数据预处理是数学建模大数据类提醒中常见的操作
数据预处理
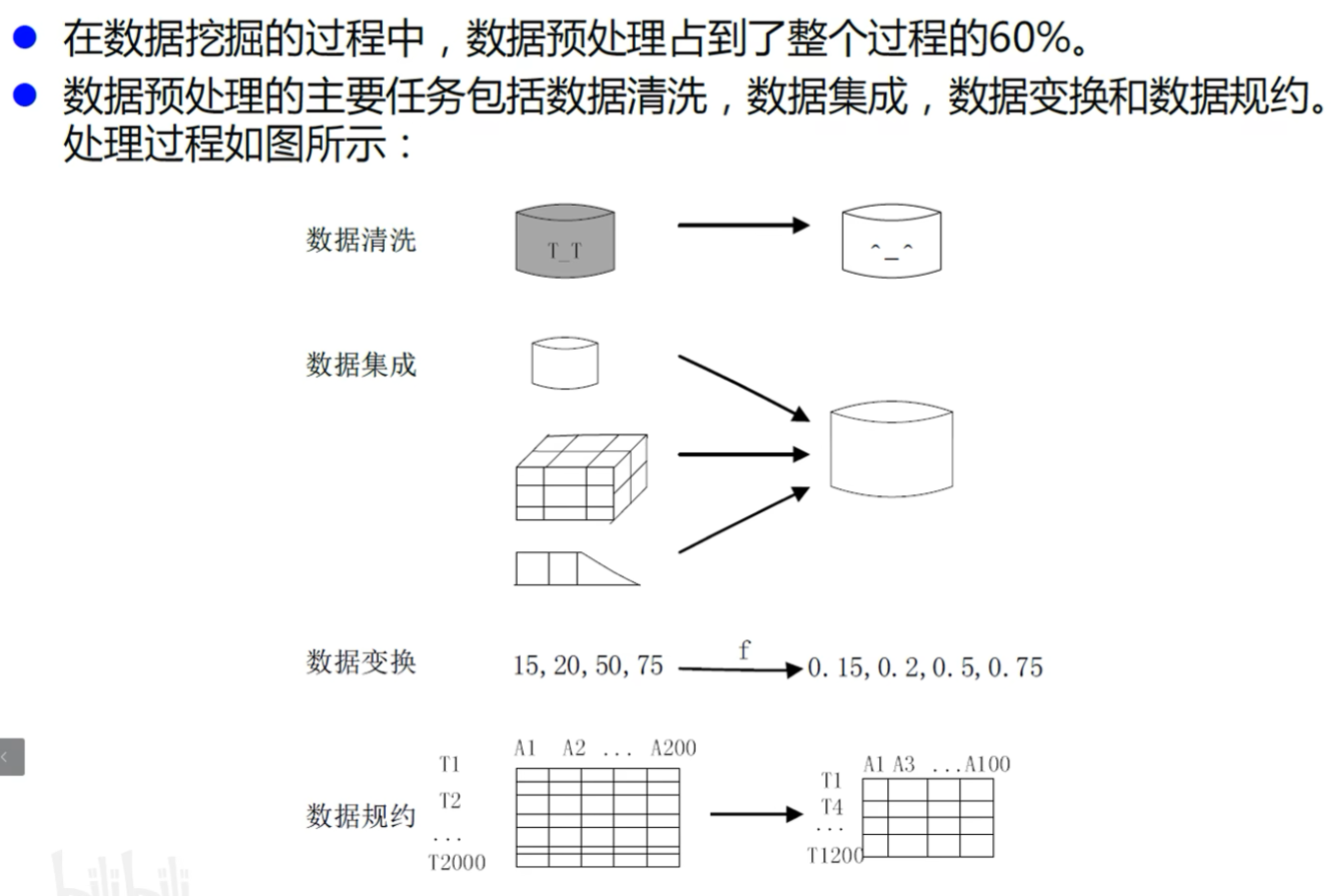
1. 数据清理(缺失值、异常值、无关值、噪声和重复值)
a. 缺失值
- 删除:缺失的数据较少时,将缺失这一属性的样本删除,前提是对整体数据没有较大的影响
- 插补:利用统计学的一些性质来填补这一数据,常见的方法有中值、中位数、平均数、众数等等
- 领近插补:使用和缺失样本最接近的样本的该属性值作为插补
- 回归法(建模预测):对所有的样本进行一定处理后进行回归建模来预测缺失数据的值作为缺失数据(这种方法处理的工作量较大,且对数据的统计特征具有一定的依赖性)
- 其他:牛顿插值法、拉格朗日插值法
b. 异常值
- 找到异常值:比较实用的方法是利用Matlab做箱线图
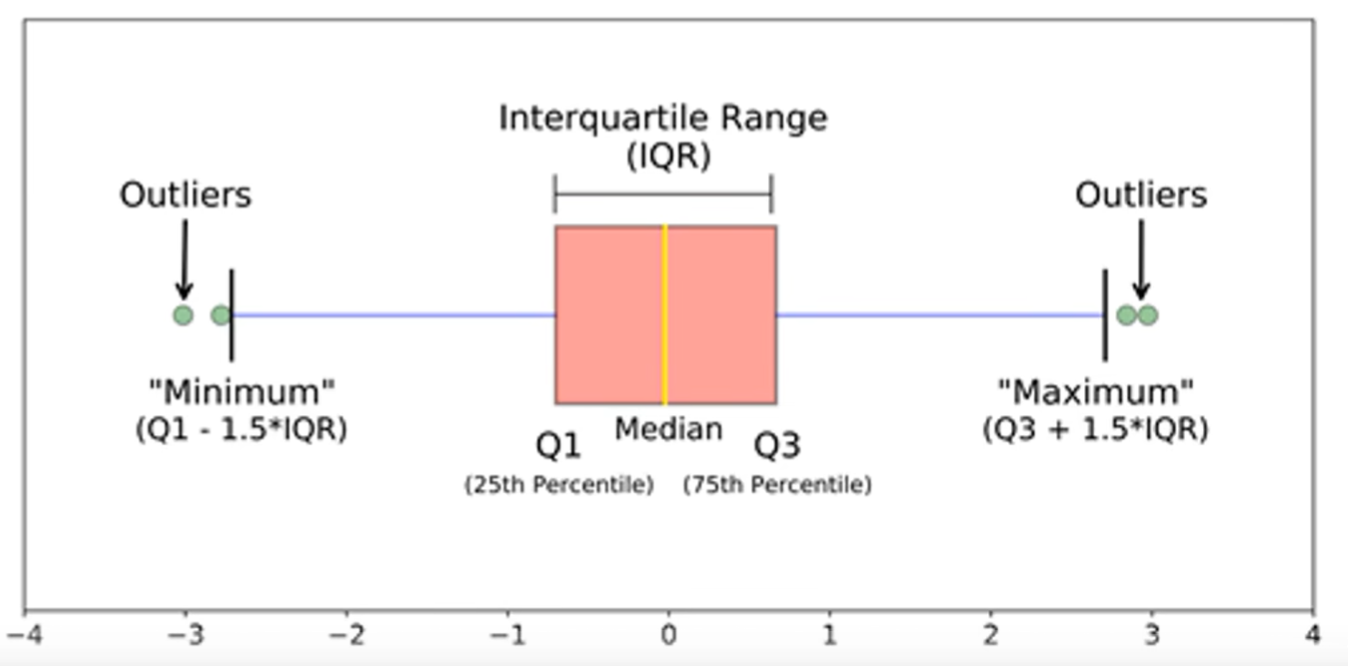
- 下四分位数(Q1)=(数据个数+1)0.25
上四分位数(Q3)=(数据个数+1)0.75
盒子长度IQR = Q3-Q1
最小观测值(下边缘)=Q1 - 1.5IQR
最大观测值(上边缘)=Q3+ 1.5IQR
不在最小最大观测值范围内的视为异常值
- 处理方法:1. 删除 2. 当作缺失值处理 3. 不处理
c. 无关值
- 整体样本中的无关属性(像ID等等)可以直接删除,但是要根据题目情况进行具体分析
d. 噪声
