Linux文件管理 | Liunx 常用命令
文件与目录基本操作
目录:
-
一、显示文件内容
-
二、文件内容查询(grep)
-
三、文件查找命令
-
四、文本处理命令
-
五、文本内容统计命令(wc)
-
六、文件比较命令
-
七、文件的复制、移动和删除命令
-
八、文件链接命令(ln)
-
九、目录的创建与删除(mkdir、rmdir)
-
十、切换目录、路径等相关命令
一、显示文件内容
用户查看文件内容时,可以通过以下命令查看。
1、cat 命令:
用于显示文件,可依次读取其后所指文件内容并将其输出到标准输出设备上。另外,还可以用于连接两个或多个文件,形成新的文件。
#cat命令
cat [option] filename
在a.txt文件中输入“hello ”,在b.txt中输入"world"。
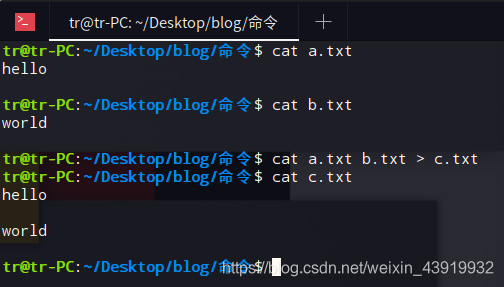
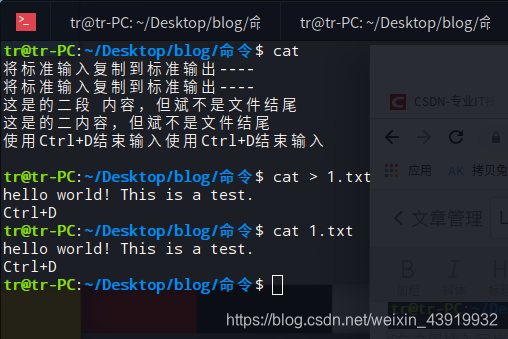
除此之外,cat 命令还可以把标准输入内容复制到标准输出文件中。在cat 命令后输入想要放在文件中的文本内容,结束用Ctrl+D结束输入(组合键Ctrl+D告知cat 已经输入到文件结尾,即 end-of-file,EOF)。Tips:如果cat 命令后省略文件则默认把输入内容复制到标准输出(屏幕上)。
用man帮助手册查看cat的使用cman cat
名称
cat - 连接文件并在标准输出上输出
概述
cat [选项]... [文件]...
描述
将文件列表中的文件连接到标准输出。
如果没有指定文件,或者指定文件为“-”,则从标准输入读取。
-A, --show-all
等价于 -vET
-b, --number-nonblank
给非空输出行编号,使 -n 失效。
-e 等价于 -vE
-E, --show-endsNAME
在每行结束显示 $
-n, --number
给所有输出行编号
-s, --squeeze-blank
将所有的连续的多个空行替换为一个空行
-t 等价于 -vT
-T, --show-tabs
把 TAB 字符显示为 ^I
-u (被忽略的选项)
-v, --show-nonprinting
除了 LFD 和 TAB 之外的不可打印字符,用 ^ 和 M- 标记方式显示
--help 显示此帮助信息并退出
--version
显示版本信息并退出
2、more命令
分页显示文件内容,使用空格或回车翻页,主要用于显示内容较多的文件。查看过程中可通过q按键退出查看
#more命令
more [option] filename
用for i in {1..100};do echo "$i " >> test; done;命令向test文件中输入1~100,使用more命令查看

用man帮助手册查看more的使用cman more
名称
more — 在显示器上阅读文件的过滤器
总览 (SYNOPSIS)
more [-dlfpcsu] [-num] [+/ pattern] [+ linenum] [file ...]
描述 (DESCRIPTION)
More 是 一个 过滤器, 用于 分页 显示 (一次一屏) 文本. 这个 版本 非常 基本. 用户 应该 知道 less(1) 提供了
more(1) 的 模拟, 并且 做了 增强.
选项 (OPTION)
下面 介绍 命令行选项. 选项 可以 从 环境变量 MORE 中获取 (要 确保 它们 以 短横线 开头 (``-’’)), 但是 命令行
选项 能够 覆盖 它们.
-num 这个选项指定屏幕的行数 (以整数表示).
-d 让 more 给 用户 显示 提示信息 "[Press space to continue, 'q' to quit.]", 当 用户 按下 其他键 时, 显示
"[Press 'h' for instructions.]", 而不是 扬声器 鸣笛.
-l More 在 通常情况下 把 ^L (form feed) 当做 特殊字符, 遇到 这个字符 就会 暂停. -l 选项 可以 阻止 这种
特性.
-f 使 more 计数 逻辑行, 而不是 屏幕行 (就是说, 长行 不会 断到 下一行).
-p 不卷屏, 而是 清除 整个屏幕, 然后 显示 文本.
-c 不卷屏, 而是 从 每一屏的 顶部 开始 显示 文本, 每 显示完 一行, 就 清除 这一行的 剩余部分.
-s 把 重复的空行 压缩成 一个 空行.
-u 防止下划线.
+/ 在 显示 每个文件 前, 搜索 +/ 选项 指定的 文本串.
+num 从行号 num 开始显示.
3、less命令
和more命令基本相同,也是分页显示内容。不过less命令在显示文件时,允许用户向前或向后翻阅文件,而more命令只能向后翻阅文件。参数与more命令类似。查看过程中可通过q按键退出查看
#less命令
less [option] filename
使用less命令查看”test“文件,使用↑或↓上下滑动翻看
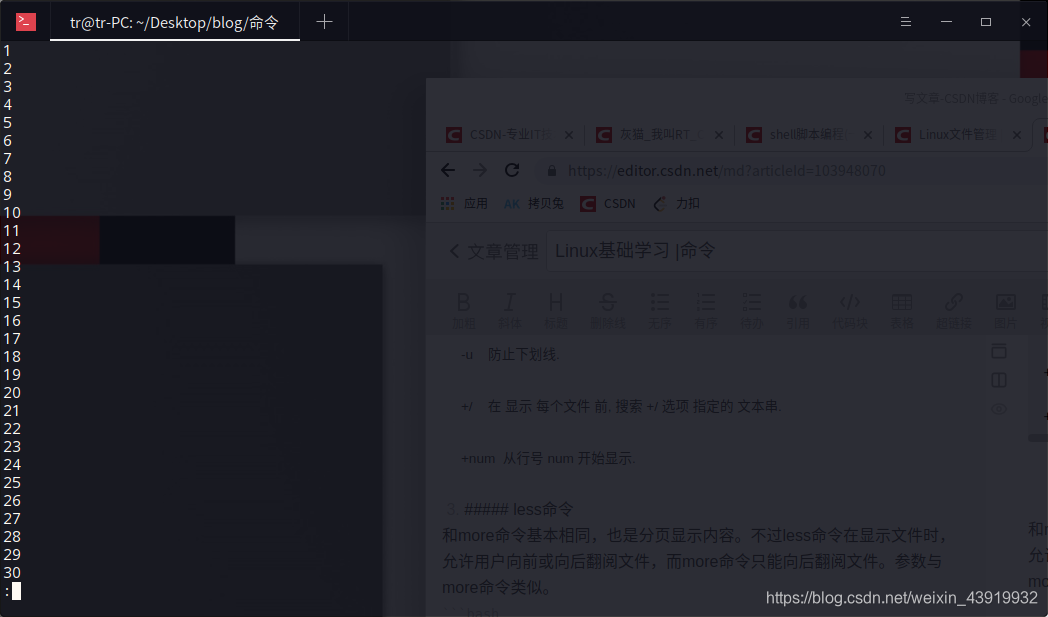
4、head命令
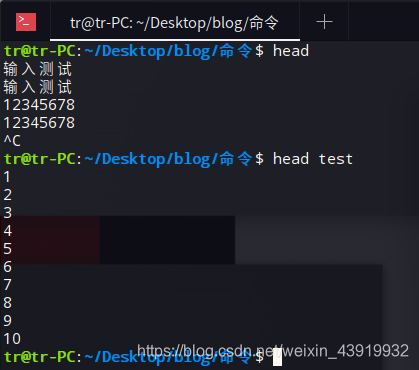
只显示文件或标准输入(从计算机的标准输入设备中得到的信息流,通常是指从键盘、鼠标等获得的数据)的头几行内容。如果用户希望查看文件头部信息便可使用该命令。查看过程中可通过q按键退出查看
#head命令
head - number filename
#注释:输出前n行,如果不指明行数(即number参数)大小,默认为10行,若不指明文件(即filename参数),则默认从标准输入读取。
分别演示从标准输入读取、从”test”文件读取。(test 文件内容是数字 1~100)
用man帮助手册查看head的使用cman head
名称
head - 输出文件的起始部分
概述
head [选项]... [文件]...
描述
将文件列表中每个文件的起始10行内容输出至标准输出。如果指定多个文件,则会在每个文件的部分之前添加给定文件
名称。
如果没有指定文件,或者指定文件为“-”,则从标准输入读取。
必选参数对长短选项同时适用。
-c, --bytes=[-]NUM
显示每个文件的前 NUM 个字节;以 '-' 起始,则显示每个文件中不包含最后 NUM 个字节的全部内容
-n, --lines=[-]NUM
显示前 NUM 行而不是前10行;以 '-' 起始,则显示每个文件中不包含最后 NUM 行的全部内容
-q, --quiet, --silent
不显示给出文件名的首部
-v, --verbose
显示给出文件名的首部
-z, --zero-terminated
以 NUL 作为行的分隔符,而非换行符
--help 显示此帮助信息并退出
--version
显示版本信息并退出
NUM 可以带倍数后缀:b 512, kB 1000, K 1024, MB 1000*1000, M 1024*1024, GB 1000*1000*1000, G
1024*1024*1024, 对于 T, P, E, Z, Y 同样适用。
5、tail命令
与head命令的功能相对应,用于查看文件尾部。同样的如果没有指定文件,则默认从标准输入读取。查看过程中可通过q按键退出查看
#tail命令
tail option filename
使用tail +90 test从“test”文件的第90行显示至末尾,使用tail -5 test显示“test”文件倒数第五行至末尾。
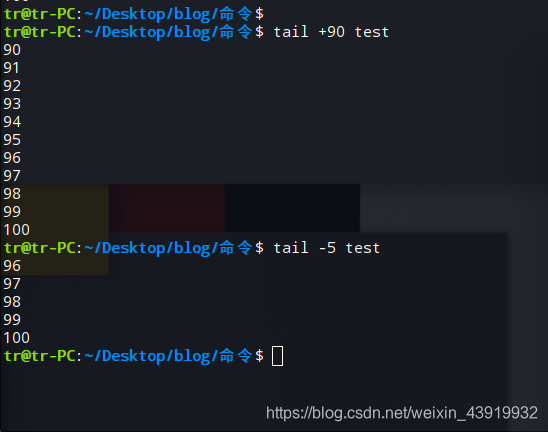
用man帮助手册查看tail的使用cman tail
NAME(名称)
tail - 输出文件的末尾部分
SYNOPSIS(总览)
../src/tail [OPTION]... [FILE]...
