OPENCV-c++ vscode 学习笔记
opencv-c++ vscode 学习笔记
内容源于网络搜集和个人整理,仅供个人学习与交流
环境安装及配置
见: Vscode配置opencv(简洁)_河旬的博客-CSDN博客 这个给了配好的相应资源,比用cmake编译之类的好多了。但最终

在这里添加了博客中代码中opencv对应的地址 最终还是解决了
opencv基本数据类型
Point,Size,Rect,Scalar,Vec3b
-
Point
Point类是一个包含两个整形数据成员x和y的以及一些简单成员 方法的类类型,和它有关的好几个Point点类的变种如下所示:
//【1】Point2f----二维单精度浮点型点类
//【2】Point2d----二维双精度浮点型点类
//【3】Point3i----三维整形点类
//使用: Point2i p1;//数据为[0,0] Point3f p2;//数据为[0,0,0] cout << p1 << '\n' << p2 << endl; -
Size
OpenCv中尺寸的表示--------Size类源代码分析 OpenCv中尺寸Size类与点Point类的表示十分类似,最主要的区别是,Size(尺寸)类的数据成员是width和 height,而Point类的数据成员是坐标点
#使用 python为例 import cv2 image = cv2.imread('xxx.jpg') size = image.shape w = size[1] #宽度 h = size[0] #高度 print(size) print(w) print(h) -------结果如下--------- (512, 772, 3) 772 512 -
Rect
ect矩形类,它有四个很重要的数据成员x,y,width,height,分别代表这个矩形左上角的坐标点和矩形 的宽度和高度,并且Rect类提供了很实用的一些成员方法,比如说:求左上角和右下角的成员函数,等等
-
Scalar
opencv中的颜色表示,后文有所提及
-
Vec3b
三维向量,存储色彩rgb信息,每个分量都是uchar类型,后文有所提及
-
RotatedRect
旋转矩阵类
(38条消息) OpenCV之RotatedRect基本用法和角度探究_opencv rotatedrect_sandalphon4869的博客-CSDN博客
RotatedRect(const Point2f& center, const Size2f& size, float angle);解释:
center 旋转矩形的质心 size 旋转矩形的宽度和高度 angle 顺时针方向的旋转角度。当角度为0°,90°,180°,270°等时,矩形变为右上方的矩形
RotatedRect(const Point2f& point1, const Point2f& point2, const Point2f& point3);
通过输入三个点的坐标,也可以创建旋转矩阵,但要指定三个点的顺序:矩形的任意三个点。注意必须遵从逆时针或顺时针的顺序
成员函数:
Rect boundingRect () const
returns the minimal up-right integer rectangle containing the rotated rectangle
Rect_< float > boundingRect2f () const
returns the minimal (exact) floating point rectangle containing the rotated rectangle, not intended for use with images
void points (Point2f pts[]) const
returns 4 vertices of the rectangle。返回矩形四个顶点的Point2f类位置信息给pts数组
在如下代码中便用到了
#include <iostream>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main()
{
Mat test_image(200, 200, CV_8UC3, Scalar(0));
RotatedRect rRect = RotatedRect(Point2f(100, 100), Size2f(100, 50), 30);
/*获得角度*/
cout << rRect.angle << endl;
//角度30度
/*获得中心点*/
cout << rRect.center << endl;
//中心点[100, 100]
/*获得宽×高*/
cout << rRect.size << endl;
//宽×高[100 x 50]
/*获得宽*/
cout << rRect.size.width << endl;
// 100
/*获得高*/
cout << rRect.size.height << endl;
// 50
/*获得面积*/
cout << rRect.size.area() << endl;
//5000
//绘制旋转矩形
Point2f vertices[4];
rRect.points(vertices);
for (int i = 0; i < 4; i++)
line(test_image, vertices[i], vertices[(i + 1) % 4], Scalar(0, 255, 0), 2); //这个是利用画线,多个线段组成的ju'xing
//圈中这个旋转矩形的外矩形
Rect brect = rRect.boundingRect();
rectangle(test_image, brect, Scalar(255, 0, 0), 2);
imshow("rectangles", test_image);
waitKey(0);
return 0;
}
inputArray、outputArray、InputOutputArray
array作为数组,是线性存储方式的数据的集合,就是图像作为二维数组的方式进行存储
经验分享
Array 是数组的意思,更直观的理解方式是一个排列,是有线性储存方式的数据的集合。
Input 和 Output 在解读代码时是为了标注输入输出使用,如果查看源码[1],可发现InputArray是首先编写的基本接口,而OutputArray是对InputArray的继承,增加了一些作为输出类所应有的成员;在此之上,又有InputOutputArray继承了OutputArray,作为输入输出接口,它的功能比前两者更多,也能起到更多的作用。
因此我们可以理解了输入排列:InputArray``输出排列:OutputArray``输入输出排列:InputOutputArray三个类。
之后三者是ArraysOfArrays,是前三者的排列,即排列的排列,定义使用了typedef。
Size 与 Point与Mat
Size是个范围,Size size(9,9)
有:
size.width = 3, size.height = 3;
Point是具体的某个点
有
Point origin
origin.x
origin.y
Mat则有:
Mat img
img.cols
img.rows
图片读取及保存
Mat
Mat 类
Mat 是一个基本图像容器,也是一个类,数据由两个部分组成: 矩阵头(包含矩阵尺寸,存储方法,存储地址等信息)和一个指向存储所有像素值的矩阵(根据所 选存储方法的不同矩阵可以是不同的维数)的指针。
Mat A, C; //仅创建了头部
A = imread(argv[1], CV_LOAD_IMAGE_COLOR); //在此我们知道使用的方法(分配矩阵)
Mat B(A); //使用拷贝构造函数
C = A; //赋值运算符
上文中的所有对象,以相同的单个数据矩阵的结束点。他们头不同,但是使用的其中任何一个对矩阵进行任何修改,也将影响所有其他的。

(29条消息) OpenCV Mat类详解和用法_cv::mat api_AI吃大瓜的博客-CSDN博客
(29条消息) OpenCV学习之Mat::at()理解_mat.at_xueluowutong的博客-CSDN博客
【从零学习OpenCV 4】Mat类构造与赋值 - 知乎 (zhihu.com)
Mat的初始化:
//一种:
Mat a(rows,cols,type,Scalar()); //手动输入行列
//另一种:
Mat b(size(row,col),type,Scalar()) //通过size的行列获取
cv::Mat::Mat(int rows, //行数
int cols, //列数
int type, //种类
const Scalar & s //给矩阵中所有元素赋值,Scalar(1)就是将元素赋值为1 如果是双通道,那么就是 Scalar(1,2) :给每个像素点赋值为(1,2) ,如果是三通道,就是 Scalar(32,1,3) :给每个像素点赋值为(32,1,3)
)
Mat::at() 用于获取图像矩阵某点的值或改变某点的值。
对于单通道图像的使用方法:
image.at<uchar>(i,j) = 255;
对于RGB三通道图像的使用方法:
image.at<Vec3b>(i,j)[0] = 255;
image.at<Vec3b>(i,j)[1] = 255;
image.at<Vec3b>(i,j)[2] = 255;
Mat::at()取值或改变某点的像素值比较耗时,可以采用Mat的模板子类Mat_<T>
实现对图像矩阵中某个值的获取和改变。
单通道的使用方法:
Mat_<uchar> img = image;
img(i,j) = 255;
三通道RGB的使用方法:
Mat_<Vec3b> img = image;
img(i,j)[0] = 255;
img(i,j)[1] = 255;
img(i,j)[2] = 255;
imread()
Mat imread( const String& filename, int flags = IMREAD_COLOR );
功能:读取图片文件中的数据
参数:filename:图片路径
flags:指定读取图片的颜色类型,注意:opencv 版本不同,宏可能不一样
opencv3.2.0 中 IMREAD_GRAYSCALE 值为 0,表示显示灰度图 IMREAD_COLOR 值为 1,表示显示原图
返回值:Mat 类对象
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main()
{
Mat src = imread("./../img/girl.jpg",IMREAD_GRAYSCALE);
// namedWindow("输出窗口",WINDOW_FREERATIO); //当图像太大是可以用WINDOW_FREERATIO,创建窗口
imshow("input",src); //input是显示窗口的名称
waitKey(0); //
destroyAllWindows(); //清除所有显示的窗口
return 0;
}
//读取图像可选参数
//! Imread flags
enum ImreadModes {
IMREAD_UNCHANGED = -1, //!< If set, return the loaded image as is (with alpha channel, otherwise it gets cropped).
IMREAD_GRAYSCALE = 0, //!< If set, always convert image to the single channel grayscale image.
IMREAD_COLOR = 1, //!< If set, always convert image to the 3 channel BGR color image.
IMREAD_ANYDEPTH = 2, //!< If set, return 16-bit/32-bit image when the input has the corresponding depth, otherwise convert it to 8-bit.
IMREAD_ANYCOLOR = 4, //!< If set, the image is read in any possible color format.
IMREAD_LOAD_GDAL = 8, //!< If set, use the gdal driver for loading the image.
IMREAD_REDUCED_GRAYSCALE_2 = 16, //!< If set, always convert image to the single channel grayscale image and the image size reduced 1/2.
IMREAD_REDUCED_COLOR_2 = 17, //!< If set, always convert image to the 3 channel BGR color image and the image size reduced 1/2.
IMREAD_REDUCED_GRAYSCALE_4 = 32, //!< If set, always convert image to the single channel grayscale image and the image size reduced 1/4.
IMREAD_REDUCED_COLOR_4 = 33, //!< If set, always convert image to the 3 channel BGR color image and the image size reduced 1/4.
IMREAD_REDUCED_GRAYSCALE_8 = 64, //!< If set, always convert image to the single channel grayscale image and the image size reduced 1/8.
IMREAD_REDUCED_COLOR_8 = 65, //!< If set, always convert image to the 3 channel BGR color image and the image size reduced 1/8.
IMREAD_IGNORE_ORIENTATION = 128 //!< If set, do not rotate the image according to EXIF's orientation flag.
};
Scalar()---给图像设置颜色
首先要知道Scalar在图像初始化时可以给图像中的像素点赋初值
例如:单通道时
Mat a(row,col,type,Scalar(45)); //就是给图像中的每个点赋灰度初值 45
再例如三通道gbr时
Mat b(row,col,type,Scalar (0,255,0)); //就是将图像中的bgr赋值,b = 0,g = 255,r = 0;绿色图像
(40条消息) opencv中的Scalar()函数_opencv scalar_一叶孤舟渡的博客-CSDN博客
矩阵存储type---- cv_xxxx(eg.CV_8UC3)
指定的数据类型,用于存储元素和每个矩阵点通道的数量。为此,我们根据以下的约定可以作出多个定义:
CV_ [每一项的位数] [有符号或无符号] [类型前缀] C [通道数]
例如,CV_8UC3 意味着我们使用那些长的 8 位 无符号的 char 类型和每个像素都有三个项目的这三个通道的形成。这是预定义的四个通道数字。Scalar 是四个元素短向量。指定此和可以初始化所有矩阵点与自定义的值。。
#include<opencv2/opencv.hpp>
#include<iostream>
using namespace std;
using namespace cv;
int main()
{
/*
Mat矩阵存储的数据类型
CV_8UC1// 8位无符号单通道
CV_8UC3// 8位无符号3通道
CV_8UC4
CV_32FC1// 32位浮点型单通道
CV_32FC3// 32位浮点型3通道
CV_32FC4
*/
Mat a(Size(3,3),CV_8UC1); //创建3行3列的单通道矩阵,采用默认初始化方式
//也可以这样写:Mat a(3,3,CV_8UC1)
Mat b(Size(3,3),CV_8UC3); //创建3行3列的三通道矩阵,三通道矩阵中,一个矩阵元素包含3个变量。
cout<<"a="<<a<<endl;
cout<<"b="<<b<<endl;
//对矩阵进行初始化
Mat c=Mat::zeros(Size(3,3),CV_8UC1); //全零矩阵
Mat d=Mat::ones(Size(4,4),CV_8UC4); //全1矩阵
cout<<"c="<<c<<endl;
cout<<"d="<<d<<endl;
system("pause");
return 0;
}
创建:create()函数
函数功能:*
1)如果需要,分配新的数组数据
2)创建一个图像矩阵的矩阵体
函数参数:
1)ndims:新的数组维数
2)rows :新数组的行数
3)cols :列数
4)Size :新矩阵的尺寸
5)type :新的矩阵类型
int main() {
Mat srcImage, grayImage;
srcImage = imread("/Users/dwz/Desktop/cpp/1.jpg");
Mat srcImage1 = srcImage.clone();
cvtColor(srcImage, grayImage, COLOR_BGR2GRAY);
Mat dstImage, edge;
blur(grayImage, grayImage, Size(3,3));
Canny(grayImage, edge, 150, 100, 3);
dstImage.create(srcImage1.size(), srcImage1.type()); //create函数
dstImage = Scalar::all(0);
srcImage1.copyTo(dstImage, edge);
imwrite("canny.jpg", dstImage);
return 0;
}
具体的讲解:
文件说明:
cv::create()函数的详解
函数原型:
inline void Mat::create(int _rows, int _cols, int _type)
inline void Mat::create(Size _sz, int _type)
void Mat::create(int ndims, const int* sizes, int type)
函数功能:
1)如果需要,分配新的数组数据
2)创建一个图像矩阵的矩阵体
函数参数:
1)ndims:新的数组维数
2)rows :新数组的行数
3)cols :列数
4)Size :新矩阵的尺寸
5)type :新的矩阵类型
补充说明:
1)这是cv::Mat图像矩阵容器类的一个重要方法
2)
详细说明:
1)关于cv::Mat。我们都知道它有两大特点:
1)不必在手动为其开辟空间
2)不必再不需要时立即将空间释放
2)但是,我们还是必须清楚的知道,cv::Mat是一个矩阵图像类,它的确有两部分组成:
1)矩阵头:包含矩阵的尺寸、存储方法、存储地址等信息和一个指向存储图像中所有像素的矩阵体
2)矩阵体
3)请看下面的代码:
cv::Mat srcImg;
cv::Mat dstImg;
我们在写代码的时候,需要清楚的知道,上面这两句代码仅仅创建了图像矩阵的信息头部分,并没有
创建矩阵体!
4)因此,说到这块,cv::Mat::create()函数的作用就很清楚了,创建一个指定大小(Size),指定类型
type(CV_8UC1,CV_16SC1,CV_32FC3)的图像矩阵的矩阵体
srcImg.create(........)
函数说明:
函数cvRound,cvFloor,cvCeil 都是用一种舍入的方法将输入浮点数转换成整数:
具体说明:
1)cvRound 返回跟参数最接近的整数值;
2)cvFloor 返回不大于参数的最大整数值;
3)cvCeil 返回不小于参数的最小整数值。
补充: c++基础知识:内联函数inline

