
机器学习基石1 学习笔记
Foundation Lesson 1
Course Introduction
- Foundation作为在大学课堂上教授课程的前半部分,Techniques是大学课堂上教授课程的后半部分。这里的Foundation和Techniques是根据Cousera的编排需求而修订的。
What's machine learning?
-
Learning是什么?机器学习定义是什么
机器学习是我们希望用电脑来模拟或模仿人类的学习过程。
acquiring skill with experience accumulated/computed from data, which skill is defined by improving some perfomance measure, so machine learning improve some perfomance measure with experience computed from data. -
为什么要使用机器学习?
一些事物的特征,不好人为定义(比如定义图片中的一棵树)。但是,通常不是人为那么好定义的。
通常人们自然的方法是,learn from data(observations) and recognize。
so ML-based tree recognization system can be easied to build than hand-programmed system.
![]()
这里面,第三/四条是随着机器学习技术的应用发展,新出现的商业、服务模式,单单以往的算法和人力,不能完成此类巨大工作量的服务。
机器学习的思想,像是“授人以鱼不如授人以渔”。使得电脑可以替人解决各种各样的问题。 -
机器学习使用的key essense
一些思考,对于机器学习的应用,是因为一些数据或信息,人无法感知、无法识别,或是数据信息量特别大;或者是人的处理满足不了需求,比如定义很多的规则满足物体识别或者语音识别,在短时间内通过大量信息作出判断等。- exists some 'underlying pattern' to be learnt
- so 'performance measure' can be improved
- no programmabel definition
- so Machine Learning is needed
- somehow there is data about the pattern
- so Machine Learning has some inputs to learn from
- exists some 'underlying pattern' to be learnt
-
机器学习应用的场景
- 衣食住行
- 娱乐
- Netflix 推荐算法比赛——100,480,507评分,480,189个用户,17,770部电影
- Yahoo! 2011 KDD Cup——252,800,275评分,1,000,990个用户,624,961首歌曲
比较大的数据量,人工难以快速确定每个用户的喜好

