

20172319 《程序设计与数据结构》 第六周学习总结
20172319 2018.10.19-10.26
《程序设计与数据结构》第6周学习总结
目录
教材学习内容总结
第十章 树
-
10.1 概述:
-
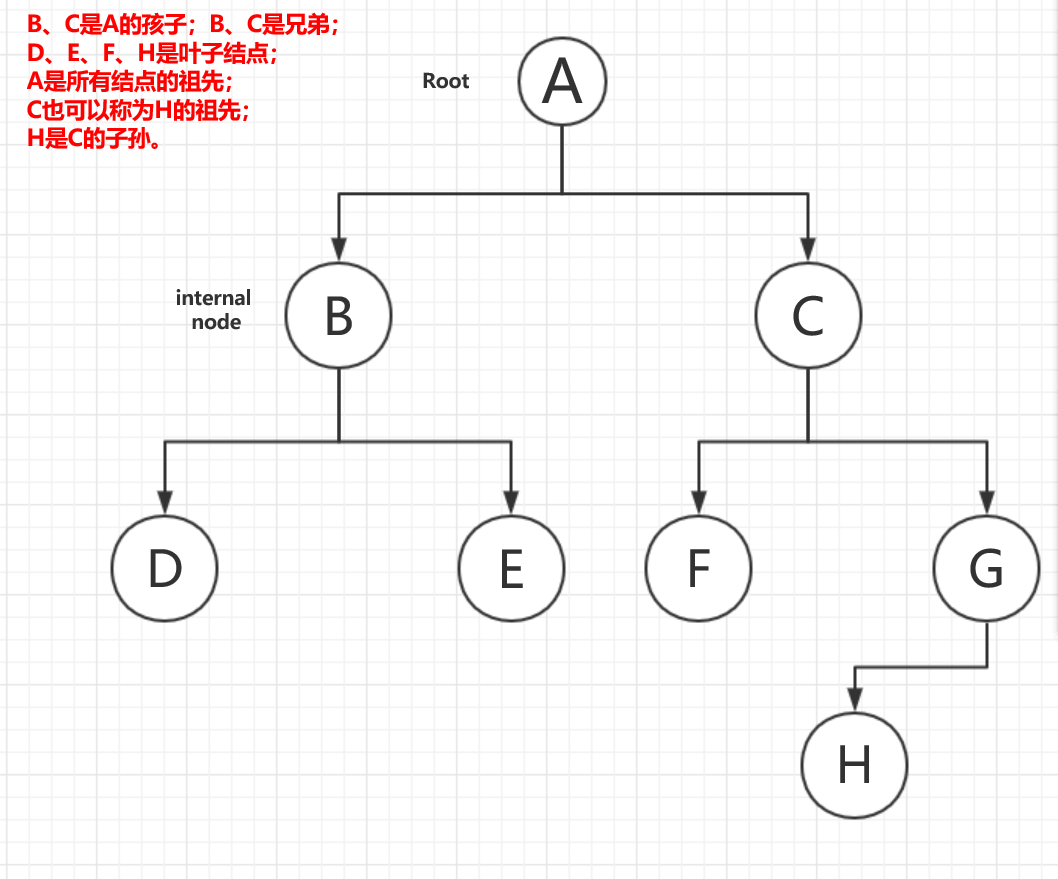
树(tree) ** 是一种非线性** 结构,其元素被组织成了一个**层次 ** 结构。
-
树 ** 由一个包含结点 (node) ** 和**边(edge) ** 的集构成,其中的元素被存储在这些结点中,边则将一个结点和另一个结点连接起来。
-
每一结点都位于该树层次结构中的某一特定层上。
-
树的根(root) ** :即位于该树顶层 ** 的唯一结点,一棵树只有一个根结点。
-
位于树中较低层的结点是上一层结点的孩子(children) , 同一双亲的两个结点称为兄弟(sibling) 。
-
没有任何孩子的结点称为叶子(leaf) , 一个至少有一个孩子的非根结点 ** 称为一个内部结点(internal node)** 。
-
若某一结点A从根 ** 开始的路径中位于另一结点B之上,则称A 为B的祖先(ancestor) ** , 根是树中所有结点的最终祖先。
-
沿着起始自某一特定结点的路径可以到达的结点是该结点的子孙(descendant) 。
![]()
-
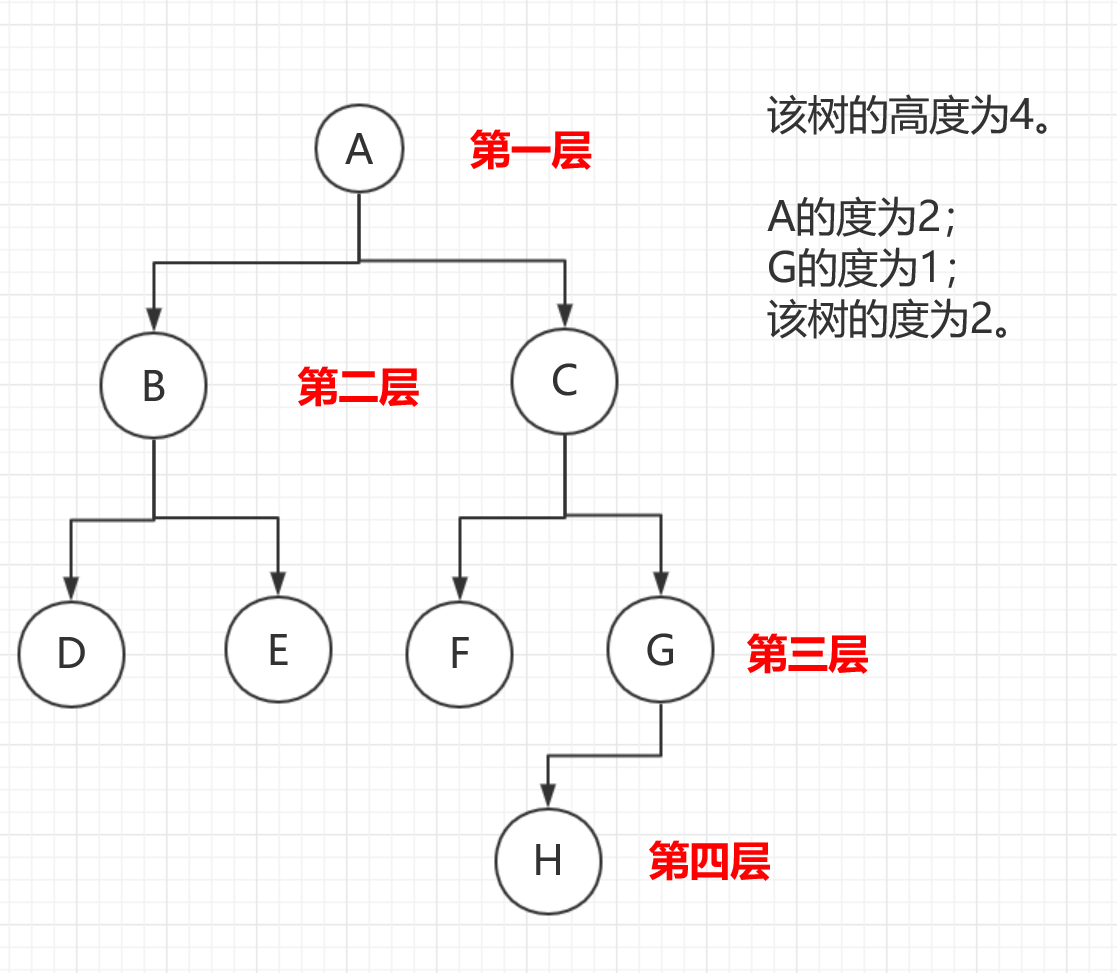
结点的层 ** :从根结点 ** 到该结点的路径长度。通过计算从根到该结点所必须越过的边数目,就可以确定其路径长度(path length) 。
-
树的**高度(height) ** :指从根到叶子之间最远路径的长度。
![]()
-
10.1.1 树的分类:
-
**分类 ** 方式有很多种:
-
最重要 ** 的一条标准是树中任一结点可以具有的最大孩子数目。这一值有时候也称为该树的度 (order)** 。