(42条消息) C++ 11 内敛函数inline_c++11 inline 函数_BUG_C++的博客-CSDN博客
(40条消息) OpenCV-Mat类型矩阵基本操作与示例_mat 零矩阵_StrawberryBoy的博客-CSDN博客
nameWindow() 窗口显示格式
- 窗口显示格式
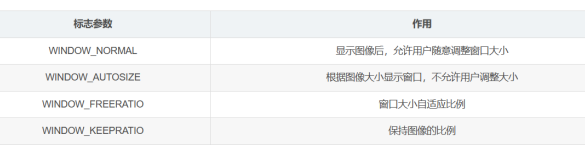
opencv中namedWindow( )函数用法总结(02)_洛克家族的博客-CSDN博客
putText在图片中添加文字
cvtColor(src,hsv,COLOR_BGR2HSV)
我们生活中大多数看到的彩色图片都是RGB类型,但是在进行图像处理时,需要用到灰度图、二值图、HSV、HSI等颜色制式,opencv提供了cvtColor()函数来实现这些功能。首先看一下cvtColor函数定义:
C++: void cvtColor(InputArray src, OutputArray dst, int code, int dstCn=0 );
#include <iostream>
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
using namespace std;
using namespace cv;
int main()
{
Mat srcImage = imread("星空.png");
//判断图像是否加载成功
if(!srcImage.data)
{
cout << "图像加载失败!" << endl;
return false;
}
else
cout << "图像加载成功!" << endl << endl;
//显示原图像
namedWindow("原图像",WINDOW_AUTOSIZE);
imshow("原图像",srcImage);
//将图像转换为灰度图,采用CV_前缀
Mat grayImage;
cvtColor(srcImage, grayImage, CV_BGR2GRAY); //将图像转换为灰度图
namedWindow("灰度图",WINDOW_AUTOSIZE);
imshow("灰度图",grayImage);
//将图像转换为HSV,采用COLOR_前缀
Mat HSVImage;
cvtColor(srcImage, HSVImage, COLOR_BGR2HSV); //将图像转换为HSV图
namedWindow("HSV",WINDOW_AUTOSIZE);
imshow("HSV",HSVImage);
waitKey(0);
return 0;
}
(29条消息) opencv学习(十六)之颜色空间转换cvtColor()_cvtcolor用法_梧桐栖鸦的博客-CSDN博客
图像的遍历
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main()
{
// Mat src = Mat::zeros(Size(8,8),CV_8UC3);
// src = Scalar(0,255,255);
Mat src = imread("C:/Users/Tan/Pictures/9f281e856584d50c19cfbeb8fe5eeda3b595ab67.jpg",1);
Mat src1;
src.copyTo(src1); //把src的内容复制到 src1 上
int w = src.cols; //宽
int h = src.rows; //高
int dims = src.channels(); //通道数
std::cout<<"宽: "<<w<<"高: "<<h<<"通道数: "<<dims<<endl;
for (int raw= 0; raw < h; raw++)
{
for(int col=0; col<w;col++)
{
if(dims==1) //单通道灰度图
{
int pv=src1.at<uchar>(raw,col); //(y,x) mat.at 获取当前像素点的值(0~255)
src1.at<uchar>(raw,col) = 255-pv;
}
if(dims==3) //彩色图片
{
Vec3b bgr = src1.at<Vec3b>(raw,col); //一次性获取三个值
//图像取反操作 : 255 - 原先色彩值
src1.at<Vec3b>(raw,col)[0] = 255-bgr[0];
src1.at<Vec3b>(raw,col)[1] = 255-bgr[1];
src1.at<Vec3b>(raw,col)[2] = 255-bgr[2];
}
}
}
imshow("像素读写演示",src1);
waitKey(0);
destroyAllWindows();
return 0;
}
(29条消息) OpenCV4学习笔记(2)——图像的像素遍历_邱小兵的博客-CSDN博客
对图像的遍历我理解为:对像素点的遍历
上述代码中有几点新内容:mat::at(), Vec3b,uchar

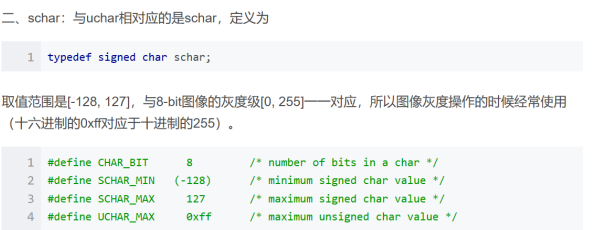
补充:schar:
(29条消息) 【OpenCV】关于Vec3b类型的含义与使用_opencv vec3b_ReturnZC的博客-CSDN博客
Vec3b:
Vec3b可以看作是vector<uchar, 3>,即一个uchar类型、长度为3的vector向量。
简单来说,Vec3b就是一个uchar类型的数组,长度为 3。
Vec3b color; //变量 color 是一个长度为 3 的 uchar 数组,用于描述 RGB 颜色
//在 OpenCV 中,颜色为 BGR,而不是 RGB
color[0] = 255; // 0 是 B 通道,该句修改 B 通道数据
color[1] = 255; // 1 是 G 通道,该句修改 G 通道数据
color[2] = 255; // 2 是 R 通道,该句修改 R 通道数据
读取像素值
mat::at()
详情写在图像读取与保存---Mat中了,
由于在OpenCV中,使用imread读取到的Mat图像数据,都是用uchar类型的数据存储,对于RGB三通道的图像,每个点的数据都是一个Vec3b类型的数据。
使用at定位方法如下:
Mat mat = imread("test.jpg");
//(row, col)即所需要定位点的坐标
mat.at<Vec3b>(row, col)[0] = 255; //修改点 (row, col) 的 B 通道数据
mat.at<Vec3b>(row, col)[1] = 255; //修改点 (row, col) 的 G 通道数据
mat.at<Vec3b>(row, col)[2] = 255; //修改点 (row, col) 的 R 通道数据
再如下例,返回值为<>中的类型:
Mat mat;
mat.at<uchar>(row, col); //单通道,返回一个 uchar 类型值
mat.at<Vec3b>(row, col); //三通道,返回 <Vec3b>,即返回一个 uchar 数组,长度为 3
mat.at<Vec4b>(row, col); //四通道
需要注意的是,上例中返回的都是uchar类型,直接使用cout输出为字符格式,需要强制转换为int类型之后输出:
Vec3b bgr = frame.at<Vec3b>(i, j);
printf("b = %d, g = %d, r = %d\n", bgr[0], bgr[1], bgr[2]);
//或
cout << (int)bgr[0] << ", " << (int)bgr.val[1] << ", " << (int)bgr.val[2] << endl;
读取摄像头中的一帧,并将其每个像素点的值打印
#include "opencv2/core.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/highgui.hpp"
#include <iostream>
using namespace cv;
using namespace std;
int main()
{
VideoCapture capture;
capture.open(0); //读入默认摄像头
if (!capture.isOpened()) {
cout << "video not open.\n";
return -1;
}
Mat frame;
capture >> frame; //读一帧
imshow("video",frame);
waitKey(0);
//destroyAllWindows(); //这个地方不销毁的话,输出BGR可能稍微慢些
if (frame.empty()) {
cout << "get frame error.\n";
return -1;
}
//遍历该图像每一个像素,并输出 BGR 值
for (int i = 0; i < frame.rows; i++) {
for (int j = 0; j < frame.cols; j++) {
Vec3b bgr = frame.at<Vec3b>(i, j); //坐标为(i,j)的像素点
printf("b = %d, g = %d, r = %d\n", bgr[0], bgr[1], bgr[2]);
}
}
return 0;
}
TrackBar滚动条操作演示-调整图像亮度
int createTrackbar(const String& trackbarname, const String& winname,
int* value, int count,
TrackbarCallback onChange = 0,
void* userdata = 0);
参数1:滑动条轨迹名;
参数2:滑动条依附的窗口名; 注意这个参数,绑定窗口名称一定要和前面创建窗口名称一样,否则不显示VBar
参数3:滑块的位置,创建时,滑块初始位置就是这个变量当前的值;
参数4:轨迹的最大值;
参数5:回调函数;
参数6:默认0,用户传给回调函数的数据,如果第三个值为全局变量,忽略这个值.;如果使用第6个参数,则作为参数传给回调函数的usrdata。
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace cv;
using namespace std;
Mat dst,m,src;
int lightness = 50;
static void on_track(int , void *)
{
dst = Scalar(lightness,lightness,lightness);
add(dst,src,m);
//m = dst + src;
imshow("亮度调整",m);
}
int main()
{
src = imread("./../img/a9c5750678b49fb41656e6e3c1d9be91--799476803.jpg",IMREAD_COLOR);
namedWindow("亮度调整",WINDOW_NORMAL);
namedWindow("input",WINDOW_NORMAL);
if(src.empty())
{
printf("could not load image\n");
}
dst = Mat::zeros(src.size(),src.type());
m = Mat::zeros(src.size(),src.type());
int max_value = 100;
imshow("input",src);
on_track(50,0);
createTrackbar("Value Bar:","亮度调整",&lightness,max_value,on_track);
waitKey(0);
destroyAllWindows();
return 0;
}
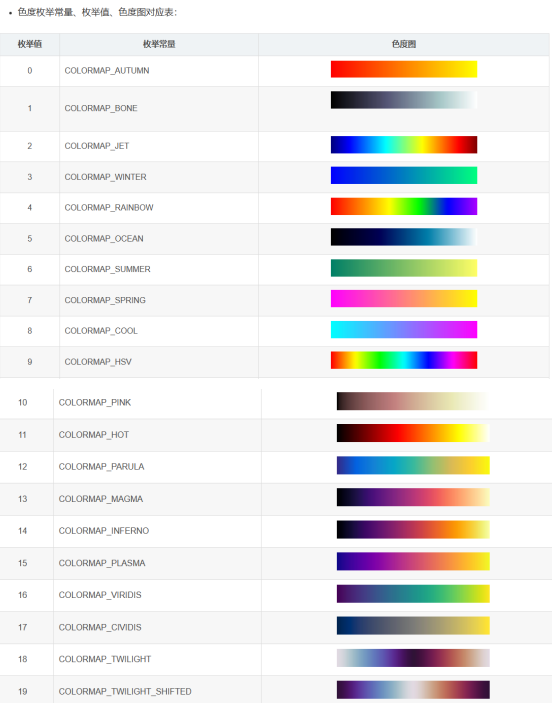
applyColorMap()函数
伪色彩函数:applyColorMap()
在OpenCV库中,常见的伪色彩模式可以通过 applyColorMap(InputArray src, OutputArray dst, int colormap)直接调用。
函数说明
-
applyColorMap(InputArray src, OutputArray dst, int colormap) // src输入图像 dst输出图像 colormap提供的色彩图代码值(参见:ColormapTypes 枚举数据类型)枚举类型: //! GNU Octave/MATLAB equivalent colormaps enum ColormapTypes { COLORMAP_AUTUMN = 0, //!<  COLORMAP_BONE = 1, //!<  COLORMAP_JET = 2, //!<  COLORMAP_WINTER = 3, //!<  COLORMAP_RAINBOW = 4, //!<  COLORMAP_OCEAN = 5, //!<  COLORMAP_SUMMER = 6, //!<  COLORMAP_SPRING = 7, //!<  COLORMAP_COOL = 8, //!<  COLORMAP_HSV = 9, //!<  COLORMAP_PINK = 10, //!<  COLORMAP_HOT = 11, //!<  COLORMAP_PARULA = 12, //!<  COLORMAP_MAGMA = 13, //!<  COLORMAP_INFERNO = 14, //!<  COLORMAP_PLASMA = 15, //!<  COLORMAP_VIRIDIS = 16, //!<  COLORMAP_CIVIDIS = 17, //!<  COLORMAP_TWILIGHT = 18, //!<  COLORMAP_TWILIGHT_SHIFTED = 19 //!<  };如图:
VideoCapture类基础知识
(39条消息) opencv学习---VideoCapture 类基础知识_hairuiJY的博客-CSDN博客
-
关于视频的读:videocapture
-
关于视频的写:videowriter
VideoCapture既支持从视频文件(.avi , .mpg格式)读取,也支持直接从摄像机(比如电脑自带摄像头)中读取。要想获取视频需要先创建一个VideoCapture对象
VideoCapture是个类,用来生成个对象
VideoCapture a;
//从文件中读取视频
方法: cv::VideoCapture capture(const string& filename); // 从视频文件读取
例程: cv::VideoCapture capture("C:/Users/DADA/DATA/gogo.avi"); // 从视频文件读取
这种情况下,我们会给出一个标识符,用于表示我们想要访问的摄像机,及其与操作系统的握手方式。对于摄像机而言,这个标志符就是一个标志数字——如果只有1个摄像机,那么就是0,如果系统中有多个摄像机,那么只要将其向上增加即可。标识符另外一部分是摄像机域(camera domain),用于表示摄像机的类型,这个域值可以是下面任一预定义常量。
//从摄像头读
cv::VideoCapture capture(int device ); //视频捕捉设备 id ---笔记本电脑的用0表示

