
如何让Redis支持高可用
Redis实现高可用,支持三种集群模式:主从模式、哨兵模式以及cluster模式。
主从模式
定义
在Redis集群中,让若干个Redis服务器去复制另一个Redis服务器,我们定义被复制的服务器为主服务器(master),而对主服务器进行复制的服务器则被称为从服务器(replica),这种模式叫做主从复制模式。
作用
- 为数据提供多个副本,支持高可用。
- 实现读写分离(主节点负责写,从节点负责读,主节点定期将数据同步到从节点,保证数据的一致性)。
- 任务分离,如从服务器负责备份工作和计算工作。
主从复制的特点
- 主节点可以进行读写操作,当主节点数据变化后会自动将数据同步给从节点;
- 从节点一般都是只读的;
- 一个master可以拥有多个replica,但是一个replica只能有一个master;
- 其中一个replica挂了不影响其他replica的读和master的读和写,重新启动后会将数据从master同步过来;
- master挂了后不影响replica节点的读,但不再提供写服务,master重启后redis将重新对外提供写服务;
- master挂了后,不会在replica节点中重新选一个master;
工作机制
当replica启动后,主动向master发送SYNC命令。master接收到SYNC命令后在后台保存快照(RDB持久化)和缓存保存快照这段时间的命令,然后将保存的快照文件和缓存的命令发送给replica。replica接收到快照文件和命令后加载快照文件和缓存的执行命令。
复制初始化后,master每次接收到的写命令都会同步发送给slave,保证主从数据一致性。
主从复制搭建
环境准备
实现一主两从,同一台服务器上,master端口6379;两个replica,一个端口6380,另一个端口6381,如下图所示。
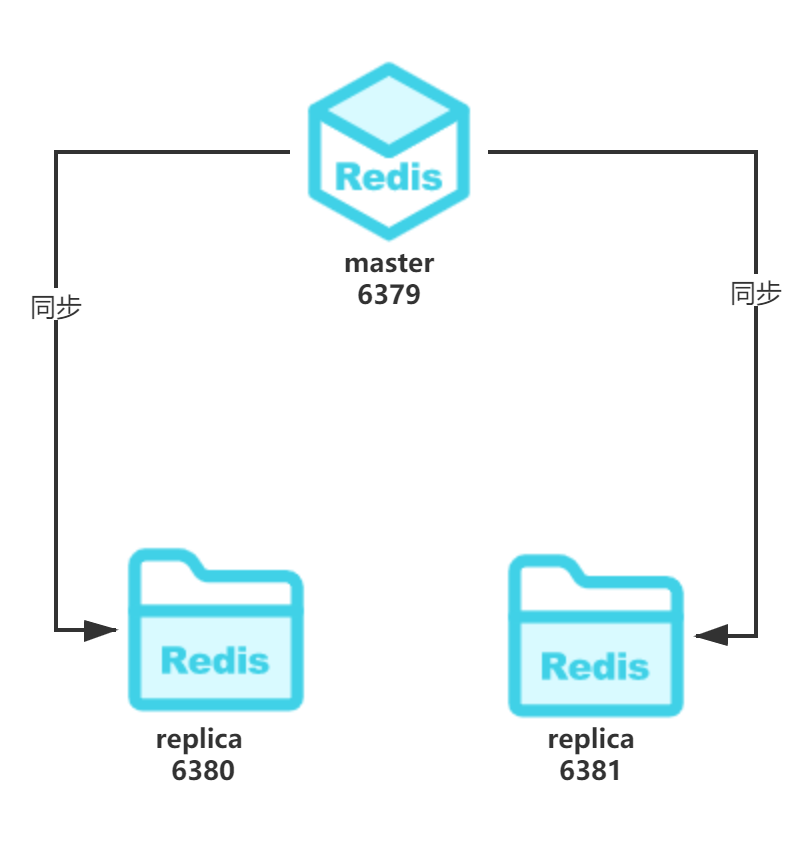
配置
复制redis.conf文件,生成redis6380.conf以及redis6381.conf文件
master配置
可以关闭rdb快照功能,将备份工作交给replica节点,aof功能可以开着,也可以关闭;
replica配置
- replicaof
:配置master服务的ip和端口,这样就建立起主从关系了。 - masterauth
:如果master需要密码认证,这里需要配置master的密码,否则连接不上; - replica-read-only:默认为yes,配置从服务默认为只读模式。
其中6380从服务的具体配置如下,6381的配置也是类似。
port 6380
pidfile /var/run/redis_6380.pid
save 900 1
save 300 10
save 60 10000
dbfilename dump6380.rdb
replicaof localhost 6379
replica-read-only yes
appendonly yes
appendfilename "appendonly6380.aof"
测试
执行命令,通过redis客户端分别连接到主从redis服务
./redis-cli -p 6379
./redis-cli -p 6380
./redis-cli -p 6381
