Linux 、Mac及windows上故障转储文件(core dump)获取方法
2021-08-05 16:42 Tanwheey 阅读(7425) 评论(0) 收藏 举报一、linux:
当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存状态记录下来,保存在一个文件中,这种行为就叫做Core Dump(“核心转储”)。可以认为 core dump 是“内存快照”,但实际上,除了内存信息之外,还有些关键的程序运行状态也会同时dump 下来,例如寄存器信息(包括程序指针、栈指针等)、内存管理信息、其他处理器和操作系统状态和信息。core dump对于编程人员诊断和调试程序是非常有帮助的,因为对于有些程序错误是很难重现的,例如指针异常,而 core dump 文件可以再现程序出错时的情景。
Core Dump 如何产生
上面说当程序运行过程中异常终止或崩溃时会发生core dump,但没说什么具体的情景程序会发生异常终止或崩溃,例如我们使用 kill -9 命令杀死一个进程会发生 core dump 吗?实验证明是不能的,那么什么情况会产生呢?
Linux 中信号是一种异步事件处理的机制,每种信号对应有其默认的操作,你可以在 这里 查看 Linux 系统提供的信号以及默认处理。默认操作主要包括忽略该信号(Ingore)、暂停进程(Stop)、终止进程(Terminate)、终止并发生core dump(core)等。如果我们信号均是采用默认操作,那么,以下列出几种信号,它们在发生时会产生 core dump:
|
Signal |
Action |
Comment |
|
SIGQUIT |
Core |
Quit from keyboard |
|
SIGILL |
Core |
Illegal Instruction |
|
SIGABRT |
Core |
Abort signal from abort |
|
SIGSEGV |
Core |
Invalid memory reference |
|
SIGTRAP |
Core |
Trace/breakpoint trap |
当然不仅限于上面的几种信号。这就是为什么我们使用 Ctrl+z 来挂起一个进程或者 Ctrl+C 结束一个进程均不会产生 core dump,因为前者会向进程发出 SIGTSTP 信号,该信号的默认操作为暂停进程(Stop Process);后者会向进程发出SIGINT 信号,该信号默认操作为终止进程(Terminate Process)。同样上面提到的 kill -9 命令会发出 SIGKILL 命令,该命令默认为终止进程。而如果我们使用 Ctrl+\ 来终止一个进程,会向进程发出 SIGQUIT 信号,默认是会产生 core dump 的。还有其它情景会产生 core dump, 如:程序调用 abort() 函数、访存错误、非法指令等等。
下面举两个例子来说明:
- 终端下比较
Ctrl+C和Ctrl+\: - 小程序产生 core dump
· guohailin@guohailin:~$ sleep 10 #使用sleep命令休眠 10 s
· ^C #使用 Ctrl+C 终止该程序,不会产生 core dump
· guohailin@guohailin:~$ sleep 10
· ^\Quit (core dumped) #使用 Ctrl+\ 退出程序,会产生 core dump
· guohailin@guohailin:~$ ls #多出下面一个 core 文件
· -rw------- 1 guohailin guohailin 335872 10月 22 11:31 sleep.core.21990
· #include <stdio.h>
·
· int main()
· {
· int *null_ptr = NULL;
· *null_ptr = 10; //对空指针指向的内存区域写,会发生段错误
· return 0;
· }
· #编译执行
· guohailin@guohailin:~$ ./a.out
· Segmentation fault (core dumped)
· guohailin@guohailin:~$ ls #多出下面一个 core 文件
· -rw------- 1 guohailin guohailin 200704 10月 22 11:35 a.out.core.22070
Linux 下打开 Core Dump
我使用的 Linux 发行版是 Ubuntu 13.04,设置生成 core dump 文件的方法如下:
- 打开 core dump 功能
- 在终端中输入命令
ulimit -c,输出的结果为 0,说明默认是关闭 core dump 的,即当程序异常终止时,也不会生成 core dump 文件。 - 我们可以使用命令
ulimit -c unlimited来开启 core dump 功能,并且不限制 core dump 文件的大小; 如果需要限制文件的大小,将 unlimited 改成你想生成 core 文件最大的大小,注意单位为 blocks(KB)。 - 用上面命令只会对当前的终端环境有效,如果想需要永久生效,可以修改文件
/etc/security/limits.conf文件,关于此文件的设置参看 这里 。增加一行: - 修改 core 文件保存的路径
- 默认生成的 core 文件保存在可执行文件所在的目录下,文件名就为
core。 - 通过修改
/proc/sys/kernel/core_uses_pid文件可以让生成 core 文件名是否自动加上 pid 号。
例如echo 1 > /proc/sys/kernel/core_uses_pid,生成的 core 文件名将会变成core.pid,其中 pid 表示该进程的 PID。 - 还可以通过修改
/proc/sys/kernel/core_pattern来控制生成 core 文件保存的位置以及文件名格式。
例如可以用echo "/tmp/corefile-%e-%p-%t" > /proc/sys/kernel/core_pattern设置生成的 core 文件保存在 “/tmp/corefile” 目录下,文件名格式为 “core-命令名-pid-时间戳”。这里 有更多详细的说明!
