

python+API接口测试框架设计(unittest)
1.测试框架简介
整个接口测试框架的设计图如下:
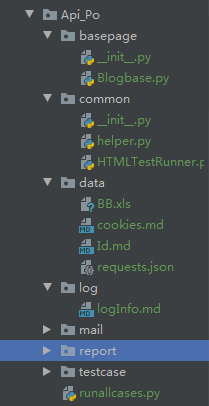
basepage:存放的是公共的方法
common:存放的是自定义工具
data:存放的是公共动态数据,如BB.xls/ Id.md
log:存放的是Log日志信息
report:存放的是接口测试报告
testcase:存放的是接口测试案例
runallcases.py 文件:项目运行的主程序文件
2、重构Requests请求,查看Blogbase.py文件代码
from TestCase.Api_Po.common.helper import Helper
import requests
class BlogBase(object):
def __init__(self):
self.helper = Helper()
self.s = requests.Session()
# self.blog = TestBlog()
def getMethod(self,nrow):
if self.helper.readUrl(nrow):
r = self.s.get(
url=self.helper.readUrl(nrow=nrow),
headers=self.helper.readHeaders(),
verify=False,
timeout=6)
# print(r.cookies)
self.s.cookies.update(self.helper.addcookie())
# print(self.s.cookies)
return r
else:
try:
print('接口地址有误')
except Exception as msg:
print('请求发生未知错误,错误原因是%s'%msg)
def postMethod(self,nrow):
if self.helper.readUrl(nrow):
r = self.s.post(
url=self.helper.readUrl(nrow=nrow),
data=self.helper.getRequestsData(nrow),
headers=self.helper.readHeaders1(),
verify=False,
timeout=6)
# print(r.cookies)
return r
else:
try:
print('接口地址有误')
except Exception as msg:
print('请求发生未知错误,错误原因是%s'%msg)
def deleteMethod(self,nrow):
if self.helper.readUrl(nrow):
r = self.s.delete(
url=self.helper.readUrl(nrow=nrow)+'%s'%self.helper.getID(),
headers=self.helper.readHeaders1(),
verify=False,
timeout=6)
return r
else:
try:
print('接口地址有误')
except Exception as msg:
print('请求发生未知错误,错误原因是%s'%msg)
3、重构公共工具类方法,参考helper.py文件代码
import xlrd
import os
import json
import requests
import logging
class Helper(object):
def get_dirName(self,filepath=None,filename=None):
'''查找文件的路径'''
return os.path.join(os.path.dirname(os.path.dirname(__file__)),filepath,filename)
def readExcels(self,nrow):
'''读取excel数据,nrow表示行数'''
# table = xlrd.open_workbook(r'D:\Project\TestCase\Api_Po\data\BB.xls')
table = xlrd.open_workbook(self.get_dirName('data','BB.xls'))
sheets = table.sheet_by_name('Sheet1')
return sheets.row_values(nrow)
def readCaseId(self,nrow):
'''获取测试用例编号'''
return self.readExcels(nrow)[0]
def readTitle(self,nrow):
'''获取测试用例标题'''
return self.readExcels(nrow)[1]
def readUrl(self,nrow):
'''获取测试用例url'''
return self.readExcels(nrow)[2]
def readMethod(self,nrow):
'''获取测试用例方法'''
return self.readExcels(nrow)[3]
def readData(self,nrow):
'''获取测试用例数据'''
return self.readExcels(nrow)[4]
def readHeaders(self):
'''获取测试用例头'''
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
return headers
def readHeaders1(self):
'''获取测试用例头'''
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",
"Content-Type":"application/json",
