

人工智能导论期末复习
人工智能导论期末考试
单择:10分
判断:20分
简答:40分
论述:16分
综合:14分
什么是人工智能
人工智能是一门关于研究知识的表示,知识的获取和知识的运用的学科
人工智能发展的五个阶段
萌芽期,启动期,消沉期,突破期,高速发展期
人工智能的流派:
三个流派:符号主义、连接主义、行为主义
符号主义:所有的知识都可以用符号来表示,它是一个物理符号系统,一切智能都是可以用逻辑关系来推理。
学派代表:图灵测试
连接主义:大脑和它的连接机制是一切智能的基础,所有智能都是可以通过大脑的神经元和它的处理信息的机制来实现的.
学派代表:神经网络,深度学习,语音识别,机器翻译
行为主义:取决于行动,类似于进化演化。行动后收到正收益就继续强化这个行动,如果负收益就不再进行这个行动,转向其他的行动,一切都是靠行为来决定的.
学派代表:Brooks的六足机器人
人工智能应用
无人驾驶,人脸识别,机器人,智能家居
人工智能研究的基本内容
知识表示:概念表示,知识表示,知识图谱
知识获取:搜索技术,群体智能,机器学习,深度学习
知识应用:机器证明,模式识别,数据挖掘,专家系统
机器学习包含
包括监督学习和无监督学习。
监督学习和无监督学习包含
监督学习包含:分类和回归,无监督学习包含聚类和关联分析
监督学习和无监督学习的具体解释
监督学习的信息是有标签,无监督学习的信息是无标签的
如果要预测的变量是连续的,监督学习的算法就是回归,线性回归就是能够找到这样的一条直线,尽量拟合所有的样本。
如果要预测的变量是离散的。监督学习的方法叫做分类。要预测的值都是离散的有限的点
无监督学习就是数据里面没有标签,我们把数据的特征提取出来,给他们做聚类。特征相似的点聚在一起,特征不相似的分开.
机器学习的过程
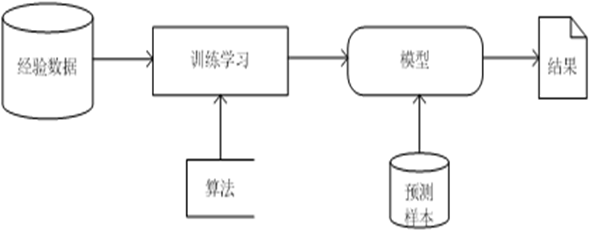
机器学习就是利用经验数据和算法来反复训练机器,获得一种处理数据的模型,然后机器就可以利用这个模型对新输入的数据进行计算,得到预测结果。
机器学习的三个因素
经验数据,模型,算法
梯度下降
线性回归要找一条直线,来拟合所有的点。找直线的过程,其实就是找这条直线中的一些参数的过程,利用所有的点,不断的使用梯度下降法,找到一个斜率导数最小值。就是我们要找到局部最优,有可能是全局最优
梯度下降中的几个概念
步长:也叫学习率,步长越短则下降速度越慢,步长越长,下降的速度是越快,但是往往不能达到最低点。
所以要开始时把步长设置的大点,下降到一定程度的时候,将步长缩短,这样既保证收敛的速度,也能保证找到最小值或极小值。
线性回归模型解决问题的一般步骤
(1):构建一个线性模型(函数)
(2):用已标注的样本数据对模型训练,训练过程中用梯度下降法调整模型参数
(3):重复步骤2,直至找到损失函数的最小值
(4):用验证集去测试模型的精度 (评价指标常用均方误差MSE)
(5):如果预测结果不理想,则需改进模型(加大训练集,改变学习率等)
(6):回到第二步,重新训练模型,直至理想模型
(7):用未来的自变量和模型去预测y值
分类的工作过程
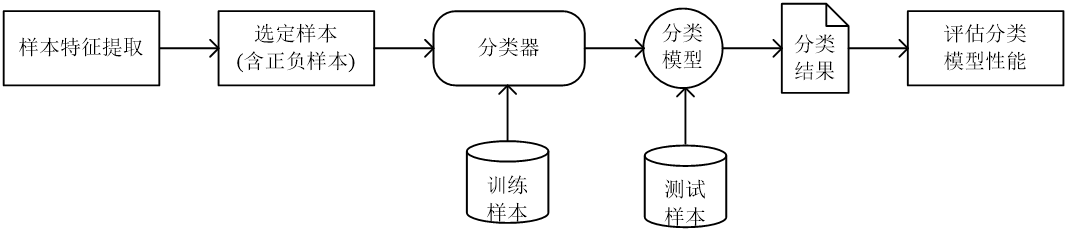
首先做样本特征提取,然后拿到一个分类器做训练。训练之后,得到一个模型。得到模型之后,我们测试一下,就是评估这个模型的性能。如果是可以,我们就可以拿这个模型进行预测。
正负样本
正样本是我们想要正确分类出的类别所对应的样本。它指的不是这个好的,坏的什么的.