方法3:先创建个捕获对象,通过open()函数来打开设定信息
cv::VideoCapture VideoCapture; 这里的第二个VideoCapture是一个对象名
VideoCapture.open( "C:/Users/DADA/DATA/gogo.avi" );
将视频帧读取到cv::Mat矩阵中,有两种方式:一种是read()操作;另一种是 “>>” 操作。
cv::Mat frame;
cap.read(frame); //读取方式一
cap >> frame; //读取方式二
案例已经写过:
#include "opencv2/core.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/highgui.hpp"
#include <iostream>
using namespace cv;
using namespace std;
int main()
{
VideoCapture capture;
capture.open(0); //读入默认摄像头
if (!capture.isOpened()) {
cout << "video not open.\n";
return -1;
}
Mat frame;
capture >> frame; //读一帧
imshow("video",frame);
waitKey(0);
//destroyAllWindows(); //这个地方不销毁的话,输出BGR可能稍微慢些
if (frame.empty()) {
cout << "get frame error.\n";
return -1;
}
//遍历该图像每一个像素,并输出 BGR 值
for (int i = 0; i < frame.rows; i++) {
for (int j = 0; j < frame.cols; j++) {
Vec3b bgr = frame.at<Vec3b>(i, j); //坐标为(i,j)的像素点
printf("b = %d, g = %d, r = %d\n", bgr[0], bgr[1], bgr[2]);
}
}
return 0;
}
初始化时:
(1)先实例化再初始化:
VideoCapture capture;
capture.open("dog.avi");
(2)在实例化的同时进行初始化:
VideoCapture("dog.avi");
3.VideoCapture::isOpened
C++: bool VideoCapture::isOpened()
功能:判断视频读取或者摄像头调用是否成功,成功则返回true。
4.VideoCapture::release
C++: void VideoCapture::release()
功能:关闭视频文件或者摄像头。
5.VideoCapture::grab
C++: bool VideoCapture::grab()
功能:从视频文件或捕获设备中抓取下一个帧,假如调用成功返回true。(细节请参考opencv文档说明)
6.VideoCapture::retrieve
C++: bool VideoCapture::retrieve(Mat& image, int channel=0)
功能:解码并且返回刚刚抓取的视频帧,假如没有视频帧被捕获(相机没有连接或者视频文件中没有更多的帧)将返回false。
7.VideoCapture::read
C++: VideoCapture& VideoCapture::operator>>(Mat& image)
C++: bool VideoCapture::read(Mat& image)
功能:该函数结合VideoCapture::grab()和VideoCapture::retrieve()其中之一被调用,用于捕获、解码和返回下一个视频帧这是一个最方便的函数对于读取视频文件或者捕获数据从解码和返回刚刚捕获的帧,假如没有视频帧被捕获(相机没有连接或者视频文件中没有更多的帧)将返回false。
从上面的API中我们会发现获取视频帧可以有多种方法 :
// 方法一
capture.read(frame);
// 方法二
capture.grab();
// 方法三
capture.retrieve(frame);
// 方法四
capture >> frame;
*8.VideoCapture::get*
C++: double VideoCapture::get(int propId)
功能:一个视频有很多属性,比如:帧率、总帧数、尺寸、格式等,VideoCapture的get方法可以获取这些属性。
参数:属性的ID。
//eg
VideoCapture capture
capture.get(15);
9.VideoCapture::set
设置属性
(39条消息) cv2.VideoCapture.get、set详解_cv2.videocapture.set_液压姬的博客-CSDN博客
VideoWriter
(39条消息) C++ opencv之视频读写(VideoCapture,VideoWriter)_c++ opencv 读取视频_阿超没有蛀牙的博客-CSDN博客
作用:视频写出、文件保存
函数原型:
VideoWriter video_writer;
video_writer.open(const string& filename, int fourcc, double fps,Size frameSize, bool isColor=true);
-
filename:保存的文件名及路径
-
fourcc:表示压缩帧的codec,一般用CV_FOURCC(‘M’,‘J’,‘P’,‘G’) = motion-jpeg codec;
-
fps:表示帧率,每秒帧数 可用video_writer.get(CV_CAP_PROP_FPS);
-
frameSize:保存的视频大小;
-
isColor:如果非零,编 码器将希望得到彩色帧并进行编码;否则,是灰度帧(只有在Windows下支持这个标志)。
#include <opencv2/core.hpp>
#include <opencv2/videoio.hpp>
#include <opencv2/highgui.hpp>
#include <iostream>
#include <stdio.h>
using namespace cv;
using namespace std;
int main(int, char**)
{
Mat src;
// use default camera as video source
VideoCapture cap(0);
// check if we succeeded
if (!cap.isOpened()) {
cerr << "ERROR! Unable to open camera\n";
return -1;
}
// get one frame from camera to know frame size and type
cap >src;
// check if we succeeded
if (src.empty()) {
cerr << "ERROR! blank frame grabbed\n";
return -1;
}
bool isColor = (src.type() == CV_8UC3);
//--- INITIALIZE VIDEOWRITER
VideoWriter writer;
int codec = VideoWriter::fourcc('M', 'J', 'P', 'G'); // select desired codec (must be available at runtime)
double fps = 25.0; // framerate of the created video stream
string filename = "./live.avi"; // name of the output video file
writer.open(filename, codec, fps, src.size(), isColor);
// check if we succeeded
if (!writer.isOpened()) {
cerr << "Could not open the output video file for write\n";
return -1;
}
//--- GRAB AND WRITE LOOP
cout << "Writing videofile: " << filename << endl
<< "Press any key to terminate" << endl;
for (;;)
{
// check if we succeeded
if (!cap.read(src)) {
cerr << "ERROR! blank frame grabbed\n";
break;
}
// encode the frame into the videofile stream
writer.write(src);
// show live and wait for a key with timeout long enough to show images
imshow("Live", src);
if (waitKey(5) >= 0)
break;
}
// the videofile will be closed and released automatically in VideoWriter destructor
return 0;
}
waitKey()----等待按键事件
int cv::waitKey ( int delay = 0 ) //用完之后返回int型
- waitKey函数属于cv命名空间
- 一个int类型的参数,默认值为0,根据delay的名称可以猜测参数值是一个延时值
- 函数返回值为int类型
waitKey函数是一个等待键盘事件的函数,参数值delay<=0时等待时间无限长,delay为正整数n时至少等待n毫秒的时间才结束。在等待的期间按下任意按键时函数结束,返回按键的键值(ascii码),等待时间结束仍未按下按键则返回-1。该函数用在处理HighGUI窗口程序,最常见的便是与显示图像窗口imshow函数搭配使用
opencv学习之等待按键事件-waitKey函数 - 芒果浩明 - 博客园 (cnblogs.com)
图像二值化--threshold函数
图像的二值化就是将图像上的像素点的灰值设置为0或者255,这样使得整个图像呈现出黑白的效果。在数字图像处理中,二值图像占有非常重要的地位,图像的二值化使图像中数据量大为减少,从而能凸显出目标的轮廓。
函数原型:

src dst: 输入图像,输出图像
thresh:阈值:当图像对应灰度图某个像素点灰值大于该值时设置为maxval,小于该值时为0;
maxval:就是大于阈值时的灰度
type:阈值类型:
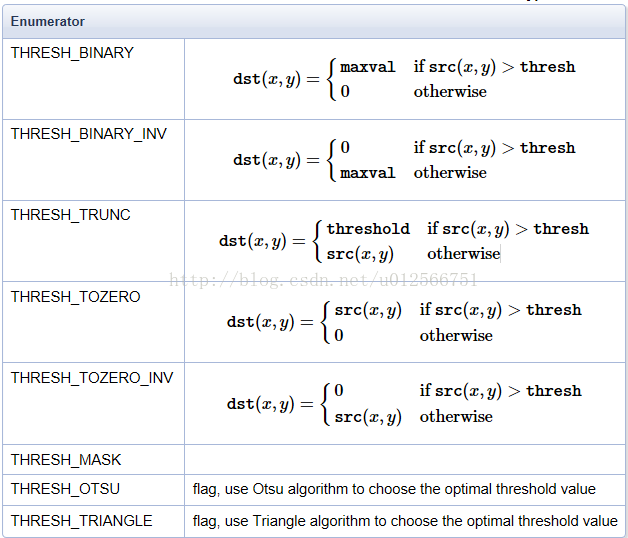
Mat gray;
cvtColor(src, gray, CV_BGR2GRAY); //先利用cvtColor化为灰色图
// 全局二值化
int th = 100;
cv::Mat threshold1,threshold2,threshold3,threshold4,threshold5,threshold6,threshold7,threshold8;
cv::threshold(gray, threshold1, th, 255, THRESH_BINARY);
cv::threshold(gray, threshold2, th, 255, THRESH_BINARY_INV);
cv::threshold(gray, threshold3, th, 255, THRESH_TRUNC);
cv::threshold(gray, threshold4, th, 255, THRESH_TOZERO);
cv::threshold(gray, threshold5, th, 255, THRESH_TOZERO_INV);
//cv::threshold(gray, threshold6, th, 255, THRESH_MASK);
cv::threshold(gray, threshold7, th, 255, THRESH_OTSU);
cv::threshold(gray, threshold8, th, 255, THRESH_TRIANGLE);
cv::imshow("THRESH_BINARY", threshold1);
cv::imshow("THRESH_BINARY_INV", threshold2);
cv::imshow("THRESH_TRUNC", threshold3);
cv::imshow("THRESH_TOZERO", threshold4);
cv::imshow("THRESH_TOZERO_INV", threshold5);
//cv::imshow("THRESH_MASK", threshold6);
cv::imshow("THRESH_OTSU", threshold7);
cv::imshow("THRESH_TRIANGLE", threshold8);
cv::waitKey(0);