DESCRIPTION(描述)
在标准输出上显示每个FILE的最后10行. 如果多于一个FILE,会一个接一个地显示, 并在每个文件显示
的首部给出文件名. 如果没有FILE,或者FILE是-,那么就从标准输入上读取.
--retry
即使tail开始时就不能访问 或者在tail运行后不能访问,也仍然不停地尝试打开文件.
-- 只与-f合用时有用.
-c, --bytes=N
输出最后N个字节
-f, --follow[={name|descriptor}]
当文件增长时,输出后续添加的数据; -f, --follow以及 --follow=descriptor 都是
相同的意思
-n, --lines=N
输出最后N行,而非默认的最后10行
--max-unchanged-stats=N
参看texinfo文档(默认为5)
--max-consecutive-size-changes=N
参看texinfo文档(默认为200)
--pid=PID
与-f合用,表示在进程ID,PID死掉之后结束.
-q, --quiet, --silent
从不输出给出文件名的首部
-s, --sleep-interval=S
与-f合用,表示在每次反复的间隔休眠S秒
-v, --verbose
总是输出给出文件名的首部
--help 显示帮助信息后退出
--version
输出版本信息后退出
二、文件内容查询
文件查询命令主要是指grep、egrep和fgrep命令。这组命令以指定的查找模式搜索文件,通知用户在什么文件中搜索到与指定的模式匹配的字符串,并且打印出所有包含该字符串的文本行。其中,
grep命令一次只能搜索一个指定的模式;
egrep命令检索扩展的正则表达式(包括表达式组和可选项);
fgrep命令检索固定字符串,但并不识别正则表达式,是一种更为快速的搜索命令。
grep [option] [search pattern] [file1, file2,……]
erep [option] [search pattern] [file1, file2,……]
frep [option] [search pattern] [file1, file2,……]
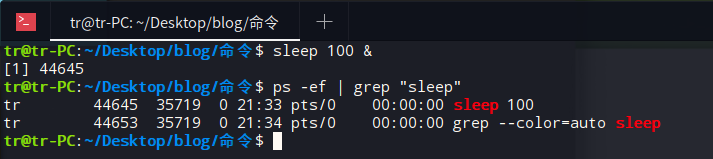
使用ps命令结合管道查询进程
ps -ef | grep "sleep" 把ps命令产生的进程信息通过管道把信息提取出来,再通过grep检索到含有 sleep 的文本行
创建一个基础“Hello World”的C程序,使用grep命令查看源码中含有“Hello”的那一行。其中,关键字是一个字符串 Hello ,如果查询没有结果不会显示任何内容,查询成功显示关键字所在的文本行
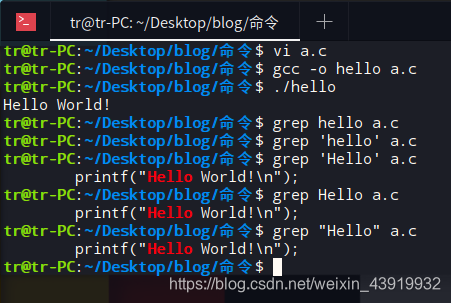
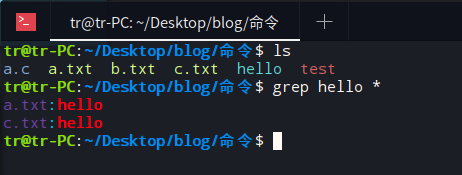
此外还可以用来查找当前目录下的所有文件中是否含有指定字符串
用man帮助手册查看grep的使用cman grep
NAME
grep, egrep, fgrep - 打印匹配给定模式的行
总览 SYNOPSIS
grep [options] PATTERN [FILE...]
grep [options] [-e PATTERN | -f FILE] [FILE...]
描述 DESCRIPTION
-
Grep 搜索以 FILE 命名的文件输入 (或者是标准输入,如果没有指定文件名,或者给出的文件名是 - 的
话),寻找含有与给定的模式 PATTERN 相匹配的内容的行。 默认情况下, grep 将把含有匹配内容的行打印出
来。 -
另外,也可以使用两个变种程序 egrep 和 fgrep 。 Egrep 与 grep -E 相同。 Fgrep 与 grep -F 相同。
选项 OPTIONS
-A NUM, --after-context=NUM
打印出紧随匹配的行之后的下文 NUM 行。在相邻的匹配组之间将会打印内容是 -- 的一行。
-a, --text
将一个二进制文件视为一个文本文件来处理;它与 --binary-files=text 选项等价。
-B NUM, --before-context=NUM
打印出匹配的行之前的上文 NUM 行。在相邻的匹配组之间将会打印内容是 -- 的一行。
-C NUM, --context=NUM
打印出匹配的行的上下文前后各 NUM 行。在相邻的匹配组之间将会打印内容是 -- 的一行。
-b, --byte-offset
在输出的每行前面同时打印出当前行在输入文件中的字节偏移量。
--binary-files=TYPE
如果一个文件的起始几个字节表明文件包含二进制数据,那么假定文件是 TYPE 类型的。默认情况下,
TYPE 是 binary ,并且 grep 一般会输出一个一行的消息说一个二进制文件匹配,或者如果没有匹配的
话就没有消息输出。如果类型 TYPE 是 without-match ,那么 grep 假定二进制文件不会匹配;这样做
与 -I 选项等价。如果类型 TYPE 是 text ,那么 grep 将一个二进制文件视为文本文件来处理;它与
-a 选项等价。 警告: grep --binary-files=text 可能会输出二进制的无用内容。如果输出设备是一
个终端,并且终端的驱动将这些输出中的一些当作命令,可能会带来恶劣的副作用。
--colour[=WHEN], --color[=WHEN]
在匹配的行周围以 GREP_COLOR 环境变量中指定的记号来标记。WHEN 可以是 `never', `always', 或是
`auto'。
-c, --count
禁止通常的输出;作为替代,为每一个输入文件打印一个匹配的行的总数。如果使用 -v, --invert-
match 选项 (参见下面),将是不匹配的行的总数。
-D ACTION, --devices=ACTION
如果输入文件是一个设备,FIFO 或是套接字 (socket) ,使用动作 ACTION 来处理它。默认情况下,动
作 ACTION 是 read ,意味着设备将视为普通文件那样来读。如果动作 ACTION 是 skip ,将不处理而
直接跳过设备。
-d ACTION, --directories=ACTION
如果输入文件是一个目录,使用动作 ACTION 来处理它。默认情况下,动作 ACTION 是 read ,意味着
目录将视为普通文件那样来读。如果动作 ACTION 是 skip ,将不处理而直接跳过目录。如果动作
ACTION 是 recurse , grep 将递归地读每一目录下的所有文件。这样做和 -r 选项等价。
-E, --extended-regexp
将模式 PATTERN 作为一个扩展的正则表达式来解释 (参见下面)。
-e PATTERN, --regexp=PATTERN
使用模式 PATTERN 作为模式;在保护以 - 为起始的模式时有用。
-F, --fixed-strings
将模式 PATTERN 视为一个固定的字符串的列表,用新行 (newlines) 分隔,只要匹配其中之一即可。
-P, --perl-regexp
将模式 PATTERN 作为一个 Perl 正则表达式来解释。
-f FILE, --file=FILE
从文件 FILE 中获取模式,每行一个。空文件含有0个模式,因此不匹配任何东西。
-G, --basic-regexp
将模式 PATTERN 作为一个基本的正则表达式 (参见下面) 来解释。这是默认值。
-H, --with-filename
为每个匹配打印文件名。
-h, --no-filename
当搜索多个文件时,禁止在输出的前面加上文件名前缀。
--help 输出一个简短的帮助信息。
-I 处理一个二进制文件,但是认为它不包含匹配的内容。这和 --binary-files=without-match 选项等
价。
-i, --ignore-case
忽略模式 PATTERN 和输入文件中的大小写的分别。
-L, --files-without-match
禁止通常的输出;作为替代,打印出每个在通常情况下不会产生输出的输入文件的名字。对每个文件的
扫描在遇到第一个匹配的时候就会停止。
-l, --files-with-matches
禁止通常的输出;作为替代,打印出每个在通常情况下会产生输出的输入文件的名字。对每个文件的扫
描在遇到第一个匹配的时候就会停止。
-m NUM, --max-count=NUM
在找到 NUM 个匹配的行之后,不再读这个文件。如果输入是来自一个普通文件的标准输入,并且已经输
出了 NUM 个匹配的行, grep 保证标准输入被定位于退出时的最后一次匹配的行之后,不管是否指定了
要输出紧随的下文的行。这样可以使一个调用程序恢复搜索。当 grep 在 NUM 个匹配的行之后停止,它
会输出任何紧随的下文的行。当使用了 -c 或 --count 选项的时候, grep 不会输出比 NUM 更多的
行。当指定了 -v 或 --invert-match 选项的时候, grep 会在输出 NUM 个不匹配的行之后停止。
--mmap 如果可能的话,使用 mmap(2) 系统调用来读取输入,而不是默认的 read(2) 系统调用。在一些情况
下, --mmap 提供较好的性能。但是,如果一个输入文件在 grep 正在操作时大小发生变化,或者如果
发生了一个 I/O 错误, --mmap 可能导致不可知的行为 (包括core dumps)。
-n, --line-number
在输出的每行前面加上它所在的文件中它的行号。
-o, --only-matching
只显示匹配的行中与 PATTERN 相匹配的部分。
--label=LABEL
将实际上来自标准输入的输入视为来自输入文件 LABEL 。这对于 zgrep 这样的工具非常有用,例如:
gzip -cd foo.gz |grep --label=foo something
--line-buffering
使用行缓冲,it can be a performance penality.