主服务中查看replica信息
info replication
显示信息
# Replication
role:master
connected_slaves:2
slave0:ip=::1,port=6380,state=online,offset=123023,lag=0
slave1:ip=::1,port=6381,state=online,offset=123023,lag=0
master_replid:37d7bc32b5aca031ba762585137da938c78a77dc
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:123023
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:123023
从服务中查看信息
# Replication
role:slave
master_host:localhost
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:123205
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:37d7bc32b5aca031ba762585137da938c78a77dc
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:123205
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:123205
redis主服务中添加名为name的key,在从服务中查看是否实现同步复制,如下面所示。
127.0.0.1:6379> set name vic
OK
127.0.0.1:6379>
127.0.0.1:6380> get name
"vic"
127.0.0.1:6381> get name
"vic"
至此,主从复制配置完成。
主从复制模式配置遇到的坑
按照之前的配置,我发现redis的主从配置没有生效,从服务并没有连接到主服务,显示如下。
master_link_status:down
本以为是防火墙问题,6379的端口没有打开,但通过netstat -lntp命令查看端口是开着的,又想着是不是主服务配置了密码,然后从服务没有配置密码引起的,结果发现并不是。
最后通过注释掉主服务的redis.conf文件里的bind 127.0.0.1就解决此问题了。
#bind 127.0.0.1
哨兵模式
概述
哨兵模式是一种特殊的模式,哨兵是一个独立的进程,通过发送命令,等待Redis服务器响应,从而监控多个Redis实例,如下图所示。当主从服务中,主服务挂掉后,可以自动实现故障切换,而不需要手动去操作,因此更为推荐这种模式。
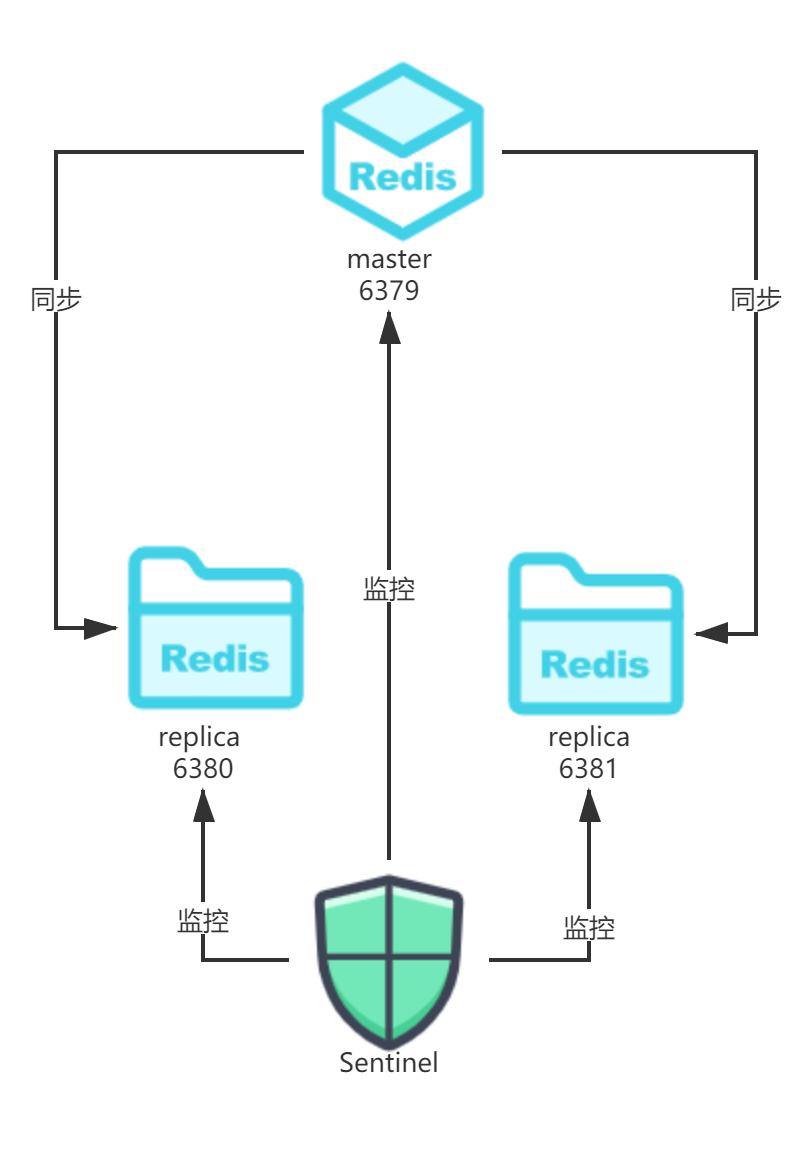
原理
哨兵的作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
在Redis高可用架构中,Sentinel往往不是只有一个,而是有3个或者以上。目的是为了让其更加可靠,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式