'Cookie':'__gads=ID=e10c3225dbe26fdd:T=1578924710:S=ALNI_MaaurX6gcz-ibwnmguYP6xQ82_iSQ; _ga=GA1.2.392048575.1578924638; _gid=GA1.2.1721164379.1581850417; UM_distinctid=1704dad947712d-0aee1dbade8bfb-39395704-100200-1704dad9478460; .Cnblogs.AspNetCore.Cookies=CfDJ8Nf-Z6tqUPlNrwu2nvfTJEhrC2s6fHXZQc4OzQdR6zEYKj27nYfGDX-6N55CXObuv5c7Z496hw_TbXnTgfB-1WA6clxBRaE9yUXK4zqrbS9hyCUhC_DRcsMNdpvOspxvsu2stUKfiqMvUdXPrilEdIrCyhj3jBvaBE2K91H2kfbXgq71wSYsKd0WZwapTXUgMcvWtKSt6qjIy9X5hHEmkMIT8KZPmD8ix5vDXIrmoPuPAMRzrMNZMI_kME0g41GF9EJb_0UHq1gtUMZQR41v78Eu3cE7Xqv7f4dbZXX6MB_p5S_ShpKCDajLmLr9EjfDnHdLLCYUhyxQQuoDakCXtG9FYkPScyXTZLQAuKeFs4XylA5v6XhmWZP087cw2Kum0clyUbXn2XeM5z5UUycmBbSmQhsIMkkPJX7ZrL9TLtpGewIq27EeKqKBuqYVTSt9oRYw130SJCNkBV2MJ2eQXhlCfT0eixXoCdZVrQXWhho9v8s9jLR-IwhQlDNLEDsB6WSqpPQK-VHpYsywVXa5cx6VrX-__mHfMmP2a8an9Sm9; .CNBlogsCookie=61D04946E80D3F55A595ABF64231EECEB662AFBF5F43EC3A11BB407816A434B13ABF8A286432AE9947C838B81D100FD8D20697AF56BDB291E7DA63C377C95760CF2483ACA8C4B24466E556FED4199F641ACF754F; _gat_gtag_UA_48445196_1=1; _gat=1',
"X-BLOG-ID":"456237"
}
return headers
def readJson(self):
'''获取json文件内容,使用到文件的反序列化'''
with open(self.get_dirName('data','requests.json'),encoding='utf-8') as fp:
return json.load(fp)
def getRequestsData(self,nrow):
'''引用BB.xls表格,提取参数'''
'''字典的序列化'''
return json.dumps(self.readJson()[self.readData(nrow)])
def addcookie(self):
'''添加cookie信息'''
c = requests.cookies.RequestsCookieJar()
c.set('.Cnblogs.AspNetCore.Cookies','CfDJ8Nf-Z6tqUPlNrwu2nvfTJEhrC2s6fHXZQc4OzQdR6zEYKj27nYfGDX-6N55CXObuv5c7Z496hw_TbXnTgfB-1WA6clxBRaE9yUXK4zqrbS9hyCUhC_DRcsMNdpvOspxvsu2stUKfiqMvUdXPrilEdIrCyhj3jBvaBE2K91H2kfbXgq71wSYsKd0WZwapTXUgMcvWtKSt6qjIy9X5hHEmkMIT8KZPmD8ix5vDXIrmoPuPAMRzrMNZMI_kME0g41GF9EJb_0UHq1gtUMZQR41v78Eu3cE7Xqv7f4dbZXX6MB_p5S_ShpKCDajLmLr9EjfDnHdLLCYUhyxQQuoDakCXtG9FYkPScyXTZLQAuKeFs4XylA5v6XhmWZP087cw2Kum0clyUbXn2XeM5z5UUycmBbSmQhsIMkkPJX7ZrL9TLtpGewIq27EeKqKBuqYVTSt9oRYw130SJCNkBV2MJ2eQXhlCfT0eixXoCdZVrQXWhho9v8s9jLR-IwhQlDNLEDsB6WSqpPQK-VHpYsywVXa5cx6VrX-__mHfMmP2a8an9Sm9')
c.set('.CNBlogsCookie','61D04946E80D3F55A595ABF64231EECEB662AFBF5F43EC3A11BB407816A434B13ABF8A286432AE9947C838B81D100FD8D20697AF56BDB291E7DA63C377C95760CF2483ACA8C4B24466E556FED4199F641ACF754F')
return c
def getID(self):
'''读取草稿箱ID'''
with open(self.get_dirName('data','Id.md'),) as fp:
return json.loads(fp.read())
def log(self,log_content):
'''日志定义级别'''
# 定义文件
logFile = logging.FileHandler(self.get_dirName('log','logInfo.md'), 'a',encoding='utf-8')
# log格式
fmt = logging.Formatter(fmt='%(asctime)s-%(name)s-%(levelname)s-%(module)s:%(message)s')
logFile.setFormatter(fmt)
# 定义日志
logger1 = logging.Logger('logTest', level=logging.DEBUG)
logger1.addHandler(logFile)
logger1.info(log_content)
logFile.close()
4、重构Mail方法,参考semdmail163.py文件代码
import smtplib
import os
from email.mime.multipart import MIMEMultipart #邮件附件类
from email.mime.text import MIMEText #邮件模板类
from email.header import Header #邮件头部模板
#发送带附件的函数
def semd_mail(file_new):
with open(file_new, "rb") as fp:
mail_body = fp.read()
#基本信息
smtpserver = "smtp.163.com"
port = 25
sender = "18797815816@163.com"
psw = "xxxxx" #163邮箱密码
receiver = "1512500241@qq.com"
#定义邮箱主题
msg = MIMEMultipart()
msg['subject'] = Header(u"自动化测试报告","utf-8")
msg['from'] = sender
msg["to"] = receiver
#不加msg['from'] msg["to"]会报错,是因为"收件人和发件人没有定义"