· # /etc/security/limits.conf
· #
· #Each line describes a limit for a user in the form:
· #
· #<domain> <type> <item> <value>
· * soft core unlimited
使用 gdb 调试 Core 文件
产生了 core 文件,我们该如何使用该 Core 文件进行调试呢?Linux 中可以使用 GDB 来调试 core 文件,步骤如下:
- 首先,使用 gcc 编译源文件,加上
-g以增加调试信息; - 按照上面打开 core dump 以使程序异常终止时能生成 core 文件;
- 运行程序,当core dump 之后,使用命令
gdb program core来查看 core 文件,其中 program 为可执行程序名,core 为生成的 core 文件名。
下面用一个简单的例子来说明:
#include <stdio.h>
int func(int *p)
{
int y = *p;
return y;
}
int main()
{
int *p = NULL;
return func(p);
}
编译加上调试信息,运行之后core dump,使用 gdb 查看 core 文件。
guohailin@guohailin:~$ gcc core_demo.c -o core_demo -g
guohailin@guohailin:~$ ./core_demo
Segmentation fault (core dumped)
guohailin@guohailin:~$ gdb core_demo core_demo.core.24816
...
Core was generated by './core_demo'.
Program terminated with signal 11, Segmentation fault.
#0 0x080483cd in func (p=0x0) at core_demo.c:5
5 int y = *p;
(gdb) where
#0 0x080483cd in func (p=0x0) at core_demo.c:5
#1 0x080483ef in main () at core_demo.c:12
(gdb) info frame
Stack level 0, frame at 0xffd590a4:
eip = 0x80483cd in func (core_demo.c:5); saved eip 0x80483ef
called by frame at 0xffd590c0
source language c.
Arglist at 0xffd5909c, args: p=0x0
Locals at 0xffd5909c, Previous frame's sp is 0xffd590a4
Saved registers:
ebp at 0xffd5909c, eip at 0xffd590a0
(gdb)
从上面可以看出,我们可以还原 core_demo 执行时的场景,并使用 where 可以查看当前程序调用函数栈帧,还可以使用 gdb 中的命令查看寄存器,变量等信息。
举例快速上手:
[root@yunji tmp]# sleep 1000
[root@yunji ~]# ps -ef|grep sleep

在‘sleep 1000’命令下,输入:control+\,显示:

^\退出(core)