几种分类算法
决策树:结构类似于二叉树,基于规则分类
贝叶斯分类器:根据概率分类
最近邻分类器:k nearest neighbor 也叫knn ,通过测量不同特征值之间的距离进行分类
支持向量机:定义在特征空间上的间隔最大的线性分类器
神经网络:分输入层,隐藏层,输出层
KNN分类器
基本思想:如果一个样本在特征空间中的k个最相近的样本中的大多数属于某一个类别,则该样本也属于这个类别
KNN手写数字识别的过程
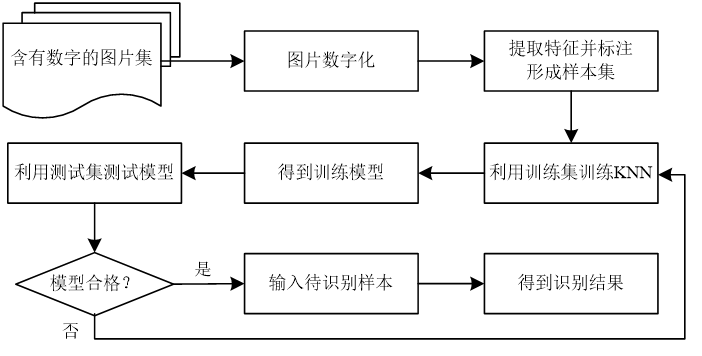
图像灰度化的作用
因为图片数据的每个像素点有三原色rgb ,灰度化之后,只要一个值就可以了。缩小了数据量,能提高计算速度。
KNN的主要参数
| 参数 | 含义 | 备注 |
|---|---|---|
| k | 周围的邻居数。显然k值过大过小都不好,可以尝试多次。 | 如果训练集较小,可选择训练集样本数量的平方根,一般为奇数。 |
| weights | 近邻的权重。一般来说距离预测目标更近的近邻具有更高的权重,因为较近的近邻比较远的近邻更有投票权。 | 一般选择权重和距离成反比例。 |
| p | 距离度量方法 | 常用欧式距离,还有曼哈顿距离 |
分类性能度量指标
准确率accuracy:指在所有样本中被正确预测的样本的比例
正确率precision:指被预测为正样本中真正正样本所占的比例
召回率recall:指被正确预测的正样本占所有正样本的比例
F1值:结合了正确率和召回率,最准确的评估指标
支持向量机
基本思想:根据样本点的分布,通过升维把样本点置于三维或更高维的空间,通过一个平面或超平面把样本点给它分开,用两类之间的支持向量做边界。
用svm支持向量机预测乳腺癌细胞的流程
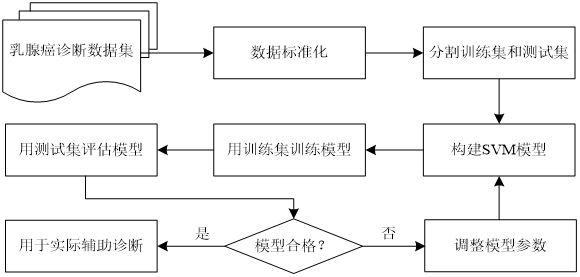
拿到数据集后进行数据标准化。然后分割训练集和测试集,构建svm模型,构建模型之后,训练模型。之后再测试,测试模型是不是合格,如果不合格,再调整参数,重新训练。合格之后,就可以做预测了
svm最优分界面
最优分界面是通过支持向量分出来的,得到的最优分界面不仅能将两类数据分离开来,同时能使其到两边临界分界面距离最大