通道分离--split()
对于彩色图像,可以将让他的多个图像通道分离出来
通道分离可以用于彩色图像的处理,图像对象可以是普通的3通道BGR彩色图像,分离后分别为b、g、r的3个通道。如果是带alpha通道的BGRA 4通道图像,分离后分别为b、g、r、a。如果图像是其他色彩空间的图像比如HSV图像,分离后的3个图像则分别为h、s、v。
python:
//python:利用b,g,r三个变量将通道存储起来\
imread(genshit) //伪代码
Mat b,g,r = split(genshint)
if img is not None and len(img.shape)==3: #彩色图像才可以做通道分离
print('img.shape:',img.shape)
show_img('img',img,-1)
if img.shape[2] == 3: #如果是3通道,分离出3个图像实例
b,g,r = cv2.split(img)
show_img('b',b,-1)
show_img('g',g,-1)
show_img('r',r,-1)
cv2.waitKey(0)
elif img.shape[2] == 4: #如果是4通道
b,g,r,a = cv2.split(img)
show_img('b',b,-1)
show_img('g',g,-1)
show_img('r',r,-1)
show_img('a',a,-1)
cv2.waitKey(0)
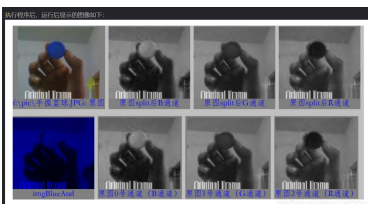
c++:
Mat test = imread("C:/Users/Tan/Pictures/9f281e856584d50c19cfbeb8fe5eeda3b595ab67.jpg",1);
Mat tst[3];
split(test,tst);
//解释:假设有个数组d[12] = {1,2,3,4,5,6,7,8,9,10,11,12}
那么 split(test,tst);
tst[0] =
[ 1, 4;
7, 10]
tst[1] =
[ 2, 5;
8, 11]
tst[2] =
[ 3, 6;
9, 12]
//发现规律了吗,就是 b[1],g[1],r[1],b[2],g[2],r[2].....这样存储
//eg
#include<iostream>
#include<opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main(){
Mat test = imread("C:/Users/Tan/Pictures/9f281e856584d50c19cfbeb8fe5eeda3b595ab67.jpg",-1);
Mat tst[3];
split(test,tst);
imshow("win1",tst[0]); //三张图还真不一样
imshow("win2",tst[1]);
imshow("win3",tst[2]);
waitKey(0);
destroyAllWindows();
return 0;
}
通道合并:merge()
将通道合并
- Mat用法:
void merge(const Mat* m,size_t size,OutArrayput); // 第一个参数是图像矩阵数组,第二个参数是需要合并矩阵的个数,第三个参数是输出
-
vector 用法:
void merge(const vector &m,outputarray); //该种为vector函数里的,算法常用 //第一个参数是图像矩阵向量容器,第二个参数是输出,这种方法无需说明需要合并的矩阵个数,[vector]对象自带说明
实例:
std::vector<Mat> channels;
Mat aChannels[3];
split(src, channels); //分离到数组
split(src, aChannels); //分离到vector对象
//do something
//xxxx
merge(channels, mergeImg);
merge(aChannels, 3, mergeImg);
图像通道混合---mixchannel()
用法
void cv::mixChannels (
InputArrayOfArrays src, //输入图像
size_t nsrcs; //输入矩阵的个数,不写默认缺省1也可以
InputOutputArrayOfArrays dst, //输出图像
size_t ndsts; //输出矩阵的个数,不写默认为1
const std::vector< int > & fromTo //复制列表,表示第输入矩阵的第几个通道复制到输出矩阵的第几个通道
)
接下来是对于fromTo的解释:
对于通道复制: ==将原来某个图像的g,b,r之一颜色改变为另一个颜色
例如:{0,2,1,1,2,0}表示:
- src 的颜色通道0复制到 dst 颜色通道2
- src 的颜色通道1 复制到 dst颜色通道2
- src 的颜色通道2 复制到 dst颜色通道0
如图: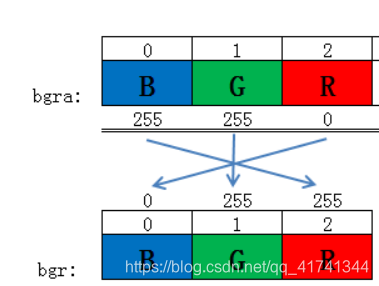
mixChannels()有多个重载,这里将他们写出来:
void mixChannels(InputArrayOfArrays src, InputOutputArrayOfArrays dst,
const std::vector<int>& fromTo);
void mixChannels(InputArrayOfArrays src, InputOutputArrayOfArrays dst,
const int* fromTo, size_t npairs);
void mixChannels(const Mat* src, size_t nsrcs, Mat* dst, size_t ndsts,
const int* fromTo, size_t npairs);
void MyDemo::channels_Demo(Mat& image) {
Mat dst = Mat::zeros(image.size(), image.type());
int ft[] = { 0,2,1,1,2,0 };//互换1、3通道
mixChannels(&image,1, &dst,1, ft,3);
imshow("Mix", dst);
}
//运行结果如下图:

我的例子:
#include<iostream>
#include<vector>
#include<opencv2/opencv.hpp>
using namespace std;
using namespace cv;
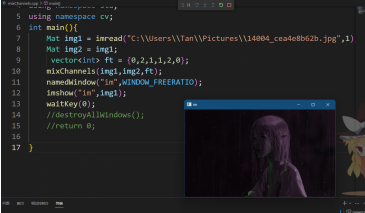
int main(){
Mat img1 = imread("C:\\Users\\Tan\\Pictures\\14004_cea4e8b62b.jpg",1);
Mat img2 = img1; //这是为了确保img2不为空图像,为空就会mixChannels上出了问题
vector<int> ft = {0,2,1,1,2,0};
mixChannels(img1,img2,ft);
namedWindow("im",WINDOW_FREERATIO);
imshow("im",img1);
waitKey(0);
destroyAllWindows();
return 0;
}
//刚刚就是 Mat img2,而不是 Mat img2 = img1,导致图像无法显示,图像通道,大小不合适
图片融合---addWeighted()
void cv::addWeighted( const CvArr* src1, //输入图像1
double alpha, //第一个图像所占权重
const CvArr* src2, //输入图像2
double beta, //第二个图像所占权重
double gamma, //gamma,图1与图2作和后添加的数值。不要太大,不然图片一片白。总和等于255以上就是纯白色了
CvArr* dst ); //dst 输出图片
实例:
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace std;
using namespace cv;
int main()
{
Mat src1,src2,dst;//创建Mat数组,等待存储图片
src1 = imread("1.jpg");
src2 = imread("2.jpg");
//将图1与图2线性混合
addWeighted(src1,0.5,src2,0.7,3,dst);
/*注释
参数分别为:图1,图1的权重,图2,图2的权重,权重和添加的值为3,输出图片src
*/
//显示图片
imshow("src1图",src1);
imshow("src2图",src2);
imshow("混合后的图片",dst);
waitKey(0);//等待按键响应后退出,0改为5000就是5秒后自动退出。
return 0;
}
图像拼接--hconcat,vconcat
-
横向拼接
void cv::hconcat ( const Mat * src, size_t nsrc, OutputArray dst )实例:
//横向拼接 void cv::hconcat ( const Mat * src, size_t nsrc, OutputArray dst ) /** @brief Applies horizontal concatenation to given matrices. 简介 将水平连接应用于给定矩阵。 The function horizontally concatenates two or more cv::Mat matrices (with the same number of rows). 该函数水平连接两个或多个cv::Mat矩阵(行数相同)。 */ cv::Mat matArray[] = { cv::Mat(4, 1, CV_8UC1, cv::Scalar(1)), cv::Mat(4, 1, CV_8UC1, cv::Scalar(2)), cv::Mat(4, 1, CV_8UC1, cv::Scalar(3)),}; //首先对这个mat类的初始化进行解释:cv::Mat(4, 1, CV_8UC1, cv::Scalar(1)), cv::Mat::Mat(int rows, //行数 int cols, //列数 int type, //种类 const Scalar & s //给矩阵中所有元素赋值,Scalar(1)就是将元素赋值为1 如果是双通道,那么就是 Scalar(1,2) :给每个像素点赋值为(1,2) ,如果是三通道,就是 Scalar(32,1,3) :给每个像素点赋值为(32,1,3) ) //cv::Mat matArray[] 创建一个mat类数组: cv::Mat out; cv::hconcat( matArray, 3, out ); //out: //[1, 2, 3; // 1, 2, 3; // 1, 2, 3; // 1, 2, 3] void cv::hconcat ( InputArray src1, InputArray src2, OutputArray dst ) /** @overload */ cv::Mat_<float> A = (cv::Mat_<float>(3, 2) << 1, 4, 2, 5, 3, 6); cv::Mat_<float> B = (cv::Mat_<float>(3, 2) << 7, 10, 8, 11, 9, 12); cv::Mat C; cv::hconcat(A, B, C); //C: //[1, 4, 7, 10; // 2, 5, 8, 11; // 3, 6, 9, 12] void cv::hconcat ( InputArrayOfArrays src, OutputArray dst ) /** @overload */ std::vector<cv::Mat> matrices = { cv::Mat(4, 1, CV_8UC1, cv::Scalar(1)), cv::Mat(4, 1, CV_8UC1, cv::Scalar(2)), cv::Mat(4, 1, CV_8UC1, cv::Scalar(3)),}; cv::Mat out; cv::hconcat( matrices, out ); //out: //[1, 2, 3; // 1, 2, 3; // 1, 2, 3; // 1, 2, 3]-
纵向拼接
//纵向拼接 void cv::vconcat ( const Mat * src, size_t nsrc, OutputArray dst ) /** @brief Applies vertical concatenation to given matrices. 简介 对给定矩阵应用垂直连接。 The function vertically concatenates two or more cv::Mat matrices (with the same number of cols). 该函数垂直连接两个或多个cv::Mat矩阵(具有相同的列数)。 */ cv::Mat matArray[] = { cv::Mat(1, 4, CV_8UC1, cv::Scalar(1)), cv::Mat(1, 4, CV_8UC1, cv::Scalar(2)), cv::Mat(1, 4, CV_8UC1, cv::Scalar(3)),}; cv::Mat out; cv::vconcat( matArray, 3, out ); //out: //[1, 1, 1, 1; // 2, 2, 2, 2; // 3, 3, 3, 3] /* @param src input array or vector of matrices. all of the matrices must have the same number of cols and the same depth. @param nsrc number of matrices in src. @param dst output array. It has the same number of cols and depth as the src, and the sum of rows of the src. @sa cv::hconcat(const Mat*, size_t, OutputArray), @sa cv::hconcat(InputArrayOfArrays, OutputArray) and @sa cv::hconcat(InputArray, InputArray, OutputArray) */ void cv::vconcat ( InputArray src1, InputArray src2, OutputArray dst ) /** @overload */ cv::Mat_<float> A = (cv::Mat_<float>(3, 2) << 1, 7, 2, 8, 3, 9); cv::Mat_<float> B = (cv::Mat_<float>(3, 2) << 4, 10, 5, 11, 6, 12); cv::Mat C; cv::vconcat(A, B, C); //C: //[1, 7; // 2, 8; // 3, 9; // 4, 10; // 5, 11; // 6, 12] /* @param src1 first input array to be considered for vertical concatenation. @param src2 second input array to be considered for vertical concatenation. @param dst output array. It has the same number of cols and depth as the src1 and src2, and the sum of rows of the src1 and src2. */ void cv::vconcat ( InputArrayOfArrays src, OutputArray dst ) /** @overload */ std::vector<cv::Mat> matrices = { cv::Mat(1, 4, CV_8UC1, cv::Scalar(1)), cv::Mat(1, 4, CV_8UC1, cv::Scalar(2)), cv::Mat(1, 4, CV_8UC1, cv::Scalar(3)),}; cv::Mat out; cv::vconcat( matrices, out ); //out: //[1, 1, 1, 1; // 2, 2, 2, 2; // 3, 3, 3, 3] /* @param src input array or vector of matrices. all of the matrices must have the same number of cols and the same depth @param dst output array. It has the same number of cols and depth as the src, and the sum of rows of the src. same depth. */
-
图片缩放 resize()
void cv::resize ( InputArray src,
OutputArray dst,
Size dsize,
double fx = 0,
double fy = 0,
int interpolation = INTER_LINEAR
)
其中src表示原始图像,dsize表示缩放大小,fx和fy也可以表示缩放大小倍数,他们两个(dsize或fx\fy)设置一个即可实现图像缩放
src - 原图
dst - 目标图像。当参数dsize不为0时,dst的大小为size;否则,它的大小需要根据src的大小,参数fx和fy决定。dst的类型(type)和src图像相同
dsize - 目标图像大小。当dsize为0时,它可以通过以下公式计算得出:
所以,参数dsize和参数(fx, fy)不能够同时为0
fx - 水平轴上的比例因子。当它为0时,计算公式如下:
fy - 垂直轴上的比例因子。当它为0时,计算公式如下:
interpolation - 插值方法。共有5种:
INTER_NEAREST - 最近邻插值法
INTER_LINEAR - 双线性插值法(默认)
INTER_AREA - 基于局部像素的重采样(resampling using pixel area relation)。对于图像抽取也叫缩小图像(image decimation)来说,这可能是一个更好的方法。但如果是放大图像时,它和最近邻法的效果类似。
INTER_CUBIC - 基于4x4像素邻域的3次插值法
INTER_LANCZOS4 - 基于8x8像素邻域的Lanczos插值缩小图像 用INTER_AREA更好,放大图像用 INTER_CUBIC更好
滤波
(40条消息) OpenCV(十一)图像滤波(平滑处理)(平均、中值、高斯、双边滤波)opencv图像滤波_(▽)_的博客-CSDN博客
图像滤波增强处理本质实质上就是利用滤波技术来增强图像某些空间频率特征,以改善地物目标与邻域或者背景之间的灰度反差,遥感系统成像过程中可能产生的”模糊”作用,常使遥感图像上某些用户感兴趣的线性形迹、纹理与地物边界等信息显示得不够清晰,不易识别。遥感系统成像过程中可能产生的”模糊”作用,常使遥感图像上某些用户感兴趣的线性形迹、纹理与地物边界等信息显示得不够清晰,不易识别
图像噪声
由于图像采集、处理、传输等过程不可避免的会受到噪声的污染,妨碍人们对图像理解及分析处理。常见的图像噪声有高斯噪声、椒盐噪声等。
椒盐噪声
椒盐噪声也称为脉冲噪声,是图像中经常见到的一种噪声,它是一种随机出现的白点或者黑点,可能是亮的区域有黑色像素或是在暗的区域有白色像素(或是两者皆有)。椒盐噪声的成因可能是影像讯号受到突如其来的强烈干扰而产生、类比数位转换器或位元传输错误等
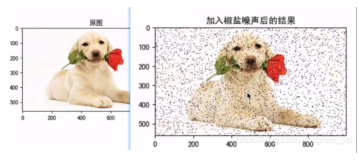
高斯噪声
高斯噪声是指噪声密度函数*服从高斯分布*的一类噪声。由于高斯噪声在空间和频域中数学上的易处理性,这种噪声(也称为正态噪声)模型经常被用于实践中。高斯随机变量z的概率密度函数公式: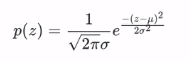