-q, --quiet, --silent
安静。不向标准输出写任何东西。如果找到任何匹配的内容就立即以状态值 0 退出,即使检测到了错
误。 参见 -s 或 --no-messages 选项。
-R, -r, --recursive
递归地读每一目录下的所有文件。这样做和 -d recurse 选项等价。
--include=PATTERN
仅仅在搜索匹配 PATTERN 的文件时在目录中递归搜索。
--exclude=PATTERN
在目录中递归搜索,但是跳过匹配 PATTERN 的文件。
三、文件查找命令
1、find命令
该命令用于从指定的目录开始,递归的搜索其各个子目录,查找满足条件的文件并对之采取相关的操作。此命令提供了相当多的查找条件,功能非常强大。find 命令的常用格式如下。
#简单用法
find [option] filename
#高级用法
find [-H] [-L] [-P] [-Olevel] [-D debugopts] [path...] [expression]
#注:默认路径为当前目录;默认表达式为 -print
#可以使用 find --help 查看详细说明,或使用 man帮助手册 或 info手册
find 命令提供的寻找条件可以是一个用逻辑运算符 not 、and 、 or 组成的复合条件。
- 逻辑与 and :命令中用
-a表示,是系统默认选项。 - 逻辑或 or :命令中用
-o表示。 - 逻辑非 not :命令中用
!表示。
1、在/usr/include/目录下存放着许多头文件,如果我们想要找出stdio.h这个头文件,就可以使用find 命令实现。
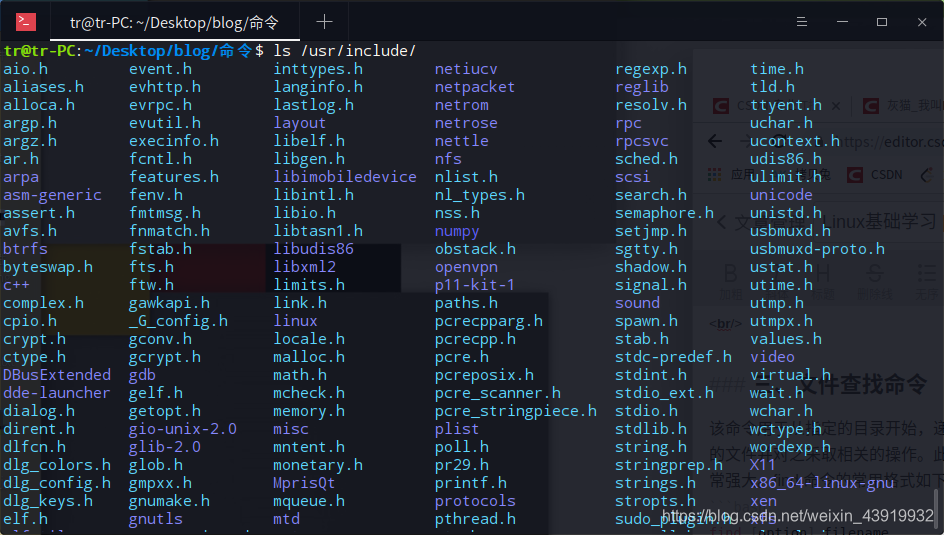
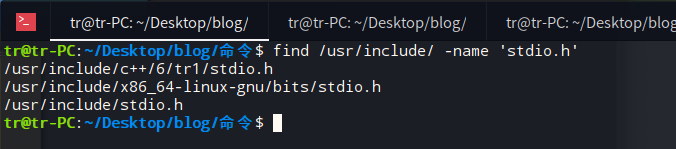
使用命令find 路径 以文件名方式查找 “文件名”的方式查找stdio.h
2、查找当前目录下,所有以 .txt 为后缀的文件
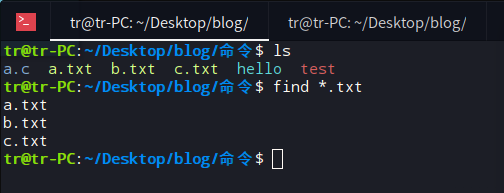
用man帮助手册查看find的使用cman find
NAME
find - 递归地在层次目录中处理文件
总览 SYNOPSIS
find [path...] [expression]
描述 DESCRIPTION
-
这个文档是GNU版本 find 命令的使用手册。 find 搜索目录树上的每一个文件名,它从左至右运算给定的表达式,按照优先规则(见运 算符OPERATORS一节)进行匹配,直到得出结果(左边运算在 ‘与’ 操作中得出假,在’或’ 操作中得出真),然后 find 移向下一个文件名。
-
第一个以 ‘-’ , ‘(’ , ‘)’ , ‘,’ 或 ‘!’ 这些字符起始的参数是表达式的开始; 在它之前的任何参数是要搜索的路径,在它之后的任何参数都是表达式的余下部分。 如果没有路径参数,缺省用当前目录。如果没有表达式,缺省表达式 用 ‘-print’.
-
当所有文件都成功处理时 find 退出并返回状态值0。如果发生错误则返回一个大于0的值。
选项 OPTIONS
所有的选项都总是返回真值,它们总会被执行,除非放在表达式中执行不到的地方。 因此,清楚起见,最好把
它们放在表达式的开头部分。
-help, --help
列出 find 的命令行用法的概要,然后退出。
数字参数可以这样给出:
+n 是比 n 大,
-n 是比 n 小,
n 正好是 n 。
-name pattern
基本的文件名(将路径去掉了前面的目录)与shell模式pattern相匹配。元字符(`*', `?', 还有`[]'
) 不会匹配文件名开头的`.' 。使用 -prune 来略过一个目录及其中的文件。查看 -path 的描述中
的范例。
-path pattern
文件名与shell模式pattern相匹配。元字符不会对`/' 或 `.' 做特殊处理。
-type c
文件是 c 类型的。类型可取值如下:
b 特殊块文件(缓冲的)
c 特殊字符文件(不缓冲)
d 目录
p 命名管道 (FIFO)
f 普通文件
l 符号链接
s 套接字
D 门 (Solaris 特有)
-uid n 文件的数字形式的用户ID是 n 。
-used n
文件最后一次存取是在最后一次修改它的状态的 n 天之后。
-user uname
文件的所有者是 uname (也可以使用数字形式的用户ID).
-print 返回true;在标准输出打印文件全名,然后是一个换行符。
运算符 OPERATORS
以优先级高低顺序排列:
( expr )
强制为优先
! expr 如果 expr 是false则返回true
-not expr
与 ! expr 相同
expr1 expr2
与 (隐含的默认运算符);如果 expr1 为false则不会执行 expr2
expr1 -a expr2
与 expr1 expr2 相同
expr1 -and expr2
与 expr1 expr2 相同
expr1 -o expr2
或;如果 expr1 为true 则不会执行 expr2
expr1 -or expr2
与 expr1 -o expr2 相同
expr1 , expr2
列表;expr1 和 expr2 都会被执行。expr1 的值被忽略,列表的值是 expr2的值
…… …… …… 以上只列出一部分参数,find 命令功能非常强大,提供了和你很多参数可供选择。 …… ……
2、locate 命令
该命令也用于查找文件,比find 命令的搜索速度更快。使用时需要一个数据库,这个数据库由每天的例行工作(crontab)程序来建立。建立好数据库后,就可以方便地用来搜寻所需文件了。
locate [option] filename
locate与find 不同: find 是去硬盘找,locate 只在/var/lib/slocate资料库中找。
locate的速度比find快,它并不是真的查找,而是查数据库,一般文件数据库在/var/lib/slocate/slocate.db中,所以locate的查找并不是实时的,而是以数据库的更新为准,一般是系统自己维护,也可以手工升级数据库,命令为:locate -u 。
#相关命令
/usr/bin/updatedb 主要用来更新数据库,通过crontab自动完成的
/usr/bin/locate 查询文件位置
/etc/updatedb.conf updatedb的配置文件
/var/lib/mlocate/mlocate.db 存放文件信息的文件
如果查询时显示“locate: can not open `/var/lib/mlocate/mlocate.db’: No such file or directory”。此时执行“updatedb”更新下数据库即可。
如下图所示,查找 “passwd” 文件,只显示前四行。
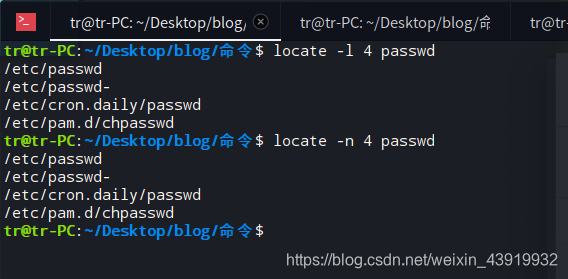
用man帮助手册查看locate的使用man locate
OPTIONS
-A, --all
Print only entries that match all PATTERNs instead of requiring only one of them to match.
-b, --basename
Match only the base name against the specified patterns. This is the opposite of --whole‐
name.
-c, --count
Instead of writing file names on standard output, write the number of matching entries
only.
-d, --database DBPATH
Replace the default database with DBPATH. DBPATH is a :-separated list of database file
names. If more than one --database option is specified, the resulting path is a concatena‐
tion of the separate paths.
An empty database file name is replaced by the default database. A database file name -
refers to the standard input. Note that a database can be read from the standard input
only once.
-e, --existing
Print only entries that refer to files existing at the time locate is run.
-L, --follow
When checking whether files exist (if the --existing option is specified), follow trailing
symbolic links. This causes broken symbolic links to be omitted from the output.
This is the default behavior. The opposite can be specified using --nofollow.
-h, --help
Write a summary of the available options to standard output and exit successfully.
-i, --ignore-case
Ignore case distinctions when matching patterns.
-l, --limit, -n LIMIT
Exit successfully after finding LIMIT entries. If the --count option is specified, the
resulting count is also limited to LIMIT.
-m, --mmap
Ignored, for compatibility with BSD and GNU locate.
-P, --nofollow, -H
When checking whether files exist (if the --existing option is specified), do not follow
trailing symbolic links. This causes broken symbolic links to be reported like other
files.
This is the opposite of --follow.
-0, --null
Separate the entries on output using the ASCII NUL character instead of writing each entry
on a separate line. This option is designed for interoperability with the --null option of
GNU xargs(1).
-S, --statistics
Write statistics about each read database to standard output instead of searching for files
and exit successfully.
-q, --quiet
Write no messages about errors encountered while reading and processing databases.
-r, --regexp REGEXP
Search for a basic regexp REGEXP. No PATTERNs are allowed if this option is used, but this
option can be specified multiple times.
--regex
Interpret all PATTERNs as extended regexps.
-s, --stdio
Ignored, for compatibility with BSD and GNU locate.
-V, --version
Write information about the version and license of locate on standard output and exit suc‐
cessfully.
-w, --wholename
Match only the whole path name against the specified patterns.
This is the default behavior. The opposite can be specified using --basename.