查看有无core文件生成:

[root@yunji tmp]# gdb program corefile-sleep-31318-1628152235
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-120.el7 Copyright (C) 2013 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-redhat-linux-gnu". For bug reporting instructions, please see: <http://www.gnu.org/software/gdb/bugs/>... program: 没有那个文件或目录. [New LWP 31318] Missing separate debuginfo for the main executable file Try: yum --enablerepo='*debug*' install /usr/lib/debug/.build-id/bb/e03535757d35ca69c622cb8d59501fe8db932f Core was generated by `sleep 1000'. Program terminated with signal 3, Quit. #0 0x00007f56af7908d0 in ?? () (gdb)
问题:显示了没有进程。
二、mac:
开启coredump:
%ulimit -c unlimited
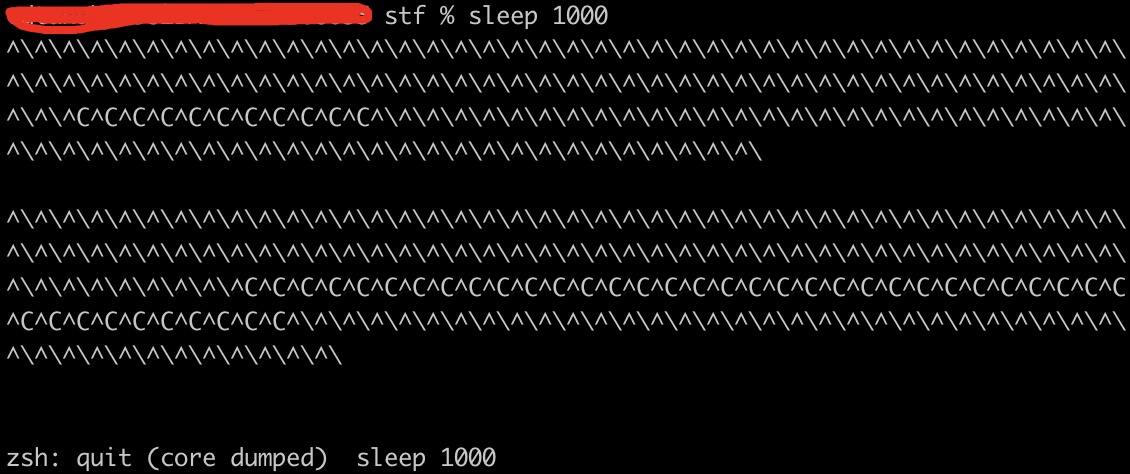
查看进程:

不指定目录,core文件均存在/cores 目录中。
cd /cores
ls
运行 lldb -c “core文件的名称”
lldb -c core.2112
warning: (x86_64) /cores/core.21126 load command 1188 LC_SEGMENT_64 has a fileoff (0x23aee5a5c8) that extends beyond the end of the file (0x95799000), ignoring this section
运行bt就可以看到程序崩溃时的堆栈信息了。
三、windows:
在 Windows 10 上,每次发生崩溃时,系统都会创建一个“转储”文件,其中包含错误发生时的内存信息,可以帮助确定问题的原因。
“.dmp”文件包括停止错误消息、出现问题时加载的驱动程序列表、内核、处理器和进程详细信息,以及其他取决于您使用的转储文件类型的信息。
Windows 10自动创建的转储文件可使用Microsoft WinDbg 工具(Windows 调试内核模式和用户模式代码、检查处理器注册表和分析故障转储工具)调试。
1、安装 WinDbg步骤:
1)打开您喜欢的浏览器。
3)单击获取(或安装/打开)按钮。
4)单击打开按钮。
5)单击安装按钮。
完成这些步骤后,将安装该应用程序,并可通过“开始”菜单使用它。
2、分析转储文件
要打开和分析由 Windows 10 崩溃创建的转储文件步骤:
1)打开开始。
2)搜索WinDbg,右键单击顶部结果,选择以管理员身份运行选项。
3)单击文件菜单。
4)单击开始调试。
5)选择打开油槽文件选项。
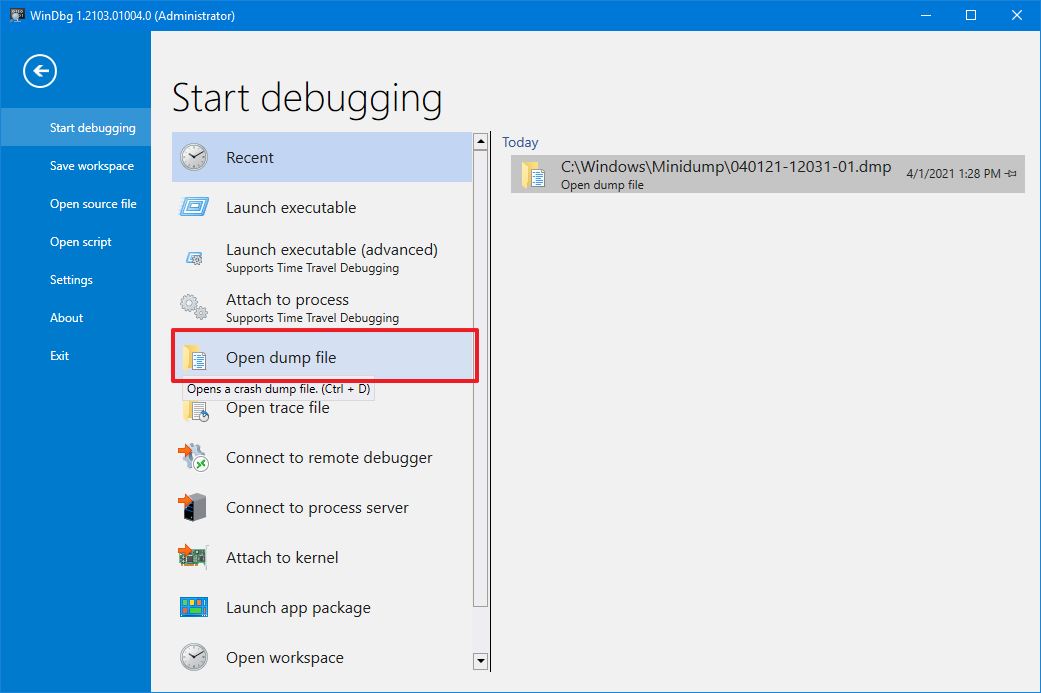
6)从文件夹位置选择转储文件 - 例如,%SystemRoot%\Minidump.