高斯噪声:服从正态分布
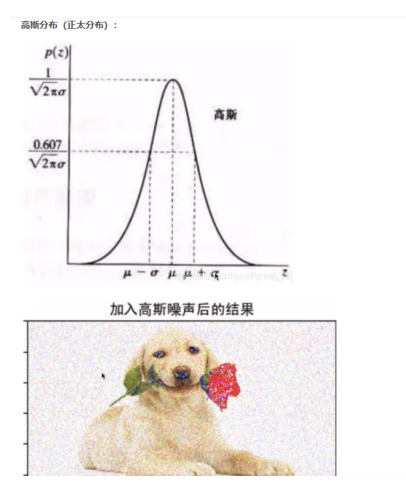
滤波介绍:
“平滑”(滤波)通常又称“模糊”,是一种简单常用的图像处理操作。进行平滑处理的原因有很多,但通常是用来去除噪声和相机失真,平滑在按照一定的原理来降低图像分辨率中也有重要应用。
根据空间滤波增强目的可分为:平滑滤波和锐化滤波;
根据空间滤波的特点可分为:线性滤波和非线性滤波。
(1)平滑滤波,能减弱或消除图像中的高频分量,但不影响低频分量。因为高频分量对应图像中的区域边缘等灰度值具有较大、较快变化的部分,平滑滤波将这些分量绿区可减少局部灰度的起伏,使图像变得比较平滑。实际应用中,平滑滤波即可以用来消除噪声,又可以用在提取较大的目标前过滤去除较小的细节或将目标内的小间断连接起来。
(2)锐化滤波,能减弱或消除图像中的低频分量,但不影响高频分量。因为低频分量对应图像中灰度值缓慢变化的区域,因而与图像的整体特性如整体对比度和平均灰度值等有关。锐化滤波将这些分量滤去可使图像反差增加,边缘明显。实际应用中,锐化滤波可用于增强图像中被模糊的细节或景物的边缘。
(1)线性滤波:运算只是对各像素灰度值进行简单处理(如乘一个权值)最后求和。
(2)非线性滤波:如果对像素灰度值的复杂运算,而不是最后求和的简单运算
线性滤波
常见的线性滤波器:
(1)低通滤波器:允许低频率通过;
(2)高通滤波器:允许高频率通过;
(3)带通滤波器 :允许一定区域的频率通过;
(4)带阻滤波器 :阻止一定范围内的频率并且允许其他频率通过;
(5)全通滤波器 :允许所有频率通过,仅仅改变相位;
(6)陷波滤波器(Band stop filter):阻止一个狭窄频率范围通过的特殊带阻滤波器。
方框滤波–> boxblur函数来实现 –> 线性滤波
均值滤波–> blur函数 –> 线性滤波
高斯滤波–> GaussianBlur函数 –> 线性滤波
中值滤波–> medianBlur函数 –> 非线性滤波
双边滤波–> bilateralFilter函数 –> 非线性滤波
线性滤波原理:
线性邻域滤波是一种常用的邻域算子,利用给定像素周围的像素值决定此点的像素值的一种算子,具体如下:
邻域算子(局部算子)是利用给定像素周围的像素值的决定此像素的最终输出值的一种算子。而线性邻域滤波是一种常用的邻域算子,像素的输出值取决于输入像素的加权和,具体过程如下图。
假设有6x6的图像像素点矩阵。卷积过程:6x6上面是个3x3的窗口,从左向右,从上向下移动,黄色的每个像个像素点值之和取平均值赋给中心红色像素作为它卷积处理之后新的像素值。每次移动一个像素格。

平滑(smoothing)/模糊(bluring)的数学理论幕后黑手——卷积:
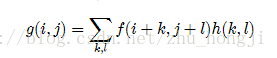
线性滤波处理的输出像素值g(i,j)也就是上面的红心的值(锚点),是输入图像f(i+k,j+l)的加权和。h(k,l)是核,也是窗口大小;
均值滤波(blur()) (简单滤波)
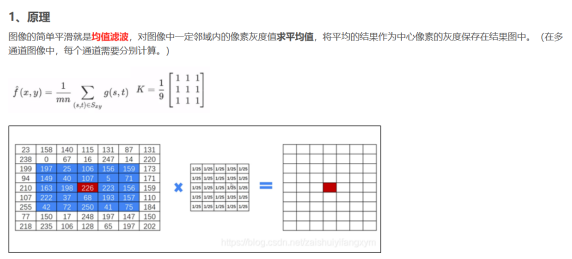
定义:
void cv::blur(
cv::InputArray src, // 输入图像
cv::OutputArray dst, // 输出图像
cv::Size ksize, // 核大小 注意上文解释: h(k,l)是核,也是窗口大小;
cv::Point anchor = cv::Point(-1,-1), // 锚点位置 ----就是上图中的红点
int borderType = cv::BORDER_DEFAULT // 边界处理方法
);
c++
blur(src, dst, Size(9, 9), Point(-1, -1)); //均值滤波
中值滤波 ----medianBlur()
作用: 适合去除椒盐噪声
所谓中值,就是在中心像素点的矩形邻域内取中值来替代中心像素。
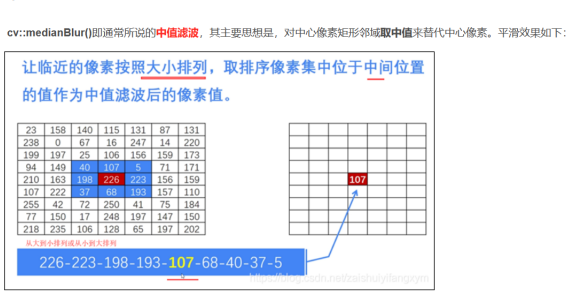
将邻域内八个元素排列起来,取中值
void cv::medianBlur(
cv::InputArray src, // 输入图像
cv::OutputArray dst, // 输出图像
cv::Size ksize // 核大小
);
medianBlur(src, dst, 9); //中值滤波
高斯滤波---GaussianBlur()
原理:根据周边矩形邻域距中心像素点的位置不同,赋予不同的权重,根据权重进行计算,最终得到中心图像的值
作用:
适合处理高斯噪声。(往中心集中的那种)原理:
让临近像素具有更高的权重,起到模糊的效果 。cv::GaussianBlur()即高斯滤波,是最常用的一种滤波方式。其主要思想是,使用高斯核与输入图像中的每个点作卷积运算,然后对卷积结果进行求和,从而得到输出图像。
在图像高斯平滑中,对图像进行平均时,不同位置的像素被赋予了不同的权重。高斯平滑与简单平滑不同,它在对邻域内像素进行平均时,给予不同位置的像素不同的权值。

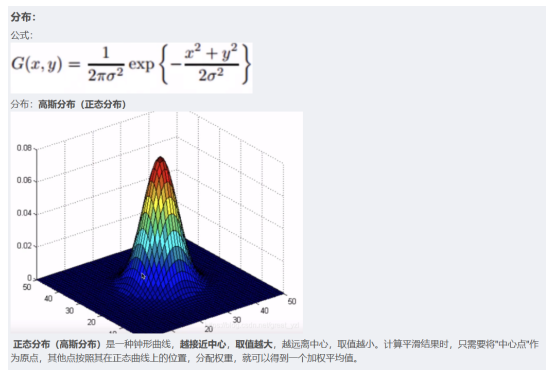
定义:
void cv::GaussianBlur(
cv::InputArray src, // 输入图像
cv::OutputArray dst, // 输出图像
cv::Size ksize, // 核大小
double sigmaX, // x方向高斯半宽
double sigmaY = 0.0, // y方向高斯半宽
int borderType = cv::BORDER_DEFAULT // 边界处理方法
);
GaussianBlur(src, dst, Size(9, 9), 0); //高斯滤波
(42条消息) opencv之GaussianBlur()函数_cv.gaussianblur_duwangthefirst的博客-CSDN博客
双边滤波--- bilateralFilter()
cv::bilateralFilter(),即双边滤波,是一种可以保持图像边缘的平滑方法。和高斯滤波类似,双边滤波也是通过计算中像素和邻域像素的加权平均所实现的,只是其权值由两部分组成。其中,第一部分与高斯平滑的权值相同;第二部分也是高斯权值,但是该权值并不是基于中心像素的空间距离,而是基于和中心像素点的灰度值的差异。
- 使用原因:
高斯滤波去降噪,会较明显地模糊边缘,对于高频细节的保护效果并不明显。
void cv::bilateralFilter ( InputArray src,
OutputArray dst,
int d, //int类型的d,表示在过滤过程中每个像素邻域的直径。如果这个值我们设其为非正数,那么OpenCV会从第五个参数sigmaSpace来计算出它来。
double sigmaColor,//double类型的sigmaColor,颜色空间滤波器的sigma值。这个参数的值越大,就表明该像素邻域内有更宽广的颜色会被混合到一起,产生较大的半相等颜色区域。
double sigmaSpace, //double类型的sigmaSpace坐标空间中滤波器的sigma值,坐标空间的标注方差。他的数值越大,意味着越远的像素会相互影响,从而使更大的区域足够相似的颜色获取相同的颜色。当d>0,d指定了邻域大小且与sigmaSpace无关。否则,d正比于sigmaSpace。
int borderType = BORDER_DEFAULT // 用于推断图像外部像素的某种边界模式。注意它有默认值BORDER_DEFAULT。
)
OpenCV 学习:9 双边滤波bilateralFilter - 知乎 (zhihu.com)
腐蚀与膨胀
所谓腐蚀与膨胀,是对图像选定部分进行“增肥”与“减肥”
膨胀与腐蚀属于形态学范围,具体的含义根据字面意思来理解即可。但是更形象的话就是“增肥”与“减肥”。
它们的用途就是用来处理图形问题上。总结性的来说: + 膨胀用来处理缺陷问题; + 腐蚀用来处理毛刺问题。
膨胀就是把缺陷给填补了,腐蚀就是把毛刺给腐蚀掉了。这里其实说的并不严谨,也是为了大家理解方便。下面我们就用实例来进行演示。
如图:
膨胀