三、文本处理命令
文本处理命令主要包括 sort 排序和 uniq 去重两个操作。
1、sort 命令
该命令用于对文件中各行进行排序。它有许多非常实用的选项,最初是用来对数据库格式的文件内容进行各种排序操作的。该命令逐行地对文件中的内容进行排序,如果两行的首字符相同,那该命令将继续比较下一字符。sort 排序是根据从输入行抽取的一个或多个关键字进行比较来完成的,默认情况下以整行为关键字按ASCII字符顺序进行排序。
sort [option] filename
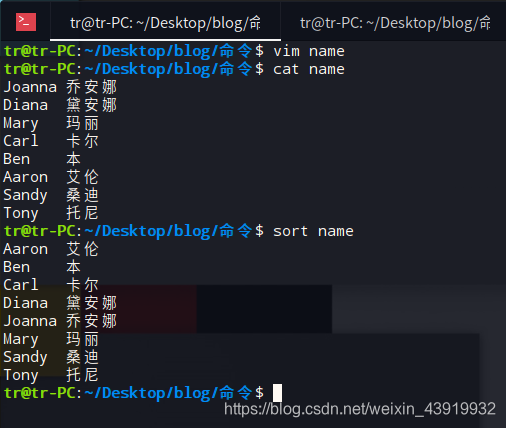
创建一个文件 “ name ” ,使用sort 进行排序
sort 命令也可以对标准输入进行操作。用cat 命令创建一个临时的 “tmp.txt” 文件,与之前的 “name” 文件合并,并且通过管道使用 sort 命令排序,最后使用输出重定向 输出到新文件 “newname” 文件中。如下图所示。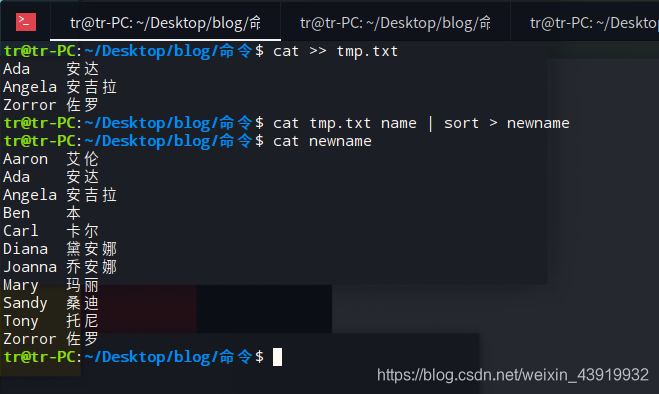
用man帮助手册查看sort的使用cman sort
NAME(名称)
sort - 对文本文件的行排序
SYNOPSIS(总览)
../src/sort [OPTION]... [FILE]...
DESCRIPTION(描述)
将排序好的所有文件串写到标准输出上.
+POS1 [-POS2]
从关键字POS1开始,到POS2*之前*结束(快过时了) 字段数和字符偏移量都从零开始计数(与-k选项比较)
-b 忽略排序字段或关键字中开头的空格
-c 检查是否指定文件已经排序好了,不排序.
-d 在关键字中只考虑[a-zA-Z0-9]字符.
-f 将关键字中的小写字母折合成大写字母.
-g 按照通常的数字值顺序作比较,暗含-b
-i 在关键字中只考虑[\040-\0176]字符.
-k POS1[,POS2]
从关键字POS1开始,*到*POS2结束. 字段数和字符偏移量都从1开始计数(与基于零的+POS格式作比较)
-l 按照当前环境排序.
-m 合并已经排序好的文件,不排序.
-M 按(未知的)<`JAN'<...<`DEC'的顺序比较,暗含-b
-n 按照字符串的数值顺序比较,暗含-b
-o FILE
将结果写入FILE而不是标准输出.
-r 颠倒比较的结果.
-s 通过屏蔽最后的再分类比较来稳定排序.
-t SEP 使用SEP来替代空格的转换non-.
-T DIRECTORY
使用DIRECTORY作为临时文件,而不是$TMPDIR或者/tmp
-u 如果有-c,则按严格的顺序进行检查; 如果有-m,则只输出相等顺序的第一个.
-z 以0字节结束行,而不是使用换行符,这是为了找到-print0
--help 显示帮助并退出.
--version
输出版本信息并退出.
POS为F[.C][OPTS],这里的F指的是字段数,而C为字段中的字符位置,这在-k中是从开 始计数的,而在过时的格式
中是从零开始的.OPTS可由一个或多个Mbdfinr组成;这有效地屏蔽了 对于那个关键字的全局-Mbdfinr设置.如果
没有指定关键字,则使用整行作为关键字.如 果没有FILE,或者FILE是-,则从标准输入读取.
2、uniq 命令
文件经过处理后可能会存在重复行,此命令用于去除重复行,删除多余的行。正常情况下,第二个及以后更多的重复行将被删除。行比较是根据所给的字符集的排列序列进行的,该命令加工后的结果被写入到输出文件中。输入文件和输出文件不能相同。如果文件名用“-”,则表示从标准输入读取。
uniq [option] filename
在文件 “tmp.txt” 和 “newname” 中存在相同项,合并后就会存在重复项,使用 uniq命令去除重复项。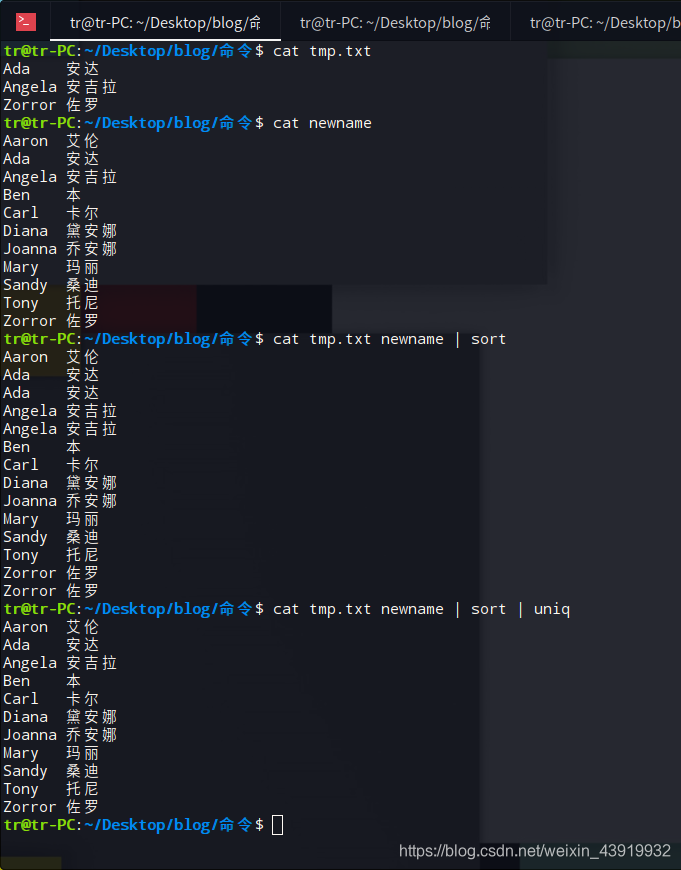
其中,使用-d 参数只显示重复项,使用-u参数,只显示不重复项
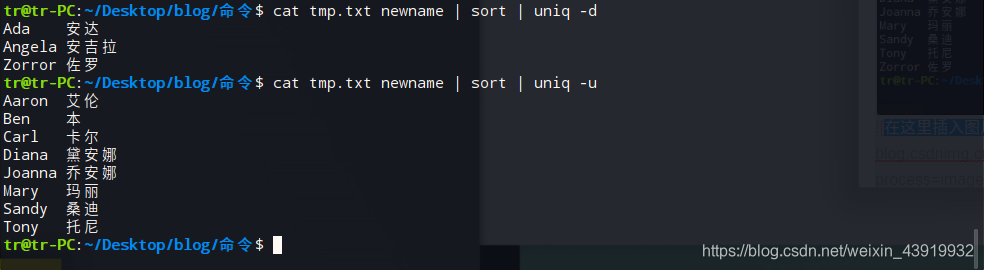
用man帮助手册查看uniq的使用cman uniq
名称
uniq - 报告或省略重复行
概述
uniq [选项]... [输入 [输出]]
描述
从输入文件(或标准输入)筛选一组相邻的匹配行,写入到输出文件(或标准输出)。
如没有指定选项,则只保留一组匹配行中的第一行。
必选参数对长短选项同时适用。
-c, --count
每行前附上重复出现的次数作为前缀
-d, --repeated
仅显示重复行,每组一个
-D 显示所有重复的行
-D, --all-repeated[=METHOD]
类似 -D,但是允许使用空行对各个组进行分隔;METHOD={none(default),prepend,separate}
-f, --skip-fields=N
比较时跳过前 N 个域
--group[=METHOD]
显示所有行,用一个空行分隔每一组 METHOD={separate(default), prepend, append, both}
-i, --ignore-case
比较时忽略大小写
-s, --skip-chars=N
比较时跳过前 N 个字符
-u, --unique
只显示不重复的行
-z, --zero-terminated
以 NUL 作为行的分隔符,而非换行符
-w, --check-chars=N
对每行第 N 个字符以后的内容不作比较
--help 显示此帮助信息并退出
--version
显示版本信息并退出
域指一个由空字符(通常是空格和/或制表符)和紧随的非空字符组成的序列。同时使用跳过域和跳过字符选项
时,先跳过域再跳过字符。
注意:“uniq”只检测那些相邻的重复行。你或许需要先对输入排序,或者使用“sort -u”而非“uniq”。另外,比
较的细则会依据“LC_COLLATE”所指定的规则。
五、文件内容统计命令(wc)
文件内容统计命令主要是指 wc 命令。该命令统计给定文件中的字节数、字行数。如果没有给出文件名,则从标准输入读取。 wc 同时也给出所有指定文件的总统计数。字是由空格字符区分开的最大字符串。
wc [option] filename
# 常用参数
-l 行数
-w 统计字数
-c 统计字节数
统计下列文件的行数、字数、字节数
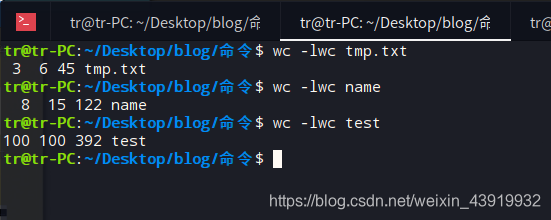
用man帮助手册查看wc 的使用cman wc
名称
wc - 输出文件中的行数、单词数、字节数
概述
wc [选项]... [文件列表]...