故障切换
当检测到主节点宕机后,断开与宕机主节点连接的所有从节点,在从节点中选取一个作为主节点,然后将其他的从节点连接到这个最新主节点的上。并且告知客户端最新的服务器地址。
相关概念
主观下线
SDOWN(subjectively down),直接翻译的为主观下线,即当前sentinel实例认为某个redis服务为不可用状态.
客观下线
ODOWN(objectively down),直接翻译为客观下线,即多个sentinel实例都认为master处于SDOWN状态,那么此时master将处于ODOWN,ODOWN可以简单理解为master已经被集群确定为”不可用”,将会开启failover。
哨兵环境搭建
在原来的主从复制测试环境的基础上,再配置sentinel.conf,并启动哨兵进程。
| 服务类型 | 主/从 | 端口 |
|---|---|---|
| Redis | 主 | 6379 |
| Redis | 从 | 6380 |
| Redis | 从 | 6381 |
| Sentinel | - | 26379 |
| Sentinel | - | 26380 |
| Sentinel | - | 26381 |
配置
sentinel.conf文件,复制三份,并进行修改,主要配置参数如下,三个文件区别主要是端口修改下,从26379~26381。
#当前Sentinel服务运行的端口
port 26379
# 第一行配置指示 Sentinel去监视一个名为 mymaster的主服务器,这个主服务器的IP地址为127.0.0.1,端口号为6379,而将这个主服务器判断为失效至少需要2个Sentinel同意
sentinel monitor mymaster 127.0.0.1 6379 2
# 10s内mymaster无响应,则认为mymaster宕机了
sentinel down-after-milliseconds mymaster 10000
#如果20秒后,mysater仍没启动过来,则启动failover
sentinel failover-timeout mymaster 20000
# 执行故障转移时, 最多有1个从服务器同时对新的主服务器进行同步
sentinel parallel-syncs mymaster 1
启动哨兵进程
/usr/local/bin/redis-sentinel sentinel.conf --sentinel &
/usr/local/bin/redis-sentinel sentinel6380.conf --sentinel &
/usr/local/bin/redis-sentinel sentinel6381.conf --sentinel &
测试验证
哨兵集群启动后,将6379主服务shutdown,这时候哨兵集群就会认定6379已经宕机,从而在6380和6381两台从服务里选举一个服务升级为master,然后再通知另一个服务,并自动修改它的配置文件,让它指向新的master,比如6380变成master,则6381则会自动变成6380的replica,当然如果我们现在再将6379启动起来,同样6379也会变成6380的replica,从而实现redis的故障自动转移。
遇到的坑