腐蚀

接下来开始具体讲解
首先导入图片:

膨胀
对于一个像素点,先指定每个像素点的膨胀范围,这里指定范围为3*3矩阵, kernel(卷积核核)指定为全为1的3 * 3矩阵,卷积计算后,该像素点的值等于以该像素点为中心的3 * 3范围内的最大值,由于我们是二值图像,所以只要包含周围白的部分,就变为白的。

- 更改卷积核大小

- 更改迭代次数
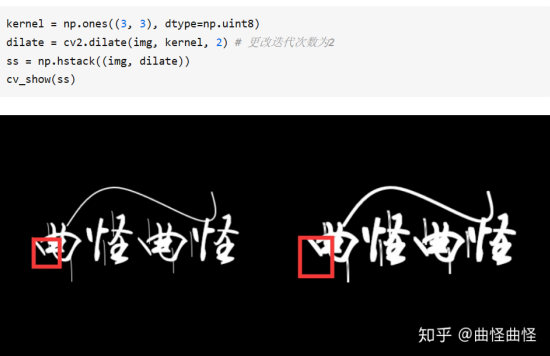
两次膨胀操作
void cv::dilate(InputArray src,
OutputArray dst,
InputArray kernel,
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_CONSTANT,
const Scalar & borderValue = morphologyDefaultBorderValue()
)
-
src:输入的待膨胀图像,图像的通道数可以是任意的,但是图像的数据类型必须是CV_8U,CV_16U,CV_16S,CV_32F或CV_64F之一。
-
dst:膨胀后的输出图像,与输入图像src具有相同的尺寸和数据类型。
-
kernel:用于膨胀操作的结构元素,可以自己定义,也可以用getStructuringElement()函数生成。
解释:getgetStructuringElement()是用
getStructuringElement(int shape,size ksize,point anchor) //用于生成卷积核 -shape(形状)(MORPH_REACT\MORPH_CROSS\MORPH_ELLIPSE) -size(大小) -point(锚点) 默认是point(-1,-1)意思就是中心像素 dilate(src,dst,kernel) 膨胀 erode(src,dst,kernel) 腐蚀
腐蚀
与膨胀操作相反,膨胀是放大,腐蚀就是缩小,将毛刺消除
在卷积核大小中对图片进行卷积。取图像中(3 * 3)区域内的最小值。由于我们是二值图像,也就是取0(黑色)。 总结: 只要原图片3 * 3范围内有黑的,该像素点就是黑的。

同样有
- 更改卷积核大小

-
更改迭代次数

morphologyEx---形态学操作函数
void cv::morphologyEx ( InputArray src,
OutputArray dst,
int op,
InputArray kernel,
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_CONSTANT,
const Scalar & borderValue = morphologyDefaultBorderValue()
)
解释:
- op :形态学处理的类型:
MORPH_ERODE = 0:腐蚀处理
MORPH_DILATE = 1:膨胀处理
MORPH_OPEN = 2:开运算处理
MORPH_CLOSE = 3:闭运算处理
MORPH_GRADIENT = 4:形态学梯度
MORPH_TOPHAT = 5:顶帽变换
MORPH_BLACKHAT = 6:黑帽变换
MORPH_HITMISS = 7 :击中-击不中变换
-
InputArray kernel:结构元矩阵
-
Point anchor:结构元中心,默认值为(-1,-1),表示正中心
-
int iteration: 腐蚀膨胀处理次数,默认为1,如果是开运算或者闭运算,次数表示先膨胀或腐蚀几次,再腐蚀或膨胀几次,而不是开运算闭运算几次
-
(7)参数7:int borderType = BORDER_CONSTANT
图像边框插值类型,默认类型为固定值填充
BORDER_CONSTANT = 0:固定值 i 填充:iiiiii | abcdefgh | iiiiiii
BORDER_REPLICATE = 1:两端复制:aaaaaa | abcdefgh | hhhhhhh
BORDER_REFLECT = 2:镜像复制:fedcba | abcdefgh | hgfedcb
BORDER_WRAP = 3:去除一端的值然后复制: cdefgh | abcdefgh | abcdefg
BORDER_REFLECT_101 = 4:去除一端的值然后镜像复制: gfedcb|abcdefgh|gfedcba
BORDER_TRANSPARENT = 5:推导赋值 uvwxyz | abcdefgh | ijklmno
BORDER_REFLECT101 = BORDER_REFLECT_101: same as BORDER_REFLECT_101
BORDER_DEFAULT = BORDER_REFLECT_101: same as BORDER_REFLECT_101
BORDER_ISOLATED = 16:< do not look outside of RO
这个博客是对开运算,闭运算,形态学梯度,顶帽运算的详细解释
[(41条消息) opencv —— morphology形态学操作函数讲解(python)_opencv morphology_岁月蹉跎的一杯酒的博客-CSDN博客](https://blog.csdn.net/weixin_44690935/article/details/108998692)
这个也是直观的图片展示:
计算机视觉基础之形态学操作——cv2.morphologyEx - 知乎 (zhihu.com)
霍夫运算
霍夫圆
void cv::HoughCircles ( InputArray image,
OutputArray circles,
int method,
double dp,
double minDist,
double param1 = 100,
double param2 = 100,
int minRadius = 0,
int maxRadius = 0
)
简介 使用Hough变换在灰度图像中查找圆
注:该功能通常能很好地检测圆的中心。但是,它可能无法找到正确的半径。如果您知道半径范围(minRadius和maxRadius),可以通过指定半径范围来辅助该函数。或者,在#HOUGH_梯度法的情况下,您可以将maxRadius设置为负数,以仅返回中心,而不进行半径搜索,并使用其他步骤找到正确的半径
它也有助于平滑图像一点,除非它已经平滑。例如,具有7x7内核和1.5x1.5sigma或类似模糊的GaussianBlur()可能会有所帮助。
霍夫线
霍夫线变换是一种用来寻找直线的方法. 在使用霍夫线变换之前, 首先要对图像进行边缘检测的处理,也即霍夫线变换的直接输入只能是边缘二值图像.
OpenCV支持三种不同的霍夫线变换,它们分别是:标准霍夫变换(Standard Hough Transform,SHT)和多尺度霍夫变换(Multi-Scale Hough Transform,MSHT)累计概率霍夫变换(Progressive Probabilistic Hough Transform ,PPHT)。
其中,多尺度霍夫变换(MSHT)为经典霍夫变换(SHT)在多尺度下的一个变种。累计概率霍夫变换(PPHT)算法是标准霍夫变换(SHT)算法的一个改进,它在一定的范围内进行霍夫变换,计算单独线段的方向以及范围,从而减少计算量,缩短计算时间。之所以称PPHT为“概率”的,是因为并不将累加器平面内的所有可能的点累加,而只是累加其中的一部分,该想法是如果峰值如果足够高,只用一小部分时间去寻找它就够了。这样猜想的话,可以实质性地减少计算时间。
在OpenCV中,我们可以用HoughLines函数来调用标准霍夫变换SHT和多尺度霍夫变换MSHT。
而HoughLinesP函数用于调用累计概率霍夫变换PPHT。累计概率霍夫变换执行效率很高,所有相比于HoughLines函数,我们更倾向于使用HoughLinesP函数。
总结一下,OpenCV中的霍夫线变换有如下三种:
标准霍夫变换(StandardHough Transform,SHT),由HoughLines函数调用。
多尺度霍夫变换(Multi-ScaleHough Transform,MSHT),由HoughLines函数调用。
累计概率霍夫变换(ProgressiveProbabilistic Hough Transform,PPHT),由HoughLinesP函数调用。
一般来说, 一条直线能够通过在平面 寻找交于一点的曲线数量来检测。而越多曲线交于一点也就意味着这个交点表示的直线由更多的点组成. 一般来说我们可以通过设置直线上点的阈值来定义多少条曲线交于一点我们才认为检测到了一条直线。
这就是霍夫线变换要做的. 它追踪图像中每个点对应曲线间的交点. 如果交于一点的曲线的数量超过了阈值, 那么可以认为这个交点所代表的参数对在原图像中为一条直线。
[(41条消息) 【OpenCV入门教程之十四】OpenCV霍夫变换:霍夫线变换,霍夫圆变换合辑_1][原]【opencv入门教程之十四】opencv霍夫变换:霍夫线变换,霍夫圆变换合辑_浅墨_毛星云的博客-CSDN博客
C++: void HoughLines(
InputArray image,
OutputArray lines,
double rho,
double theta,
int threshold,
double srn=0,
double stn=0
)
参数讲解:
- image: 输入图像
- OtrputArray lines:经过调用HoughLines函数后储存了霍夫线变换检测到线条的输出矢量。每一条线由具有两个元素的矢量
表示,其中,
是离坐标原点((0,0)(也就是图像的左上角)的距离。
是弧度线条旋转角度(0垂直线,π/2水平线)。就是所学过的极坐标表示方法
- 第三个参数,double类型的rho,以像素为单位的距离精度。另一种形容方式是直线搜索时的进步尺寸的单位半径。PS:Latex中/rho就表示
- 第四个参数,double类型的theta,以弧度为单位的角度精度。另一种形容方式是直线搜索时的进步尺寸的单位角度。
- int threshold: 阀值, 即识别某部分为图中的一条直线时他在累加平面中必须达到的值,大于阈值threshold 的线段才能被检测通过并返回到结果中
- double srn,对于多尺度的霍夫变换,这是第三个参数进步尺寸rho的除数距离。粗略的累加器进步尺寸直接是第三个参数rho,而精确的累加器进步尺寸为rho/srn
- 第七个参数,double类型的stn,有默认值0,对于多尺度霍夫变换,srn表示第四个参数进步尺寸的单位角度theta的除数距离。且如果srn和stn同时为0,就表示使用经典的霍夫变换。否则,这两个参数应该都为正数。
实例代码:
#include <opencv2/opencv.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include<iostream>
#include<vector>
using namespace cv;
using namespace std;
int main( )
{
//【1】载入原始图和Mat变量定义
Mat srcImage = imread("roadtianwest.jpg"); //工程目录下应该有一张名为1.jpg的素材图
Mat midImage,dstImage;//临时变量和目标图的定义
//【2】进行边缘检测和转化为灰度图
Canny(srcImage, midImage, 50, 200, 3);//进行一此canny边缘检测
cvtColor(midImage,dstImage,COLOR_GRAY2BGR);//转化边缘检测后的图为灰度图
//【3】进行霍夫线变换
//【4】依次在图中绘制出每条线段
vector<Vec4i> lines;
//进行霍夫变换
HoughLinesP(midImage, lines, 1, CV_PI / 180, 80, 50, 10);
//依次在图中绘制每条线段
for (size_t i = 0;i < lines.size();i++) {
Vec4i l = lines[i];
line(dstImage, Point(l[0], l[1]), Point(l[2], l[3]), Scalar(0, 0, 255), 1, LINE_AA);
}
namedWindow("midimage",WINDOW_FREERATIO);
namedWindow("dstimage",WINDOW_FREERATIO);
//【5】显示原始图
imshow("1", srcImage);
//【6】边缘检测后的图
imshow("midimage", midImage);
//【7】显示效果图
imshow("dstimage", dstImage);
waitKey(0);
return 0;
}
图像轮廓处理
再n维矩阵中,每个元素对应不同位置信息,与某个元素相邻的某些元素具有相似或相同的值,可以认为他们存在关系。颜色相近或相同的像素块,转为灰度图后,即变成了亮度的连续与突变关系。转化为二值图后,就是明暗色块的连续和突变
这些连续与突变的组合,其实就是肉眼可观的轮廓。在Robomaster比赛中,传统的视觉方法就是通过预处理,将采集到的图像转换为灰度图像或二值化图像,进行轮廓处理,特征比对,拟合,解算。最重要的就是对处理后的轮廓进行比对拟合。
findContours()--寻找轮廓
PS:寻找轮廓是针对白色物体的,一定要保证物体是白色,而背景是黑色,不然很多人在寻找轮廓时会找到图片最外面的一个框。
找到一篇好文章
轮廓处理:
(41条消息) 利用OpenCV进行图像的轮廓检测_opencv轮廓检测_卓晴的博客-CSDN博客
过程:
- 导入图像
- cvtColor转化为灰度图
- threshold二值化处理
- findContours寻找轮廓
- drawContours绘制轮廓
findContours():
(42条消息) findContours函数参数详解_-牧野-的博客-CSDN博客
findContours( InputOutputArray image, //输入
OutputArrayOfArrays contours, //保存所有轮廓点的向量
OutputArray hierarchy, //Vec4i是Vec<int,4>的别名,定义了一个“向量内每一个元素包含了4个int型变量”的向量,4个整形分别对应当前轮廓的后一个轮廓、前一个轮廓、父轮廓、内嵌轮廓的索引编号。
int mode, //轮廓检索方式
int method, //定义轮廓的近似方法:
Point offset=Point() //Point偏移量,所有的轮廓信息相对于原始图像对应点的偏移量,相当于在每一个检测出的轮廓点上加上该偏移量,并且Point还可以是负值!
);
drawContours()--- 描绘轮廓
(42条消息) OpenCV中drawContours用法_牧羊女说的博客-CSDN博客
opencv —— findContours、drawContours 寻找并绘制轮廓 - 老干妈泡面 - 博客园 (cnblogs.com)
void drawContours(InputOutputArray image,
InputOutputArrays contours,
int contourIdx, //轮廓的索引编号。若为负值,则绘制所有轮廓。
const Scalar& color, //轮廓颜色。Scalar(x,x,x)来确定颜色
int thickness = 1, 轮廓线条的粗细程度,有默认值 1。若其为负值,便会填充轮廓内部空间。
int lineType = 8, 线条的类型,有默认值8
InputArray hierarchy = noArray(),
int maxLevel = INT_MAX,
Point offset = Point()
);
API详细讲解:
- lineType,线条的类型,有默认值 8。可去类型如下:
| 类型 | 含义 |
|---|---|
| 8 | 8 连通线型 |
| 4 | 4 连通线型 |
| LINE_AA | 抗锯齿线型 |
- hierarchy,可选的层次结构信息,有默认值 noArray()。
- maxLevel,用于绘制轮廓的最大等级,有默认值 INT_MAX。
- offset,轮廓信息相对于目标图像对应点的偏移量,相当于在每一个轮廓点上加上该偏移量,有默认值 Point() 。在 ROI 区域(感兴趣区域)绘制轮廓时,这个参数便可派上用场。
轮廓检测方法:
寻找轮廓时,可以按着这个模板来:
//接下来进行寻找轮廓
vector<vector<Point>>contours; //这两步vector必须要有
vector<Vec4i>hierarchy;
findContours(img2,contours,hierarchy,CV_RETR_TREE,CHAIN_APPROX_NONE);
取值一:CV_RETR_EXTERNAL只检测最外围轮廓,包含在外围轮廓内的内围轮廓被忽略
取值二:CV_RETR_LIST 检测所有的轮廓,包括内围、外围轮廓,但是检测到的轮廓不建立等级关系,彼此之间独立,没有等级关系,这就意味着这个检索模式下不存在父轮廓或内嵌轮廓,所以hierarchy向量内所有元素的第3、第4个分量都会被置为-1,具体下文会讲到
取值三:CV_RETR_CCOMP 检测所有的轮廓,但所有轮廓只建立两个等级关系,外围为顶层,若外围 内的内围轮廓还包含了其他的轮廓信息,则内围内的所有轮廓均归属于顶层
取值四:CV_RETR_TREE, 检测所有轮廓,所有轮廓建立一个等级树结构。外层轮廓包含内层轮廓,内层轮廓还可以继续包含内嵌轮廓。
定义轮廓近似方法:
取值一:CV_CHAIN_APPROX_NONE 保存物体边界上所有连续的轮廓点到contours向量内
取值二:CV_CHAIN_APPROX_SIMPLE 仅保存轮廓的拐点信息,把所有轮廓拐点处的点保存入contours向量内,拐点与拐点之间直线段上的信息点不予保留
取值三和四:CV_CHAIN_APPROX_TC89_L1,CV_CHAIN_APPROX_TC89_KCOS使用teh-Chinl chain 近似算法
自己写的代码:
#include<opencv2/opencv.hpp>
#include<opencv2/imgproc/imgproc_c.h>
#include<opencv2/highgui.hpp>
#include<opencv2/core.hpp>
#include<iostream>
#include<vector>
using namespace std;
using namespace cv;
int main(){
Mat img1 = imread("roadtianwest.jpg");
Mat img2 = img1;
cvtColor(img1,img2,CV_BGR2GRAY); //#include<opencv2/imgproc/imgproc_c.h>要加入这个头文件,才不会cv_bgr2gray报错
//二值化
threshold(img2,img2,85,255,THRESH_BINARY);
//接下来进行寻找轮廓
vector<vector<Point>>contours;
vector<Vec4i>hierarchy;
findContours(img2,contours,hierarchy,CV_RETR_TREE,CHAIN_APPROX_NONE);
//绘制轮廓
Mat img3; //Mat img3 = img1; 这样做传的是地址,导致img1也被修改了
//试试克隆
img3 = img1.clone(); //这一次行了,就是深拷贝与浅拷贝的区别
drawContours(img3, contours, -1, Scalar(255, 255, 255), 2);
//展示效果
namedWindow("originalphoto",WINDOW_FREERATIO);
namedWindow("threshold_img2",WINDOW_FREERATIO);
namedWindow("drawcontoursimg3",WINDOW_FREERATIO);
imshow("originalphoto",img1);
imshow("threshold_img2",img2);
imshow("drawcontoursimg3",img3);
waitKey(0);
destroyAllWindows();
return 0;
}
成品展示: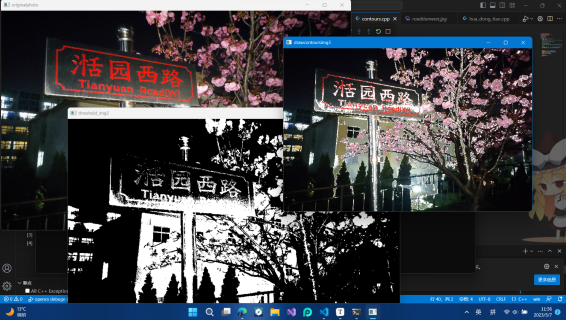
canny 边缘检测
使用canny方法:
1.消噪
一般情况均值滤波降噪
2.计算幅度和方向
梯度的方向与边缘的方向是垂直的。
边缘检测算子返回水平方向的Gx和垂直方向的Gy。梯度的幅度𝐺和方向𝛩(用角度值表示)为:
式中,atan2(•)表示具有两个参数的 arctan 函数。
梯度的方向总是与边缘垂直的,通常就近取值为水平(左、右)、垂直(上、下)、对角线(右上、左上、左下、右下)等 8 个不同的方向。
因此,在计算梯度时,我们会得到梯度的幅度和角度(代表梯度的方向)两个值。
图 10-2 展示了梯度的表示法。其中,每一个梯度包含幅度和角度两个不同的值。为了方便观察,这里使用了可视化表示方法。例如,左上角顶点的值“2↑”实际上表示的是一个二元数对“(2, 90)”,表示梯度的幅度为 2,角度为 90°。