svm核函数的作用
核函数K(x,y):能够将输入的空间样本变换到高维输出空间,使原本不能线性分割的问题变得线性可分
核函数的三个参数
| 参数 | 含义 | 备注 |
|---|---|---|
| kernel | 核函数,有线性linear、多项式poly、径向基rbf、sigmoid等 | 常用rbf |
| C | 惩罚参数,C越大,对误分类的惩罚增大,训练误差低,但泛化能力弱;C值小,对误分类的惩罚减小,训练误差大,但泛化能力较强 | 一般C在[0.5,1]内取值,可以采用交叉验证方法选最优值 |
| gamma | 核函数参数 | 仅对poly、rbf和sigmoid有效 |
聚类和分类的区别
分类是监督学习,聚类是无监督学习
分类的数据带标签,聚类的数据不带标签,所以聚类是要提取标签的
什么是聚类分析
是一种无监督学习,在事先不知道每个样本的类别,没有对应的标签值的情况下,可以对未知类别的样本按照一定的规则划分成若干个类簇
类簇的两个特点
同一个类中样本尽可能相似
不同类簇中样本尽可能不相似
聚类的基本特征
聚类中心:一个簇中所有样本点的均值,也叫质心
簇大小:表示一个簇中所含的样本的数量
簇密度:表示簇中样本点的紧密程度,越紧密,说明簇内样本的相似度越高
常见的聚类方法。
基于划分的聚类,基于层次的聚类,基于密度的聚类(还有网格,模型等)
聚类的性能度量
外部指标
要事先指定聚类模型作为参考来评价聚类结果好坏,被称为有标签的聚类
内部标签
轮廓系数SC:S取值在[-1,1]之间,值越大,说明同类样本越接近,聚类效果越好
CH分数:CH值越大,类别内部协方差越小,聚类效果越好
戴维森堡丁指数DBI:DBI越小,簇内样本之间的距离越小,聚类效果越好
k均值算法
k均值(K-means)是一种基于划分的聚类方法,通过样本间的距离来衡量他们之间的相似度。,两个样本距离越远,相似度越低,否则相似度越高
算法的流程
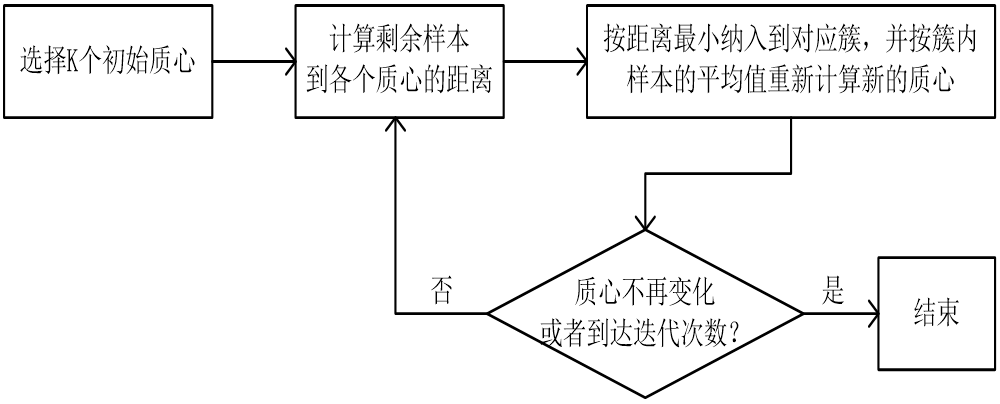
K均值的几个参数
K的初始值
K初值取决于业务需求或分析动机,不确定时常用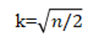 .其中n是样本总数.