23617:X 19 Aug 2020 16:01:43.844 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
23617:X 19 Aug 2020 16:01:43.844 # Sentinel ID is 6c4ad4b0df82b09a7d3078927182b59da3becb5f
23617:X 19 Aug 2020 16:01:43.844 # +monitor master mymaster 127.0.0.1 6379 quorum 1
23617:X 19 Aug 2020 16:01:43.845 * +slave slave [::1]:6380 ::1 6380 @ mymaster 127.0.0.1 6379
23617:X 19 Aug 2020 16:01:43.850 * +slave slave [::1]:6381 ::1 6381 @ mymaster 127.0.0.1 6379
23617:X 19 Aug 2020 16:01:53.867 # +sdown slave [::1]:6381 ::1 6381 @ mymaster 127.0.0.1 6379
23617:X 19 Aug 2020 16:01:53.867 # +sdown slave [::1]:6380 ::1 6380 @ mymaster 127.0.0.1 6379
23617:X 19 Aug 2020 16:03:55.606 # +sdown master mymaster 127.0.0.1 6379
23617:X 19 Aug 2020 16:03:55.606 # +odown master mymaster 127.0.0.1 6379 #quorum 1/1
23617:X 19 Aug 2020 16:03:55.606 # +new-epoch 1
23617:X 19 Aug 2020 16:03:55.606 # +try-failover master mymaster 127.0.0.1 6379
23617:X 19 Aug 2020 16:03:55.610 # +vote-for-leader 6c4ad4b0df82b09a7d3078927182b59da3becb5f 1
23617:X 19 Aug 2020 16:03:55.610 # +elected-leader master mymaster 127.0.0.1 6379
23617:X 19 Aug 2020 16:03:55.610 # +failover-state-select-slave master mymaster 127.0.0.1 6379
23617:X 19 Aug 2020 16:03:55.669 # -failover-abort-no-good-slave master mymaster 127.0.0.1 6379
23617:X 19 Aug 2020 16:03:55.735 # Next failover delay: I will not start a failover before Wed Aug 19 16:09:55 2020
原因:脑裂