3.非极大值抑制
在获得了梯度的幅度和方向后,遍历图像中的像素点,去除所有非边缘的点。在具体实现时,逐一遍历像素点,判断当前像素点是否是周围像素点中具有相同梯度方向的最大值,并根据判断结果决定是否抑制该点。通过以上描述可知,该步骤是边缘细化的过程。针对每一个像
素点:
如果该点是正/负梯度方向上的局部最大值,则保留该点。
如果不是,则抑制该点(归零)
4.应用双阈值确定边缘
这是最后一步,canny使用了滞后阈值,滞后阈值需要两个阈值,分别是高阈值和低阈值:
- 如果某一像素位置的幅值超过高阈值,该像素被保留为边缘像素;
- 如果某一像素位置的幅值小于低阈值,该像素被排除;
- 如果某一像素位置的幅值在两个阈值之间,该像素仅仅在连接到一个高于高阈值的像素时被保留。
对canny函数,高阈值与低阈值的比值最好是2:1和3:1之间。
以上步骤仅作演示,不严格按照上述步骤也能进行,不过不降噪的话边缘检测可能不准
void cv::Canny ( InputArray image,
OutputArray edges,
double threshold1,
double threshold2,
int apertureSize = 3,
bool L2gradient = false
)
- image 输入
- edges 输出的边缘图,需要与输入图像具有相同的尺寸和类型
- threshold1 第一个滞后性阈值
- threshold2 第二个滞后性阈值
- apertureSize 表示算子的孔径大小,默认值为3
- bool类型的L2gradient,一个计算图像梯度复制的标识,默认false。
需要注意的是,阈值1和阈值2两者中比较小的值用于边缘连接,较大的值用来控制边缘的初始段,推荐高低阈值比在2:1和3:1之间。
实例代码:
#include<iostream>
#include<opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main(){
Mat img1 = imread("roadtianwest.jpg");
GaussianBlur(img1,img1,Size(5,5),0); //注意,Size S要大写
Mat img2 = img1.clone();
Canny(img1,img2,150,50);
namedWindow("dstimg",WINDOW_KEEPRATIO);
imshow("dstimg",img2);
waitKey(0);
destroyAllWindows();
return 0;
}
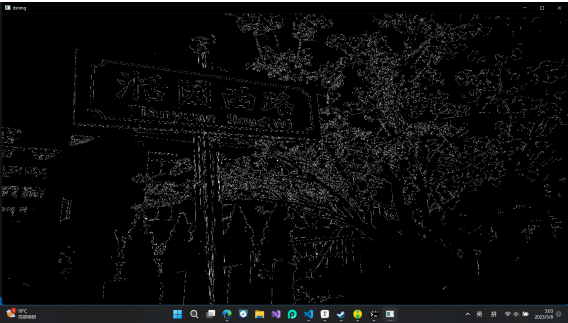
sobel算子
Sobel算子:用于边缘检测的离散微分算子。(一阶)(结合了高斯平滑和微分)
1、边缘检测: Gx 用于检测纵向边缘, Gy 用于检测横向边缘.
2、计算法线: Gx 用于计算法线的横向偏移, Gy 用于计算法线的纵向偏移.
Sobel边缘检测算法比较简单,实际应用中效率比canny边缘检测效率要高,但是边缘不如Canny检测的准确,但是很多实际应用的场合,sobel边缘却是首选,Sobel算子是高斯平滑与微分操作的结合体,所以其抗噪声能力很强,用途较多。尤其是*效率要求较高,而对细纹理不太关心的时候*。
对某个方向进行求轮廓时,要进行微分:
求x方向上的轮廓,就是对y方向求导
求y方向上的轮廓,就是对x方向求导
原理:
*因为图像是二维的,所以需要在两个方向求导*:
*垂直*方向的边缘在*水平方向*的*梯度*(偏导数)幅值*较大***
*水平*方向的边缘在*垂直方向*的*梯度*(偏导数)幅值*较大***
Sobel算子刚好能*描述*这个图像变化。
具体原理见博客:(42条消息) OpenCV(十五)边缘检测1 -- Sobel算子(一阶微分算子,X、Y方向边缘检测)opencv sobel_(▽)_的博客-CSDN博客
Schar算子能够弥补Sobel内核为3时的误差:(更佳的3*3滤波器:Scahrr ()函数)
void Sobel (InputArray src, //输入
OutputArray dst, //输出
int depth, //输出图像的深度,针对不同的输入图像,输出目标图像有不同的深度
int dx, // x 方向上的差分阶数,1或0 就是在不在x上求导
int dy, // y 方向上的差分阶数,1或0 就是在不在y上求导
int ksize=3, //为进行边缘检测时的模板大小,为ksize*ksize,设置这个ksize就表明了大小为ksize*ksize大小的模板,
double scale=1,
double delta=0,
int borderType=BORDER_DEFAULT );
-
对于depth的解释:
- 若src.depth() = CV_8U, 取depth =-1/CV_16S/CV_32F/CV_64F
- 若src.depth() = CV_16U/CV_16S, 取depth =-1/CV_32F/CV_64F
- 若src.depth() = CV_32F, 取depth =-1/CV_32F/CV_64F
- 若src.depth() = CV_64F, 取depth = -1/CV_64F
-
对于ksize具体的解释:
为进行边缘检测时的模板大小为ksizeksize,取值为1、3、5和7,其中默认值为3。特殊情况:ksize=1时,采用的模板为31或1*3。
当ksize=3时,Sobel内核可能产生比较明显的误差,此时,可以使用 Scharr 函数,该函数仅作用于大小为3的内核。具有跟sobel一样的速度,但结果更精确,其内核为: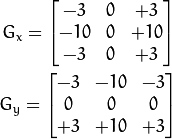
代码:
Sobel(gray, grad_x, CV_16S, 1, 0, 3);
// x方向差分阶数 y方向差分阶数 核大小
使用过程:
1)高斯模糊平滑降噪:
GaussianBlur( src, dst, Size(3,3), 0, 0, BORDER_DEFAULT );
2)转灰度:
cvtColor( src, gray, COLOR_RGB2GRAY );
3)求X和Y方向的梯度(求导):
Sobel(gray_src, xgrad, CV_16S, 1, 0, 3);
Sobel(gray_src, ygrad, CV_16S, 0, 1, 3);
Scharr(gray_src, xgrad, CV_16S, 1, 0);
Scharr(gray_src, ygrad, CV_16S, 0, 1);
4)像素取绝对值:
convertScaleAbs(A, B); //计算图像A的像素绝对值,输出到图像B
5)相加X和Y,得到综合梯度,称为振幅图像:
addWeighted( A, 0.5,B, 0.5, 0, AB); //混合权重相加,效果较差
或者循环获取像素,每个点直接相加,效果更好。
当然,上述步骤不遵循还是可以执行的
如果直接是对原图进行sobel检测边缘,所得边缘是原来颜色。
如图
#include<iostream>
#include<opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main(){
Mat img1 = imread("roadtianwest.jpg");
namedWindow("img",WINDOW_KEEPRATIO);
namedWindow("img1",WINDOW_KEEPRATIO);
namedWindow("img2",WINDOW_FREERATIO);
Mat img2 = img1.clone();
Mat img3 = img1.clone();
Mat img4 = img1.clone();
Sobel(img1,img2,-1,1,0); //当sobel x,y同时求导时,所求图像为黑色
Sobel(img1,img3,-1,0,1);
imshow("img",img2);
imshow("img1",img3);
addWeighted(img2,0.5,img3,0.5,20,img4);
imshow("img2",img4);
waitKey(0);
destroyAllWindows();
return 0;
}
这里有个addWeighted函数:(42条消息) opencv中addWeighted()函数用法总结(05)_洛克家族的博客-CSDN博客