.其中n是样本总数.
初始质心的选择
(方法1是如果事先知道某几个样本是彼此完全不同的,就选择他们为质心;
方法2是跳出样本范围,在特征空间任意地方取随机值为质心;
方法3是分段选质心,第1个质心随机取,其它质心按距离已定质心最远的样本点来选取。)
聚类完毕后,所有样本是有簇号的
也就是原来没有标签的样本,经过聚类后都会给一个标签号
聚类结束的条件
当样本数量很大时,或定义的聚类误差很严苛时,为避免聚类运行陷入迟迟不出结果的尴尬局面,就必须设定最大迭代次数和误差阈值,满足其一即可停止聚类。
随机种子random state
不只是在聚类,在很多数据分割中,都有random state 随机种子。设置相同的种子,能够保证随机分割的数据的结果复现.
rfm模型
它不是机器学习中的模型,而是商业上的一个模型,rfm 也是应用最广的识别客户的模型。
r :表示客户最近一次的消费时间和截止时间的间隔。
f :这个某段时间内消费次数
m: 某段时间内的消费总额
推荐系统两个特征
主动化和个性化
冷启动
指新用户注册或者新物品入库,该怎么样给新用户提供推荐服务或怎么将新物品推荐出去
推荐系统主要的算法
协同过滤,基于内容的推荐,关联规则
什么是协同过滤
包括基于用户的协同过滤,基于物品的协同过滤和隐语义模型等
基于用户的协同过滤:
基本思想:给用户推荐和他兴趣相似的用户感兴趣的物品
计算协同过滤中的用户之间的相似度,可以用皮尔逊相关系数,余弦向量相似度。
基于物品的协同过滤:
基本思想:给用户推荐与他们以前喜欢的物品相似的物品
基于内容的推荐:
基本思想:为用户推荐与他感兴趣的内容相似的物品
基于关联规则
基本思想:基于物品之间的关联性,通过对顾客的购买记录进行规则挖掘,发现不同顾客群体之间共同的购买习惯,从而实现顾客群的兴趣建模和商品推荐
推荐方法
评分预测:根据打分
TopN推荐:提供个性化推荐列表
评估方法
离线实验,用户调查,在线实验等
评测指标
评估效果分定量分析和定性评价
优先使用定量分析,其常用的指标有:满意度,预测准确度,覆盖率等
综合题(代码题)
线性回归步骤
1,导入数据,处理数据
2,分隔数据集,线性回归用sample()分割
train_data=df.sample(frac=0.8,replace=False)
test_data=df.drop(train_data.index)
x_train=train_data['area'].values.reshape(-1,1)
y_train=train_data['price'].values
x_test=test_data['area'].values.reshape(-1,1)
y_test=test_data['price'].values
3,创建线性模型对象SGD或Linear
model=...
4,训练模型,训练的是x,y的train(通用)
model=fit(x_train,y_train)
5,获得系数和截距
model.coef_
model.inception_
6,获得预测集,用x_test,获取y_pred(通用)
y_pred=model.predict(x_test)
7,计算损失函数
MSE=np.mean((y_test-y_pred)**2)
8,模型自带评分,评分用的是x,y的test(通用)
model.score(x_test,y_test)
分类步骤
1,导入数据,处理数据
2,分割数据集
x_train,y_train,x_test,y_test=train_test.split(...)
3,构建模型
KNN,SVM=.....