脑裂,也就是说,某个 master 所在机器突然脱离了正常的网络,跟其他 slave 机器不能连接,但是实际上 master 还运行着。此时哨兵可能就会认为 master 宕机了,然后开启选举,将其他 slave 切换成了 master。这个时候,集群里就会有两个 master ,也就是所谓的脑裂。
解决方法
min-slaves-to-write 1
min-slaves-max-lag 10
表示,要求至少有 1 个 slave,数据复制和同步的延迟不能超过 10 秒。
如果说一旦所有的 slave,数据复制和同步的延迟都超过了 10 秒钟,那么这个时候,master 就不会再接收任何请求了。
cluster模式
哨兵解决和主从不能自动故障恢复的问题,但是同时也存在难以扩容以及单机存储、读写能力受限的问题,并且集群之前都是一台redis都是全量的数据,当并发量很高的时候,会遇到内存、并发、存储等的瓶颈,因此需要真正的分布式架构来进行负载均衡。
简介
cluster模式实现了Redis数据的分布式存储,实现数据的分片,每个redis节点存储不同的内容,并且解决了在线的节点收缩(下线)和扩容(上线)问题。
redis cluster 主要基于 CRC16 算法对 key 进行 hash ,然后散列到不同散列槽。
redis cluster 总共提供 16384 个hash 槽(slot) ,理论上,集群的最大节点数量最大为 16384 个。不过 redis 官方给出的建议是不要超过 1000 的量级。每个 redis instance 会负责这个散列槽中的一部分。新增或删除节点,对于 redis cluster 而言就是对 slot 进行 reshard,redis cluster 保证 slot 平滑移动。
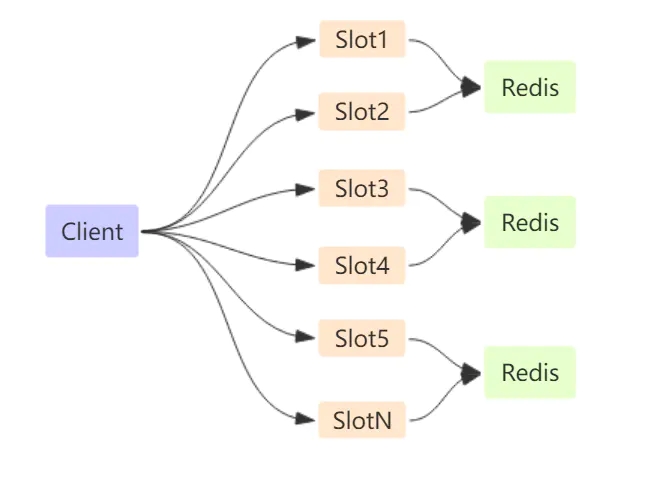
- 优点:无中心节点(所有Redis节点都是对等的节点,同步数据使用的是Gossip协议),数据按照槽存储分布在多个 Redis 实例上,可以平滑的进行节点 扩容/缩容,当节点数量改变时,只需要动态更改节点负责的槽就行,这对于客户端来说是透明的。不需要依赖中间件,运维成本低。
- 缺点:严重依赖 Redis-trib 工具,缺乏监控管理,Failover节点的检测过慢,Gossip协议传播消息到最终一致性有一定的延迟。
通信机制
Redis cluster 节点间采用 gossip 协议进行通信。
gossip协议
gossip协议包含多种消息,包含 ping , pong , meet , fail 等等。
- meet:某个节点发送 meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其它节点进行通信。
- ping:每个节点都会频繁给其它节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过 ping 交换元数据。
- pong:返回 ping 和 meeet,包含自己的状态和其它信息,也用于信息广播和更新。
- fail:某个节点判断另一个节点 fail 之后,就发送 fail 给其它节点,通知其它节点说,某个节点宕机
分布式寻址算法
- hash算法
- 一致性hash算法
- hash slot算法(redis cluster采用)