7)单击打开按钮。
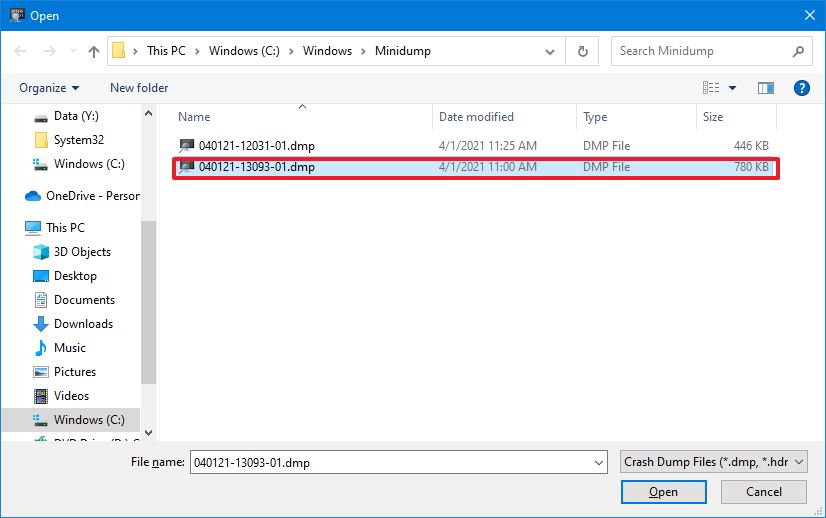
8)检查进度条,直到它加载转储文件(这可能需要一段时间)。
9)在运行命令中键入以下命令并按Enter 键:
!analyze -v
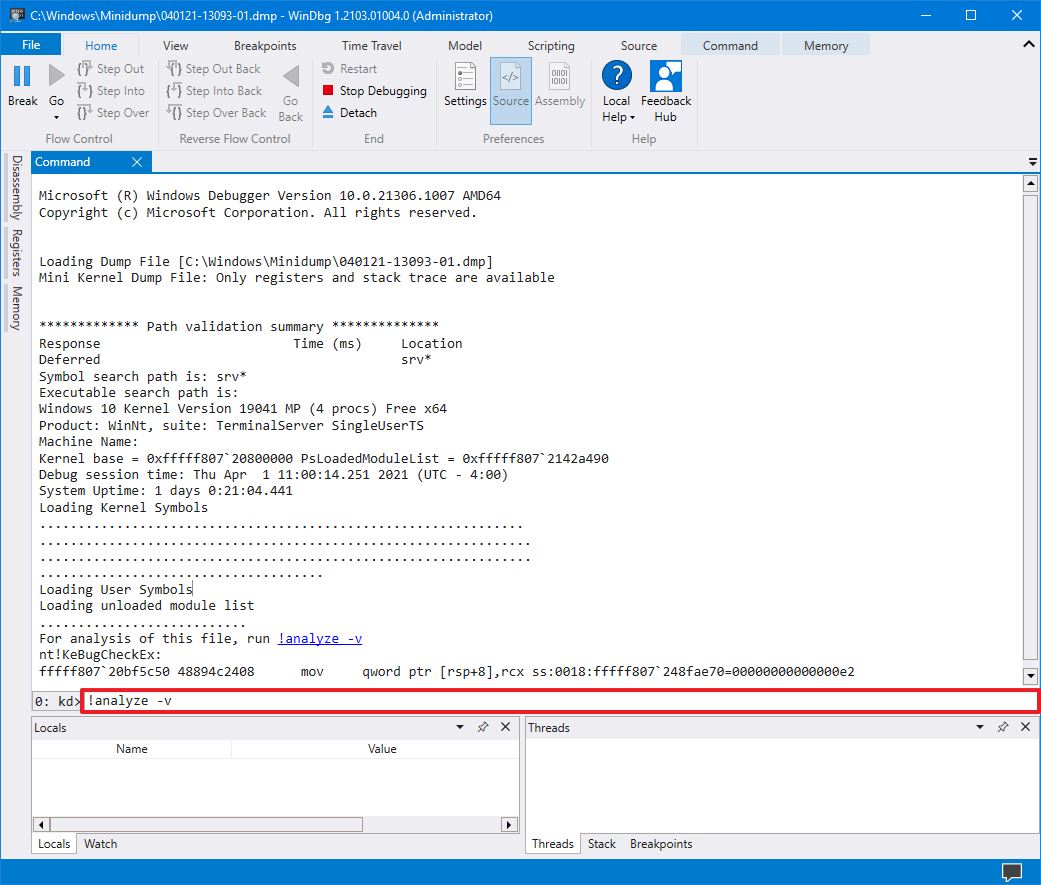 来源:Windows 中心
来源:Windows 中心
快速提示:您还可以单击!analyze -v链接(如果在加载转储文件后可用)从主区域可用。
10)检查进度条直到分析完成(这可能需要很长时间,具体取决于数据大小)。