- 分箱:通过考察相邻数据来确定最终值。实际上就是按照属性值划分的子区间,如果一个属性值处于某个子区间范围内,就称把该属性值放进这个子区间所代表的“箱子”内。把待处理的数据(某列属性值)按照一定的规则放进一些箱子中,考察每一个箱子中的数据,采用某种方法分别对各个箱子中的数据进行处理。分箱的方法一般有等深分箱法、等宽分箱法、最小熵法和用户自定义区间法。数据平滑方法:按平均值平滑、按边界值平滑和按中值平滑。按平均值平滑:对同一箱值中的数据求平均值,用平均值替代该箱子中的所有数据。按边界值平滑:用距离较小的边界值替代箱中每一数据。按中值平滑:取箱子的中值,用来替代箱子中的所有数据。
- 聚类:将物理的或抽象对象的集合分组为由类似的对象组成的多个类。找出并清除那些落在簇之外的值(孤立点),这些孤立点被视为噪声。
- 回归:试图发现两个相关的变量之间的变化模式,通过使数据适合一个函数来平滑数据,即通过建立数学模型来预测下一个数值,包括线性回归和非线性回归。
e. 重复值
- 对于重复项的判断,基本思想是“排序与合并”,先将数据集中的记录按一定规则排序,然后通过比较邻近记录是否相似来检测记录是否重复,
- 这里面其实包含了两个操作,一是排序,二是计算相似度。一般过程中主要是用duplicated方法进行判断,然后将重复的样本进行简单的删除处理。
- 需要注意:
- 数据去重是处理重复值的主要方法,但如下几种情况慎重去重
- 样本不均衡时,故意重复采样的数据重复记录用户检测业务规则问题
- 分类模型,某个分类训练数据过少,可以采取简单复制样本的方法来增加样本数量
- 重复记录用户检测业务规则问题