#HTML 邮件正文,直接发送附件的代码
body = MIMEText(mail_body,"html","utf-8")
msg.attach(body)
# 附件
att = MIMEText(mail_body,"base64","utf-8")
att["Content-Type"] = "application/octet-stream"
att["Content-Disposition"] = 'attachment; filename="test_report.html'
msg.attach(att)
#链接邮件服务器发送邮件
try:
smtp = smtplib.SMTP()
smtp.connect(smtpserver) # 连服务器
smtp.login(sender, psw)
except:
smtp = smtplib.SMTP_SSL(smtpserver, port)
smtp.login(sender, psw) # 登录
smtp.sendmail(sender, receiver, msg.as_string()) # 发送
print("邮件发送成功")
smtp.quit()
#查找最新的邮件
def new_file(report_path):
result_path = report_path
lists = os.listdir(result_path)
lists.sort() #从小到大排序
file = [x for x in lists if x.endswith(".html")]
file_new_name = os.path.join(result_path,file[-1])
return file_new_name
5、重构接口案例,参考testcase目录下的testblog.py文件代码
import unittest
import json
from TestCase.Api_Po.common.helper import Helper
from TestCase.Api_Po.basepage.Blogbase import BlogBase
class TestBlog(unittest.TestCase):
def setUp(self) -> None:
self.obj = BlogBase()
self.hepler = Helper()
def test_login(self):
'''测试登录'''
r1 = self.obj.getMethod(1)
# r1.cookies.update(self.hepler.addcookie())
self.assertEqual(r1.status_code,200)
self.hepler.log('测试登录成功')
# self.hepler.SaveImage('')
def test_aaa(self):
'''测试编辑保存'''
r2 = self.obj.postMethod(2)
with open(self.hepler.get_dirName('data','Id.md'),'w') as fp:
fp.write(json.dumps(r2.json()['id']))
self.assertEqual(r2.status_code,200)
# self.assertEqual(r2.json()['blogUrl'],'//www.cnblogs.com/Teachertao/')
self.hepler.log('测试编辑保存成功')
def test_delete_ID(self):
'''删除草稿箱'''
r3 = self.obj.deleteMethod(3)
print(r3.text)
self.assertEqual(r3.status_code,200)
self.hepler.log('测试删除草稿成功')
if __name__ == '__main__':
unittest.main(verbosity=2)
6、发送接口测试报告,参考runallcases.py文件代码
from TestCase.Api_Po.common.HTMLTestRunner import *
from TestCase.Api_Po.mail.sendmail163 import *
import HTMLTestRunnerCN
#实现的逻辑
#先生成测试报告
#查找最新的测试报告文件,通过new_file函数找到最新的测试报告,把返回的结果return file_new_name
#把new_file函数,file_new_name文件传入到send_mail 读取出来,然后以邮件的附件形式加载到邮件模板中,设置参数,链接服务器发送最新的测试报告#
if __name__ == '__main__':
report = os.path.dirname(__file__) #D:/Project/TestCase/Api_Po
test_path = os.path.join(report,"testcase") #测试用例文件夹
suite = unittest.defaultTestLoader.discover(
start_dir=test_path,pattern="test*.py",top_level_dir=None)
report_path = os.path.join(report,"report") #测试报告文件夹
if not os.path.exists(report_path):
os.mkdir(report_path)
else:
print('存在report报告文件夹')
now = time.strftime("%Y-%m-%d %H_%M_%S") #时间戳
file_name = report_path + '\\' + now + "report_test.html" #测试报告文件名
fp = open(file_name,"wb")
runner = HTMLTestRunnerCN.HTMLTestRunner(
stream = fp,
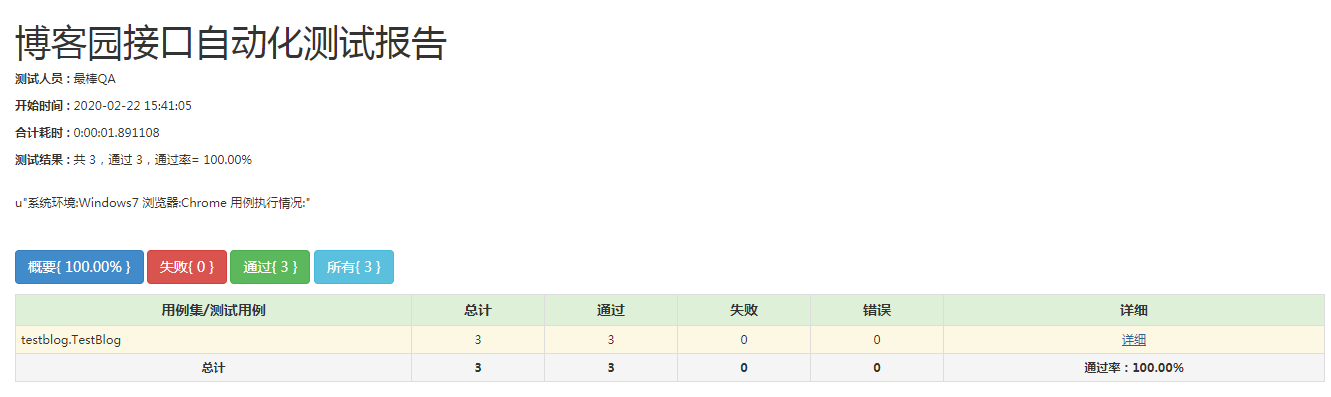
title = '博客园接口自动化测试报告',
description = 'u"系统环境:Windows7 浏览器:Chrome 用例执行情况:"'
)
runner.run(suite) #执行测试用例
fp.close()
new_report = new_file(report_path) #获取最新的报告文件
semd_mail(new_report) #发送最新的测试报告


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具