wc [选项]... --files0-from=F
描述
对每个文件输出行、单词和字节统计数,如果指定的文件多于一个,则同时输出总行数。单词指以空白字符分隔的长度非零的字符序列。
如果没有指定文件,或者指定文件为“-”,则从标准输入读取。
下列选项可被用来选择应该显示哪些计数信息。它们总是按照行数、单词数、字符数、字节数、最大行长度的顺
序显示。
-c, --bytes
输出字节统计数
-m, --chars
输出字符统计数
-l, --lines
输出换行符统计数
--files0-from=F
将文件F 中的以 NUL 结尾的名字所指定的文件作为待统计文件;如果文件F 为“-”,则从标准输入读取
这些名字
-L, --max-line-length
打印最大显示宽度
-w, --words
输出单词统计数
--help 显示此帮助信息并退出
--version
显示版本信息并退出
六、文件比较命令
1、comm 命令
该命令对两个已排好序的文件进行比较,其中file1 和 file2 是已排序的文件。common 读取这两个文件,然后生成 3 列输出:仅在 file1 中出现的行;仅在 file2 中出现的行;在两个文件中都存在的行。如果文件名用“-”,则表示从标准输入读取。
comm [option] filename
#选项中提供1、2、3选项控制相应的列是否显示
“-12” 只显示两个文件中都存在的
“-13” 只显示第二个文件中出现而在第一个文件中未出现的
“-23” 只显示第一个文件中出现而在第二个文件中未出现的
“-123” 什么都不显示
tips:可以把 "3” 看成一种屏蔽某列的操作,如“-13”,屏蔽第一列,只显示出现在第二列(而未在第二列出现的)
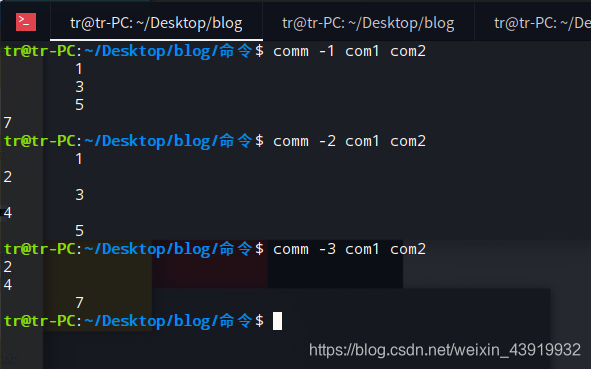
在文件 “com1” 中输入“ 1\2\3\4\5” , 在文件 “com2” 中输入 “1\3\5\7” ,使用comm命令比较。
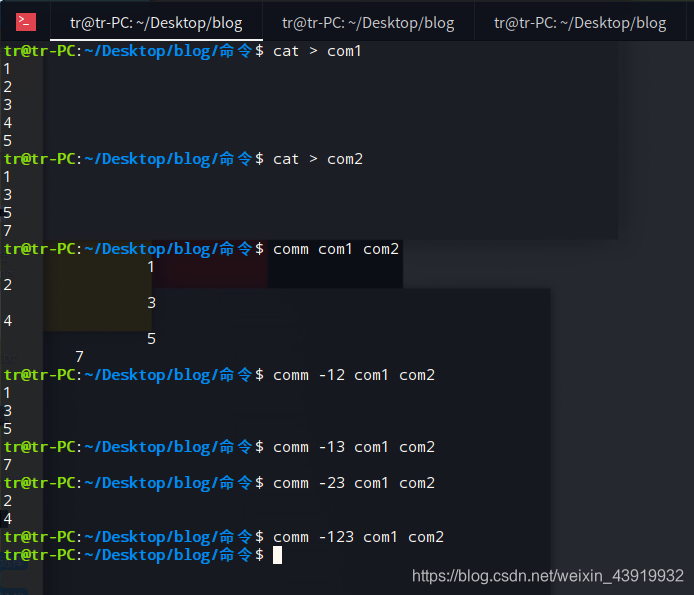
使用单个数字,也会有不同的效果:
使用comm -1 com1 com2命令,把 “com2” 文件的信息比较后输出,第一列为 “com2” 独有,第二列为两文件共有;
使用comm -2 com1 com2命令,把 “com1” 文件的信息比较后输出,第一列为 “com1” 独有,第二列为两文件共有;
使用comm -3 com1 com2命令,把两个文件的信息比较后输出,第一列为 “com1” 独有,第二列为 “com2” 独有;
用man帮助手册查看comm 的使用cman comm
NAME
comm - 逐行比较两个已排序的文件
总览 (SYNOPSIS)
../src/comm [OPTION]... LEFT_FILE RIGHT_FILE
描述 (DESCRIPTION)
逐行比较 已排序的 文件 LEFT_FILE 和 RIGHT_FILE.
-1 屏蔽 左边文件 (LEFT_FILE) 中 不同于 右边文件 的 行(或内容)
-2 屏蔽 右边文件 (RIGHT_FILE) 中 不同于 左边文件 的 行(或内容)
-3 屏蔽 两个文件 中 相同 的 行(或内容)
(译注: 原文为 "不相同的行", 疑有误)
-l 认为 输入数据 根据 当前的 locale 排了序 (应该 给 sort 提供 -l 选项).
--help 显示 帮助信息, 然后 结束
--version
显示 版本信息, 然后 结束
2、diff 命令
该命令用于逐行比较两文件,列出其中不同之处。它对给出的文件进行系统的检查,并显示出两文件中所有不同的行,不要求事先对文件进行排序。
diff [option] file1 file2
diff [option] dir1 dir2
该命令运行后输出通常由下述形式的行组成
n1 a n3, n4
n1, n2 d n3
n1, n2 c n3, n4
以上说明如何将 file1 转变成 file2 ,并给出了两文本文件之间的差异,其中,字母(a、d和c)之前的行号 n1、n2 是针对 file1 的,其后面的行号(n3,、n4)是针对 file2 的。字母 a、d 和 c 分别表示附加、删除和修改操作。
在上述形式的每一行的后面跟随受到影响的若干行,以 “<” 打头的行属于第一个文件,以 “>” 打头的属于第二个文件。
Tips:diff 能区别块和字符设备文件及FIFO(管道文件),不会把它们与普通文件进行比较
如果比较的是目录,则 diff 会产生很多信息。如果一个目录中只有一个文件,则产生一条消息,指出该目录路径名和其中的文件名。
使用 diff命令比较 “file1” 和 “file2”
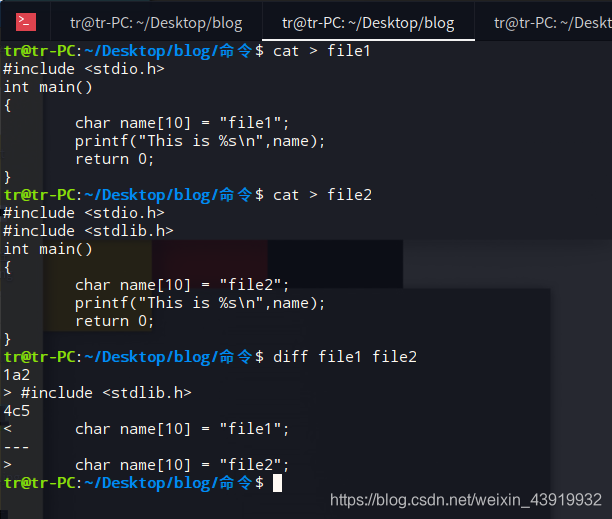
上述"1a2"表示把 “file1”的第一行后追加上 ”file2“ 的第二行,即”#include <stdlib.h>“
"4c5"表示把 “file1”的第四行语句修改成 ”file2“ 的第五行的语句,即”char name[10] = "file1"; ==> char name[10] = "file2";“
若按上述操作,则可把 ”file1“ 转换成 ”file2“
用man帮助手册查看diff 的使用cman diff
NAME
diff - 找出两个文件的不同点
总览
diff [选项] 源文件 目标文件
描述
- 在最简单的情况是, diff 比较两个文件的内容 (源文件 和 目标文件). 文件名可以是 - 由标准输入设备读入的文本.
- 作为特别的情况是, diff - - 比较一份标准输入的它自己的拷贝
- 如果 源文件 是一个目录和 目标文件 不是(目录), diff 会比较在 源文件(目录) 里的文件中和 目标文件同名的(文件),.
反过来也一样. 非目录文件不能是 -. - 如果 源文件 和 目标文件 都是目录, diff 比较两个目录中相应的文件, 依照字母次序排序;这个比较是不会递归的,
除非给出 -r 或者 --recursive. diff 不把一个目录的内容看为它是一个文件来比
用man帮助手册查看diff 的使用cman diff
较。被指定的文件不 能是标准的输入, 因为标准的输入是无名的并且"有一样的名字的文 件"的观点
不适用。 diff 的选项由 -, 开始 所以正常地 源文件(名) 和 目标文件(名) 不可以用 - 开头.
然而, -- 可以被它视为保留的即使作为文件名的开头( they begin with -.)
选项
下面是 GNU所接受的 diff 的所有选项的概要. 大多数的选项有两个相同的名字,一个是单个的 跟在 - 后面字母,
另一个是由 – 引出的长名字. 多个单字母选项(除非它们产生歧义)能够组合为单行的命令行语法 -ac 是等同
于 -a -c. 长命名的选项能被缩短到他们的名字的任何唯一的前缀. 用 ([ 和 ]) 括起来显示选项产生歧义的选项
-行数(一个整数)
显示上下文 行数 (一个整数). 这个选项自身没有指定输出格式,这是没有效果的,除非和 -c
或者 -u 组合使用. 这是已废置的选项,对于正确的操作, 上下文至少要有两行。
-a 所有的文件都视为文本文件来逐行比较,甚至他们似乎不是文本文件.
-b 忽略空格引起的变化.
-B 忽略插入删除空行引起的变化.
--brief
仅报告文件是否相异,在乎差别的细节.
-c 使用上下文输出格式.
-C 行数(一个整数)
--context[=lines]
使用上下文输出格式,显示以指定 行数 (一个整数), 或者是三行(当 行数 没有给出时. 对
于正确的操作, 上下文至少要有两行.
--changed-group-format=format
使用 format 输出一组包含两个文件的不同处的行,其格式是 if-then-else .
-d 改变算法也许发现变化的一个更小的集合.这会使 diff 变慢 (有时更慢).
-D name
合并 if-then-else 格式输出, 预处理宏(由name参数提供)条件.
-e
--ed 输出为一个有效的 ed 脚本.
--exclude=pattern
比较目录的时候,忽略和目录中与 pattern(样式) 相配的.
--exclude-from=file
比较目录的时候,忽略和目录中与任何包含在 file(文件) 的样式相配的文件和目录.