完成这些步骤后,应用程序将返回转储文件分析,然后您可以查看这些分析以确定问题的原因以帮助您解决问题。
信息会因问题而异。例如,此测试转储文件显示蓝屏死机 (BSoD)(也称为错误检查)的信息。
结果指出这是一个带有“e2”错误代码的手动启动的崩溃,这是正确的,因为出于本指南的目的,我们使用这些指令来强制 BSoD。WinDbg 甚至出色地用任何人都能理解的语言描述了崩溃(用户手动启动了此崩溃转储)。
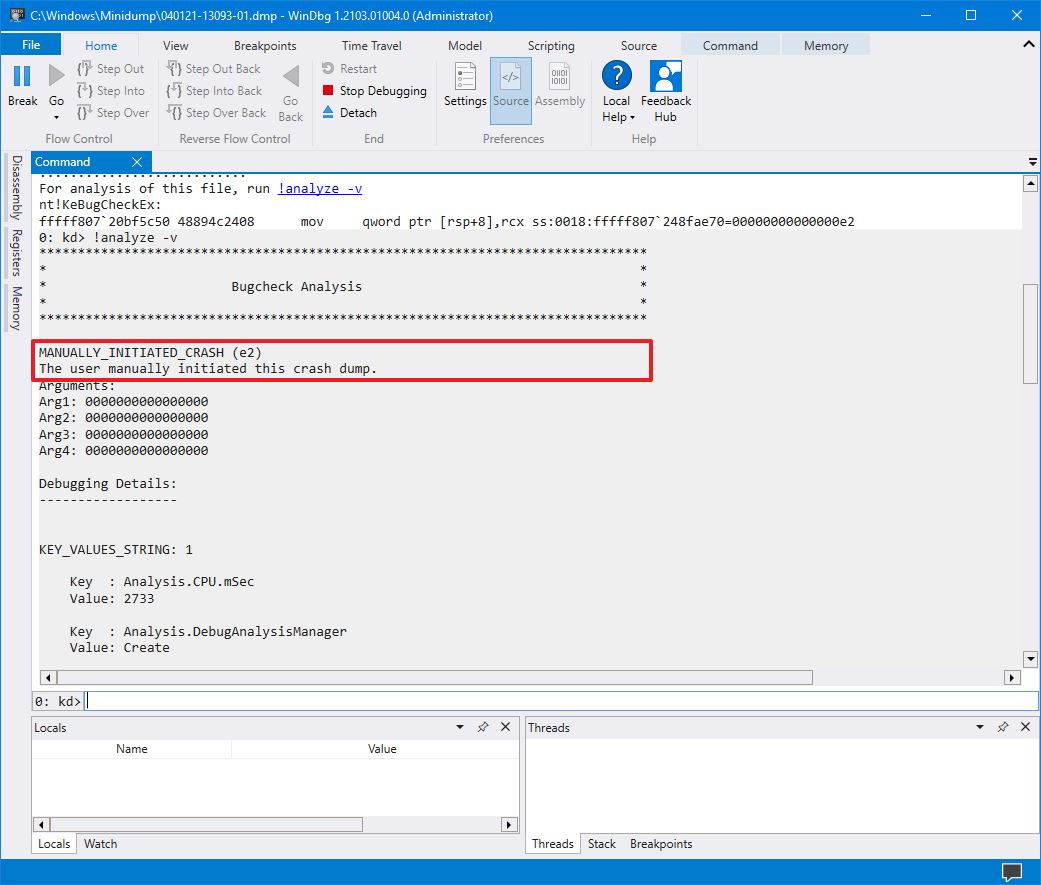
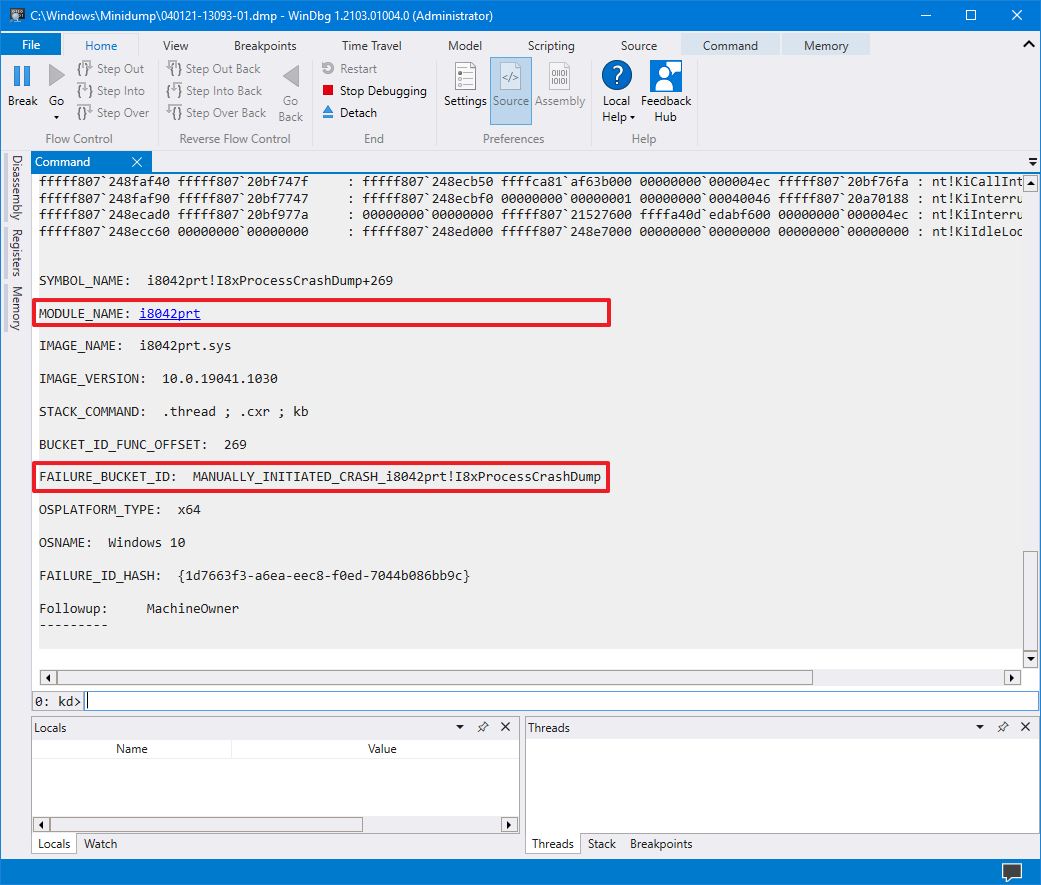
当继续查看转储文件时,您还会发现更多信息,例如“FAILURE_BUCKET_ID”和“MODULE_NAME”,它们可以指出导致问题的原因。
参考:
https://www.cnblogs.com/hazir/p/linxu_core_dump.html
https://www.windowscentral.com/how-open-and-analyze-dump-error-files-windows-10

 浙公网安备 33010602011771号
浙公网安备 33010602011771号