-
广义树(general tree) : 对结点所含有的孩子数目**无限制 ** 的树。
-
n元树(n-ary tree) : 每一结点所含孩子数目不超过n。
-
二叉树(binary tree) : 结点最多具有两个孩子。
-
**另一种分类方式: **
-
判断该树是否平衡;粗略地说,如果树的所有叶子都位于同一层或者至少是彼此相差不超过一层,就称之为是平衡的。
-
含有m个元素的平衡n元树具有的高度为lognm。 含有n个结点的平衡二叉树具有的高度为log2m。
-
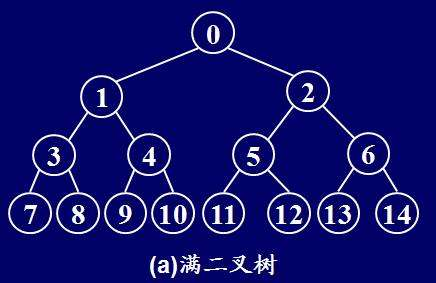
完全树(complete tree) : 如果一棵树是平衡的,且底层所有叶子都位于树的左边,则认为该树完全。
-
完全二叉树在每个k层上都具有2k个结点,最后一层除外,在最后一层的结点必须是最左边结点。
![]()
-
满树(full tree) : n元树的所有叶子都位于同一层且每个结点只有一片叶子或正好具有n个孩子。
![]()
-
10.2 实现树的策略
-
10.2.1 树的数组实现之计算策略:
-
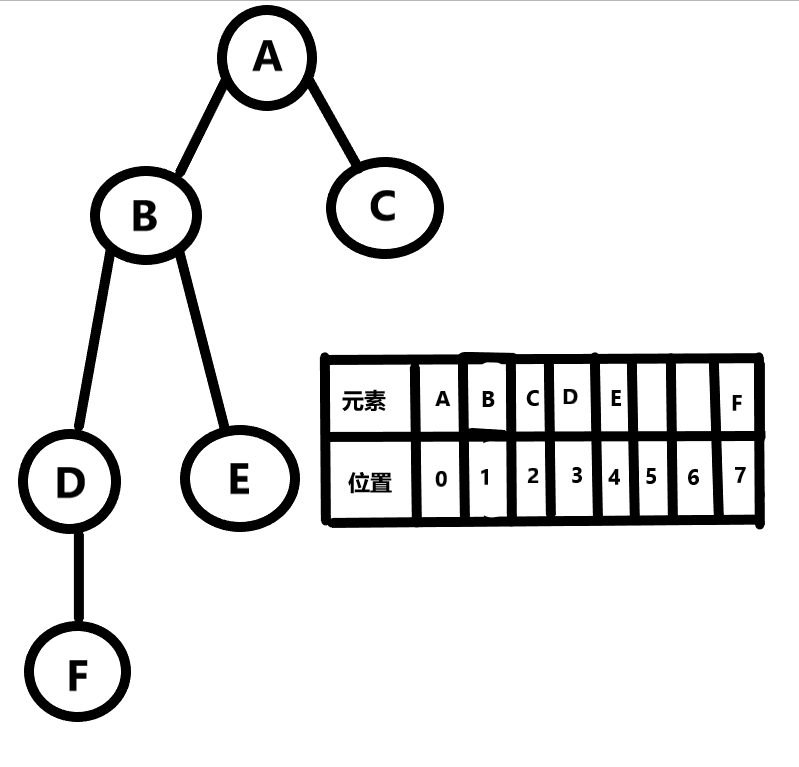
对于任何存储在数组 ** 位置n处的元素而言,该元素的左孩子 ** 将存储在位置(2 x n +1) 处 ,该元素的右孩子则存储在位置(2 x (n + 1)) 处。
-
缺陷 : 浪费存储空间;其会为不完全树的无元素位置分配多余的空间。
![]()
-
10.2.2 树的数组实现之模拟链接策略:
-
数组的每一个元素都是一个结点类,每一结点存储的是每一孩子(可能还有其双亲)的数组索引,而不是作为指向其孩子(可能还有其双亲)指针的对象引用变量。
-
元素能连续存储在数组中,不会浪费存储空间。
-
增加了删除树中元素的成本,要么对剩余元素进行移位以维持连续状态,要么保留一个空闲列表。
-