4,训练模型
KNN,SVM.fit(x_train,y_train)
5,模型自带评分
KNN,SVM.score(x_test,y_test)
6,获取预测集
y_pred=KNN,SVM.predict(x_test)
7,性能指标,用的是y_test,和y_pred,测试集和预测集
from sklearn.metrics import classification_report
classification_report(y_test,y_pred)
8,交叉表(混淆矩阵),用的也是测试集和预测集
要先将数据转成矩阵
from sklearn.metric import confusion_matrix
y_test=np.array(y_test)
confusion_matrix(y_test,y_pred)
pd.crosstab(y_test,y_pred)
详解
①线性回归-房屋价格预测
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#导入处理数据
# sep:分隔符,不能少了空格,不然识别不出来后一列,导致x列和y列不相等的错误
# house.txt中的两列中间都必须是,和空格,不然也无法识别
# header:用第0行的字符做列表头
df=pd.read_csv('data\house.txt',sep=', ',header=0)
# scatter()是绘制散点图的函数,前两个参数是横纵坐标,c是颜色
plt.scatter(df['area'],df['price'],c='purple')
# 选择80%作为训练集,20%作为测试集sample()分割数据集的
train_data=df.sample(frac=0.8,replace=False)
test_data=df.drop(train_data.index)
# 转成数组形式,便于矩阵计算
x_train=train_data['area'].values.reshape(-1,1)
y_train=train_data['price'].values
x_test=test_data['area'].values.reshape(-1,1)
y_test=test_data['price'].values
#构建模型
from sklearn.linear_model import SGDRegressor
import joblib
# 构建线性回归模型,迭代次数500,学习率初始值0.01,并在学习过程中自动优化更新
model=SGDRegressor(max_iter=500,learning_rate='optimal',eta0=0.01)
# .fit()就是开始训练模型
model.fit(x_train,y_train)
# .score()是模型自带的评分
pre_score=model.score(x_train,y_train)
print('score=',pre_score)
# coef_是系数,intercept_是截距,就是一元线性方程的两个参数
print('coef=',model.coef_,'intercept=',model.intercept_)
# 保存训练后的模型到指定位置,便于后续调用该训练好的模型
joblib.dump(model,'.\SGDRegress.model')
# 加载之前训练好的模型
model=joblib.load('.\SGDRegress.model')
# 利用模型对测试集预测
y_pred=model.predict(x_test)
print('测试集准确得分=%.5f'%model.score(x_test,y_test))
# 计算损失MSE
MSE=np.mean((y_test-y_pred)**2)
print('损失MSE={:.5f}'.format(MSE))
绘图
# 绘制预测效果图
# rcParams[]用来指定字体
plt.rcParams['font.sans-serif']=['SimHei']
# figure()设置长宽,10英寸X4英寸
plt.figure(figsize=(10,4))
# Subplot()设置图像数量和排列,三个参数分别是行,列,次序
# 这里是1行2列,也就是两个图,ax1在第一个
ax1=plt.Subplot(121)
plt.scatter(x_test,y_test,label='测试集')
# plot()函数用来画点的图
plt.plot(x_test,y_pred,'orange',label='预测回归线')
ax1.set_xlabel('面积')
ax1.set_ylabel('价格')
# legend()指定图显示的位置,为左上
plt.legend(loc='upper left')
# 第二个图ax2,在第二个位置
ax2 = plt.subplot(122)
x=range(0,len(y_test))
plt.plot(x,y_test,'pink',label='真实值')
plt.plot(x,y_pred,'red',label='预测值')
ax2.set_xlabel('样本序号')
ax2.set_ylabel('价格')
plt.legend(loc='upper right')
# plt.show()显示图片
plt.show()
②线性回归-预测投保人医疗费用
Pandas读取数据后返回的数据类型是数据框架DataFrame,为方便对DataFrame数据进行检索,pandas提供了loc、iloc两种灵活的访问数据的方式。
loc():按名称进行切分,格式:
DataFrame.loc[行索引名称或检索条件,列索引名称]
iloc():按索引位置进行切分,格式:
DataFrame.iloc[行索引位置,列索引位置]
Eg.
