数据分析报告的阅读
数据分析报告的阅读
如何生成数据分析报告
通常我们拿到一份数据时,我们希望尽快了解她的全貌,那就不可避免的要做探索性数据分析的工作(EDA)。而这项工作对于我而言一次两次到还好,有些数据集的特征值极多,且分布规律极其抽象,所以我还是希望有一种自动生成报告的方法。为此,特学习了利用pandas profiling来自动生成数据报告的方法。代码如下:
import pandas as pd
import pandas_profiling as pp
df = pd.read_csv('data/kaggle_house_pred_train.csv')
# 生成数据报告,并转换为 html 的形式
report = pandas_profiling.ProfileReport(df)
report.to_file('report.html')
如上是常用的模板,总的来说就是读入数据-->生成报告-->转换为.html。
解读数据分析报告
数据报告由如下五个部分组成:数据摘要、各特征的基础分析、变量交互、缺失值和样本。

Overview
数据摘要可以很好的展现数据的全貌,但是缺点是没有做可视化。
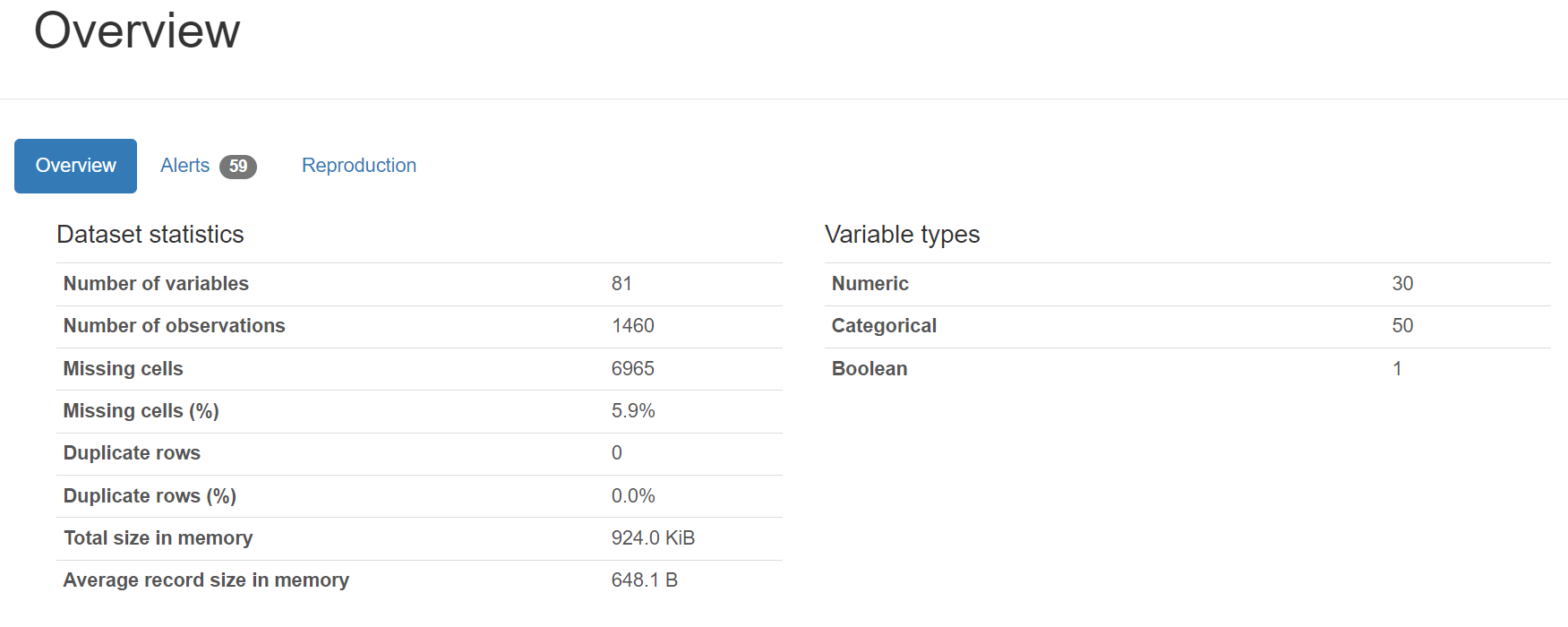
她通常包含:属性值、样本总数、缺失值及确实率、重复行及重复率、各属性的分类。
注意: 第二栏 Alerts 会给出异常提醒,包含: 属性是否服从正态分布、哪些属性有较高的相关性、属性有较高的缺失率,较高的含零率等等。
Variables
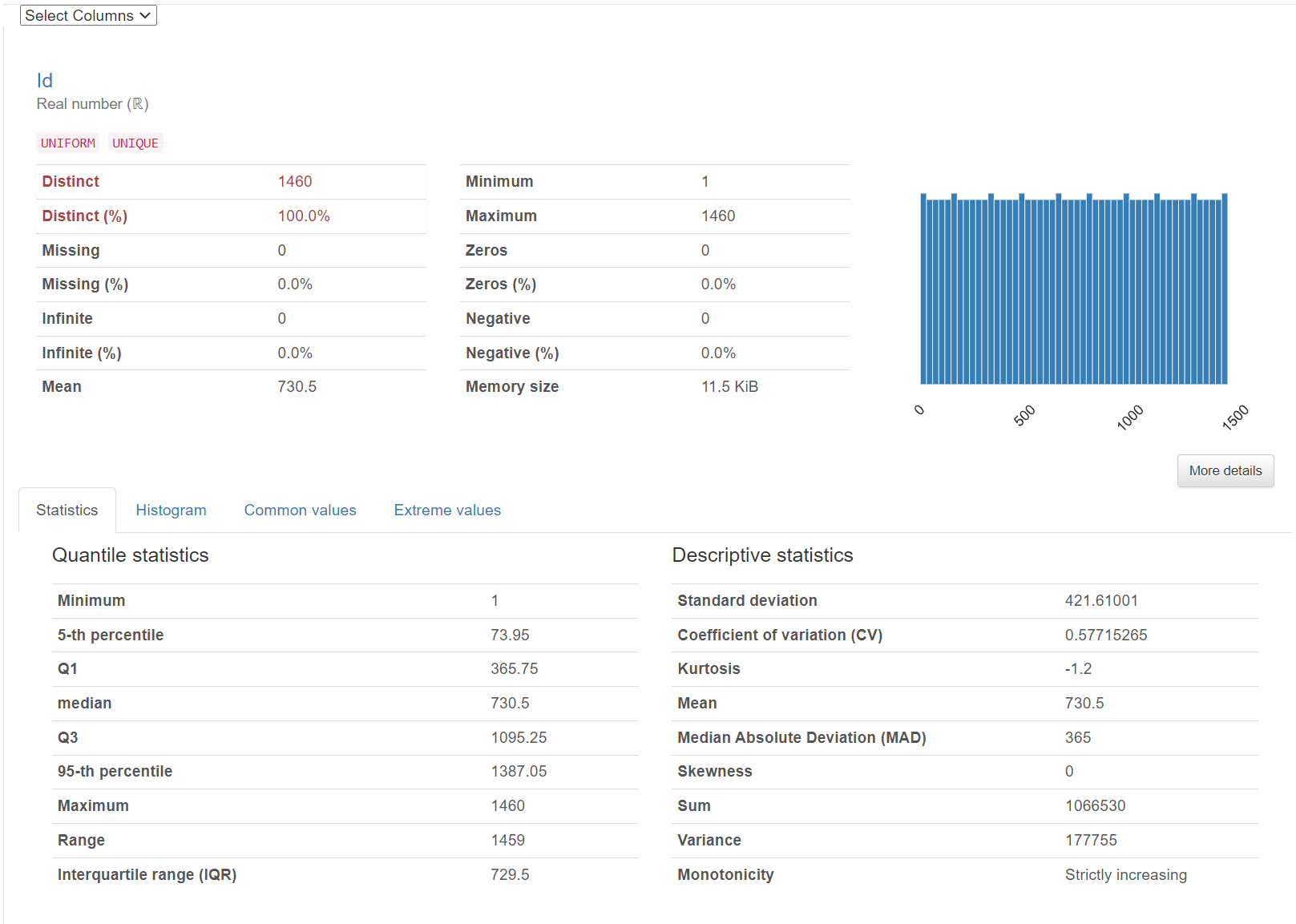
这里几乎涵盖所以基础探索性分析所需要的统计变量,甚至还做了可视化,这对我们分析属性值的分布情况非常有利。