该策略允许连续分配数组位置而不用考虑该树的完整性。


- 10.3 树的遍历
![]()
- 10.3.1 前序遍历(preorder traversal):
- 从根结点开始,访问每一结点及孩子。

-
10.3.2 中序遍历(inorder traversal):
-
从根结点开始,访问节点的左孩子,然后是该结点,再然后是剩余任何结点。
![]()
-
10.3.3 后序遍历(postorder traversal):
-
从根结点开始,访问结点的孩子,然后是该结点。
![]()
-
10.3.4 层序遍历(level-order traversal):
-
从根结点开始,访问每一层的所有结点,一次一层。
![]()
-
10.4 二叉树
-
二叉树的操作:
-
| 操作 | 说明 |
| -------- | :----------------: |
| getRoot |返回指向二叉树根的引用 |
| isEmpty |判定该树是否为空 |
| size |判定树中的元素数目 |
| contains |判定指定目标是否在树中 |
| find |如果找到指定元素,则返回指向其引用 |
| toString |返回树的字符串表示 |
| iteratorInOrder| 为树的中序遍历返回一个迭代器|
| iteratorPreOrder |为树的前序遍历返回一个迭代器 |
| iteratorPostOrder| 为树的后序遍历返回一个迭代器|
| iteratorLevelOrder |为树的层序遍历返回一个迭代器 |


教材学习中的问题和解决过程
- 问题1:无。
- 解决:
代码调试中的问题和解决过程
-
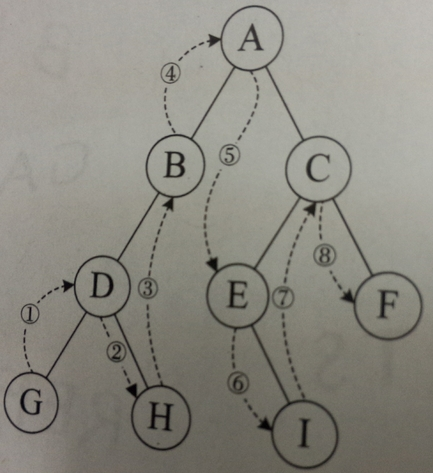
问题1:如何删除某一指定结点的子树。
-
解决:
-
刚开始的代码是:
public LinkedBinaryTree removeRightsubtree(){