filter_data=df.loc[df['年龄']>18,['性别','年龄']]
选取 年龄>18的, 性别,和年龄 列 数据
数据清洗和转换
df.loc[df['sex']'female','sex']=0
df.loc[df['sex']'male','sex']=1
就是把sex==female的sex设置成0,sex=male的sex设置成1
数据归一化:就是把量级不同的数据都处理成[0,1]之间
# 导入MinMaxScaler类对df中的数据进行[0,1]归一化处理
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
# 拟合训练集,求得训练集的固有属性,如最大值,最小值,均值,方差等
scaler.fit(df)
# 缩放训练集,再fit()基础上进行归一化
df1=scaler.transform(df)
df1
构建线性回归模型
# 采用线性模型包linear_model中的LinearRegression类来构建模型
from sklearn.linear_model import LinearRegression
# 线性回归模型model
model=LinearRegression()
# 样本集中特征输入数据为0-5列,第6列为标签医疗费用
from sklearn.model_selection import train_test_split
# data是自变量,target是因变量,就是要预测的结果
# df[left:right],left是行,:表示选取所有行,right是列
train_data=df1[:,[0,1,2,3,4,5]]
train_target=df1[:,[6]]
# train_test_split()用来分隔数据集,test_size表示测试集的大小
x_train,x_test,y_train,y_test=train_test_split(train_data,train_target,test_size=0.3)
③KNN分类器-手写数字识别
构建模型
# 导入k近邻类
from sklearn.neighbors import KNeighborsClassifier
# 创建分类模型对象
Knn=KNeighborsClassifier(n_neighbors=43,weights='distance',p=2)
评估
from sklearn.metrics import classification_report
y_pred=Knn.predict(x_test)
# 性能指标,用classification_report()
print(classification_report(y_test,y_pred))
交叉表(混淆矩阵)
from sklearn.metrics import confusion_matrix
y_test=np.array(y_test)
confusion_matrix(y_test,y_pred)
pd.crosstab(y_test,y_pred,rownames=['真实值'],colnames=['预测值'],margins=True)
④SVM分类器-乳腺癌诊断
# 将y列转换成一维数组,即455行1列的数据转成1行,455个元素
y_train=y_train.values.ravel()
y_test=y_test.values.ravel()
构建SVM模型
# 导入支持向量机SVM模块
import sklearn.svm as svm
# 高斯核函数rbf构建模型,惩罚参数C取1
model=svm.SVC(C=1,kernel='rbf')
⑤聚类-鸢尾花
降维,绘制散点图
import matplotlib.pyplot as plt
# 从流形模块中导入降维类TSNE
from sklearn.manifold import TSNE
import numpy as np
import pandas as pd
datas=pd.read_csv(r'./iris.csv',sep=',')
# 创建一个二维的降维对象tsne
# 设置嵌入的初始化和学习率
tsne=TSNE(n_components=2,init='random',learning_rate='auto')
# 将原来四维的数据集进行降维转换,生成二维数据集X_2d
X_2d=tsne.fit_transform(datas)
plt.figure(figsize=(9,6))
plt.plot(X_2d[:,0],X_2d[:,1],'k*')
plt.show()
绘制K值和轮廓系数变化图
iris_data=pd.read_csv(r'./iris.csv',sep=",")
sc=[]
for i in range(2,9):
# 对鸢尾花样本数据iris_data按K_means算法进行聚类训练
Kmeans=KMeans(n_clusters=i,random_state=151).fit(iris_data)
# 利用指标函数silhouette_score计算聚类后的轮廓系数值score
score=silhouette_score(iris_data,Kmeans.labels_)
sc.append(score)
plt.plot(range(2,9),sc,linestyle='-')
plt.xlabel('k')
plt.ylabel('silhouette_score')
plt.show()
选择题
第一单元

第二单元

第三单元

第四单元

第五单元

本文来自博客园,作者:Tenerome,转载请注明原文链接:https://www.cnblogs.com/Tenerome/articles/AIExam.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号