同时,在这个 .html 中还可以下拉选择更多丰富的拓展。
Interactions
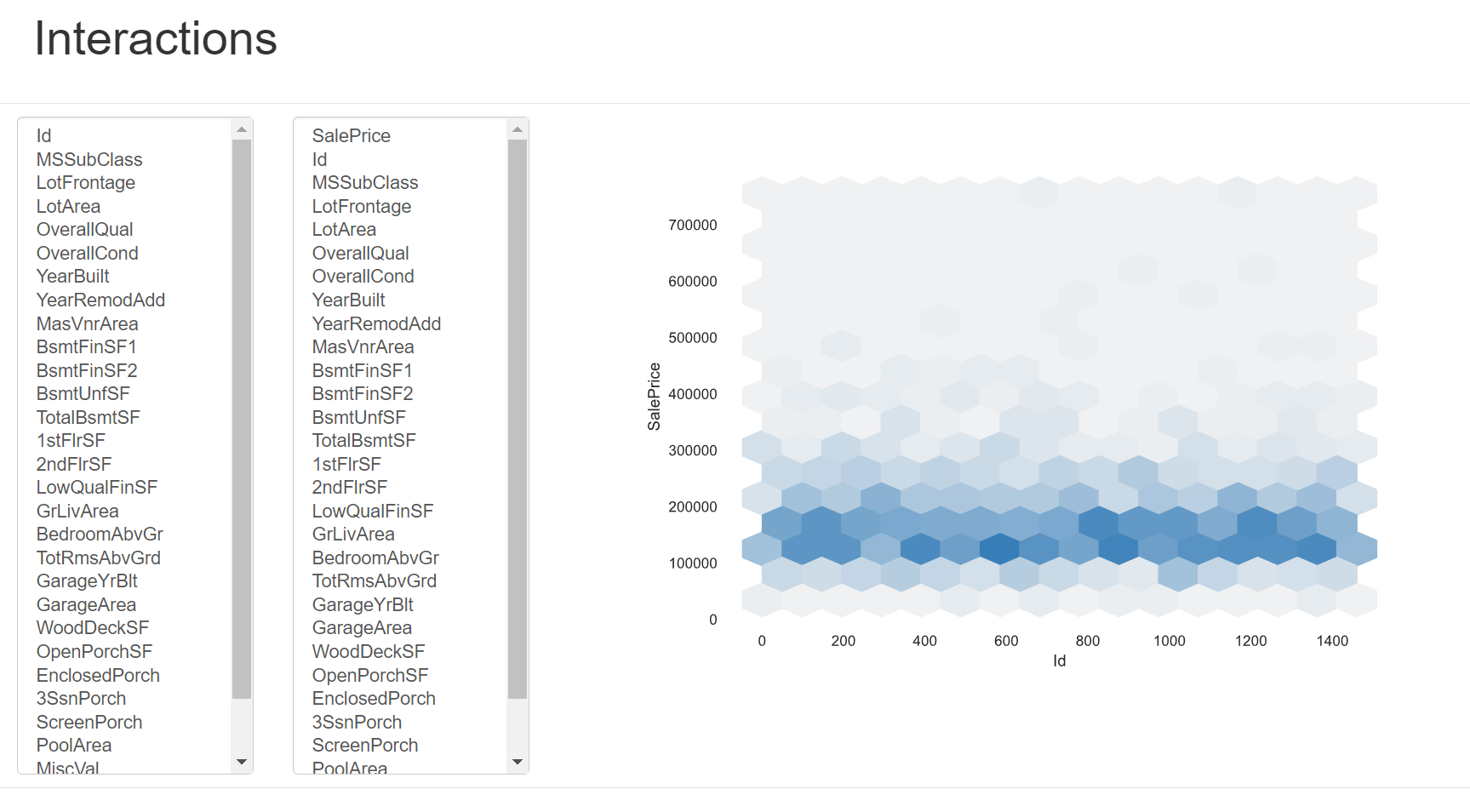
交互性分析也是一个非常强大的模块,它可以很好的可视化展现两个数值属性之间的相关性情况。
Missing Value
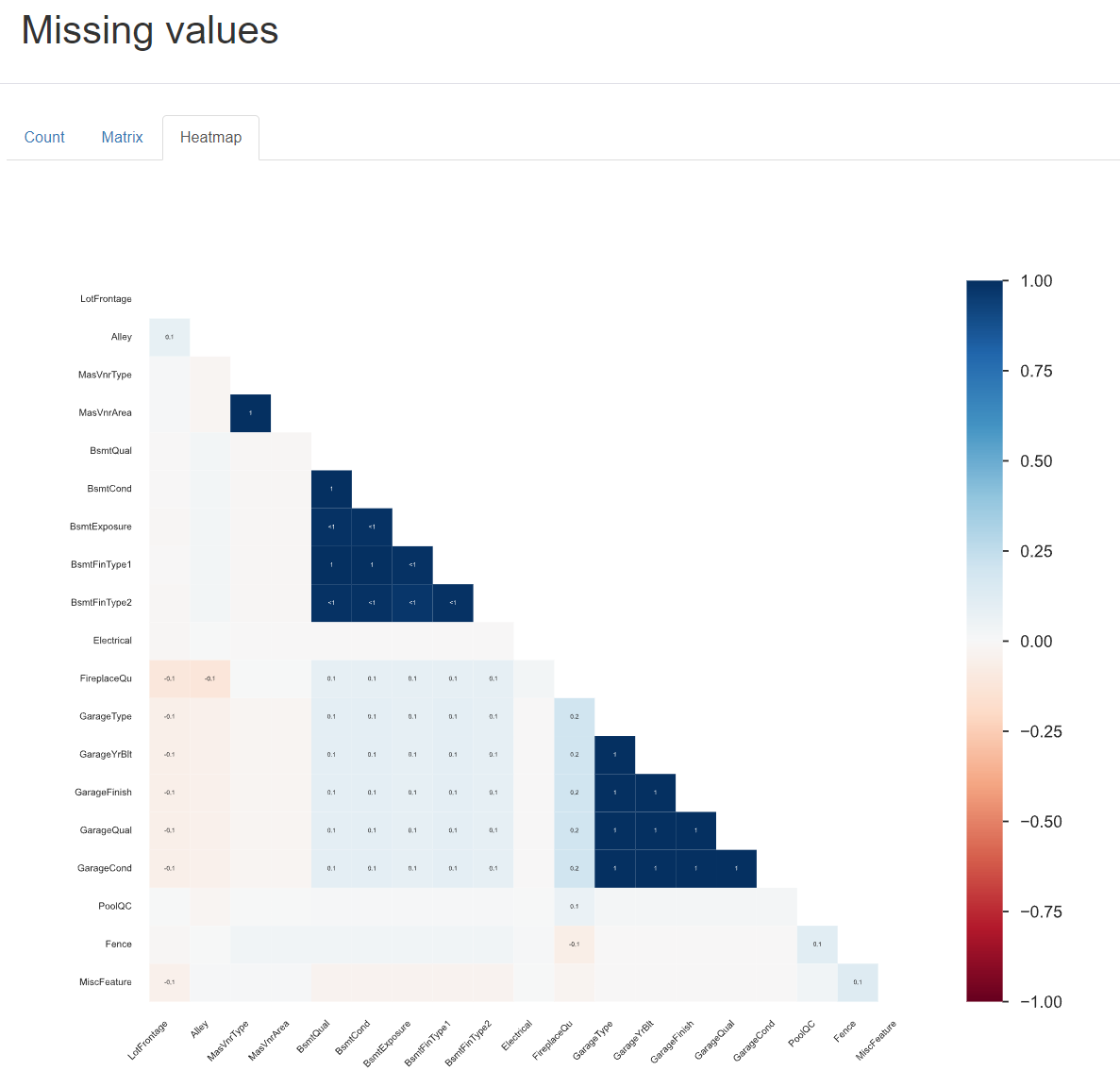
这部分包含三个功能:count、matrix、heatmap,分别是数值统计、以矩阵的方式显示、相关性热力图。
Samples
这部本是样本展示,一般展示前十条和后十条样本。