--expand-tabs
在输出时扩展tab为空格,保护输入文件的tab对齐方式
-f 产生一个很象 ed 脚本的输出,但是但是在他们在文件出现的顺序有改变
-F regexp
在上下文和统一格式中,对于每一大块的不同,显示出匹配 regexp. 的一些前面的行.
--forward-ed
产生象 ed 脚本的输出,但是它们在文件出现的顺序有改变。
-h 这选项现在已没作用,它呈现Unix的兼容性.
-H 使用启发规则加速操作那些有许多离散的小差异的大文件.
--horizon-lines=lines
比较给定行数的有共同前缀的最后行,和有共同或缀的最前行.
-i 忽略大小写.
-I regexp
忽略由插入,删除行(由regexp 参数提供参考)带来的改变.
--ifdef=name
合并 if-then-else 格式输出, 预处理宏(由name参数提供)条件.
--ignore-all-space
在比较行的时候忽略空白.
--ignore-blank-lines
忽略插入和删除空行
--ignore-case
忽略大小写.
--ignore-matching-lines=regexp
忽略插入删除行(由regexp 参数提供参考).
--ignore-space-change
忽略空白的数量.
--initial-tab
在文本行(无论是常规的或者格式化的前后文关系)前输出tab代替空格. 引起的原因是tab对齐方式看上去象是常规的一样.
…… …… …… 由于信息过长,以下部分省略 …… …… ……
七、文件的复制、移动和删除命令
1、cp 命令
该功能是将给出的文件或目录复制到另一文件或目录中,就如同 DOS 下的 copy 命令一样,功能非常强大。
cp [option] [src_file|src_dir] [dst_file|dst_dir]
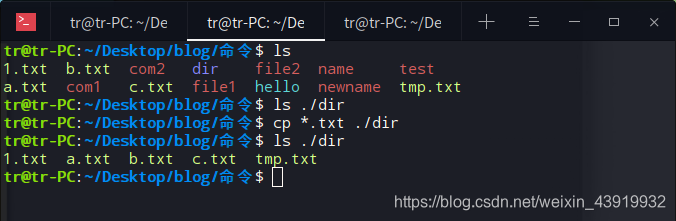
将目录下所有以 ”.txt“ 结尾的文件,拷贝至当前目录下的 dir 目录下
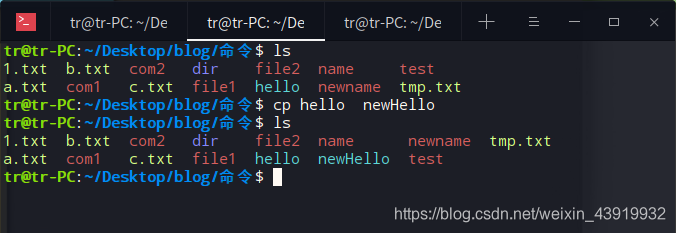
拷贝 “hello” 文件为 ”newHello“ 文件
用man帮助手册查看cp 的使用cman cp
名称
cp - 复制文件和目录
概述
cp [选项]... [-T] 来源 目标
cp [选项]... 来源... 目录
cp [选项]... -t 目录 来源...
描述
从指定的来源文件复制到目标处,或者将多个源文件复制到目标目录中。
必选参数对长短选项同时适用。
-a, --archive
与 -dR --preserve=all 相同。
--attributes-only
不要复制文件数据,仅仅复制其属性值。
--backup[=控制参数]
为每个已存在的目标文件创建一个备份
-b 类似 --backup,但是不接受参数
--copy-contents
递归模式下复制特殊文件的内容
-d 与 --no-dereference --preserve=links 相同
-f, --force
如果有一个已存在且无法打开的目标文件,删除之并进行重试(该选项在 -n 选项同时
被使用时无效)
i, --interactive
覆写前进行提示(覆盖先前的 -n 选项)
-H 跟随源文件命令行中显式给出的符号链接
-l, --link
使用硬链接取代复制
-L, --dereference
总是跟随源文件中的符号链接
-n, --no-clobber
不要覆写已有的文件(覆盖先前给出的 -i 选项)
-P, --no-dereference
永远不要跟随源文件中的符号链接
-p 与 --preserve=mode,ownership,timestamps 相同
--preserve[=属性列表]
保留指定的属性(默认:模式、从属关系、时间戳),如果可能的话还有额外属性:上下文、链接(links)、
xattr、all
--no-preserve=属性列表
不要保留指定的属性
--parents
在目标目录下使用完整的源文件名
-R, -r, --recursive
递归地复制文件
--reflink[=WHEN]
控制克隆/写入时复制(CoW)副本。详情见下文
--remove-destination
在尝试打开每个已存在的目标文件之前对其进行删除(和 --force行为相反)
--sparse=WHEN
控制稀疏文件的创建。详情见下文
--strip-trailing-slashes
移除每个源文件参数后的任何末尾斜杠
-s, --symbolic-link
使用符号链接代替复制
-S, --suffix=后缀名
使用给定名称代替常用备份后缀名
-t, --target-directory=目录
将所有源文件参数给出的内容复制到目标目录中
-T, --no-target-directory
将目标文件当作普通文件对待(而不是目录)
-u, --update
仅在源文件比目标文件新,或者目标文件不存在的情况下复制
-v, --verbose
解释正在发生的情况
-x, --one-file-system
停留在当前文件系统中
-Z 将目标文件 SELinux 安全上下文设置为默认类型
--context[=CTX]
类似 -Z,或者如果给定了上下文(CTX)那么将 SELinux 或者SMACK 安全上下文设置为给定值
--help 显示此帮助信息并退出
--version
显示版本信息并退出
默认情况下,程序会使用一种粗糙的启发式算法探测源文件是否是稀疏的,若判定为稀疏,则目标文件也
会以稀疏形式创建。这个行为可以通过--sparse=auto 指定。若指定 --sparse=always,将在源文件包含足
够多内容为零的字节序列时将其视作稀疏文件。使用 --sparse=never 以禁止创建稀疏文件。
当指定了 --reflink[=always] 时,进行轻量级复制,其中的数据块仅在被修改时进行复制。如果这样的复制
失败,或无法实行,或者指定了 --reflink=auto 时,回退到标准复制。
备份的后缀为“~”,除非设置了 --suffix 或者SIMPLE_BACKUP_SUFFIX。
版本控制方式可以使用 --backup 选项或者 VERSION_CONTROL 环境变量进行指定。可用的值如下:
none, off
永远不制作备份(即使给出了 --backup )
numbered, t
制作编号的备份
existing, nil
如果已编号副本存在则编号,否则采用简单方式
simple, never
总是制作简单备份
作为一个特例,cp 将在同时给出 force 选项与 backup 选项,并且源文件和目标文件是同一个已存在普通文件
的情况下制作备份副本。
2、mv 命令
使用 mv命令可以给目录或文件改名,此外,mv 命令的主要用途是将一个文件或目录移动到另一个目录中,该命令如同 DOS 下的 ren 和 move 的组合。
mv [option] [src_file|src_dir] [dst_file|dst_dir]
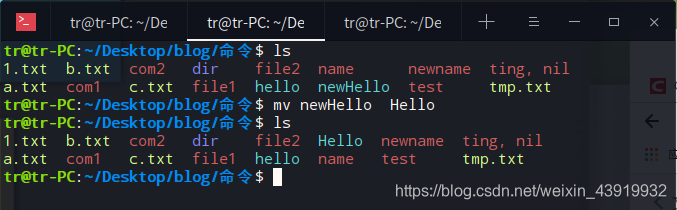
用mv命令将 ”newHello“ 文件改名为 ”Hello“
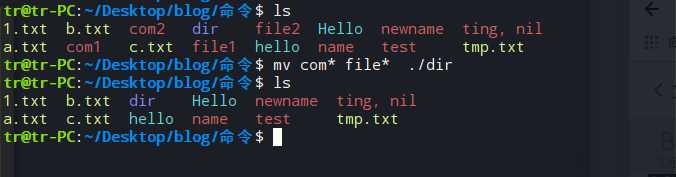
将 ”com1、com2、file1、file2“ 移动到 ”dir“目录下
用man帮助手册查看mv 的使用cman mv
NAME
mv - 移动 (改名) 文件
摘要
mv [选项]... 源文件 目标文件
mv [选项]... 源文件... 目录
mv [选项]... --target-directory=DIRECTORY SOURCE...
描述
改“源文件”名到“目标文件”名, 或移动“源文件”(可以不只一 个)到一个“目录”。
--backup[=CONTROL]
为现有的每一个目标文件作一个备份
-b 和--backup一样但是不接受参数
-f, --force
覆盖前永不提示
-i, --interactive
覆盖前提示
--strip-trailing-slashes
删除任何“源文件”参数后面跟随的斜杠
-S, --suffix=SUFFIX
省略一般的备份后缀
--target-directory=DIRECTORY
移动全部“源文件”参数到“目录”中
-u, --update
只移动更老的或者标记新的非目录
-v, --verbose
说明完成了什么
--help 显示帮助且退出程序
--version
输出版本信息且退出程序
这是备份后缀 `~', 除非设定 --suffix 或 SIMPLE_BACKUP_SUFFIX。 这个版本管理方法可以选择通过 --backup 选项或通过
VERSION_CONTROL 环境变量。这些值是:
none, off
永不做备份 (即使用 --backup)
numbered, t
做备份编号
existing, nil
编号,如果编号备份存在,用其它的简单方法
simple, never
总是做简单备份
3、rm 命令
rm命令是个及其危险的命令,它用于删除文件,一旦文件被删除恢复起来相当麻烦。因此,在使用此命令时要格外小心。此外,如果对于链接文件,该命令只是删除了链接,原有文件均保持不变。
rm [option] [files|dirs]
#常用的参数
-f 忽略不存在的文件,从不给出提示
-r 递归的删除参数中列出的全部目录和子目录及其中的文件。此参数常用来输出非空目录及其下的文件
-i 进行交互式删除,及删除时会让用户确认每一个文件是否要删除,输入 y 确认,输入其他内容均认为是取消。
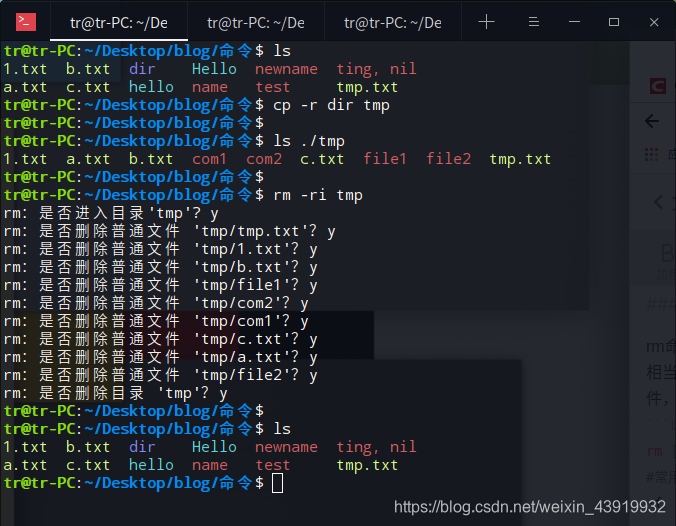
使用cp命令及其参数对 ”tmp“ 目录进行操作
用man帮助手册查看rm 的使用cman rm
名称
rm - 移除文件或者目录
概述
rm [选项]... 文件列表...
