并发的结果,但协程是在一个线程中实现的.协程的资源消耗很少,而且没有多线程下的锁机制
在python中,协程是通过生成器实现的
①非协程方式的函数调用
import time
def test1():
print("1",end=" ")
time.sleep(1)
def test2():
print("2",end=" ")
time.sleep(1)
def main():
for i in range(5):
test1()
test2()
main()
1 2 1 2 1 2 1 2 1 2
②使用生成器实现协程,函数内部通过yield语句实现"让出执行权"操作.与多线程相比,线程遇到I/O操作时会自动进行线程切换,线程切换是通过yield实现的.所以生成器实现的协程是一种半自动的协程
import time
def test1():
while True:
print("1",end=" ")
yield()
def test2():
while True:
print("2",end=" ")
yield()
def main():
t1=test1()
t2=test2()
for i in range(5):
next(t1)
next(t2)
main()
1 2 1 2 1 2 1 2 1 2
此时还是手动切换的程序,对yield进一步封装,可以使用第三方库greenlet实现协程,也可以对greenlet进一步封装,使用gevent库
使用gevent库实现多协程
②
gevent:
通过gevent实现coroutine.创建,调度的开销比线程小,执行效率高.gevent实现了python标准库中一些阻塞库的非阻塞版本:socket,os,select等.基本思想是:当一个greenlet遇到IO操作时,比如访问网络,就自动切换其他greenlet,等到IO操作完成,再适当的时候切回来继续执行.
gevent常用方法:
gevent.spawn()创建一个greenlet对象
gevent.getcurrent()返回当前正在执行的greenlet对象
monkey.patch_all(),猴子补丁,会自动将python的一些标准模块替换成gevent的非阻塞版本
gevent.join() 汇合语句,等待协程结束
gevent.joinall(greenlets):将多个greenlet对象放入列表中批量执行,相当于调用多次spawn和join
import time
def run_time(f):
def inner():
start=time.time()
f()
end=time.time()
print('执行时间为%.3f ms'%((end-start)*1000))
return inner
import gevent
def f(n):
for i in range(n):
print(gevent.getcurrent(),i)
gevent.sleep(0.5)
gevent.sleep()执行到这自动进行协程切换
@run_time
def gevent_test():
print('1')
g1=gevent.spawn(f,5)
print('2')
g2=gevent.spawn(f,5)
print('3')
g3=gevent.spawn(f,5)
g1.join()
g2.join()
g3.join()
if __name__=="__main__":
gevent_test()
1
2
3
<Greenlet at 0x26cf1556bf0: f(5)> 0
<Greenlet at 0x26cf1556e10: f(5)> 0
<Greenlet at 0x26cf19da040: f(5)> 0
<Greenlet at 0x26cf1556bf0: f(5)> 1
<Greenlet at 0x26cf1556e10: f(5)> 1
<Greenlet at 0x26cf19da040: f(5)> 1
<Greenlet at 0x26cf1556bf0: f(5)> 2
<Greenlet at 0x26cf1556e10: f(5)> 2
<Greenlet at 0x26cf19da040: f(5)> 2
<Greenlet at 0x26cf1556bf0: f(5)> 3
<Greenlet at 0x26cf1556e10: f(5)> 3
<Greenlet at 0x26cf19da040: f(5)> 3
<Greenlet at 0x26cf1556bf0: f(5)> 4
<Greenlet at 0x26cf1556e10: f(5)> 4
<Greenlet at 0x26cf19da040: f(5)> 4
执行时间为2549.958 ms
正常执行至少7.5s,使用协程后只需2.5s
③猴子补丁
猴子补丁:运行时打补丁,对于某模块,使用时像修改其中某几个功能,在不修改其源码和调用方式的前提下,把这几个功能替换为使用者自定义的功能,这就叫打上猴子补丁
例如开发初期使用的时import json,后来发现ujson性能更高,如果把每个文件的import json都改成import ujson as json成本较高,只需要在进程入口加上
import json
import ujson
def monkey_path_json():
json.__name__='ujson'
json.dumps=ujson.dumps
json.loads=ujson.loads
给程序打补丁monkey.path_all(),猴子补丁可以让gevent替换那些标准库中造成阻塞调用的标准库,(比如socket,os,select等)替换为gevent自己实现,不需要改动原来的代码即可变为非阻塞
import gevent
import time
from gevent import monkey
monkey.patch_all()
def run_time(f):
def inner():
start=time.time()
f()
end=time.time()
print('执行时间为%.3f ms'%((end-start)*1000))
return inner
def f(n):
for i in range(n):
print(gevent.getcurrent(),i)
time.sleep(0.5)#time.sleep()会被自动替换成gevent.sleep()
@run_time
def gevent_test():
print('1')
g1=gevent.spawn(f,5)
print('2')
g2=gevent.spawn(f,5)
print('3')
g3=gevent.spawn(f,5)
g1.join()
g2.join()
g3.join()
if __name__=="__main__":
gevent_test()
本文来自博客园,作者:Tenerome,转载请注明原文链接:https://www.cnblogs.com/Tenerome/articles/PythonCourse2.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号