Redis cluster 有固定的 16384 个 hash slot,对每个 key 计算 CRC16 值,然后对 16384 取模,可以获取 key 对应的 hash slot。
Redis cluster 中每个 master 都会持有部分 slot,比如有 3 个 master,那么可能每个 master 持有 5000 多个 hash slot。hash slot 让 node 的增加和移除很简单,增加一个 master,就将其他 master 的 hash slot 移动部分过去,减少一个 master,就将它的 hash slot 移动到其他 master 上去。移动 hash slot 的成本是非常低的。客户端的 api,可以对指定的数据,让他们走同一个 hash slot,通过 hash tag 来实现。
任何一台机器宕机,另外两个节点,不影响的。因为 key 找的是 hash slot,不是机器。
高可用与主备切换原理
Redis cluster 的高可用的原理,几乎跟哨兵是类似的。
- 判断节点宕机
- 从节点过滤
- 从节点选举
相比哨兵模式,Redis cluster 功能强大,直接集成了 replication 和 sentinel 的功能。
cluster环境搭建
redis 集群一般由多个节点组成,节点数量至少为6个,才能保证组成 完整高可用的集群。每个节点需要开启配置 cluster-enabled yes,让 redis 运行在集群模式下。
因此搭建三主三从,主服务分别为7000,7001,7002,从服务分别为7003,7004,7005。如下图所示。
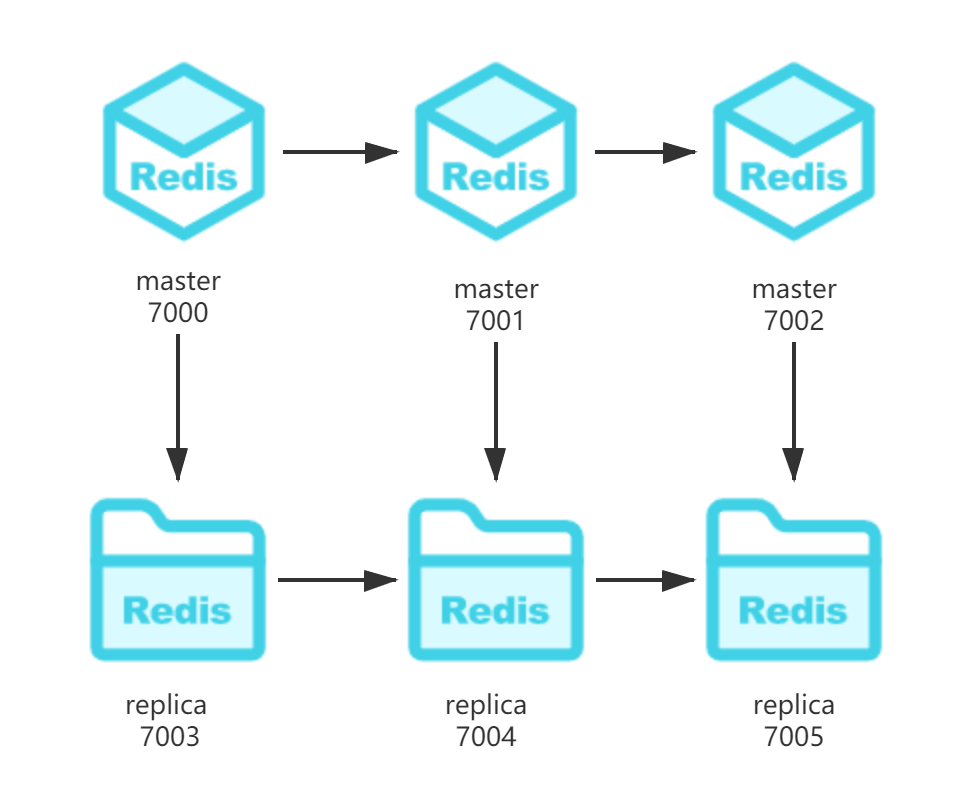
配置文件
编辑redis.conf文件,复制5份,将其中的7000进行替换修改,主要配置如下:
port 7000
daemonize yes
pidfile /home/redis/tmp/scripts-redis/cluster/pid/pid_7000.pid
bind 127.0.0.1
loglevel notice
logfile /home/redis/tmp/scripts-redis/cluster/log/log_7000.log
dbfilename "dump.rdb"
dir "/home/redis/tmp/scripts-redis/cluster/data/7000"
cluster-enabled yes
cluster-config-file "/home/redis/tmp/scripts-redis/cluster/config/nodes_7000.conf"
cluster-node-timeout 5000
启动服务
/usr/local/bin/redis-server redis7000.conf
/usr/local/bin/redis-server redis7001.conf
/usr/local/bin/redis-server redis7002.conf
/usr/local/bin/redis-server redis7003.conf
/usr/local/bin/redis-server redis7004.conf
/usr/local/bin/redis-server redis7005.conf
启动命令后结果如下图所示。