其实,台湾大学林轩田老师的《机器学习视频》之所以一度很火爆,是因为从2010年到2013年的KDDCup中,他们队伍都取得了第一名的成绩。
Componets of Machine Learning
- 模型
- hypothesis set \(\mathcal{H}\), 未知的函数
- 演算法(learning algorithms \(\mathcal{A}\)
- 训练集
- \(\mathcal{D}: \{\mathbf{x}_1,y_1\}, \{\mathbf{x}_2, y_2\},\ldots\)
- 输入和输出
\(\mathcal{X}\)和\(\mathcal{Y}\)
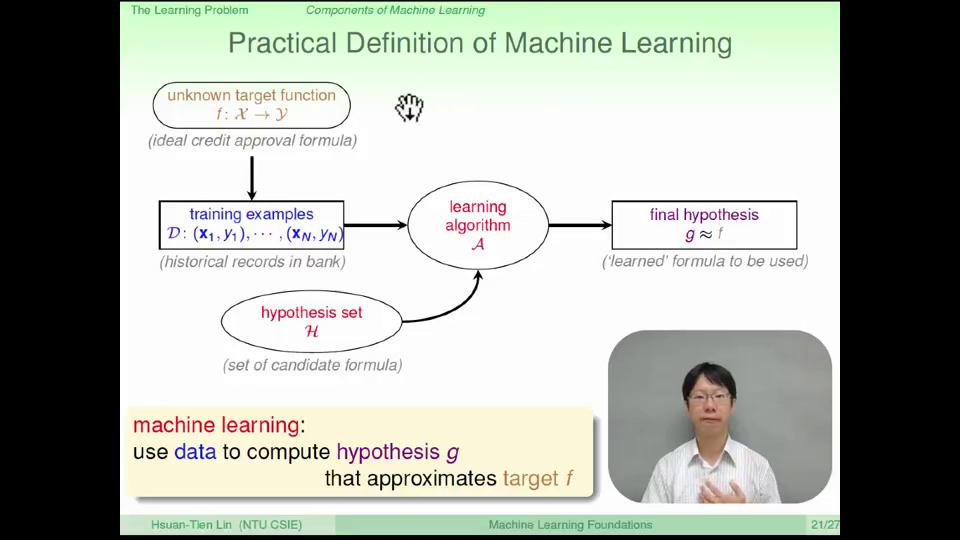
机器学习的方法,抽象上来说,是从我们未知但是存在的一个规则或者公式\(f\)约束下的大量的数据(资料,即训练样本的基础上),得到一个近似于未知规则\(g\)的过程。
配置网页上cnblog中的MathJax有一个比较好的博文,是前端整合MathJax笔记。
对于我的学习笔记,可以参考相同课程的的其他笔记来看杜少。
Foundation Lesson 2
感知器
这堂课简单介绍一个有输入输出,模型的机器学习算法,应用在二元分类问题(信用卡审批)上——感知机。
输入是用户的各种属性,如年龄、年薪、工作年限、负债情况等,这些属性可以作为上面一节课提到的样本输入\(\mathcal{x}=\{x_1, x_2, x_3, x_4\}^T\)向量的属性值。
假设的模型\(\mathcal{H}\),类似考试给的成绩,对每一题给一个特定的分数,即权重:给输入向量的每个属性乘以一个权重\(\omega_i\),设计一个及格线,即所谓的阈值(threshhold),如果加权求和的分数大于这个及格线就输出1,小于这个及格线称为不及格,输出值为-1.。
那么,\(h(x) = sign\left(\sum_{i=1}^d w_i x_i - threshold \right)\), 简化为\(h(x) = sign(W^T \cdot X)\)。
上面的公式,对应了一个\(h(x)\),不同的\(h(x)\)对应的不同的向量\(W\),即可以说假设空间\(\mathcal{H}\)就是向量\(W\)的取值范围。以上公式表达了一种模型,称为感知器,是一种二元线性分类器。
感知器学习算法(Perception Learning Algorithm)
公式 \(sign(W^T \cdot X_{n(t)} \ne y_{n(t)}\),那么\(W_{t+1} = W_{t} + y_{n(t)} \cdot x_{n(t)}\)。如下图所示:

上图,需要特别注意一下,理解:
- 对于false negative point(\(y\)是1,分类为-1的点),\(W_{t+1} \leftarrow W_{t}+ x_{n(t)}\),图上理解为,将\(W_{t+1}\)是当前\(W_{t}\)和\(x_{n(t)}\)的平行四边形对角线,\(W_{(t+1)}\)靠近 \(x_{n(t)}\);
- 对于false positive point,\(W_{t+1} \leftarrow W_{t} - x_{n(t)}\),\(W_{(t+1)}\) 夹角偏离\(x_{n(t)}\)。
上述两种情况,综合到一个公式里,\(W_{(t+1)} = W_{t} + y_{n(t)}x_{n(t)}\)。
感知机更新\(W_{t}\)的过程,可以参考原课件Page9-18。
感知器PLA在线性可分的超平面上的执行有穷性
可以证明,感知机模型的\(W_t\),在经过一段迭代的更新权值后会停止,即\(t\)次修正有上界。
首先我们考虑是否每次修正都可以使得权值向量\(W_t\)变得更好,就是是否会更接近未知的目标函数所表示的向量。有了这个思路,我们先假设目标函数的权值向量为\(W_f\),可以求解出两个向量相似度的度量方式有很多,其中比较常用的一种方式就是求两个向量的内积,于是我们对\(W_f\)和\(W_T\)做内积。其中T表示为停止时的次数。
可以先证明,\(W_t\)的变化有上界(终止条件)\(W_f\)。
再证明,迭代的每次,\(\lVert W_{t+1} \rVert^2 = \lVert W_t \rVert ^2 + \max_n \lVert y_nX_n \rVert^2\),
所以,
以上两个步骤,说明在线性可分的数据集上,PLA方法可以终止。
其实,这个小章节的部分,解决了算法理解的过程中\(W_t\)会不会在最优值\(W_f\)左右要摇摆不收敛的疑惑,证明PLA方法可以学习到较优的\(W_t\)。
Types of Learning
Learning with different Output Space \(\mathcal{y}\)
Classification Problems
- binary classification
- Multiclass Classification: Coin Recognition Problem
- written digits
- pictures: apple, orange, strawberry
- emails: spam, primary, social, promotion, update
- many applications, especially in 'recognition'
Regression Problem
- regression example
- patient features \(\rightarrow\) how many days before recovery
- \(\mathcal{y} = \mathcal{R}\) or \(\mathcal{y} = [lower, upper] \in \mathcal{R}\)(bounded regression)
--deeply studied in statistics - company feature to predict stock price
这里可以通过以上举例,Classification和Regression的不同之处:我理解,机器学习中分类问题是从现有数据中识别出某些目标,回归问题从现有数据中找出模型、预测数据集之外的数据实例点,可以在以后数据集扩大后来验证模型的准确性。
Structure Learning
不同于多类别分类问题中的“词->词性"的分类,输入是一个句子,输出是句子的文法结构,模型\(\mathcal{H}\)是识别句子文法结构的算法,这里“文法结构”是不能穷举的,无法显式定义,所以归为"huge multiclass classification problem"。
其他Structure Learning的问题,比如"protein data->protein folding"/"speech data->speech parse tree"等。
可能隐私识别问题,是一种structure learning。
Learning with Different Input Space \(\mathcal{X}\)
the process from raw features to concrete features is called feature engineering.