LinkedBinaryTree Rightsubtree = new LinkedBinaryTree();
Rightsubtree.root = root;
root.right = null;
return Rightsubtree;
}
- 定义一个新二叉树,将原二叉树复制,之后将二叉树根右孩子赋予null,这样右孩子与其后代便可全部删除。
![]()
- 如果要删除某一内部结点的子树怎么办?
- 刚开始我写的方法是这样的:

public LinkedBinaryTree removeRightsubtree(BinaryTreeNode node){
LinkedBinaryTree Rightsubtree = new LinkedBinaryTree();
Rightsubtree.node = node;
node.right = null;
return Rightsubtree;
}
- 然而并不知道具体的元素结点的索引,因此决定换个参数:
public LinkedBinaryTree removeRightsubtree(T Element){
LinkedBinaryTree Rightsubtree = new LinkedBinaryTree();
BinaryTreeNode node = new BinaryTreeNode(Element);
Rightsubtree.node = node;
node.right = null;
return Rightsubtree;
}
- 仿造删除根的子树的方法,直接给索引结点赋null,然而,node只是我自己新建立的结点,赋值为Element,并非真正想删除的树的内部结点。
![]()
- 显而易见,没删除掉;
- 之后发现首要解决的是找到对应Element元素的位置,然而头铁的我刚开始打算自己写,写了半天一大堆错误之后,才记起有个findNode方法:
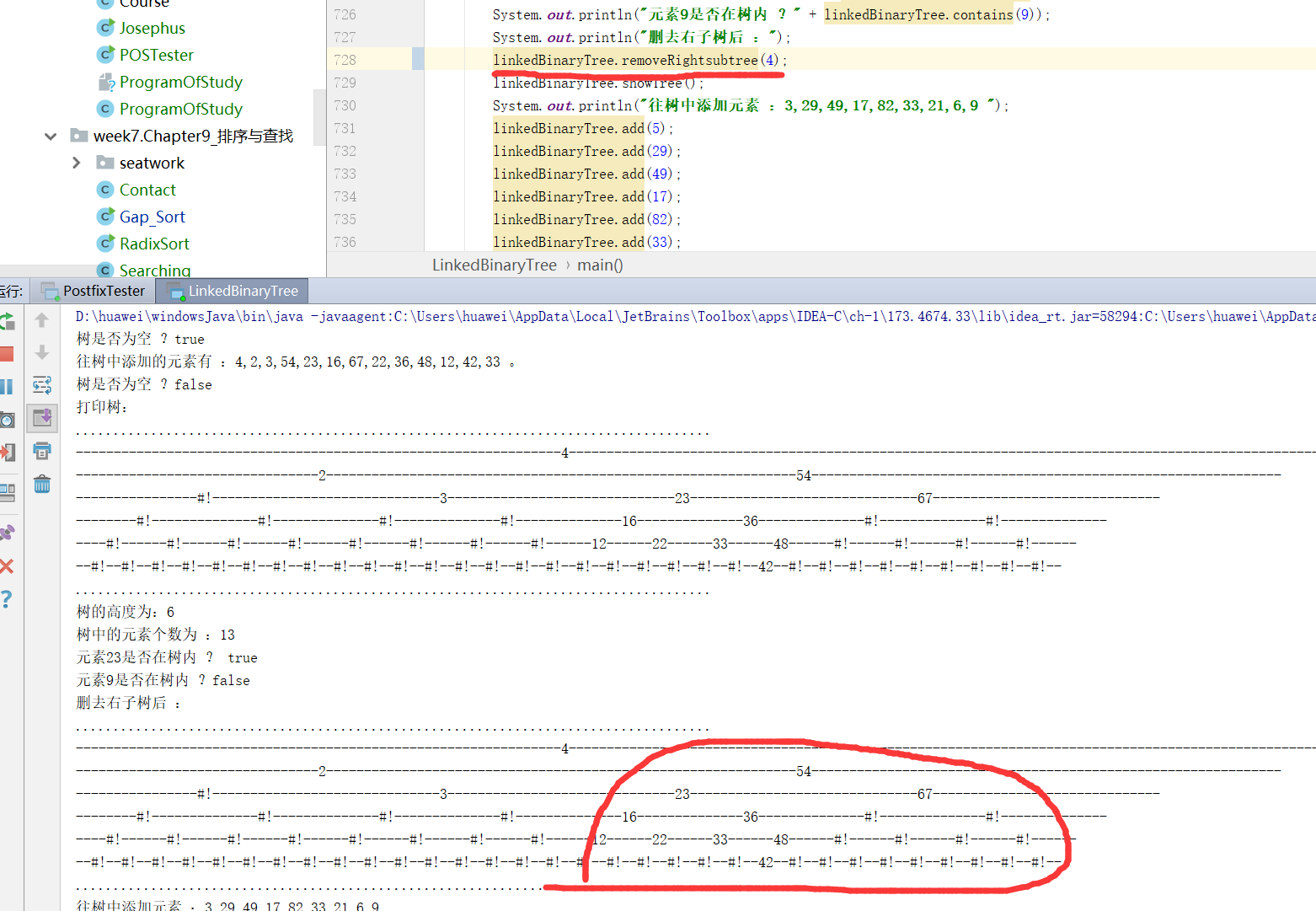

- 前面一样先将原树复制,后面找到Element所在位置,然后对其子树进行赋值null,即可删除。
![]()

代码托管
上周考试错题总结
- 错题1:上周无测试活动。
- 解决:
- 错题2:
- 解决:
- 错题3:
- 解决:
结对及互评
点评过的同学博客和代码
- 本周结对学习情况:
- 20172316赵乾宸
- 博客中值得学习的或存在问题:
- 20172329王文彬
- **博客中值得学习的或存在问题: **
- 博客内容充实、排版整齐、对教材内容有经过一番认真思考、继续保持。
- 代码截图做标注时应尽量避免遮挡代码。
- Markdown的部分缩进有误。
- 教材问题2提出得很好,可以看出近断时间来反复使用链表、数组去实现同一类型的数据结构起得了一定的成效。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | |
|---|---|---|---|
| 目标 | 3000行 | 15篇 | 300小时 |
| 第一周 | 0/0 | 1/1 | 12/12 |
| 第二周 | 935/935 | 1/2 | 24/36 |
| 第三周 | 849/1784 | 1/3 | 34/70 |
| 第四周 | 3600/5384 | 1/5 | 50/120 |
| 第五周 | 2254/7638 | 1/7 | 50/170 |
| 第六周 | 2809/10447 | 1/9 | 45/215 |
| 返回目录 |
参考资料
- ** 树的定义、分类及存储 **
- 数据结构及算法基础--树(Tree)(一)基础详解
- 【图解数据结构】 树
- ** 二叉树的4种遍历方法图解 **
返回目录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号