描述
本手册页记录 GNU 版本的 rm。rm 移除每一个指定的文件。默认情况下,它不删除目录。
如果指定 -I 或 --interactive=once 选项,且给出了三个以上的文件或指定了 -r, -R 或 --recursive 选项,
则 rm 将提示并询问用户是否继续进行整个操作。如果未得到用户的确认,则整个命令将被中止。
否则,如果一个文件不可写、标准输入是一个终端且未给出 -f 或 --force 选项,或 --interactive=always 选项
被给出, rm 将提示用户是否删除该文件。如果未得到用户的确认,则该文件将被跳过。
选项
删除 (unlink) 给定文件。
-f, --force
忽略不存在的文件和参数,从不提示
-i 在每次删除前提示
-I 在进行递归删除或删除多于三个文件之前提示用户一次;与 -i 相比较更少干扰用户,但是仍然为大多数
操作失误起到保护作用。
--interactive[=WHEN]
根据 WHEN 确定提示用户的频率: "never"(从不)、"once" (-I)、或者 "always" (-i);如果没有给定
WHEN 参数,则总是提示用户。
--one-file-system
在递归地删除一个目录结构时,跳过与对应命令行参数不在同一个文件系统中的所有目录
--no-preserve-root
不对 '/' 做特殊处理
--preserve-root
不删除 '/'(默认)
-r, -R, --recursive
递归地移除目录及它们的内容
-d, --dir
删除空目录
-v, --verbose
解释正在发生的情况
--help 显示此帮助信息并退出
--version
显示版本信息并退出
默认情况下,rm 不移除目录。可以使用 --recursive(-r 或 -R)选项来同时移除列出的每个目录及其内容。
如果需要删除一个文件名以连字符 “-”起始的文件,例如 '-foo',请使用下列命令:
rm -- -foo
rm ./-foo
请注意,如果你使用 rm 删除一个文件,在有足够技术水平和/或时间的情况下,它的部分内容可能仍然能够被恢复。
如果需要更高的保障来使得文件内容不可恢复,请考虑使用 shred.
八、文件链接命令(ln)
该命令可以在文件之间创建链接。这种操作实际上是给系统中已存在的某个文件指定另一个可用于访问它的名称。对于这个新的文件名,可以为其指定不同的访问全向权限,以控制对信息的共享和安全性的问题。
链接分为两种,一种是硬链接(Hard Link),另一种是符号链接(Sysmbolic Link 也称为软链接)。
建立硬链接时,链接文件和被连接文件必须位于同一文件系统中,并且不能建立指向目录的链接。而建立符号链接时,则不存在这个问题。默认情况下产生硬链接。
ln [option] file link
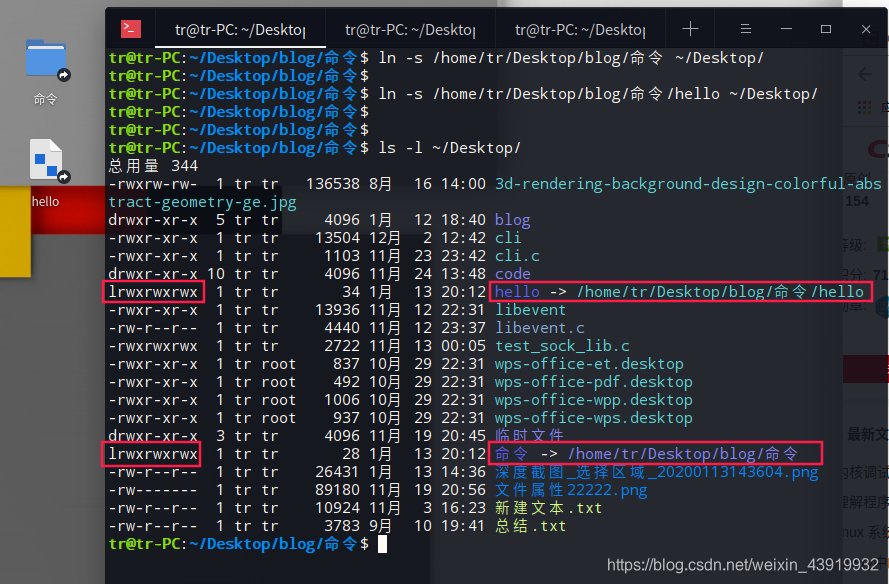
在桌面创建一个目录的软链接和一个文件的软连接,注意链接文件要用绝对路径。
用man帮助手册查看ln 的使用cman ln
NAME
ln -在文件之间建立连接
总览
ln [options] source [dest]
ln [options] source...directory
POSIX 选项:
[-f]
GNU 选项(缩写):
[-bdfinsvF] [-S backup-suffix] [-V {numbered, existing, simple}] [--help]
[--version] [--]
描述
在Unix世界里有两个’link’(连接)概念,一般称之为硬连接和软连接。一个硬连 接仅仅是一个文件名。(一个文件可以有好几个文件名,只有
将最后一个文件名从 磁盘上删除,才能把这个文件删掉。文件名的个数是由ls(1)来确定的。所有的文件 名都处于同一个状态,也就没有什么“源
名字” 之说。通常文件系统里的一个 文件的所有名字包含着一样的数据信息,不过这样也不是必需的。)一个软连接 (或符号连接)是完全不
同的:它是一个包含了路径信息的小小的指定文件。因此, 软连接可以指向不同文件系统里的文件(比如由NFS装载的不同机器文件系统上的
文件),甚至可以指向一个不一定确实存在的文件。在软连接文件被访问(系统调用 open(2) 或stat(2))的时候,操作系统用该文件所包含的路
径替换该文件的访问介 入点,从而实现对所指文件的访问。(用命令rm(1)和unlink(2)可以删除连接,但 不是删除该文件所指向的文件。系统指
定调用lstat(2)和readlink(2) 来读取连接 文件与其所指文件的状态。到底是对软连接文件操作,还是对被指向文件操作,由 于不同操作系统件
存在不同的系统调用,而存在着差异。)
ln 在文件间产生连接。缺省时,产生硬连接,有-s选项,则产生符号(软)连接。
如果仅仅只给出一个文件名,那么ln将在当前目录里产生这个文件的连接, 也就是说,以该文件(的最后一个)名称等同的名字在当前目录里
产生一个连接 (GNU范围内); 如果最后一个参数是一个已存在的目录名, ln 将在那个目录里给每一个源文件用以与源文件相同的文件名产
生连接, (不同情况见以下–no-dereference的描述); 如果只给出两个文件名,ln将产生源文件的连接; 如果最后一个参数不是一个目录名或
多于两个文件名,则报错。
缺省时,ln不删除已存在的文件或符号连接。 (因此,它可以被用来锁定目标文件,即当dest已经不存在时) 但选项-f可以强制执行。
在已存在的实现中,只有超级用户才能建立目录的硬连接。 POSIX 禁止系统调用link(2)和ln建立目录的硬连接 (但是允许在不同的文件系统间
建立硬连接)。
POSIX 选项
-f 删除已存在的目的文件。
GNU 选项
-d, -F, --directory
允许超级用户建立目录硬连接。
-f, --force
删除已存在的目的文件。
-i, --interactive
提示是否删除已存在的目的文件。
-n, --no-dereference
当所给出的目的文件名是一个目录的符号连接时,将其视为一般文件处理。
当目的目录名是一个确实存在的目录(不是一个符号连接)时, 不进行模糊处理,而在那个目录里建立连接。 但是当所指定
的目的目录名是一个符号连接时, 有两种方式来对待用户的要求。 ln 会视目的为一个普通目录,并且在里面建立连接。 或
者如同符号连接本身一样地视其为一个非目录。 这种情况下,ln 将在建立新连接之前删除或备份这个符号连接。 缺省
地,把符号连接视为普通目录来对待。
-s, --symbolic
建立符号连接以替代硬连接。 在不支持符号连接的系统上,这个选项仅仅会产生一个错误提示而已。
-v, --verbose
在建立连接前显示所操作的文件名。
九、目录的创建与删除
1、mkdir 命令
创建目录时用mkdir命令。
mkdir [option] [dirname]
# 常见参数
# “-m” 对新建目录设置存取权限,也可以用 chmod 命令设置
# “-p” 可以是一个路径名称。此时若路径中某些目录尚不存在,加上此项后,系统将自动建立好这些尚不存在的目录,即一次创建多个目录
该命令要求在当前的工作目录下具有写权限,并且所创建的目录名不能是当前目录下已有的目录名。
当前目录下创建只有属主有权限,并且创建了多个连续目录
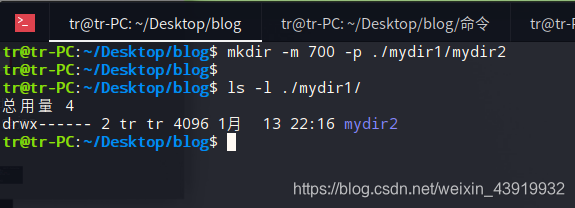
用man帮助手册查看mkdir的使用cman mkdir
名称
mkdir - 创建目录
概述
mkdir [选项]... 目录列表...