Feasibility of Learning
Connection between Hoeffding's Inequality and Learning
通过霍夫丁不等式,
\(P( \left [ \vert \mu - \nu \vert \right ]) \le 2 exp \left( -2\epsilon^2 N\right)\)
可以知道,在训练集上的学习算法(learning algorithm)训练的模型\(\mathcal{h}\)的准确率,可以近似看做是\(\mathcal{f}\)在整个空间中的准确率(probably aproximately correct, PAC)。
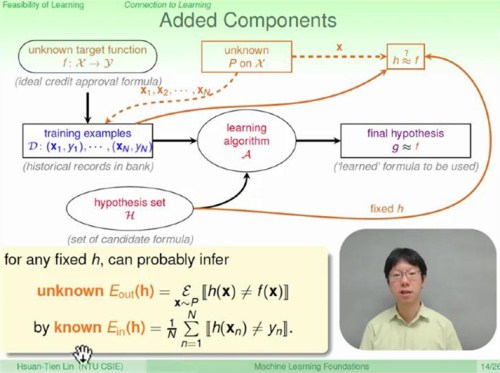
因而,如果在训练集上可以得到一个较为准确的模型,理论上可以认为该模型泛化在整个数据空间中的准确率接近在训练集上的模型准确率。

在机器学习涵盖的learning algorithm,不同于Verification flow——将模型空间中的所有模型一个一个地在测试集上检验,来找出最优模型。Verification flow可以用来评价learning algorithm训练的模型的准确性。
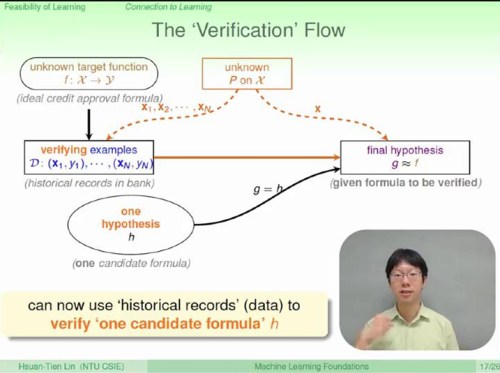
比较有意思的是这小节的测试题:

说明,
1. 在训练集和测试集的选取上,训练集和测试集要满足相同的分布规律,
2. (3) learning algorithm 不同与 verification flow。
Connection to Real Learning
这里通过类比其他事件,明确一个观点:对训练集和测试的选取,要避免那些频率上罕见出现的训练集组成。有些训练集,对多个模型空间中的模型,都是不好的训练集,训练的准确率和测试准确率差别很大(可以说,对于某一个模型,数据集的特性(比如说线性分类模型,应用在线性不可分的训练集上)比较重要,数据的特性影响到模型的选择)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号