创建集群
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
执行命令后,输出如下图所示。
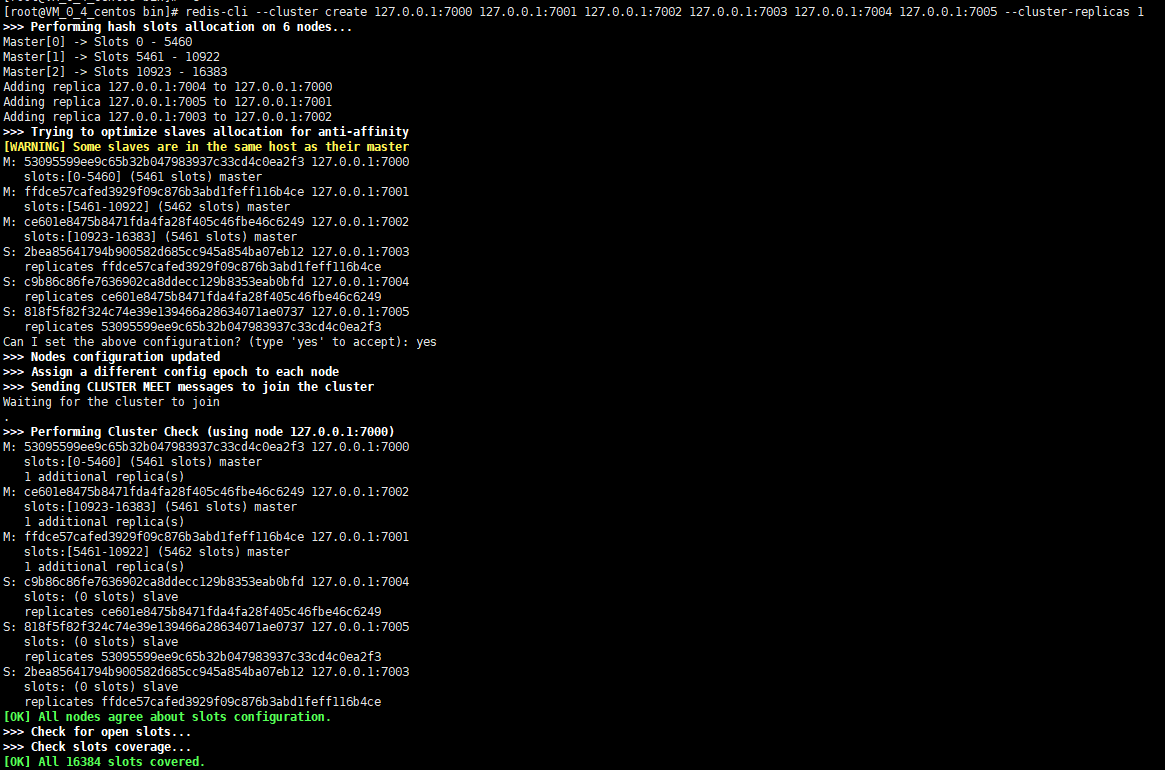
集群验证
以集群模式连接客户端,并设置key。
[root@VM_0_4_centos bin]# redis-cli -c -p 7000
127.0.0.1:7000> set a b
-> Redirected to slot [15495] located at 127.0.0.1:7002
OK
127.0.0.1:7002> set short short
-> Redirected to slot [2103] located at 127.0.0.1:7000
OK
127.0.0.1:7000> get short
"short"
127.0.0.1:7000>
将7000端口的主服务停掉,可以看到原来存储在7000里的key自动存储到7005上,同时cluster自动切换主服务到7005。
127.0.0.1:7000> shutdown
not connected>
[root@VM_0_4_centos bin]# redis-cli -c -p 7000
Could not connect to Redis at 127.0.0.1:7000: Connection refused
not connected> set a b [EX seconds|PX milliseconds] [NX|XX] [KEEPTTL]
[root@VM_0_4_centos bin]# redis-cli -c -p 7001
127.0.0.1:7001> get short
-> Redirected to slot [2103] located at 127.0.0.1:7005
"short"
127.0.0.1:7005> get name
-> Redirected to slot [5798] located at 127.0.0.1:7001
"hello"
127.0.0.1:7001>
127.0.0.1:7005> info replication
# Replication
role:master
connected_slaves:0
master_replid:5b3a8ba01eb3c6afa931cb6143a72340f283e48c
master_replid2:47821ec4918bb29baa1f4546f4111f57af88efaa
master_repl_offset:1107
second_repl_offset:1108
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:1107
127.0.0.1:7005>
总结
Redis实现高可用,支持三种集群模式:主从模式、哨兵模式以及cluster模式。
其中cluster模式是最好用的,推荐使用。
本文作者: vic
同步个人博客: http://geekvic.top/post/d254c291.html
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号