- 事务型数据,尤其与钱相关的业务场景下出现重复数据时,如重复订单,重复出库申请
2. 数据集成
- 在赛题中,给出的数据来自于多个数据集,需要对这几个数据集中的数据进行整合
- 需要注意:
- 属性的意义问题:在不同的数据集中,相同的属性名对应的实际意义是有所差异的
- 字段的结构问题:在不同的数据集中,相同的属性使用的量纲、记录格式可能存在差异,需要进行统一
- 字段冗余问题:集成后的字段有较强的相关性,可以相互推导出,即有冗余表示的若干个属性
- 所以,一般在集成前可以对多个数据集中的所有属性进行统计然后再处理
3. 数据变换
- 目的:
- 方便置信区间分析和可视化(缩放数据、将数据压缩进更有对称性的分布里)
- 为了获得更容易解释的特征
- 降低数据的维度或者数据的复杂度(降低数据矩阵的维度),也即剔除部分属性
- 方便使用简单的回归模型
- 常见的一般操作有 归一化->标准化->规范化
- 更多变化规律参见 这里
4. 数据归约
- 类似与数据压缩,常见的方法是减少数据的维度或者减少数据的数量,来达到降低数据规模的目的
- 常见方法:
- 维度规约(Dimensionality Reduction):减少所需自变量的个数。代表方法为WT、PCA与FSS。
- 数量规约(Numerosity Reducton):用较小的数据表示形式替换原始数据。代表方法为对数线性回归、聚类、抽样等。
posted @
2023-07-29 14:23
Tatsukyou
阅读(
240)
评论()
编辑
收藏
举报