描述
如果目录列表中的目录不存在,则创建之。
必选参数对长短选项同时适用。
-m, --mode=模式
设置文件模式(类似chmod),而不是 rwx 减 umask
-p, --parents
如果目录已存在,不报错,且按需创建父目录
-v, --verbose
为每一个已创建的目录打印信息
-Z 将每个创建的目录的 SELinux 安全上下文设置为默认类型
--context[=CTX]
类似 -Z,或者如果指定了上下文,则将 SELinux 或者 SMACK 安全上下文设置为指定类型
--help 显示此帮助信息并退出
--version
显示版本信息并退出
2、rmdir 命令
用于删除空目录。
rmdir [option] [diename]
# 常见参数
# “-p” 递归的删除,当子目录删除后其父目录为空时,也一同删除。如果被删除或由于某种原因保留部分路径,则系统在标椎输出上显示相应的信息
此命令用于删除空目录,并且要求用户对当前目录具有写权限,如果该目录非空,可以用rm -r dirname删除
使用 rmdir 命令删除之前创建的连续空目录
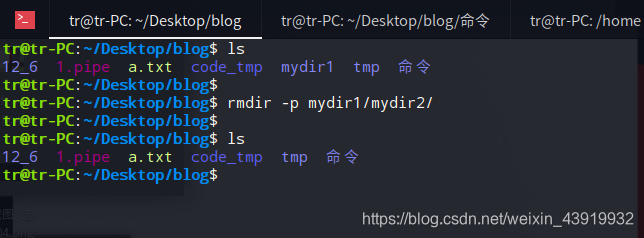
用man帮助手册查看mkdir的使用cman mkdir
名称
rmdir - 删除空目录
概述
rmdir [选项]... 目录列表...
描述
删除目录列表中的空目录。
--ignore-fail-on-non-empty
忽略每一个仅因目录非空而导致的错误
-p, --parents
删除目录及其路径上的目录;比如,'rmdir -p a/b/c' 类似于 'rmdir a/b/c a/b a'
-v, --verbose
为每一个处理过的目录输出诊断信息
--help 显示此帮助信息并退出
--version
显示版本信息并退出
十、切换目录、路径及显示命令
1、cd 命令
cd 命令(change directory),作用是改变当前工作目录,或者叫切换目录。
cd [directory]
#若没有指定目录则回到用户主目录,除此之外,还有以下几种切换方式
# ”cd ~“ 回到主目录
# ”cd -“ 最近使用过的的两个工作目录之间切换
# ”cd ..“ 回到上级目录(父目录)
cd切换目录演示
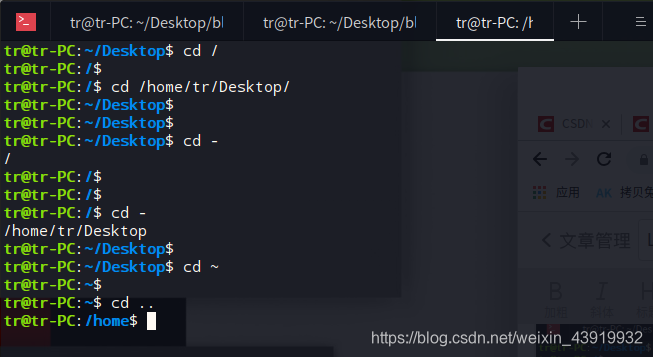
用man帮助手册查看cd 的使用cman cd
NAME
bash - GNU Bourne-Again SHell (GNU 命令解释程序 “Bourne二世”)
概述(SYNOPSIS)
bash [options] [file]
描述(DESCRIPTION)
-
Bash 是一个与 sh 兼容的命令解释程序,可以执行从标准输入或者文件中读取的命令。 Bash 也整合了
Korn 和 C Shell (ksh 和 csh) 中的优秀特性。 -
Bash 的目标是成为遵循 IEEE POSIX Shell and Tools specification (IEEE Working
Group 1003.2,可移植操作系统规约: shell 和工具) 的实现。
选项(OPTIONS)
除了在 set 内建命令的文档中讲述的单字符选项 (option) 之外,bash 在启动时还解释下列选项。
-c string 如果有 -c 选项,那么命令将从 string 中读取。如果 string 后面有参数 (argument),它们将用于给位置
参数 (positional parameter,以 $0 起始) 赋值。
-i 如果有 -i 选项,shell 将交互地执行 ( interactive )。
-l 选项使得 bash 以类似登录 shell (login shell) 的方式启动 (参见下面的 启动(INVOCATION) 章节)。
-r 如果有 -r 选项,shell 成为受限的 ( restricted ) (参见下面的 受限的shell(RESTRICTED SHELL) 章
节)。
-s 如果有 -s 选项,或者如果选项处理完以后,没有参数剩余,那么命令将从标准输入读取。 这个选项允许在
启动一个交互 shell 时可以设置位置参数。
-D 向标准输出打印一个以 $ 为前导的,以双引号引用的字符串列表。 这是在当前语言环境不是 C 或 POSIX
时,脚本中需要翻译的字符串。 这个选项隐含了 -n 选项;不会执行命令。
[-+]O [shopt_option]
shopt_option 是一个 shopt 内建命令可接受的选项 (参见下面的 shell 内建命令(SHELL BUILTIN
COMMANDS) 章节)。 如果有 shopt_option,-O 将设置那个选项的取值; +O 取消它。 如果没有给出
shopt_option,shopt 将在标准输出上打印设为允许的选项的名称和值。 如果启动选项是 +O,输出将以一
种可以重用为输入的格式显示。
-- -- 标志选项的结束,禁止其余的选项处理。任何 -- 之后的参数将作为文件名和参数对待。参数 - 与此等
价。
Bash 也解释一些多字节的选项。在命令行中,这些选项必须置于需要被识别的单字符参数之前。
--dump-po-strings
等价于 -D,但是输出是 GNU gettext po (可移植对象) 文件格式
--dump-strings
等价于 -D
--help 在标准输出显示用法信息并成功退出
…… …… …… 以下省略 …… …… ……
2、pwd 命令
pwd 命令(print working directory),作用是显示当前工作目录的路径。该命令无参数和选项。
演示pwd命令
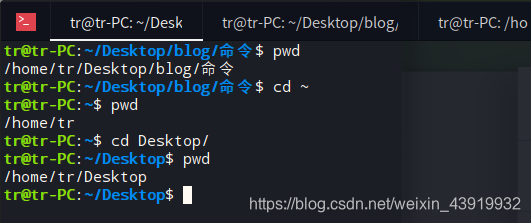
用man帮助手册查看pwd 的使用cman pwd
名称
pwd - 显示出当前/活动目录的名称
概述
pwd [选项]...
描述
输出当前工作目录的完整名称。
-L, --logical
使用环境变量中的 PWD,即使其中包含符号链接
-P, --physical
避免所有符号链接
--help 显示此帮助信息并退出
--version
显示版本信息并退出
如果没有指定任何选项,默认使用 -P。
ls 命令
ls 命令(list),功能是列出目录内容,只是用户最常用的命令之一,该命令类似与 DOS 下的 dir 命令。对于每个目录,该命令将列出其中所有的子目录与文件。
ls [option] [dirname] filename
# 常用以下参数
# ”-a“ 显示指定目录下所有的子目录与文件,包括隐藏文件
# ”-A“ 显示指定目录下所有的子目录与文件,包括隐藏文件,但不列出 ”.“ 与 ”..“
# ”-l“ 以长格式来显示文件详细信息。这个选项组最常用,列出的信息依次是:文件类型与权限、链接数、文件属主、文件数组、文件大小以及建立或修改的时间和名字。
ls 命令测试
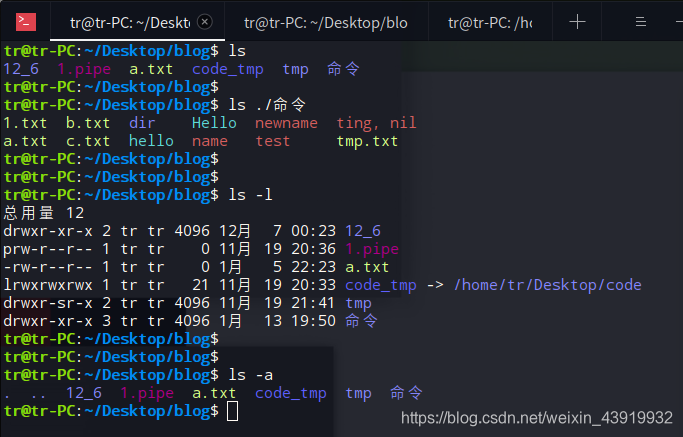
用man帮助手册查看ls的使用cman ls
NAME
ls, dir, vdir - 列目录内容
提要
ls [选项] [文件名...]
POSIX 标准选项: [-CFRacdilqrtu1]
GNU 选项 (短格式):
[-1abcdfgiklmnopqrstuxABCDFGLNQRSUX] [-w cols] [-T cols] [-I pattern] [--full-time]
[--format={long,verbose,commas,across,vertical,single-column}] [--sort={none,time,size,extension}]
[--time={atime,access,use,ctime,status}] [--color[={none,auto,always}]] [--help] [--version] [--]
描述( DESCRIPTION )
程序 ls 先列出非目录的文件项,然后是每一个目录中的“可显示”文件。如果 没有选项之外的参数【译注:即文件名部分为空】
出现,缺省为 “.” (当前目录)。 选项“ -d ”使得目录与非目录项同样对待。除非“ -a ” 选项出现,文件名以“.”开始的文件不属“可显示”文件。
以当前目录为准,每一组文件(包括非目录文件项,以及每一内含文件的目录)分 别按文件名比较顺序排序。如果“ -l
”选项存在,每组文件前显示一摘要行: 给出该组文件长度之和(以 512 字节为单位)。
输出是到标准输出( stdout )。除非以“ -C ”选项要求按多列输出,输出 将是一行一个。然而,输出到终端时,单列
输出或多列输出是不确定的。可以分别 用选项“ -1 ” 或“ -C ”来强制按单列或多列输出。
-C 多列输出,纵向排序。
-F 每个目录名加“ / ”后缀,每个 FIFO 名加“ | ”后缀, 每个可运行名加“ * ”后缀。
-R 递归列出遇到的子目录。
-a 列出所有文件,包括以 "." 开头的隐含文件。
-c 使用“状态改变时间”代替“文件修改时间”为依据来排序 (使用“ -t ”选项时)或列出(使用“ -l ”选项时)。
-d 将目录名象其它文件一样列出,而不是列出它们的内容。
-i 输出文件前先输出文件系列号(即 i 节点号: i-node number)。 -l 列出(以单列格式)文件模式( file
mode ),文件的链 接数,所有者名,组名,文件大小(以字节为单位),时间信 息,及文件名。缺省时,时
间信息显示最近修改时间;可以以 选项“ -c ”和“ -u ”选择显示其它两种时间信息。对于设 备文件,原先显示
文件大小的区域通常显示的是主要和次要的 号(majorand minor device numbers)。
-q 将文件名中的非打印字符输出为问号。(对于到终端的输出这是缺省的。)
-r 逆序排列。
-t 按时间信息排序。
-u 使用最近访问时间代替最近修改时间为依据来排序(使用 “ -t ”选项时)或列出(使用“ -l ”选项时)。
-1 单列输出。
注:文中使用 man 帮助手册是使用的中文版本 cman,详情Linux下的cman中文帮助手册配置