approxPolyDP生成逼近曲线
opencv —— approxPolyDP 生成逼近曲线 - 老干妈泡面 - 博客园 (cnblogs.com)
这个博客对原理写的很详细
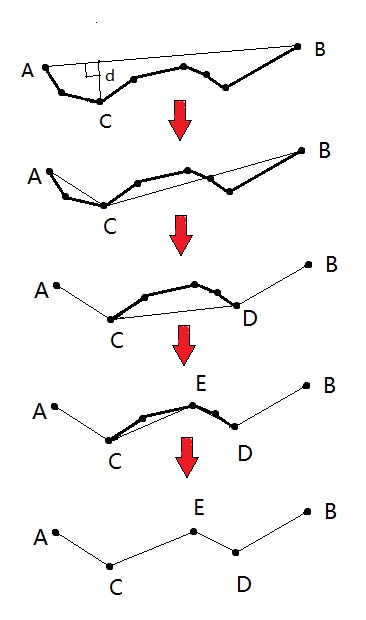
该函数采用 Douglas-Peucker 算法(也称迭代终点拟合算法)。可以有效减少多边形曲线上点的数量,生成逼近曲线,简化后继操作。
经典的 Douglas-Peucker 算法描述如下:
- 在曲线首尾两点 A,B 之间连接一条直线 AB,该直线为曲线的弦;
- 得到曲线上离该直线段距离最大的点 C,计算其与 AB 的距离 d;
- 比较该距离与预先给定的阈值 threshold 的大小,如果小于 threshold,则该直线段作为曲线的近似,该段曲线处理完毕。
- 如果距离大于阈值,则用 C 将曲线分为两段 AC 和 BC ,并分别对两段曲线进行 1~3 的处理。
- 当所有曲线都处理完毕时,依次连接各个分割点形成的折线,即可以作为曲线的近似。
void approxPolyDP(InputArray curve, //vector或mat类型
OutputArray approxCurve, //与输入类型保持一致
double epsilon, //逼近的精度,设定的原始曲线与近似曲线之间的最大距离,即上文提到的的阈值。
bool closed); //如果为真,则近似的曲线为封闭曲线(第一个顶点和最后一个顶点相连),否则,近似的曲线不封闭。
我的代码:
#include<opencv2/opencv.hpp>
#include<opencv2/imgproc/imgproc_c.h>
#include<opencv2/highgui.hpp>
#include<opencv2/core.hpp>
#include<iostream>
#include<vector>
using namespace std;
using namespace cv;
int main(){
Mat img1 = imread("roadtianwest.jpg");
Mat img2;
cvtColor(img1,img2,CV_BGR2GRAY);
threshold(img2,img2,50,255,THRESH_BINARY);
//imshow("img2",img2);
//首先寻找轮廓:
vector<vector<Point>>contours; //保存所有轮廓点的向量
vector<Vec4i>hierarchy;
//findContours 用来寻找轮廓向量
findContours(img2,contours,hierarchy,CV_RETR_EXTERNAL,CHAIN_APPROX_NONE);
vector<vector<Point>>approx_contours(contours.size()); //定义个与contours一样大的vector,用来存放逼近曲线的数组
//尝试过不用for循环赋值向量,而是直接 approxPolyDP(contours,approx_contours,5,true);结果不行
for(int i = 0;i<contours.size();i++){
approxPolyDP(contours[i],approx_contours[i],5,true);
}
drawContours(img1,approx_contours,-1,Scalar(255,255,255),3);
namedWindow("img1",WINDOW_FREERATIO);
imshow("img1",img1);
//尝试下传一下mat,结果失败了
Mat img3,img4;
img4.create(img1.size(),img1.type());
img4 = Scalar::all(0);
Canny(img1,img3,150,50);
approxPolyDP(img3,img4,5,true); //失败了
namedWindow("img4",WINDOW_FREERATIO);
imshow("img4",img3);
//imshow("img4",img4);
waitKey(0);
return 0;
}
RotateRect类
RotatedRect该类表示平面上的旋转矩形,该类对象有三个重要属性:矩形中心点(质心),边长(长和宽),旋转角度。三种构造函数和三种成员操作函数,定义如下:
class CV_EXPORTS RotatedRect
{
public:
//构造函数
RotatedRect();
RotatedRect(const Point2f& center, const Size2f& size, float angle);
RotatedRect(const CvBox2D& box);
//!返回矩形的4个顶点
void points(Point2f pts[]) const;
//返回包含旋转矩形的最小矩形
Rect boundingRect() const;
//!转换到旧式的cvbox2d结构
operator CvBox2D() const;
Point2f center; //矩形的质心
Size2f size; //矩形的边长
float angle; //旋转角度,当角度为0、90、180、270等时,矩形就成了一个直立的矩形
};
(42条消息) OpenCV之RotatedRect基本用法和角度探究_opencv rotatedrect_sandalphon4869的博客-CSDN博客
实例代码:
mat input=img.clone()//img图像为预处理后的二值化图像
vector<vector<Point> > contours;
vector<Vec4i> hierarchy;//存储查找到的第i个轮廓的后[i][0]、前[i][1]、父[i][2]、子轮廓[i][3]
findContours(input, contours, hierarchy, RETR_CCOMP, CHAIN_APPROX_SIMPLE);
RotatedRect r= minAreaRect(contours[i]);
rectangle()----绘制矩形框
rectangle函数是用来绘制一个矩形框的,通常用在图片的标记上。
函数原型1:
rectangle(img2, //输入
Point(j,i), //矩形左上坐标
Point(j + img4.cols, i + img4.rows), //矩形右下坐标
Scalar(255, 255, 0), //矩形框颜色
2, //线条宽度
8 //线型,默认为8
);
函数原型2:
void cv::rectangle ( InputOutputArray img, //将矩阵写在这个矩形上
Rect rec, //传入的矩阵
const Scalar & color,
int thickness = 1, // 线条宽度
int lineType = LINE_8,
int shift = 0 //点坐标中的小数位数
)
Rect()---画矩形
Rect函数也是画矩形的,但与上面的有所不同
Rect(x,y,width,height),x, y 为左上角坐标, width, height 则为长和宽。
Rect roi_rect = Rect(128, 128, roi.cols, roi.rows);
boundingRect()---边缘矩形近似
这个函数可以根据findcontours所得的轮廓,根据这个轮廓来确定一个最小的包围轮廓的矩形,这个函数得到的矩阵都是方正的,minAreaRect所得的是带倾斜角度的,下面也有写
Rect cv::boundingRect ( InputArray array )
返回类型是 Rect 。
因此,可以通过使用rectangle()函数绘制到原图上:
#include <iostream>
#include <time.h>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main()
{
cv::Mat src = imread("test.png",0);
cv::Mat result = src.clone();
cv::Mat th1;
// 最大类间差法,也称大津算法
threshold(result, th1, 0, 255, THRESH_OTSU);
// 反相
th1 = 255 - th1;
// 确定连通区轮廓
std::vector<std::vector<cv::Point> > contours; // 创建轮廓容器
std::vector<cv::Vec4i> hierarchy;
cv::findContours(th1, contours, hierarchy, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_NONE, cv::Point());
// 遍历轮廓显示矩形框
for (int i = 0; i < contours.size(); ++i)
{
cv::Rect rect = cv::boundingRect(cv::Mat(contours[i]));
cv::rectangle(result, rect, Scalar(255), 1);
}
imshow("original", src);
imshow("thresh", th1);
imshow("result", result);
waitKey(0);
return 0;
}

最小面积旋转矩形近似 ---minAreaRect
RotatedRect cv::minAreaRect ( InputArray points )
解释:points 为一系列点集,这个函数的作用就是圈出一个矩形框框,把所有的点都圈在这个框框里:
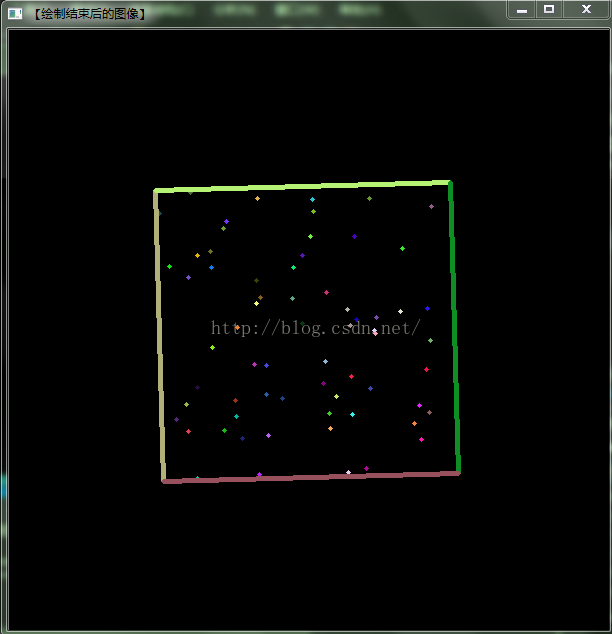
mat input=img.clone()//img图像为预处理后的二值化图像
vector<vector<Point> > contours;
vector<Vec4i> hierarchy;//存储查找到的第i个轮廓的后[i][0]、前[i][1]、父[i][2]、子轮廓[i][3]
findContours(input, contours, hierarchy, RETR_CCOMP, CHAIN_APPROX_SIMPLE);
RotatedRect r= minAreaRect(contours[i]);
示例代码试试将上面的bound ingRect()函数换成 minAreaRect()试试
#include <iostream>
#include <time.h>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main()
{
cv::Mat src = imread("test.png",0);
cv::Mat result = src.clone();
cv::Mat th1;
// 最大类间差法,也称大津算法
threshold(result, th1, 0, 255, THRESH_OTSU);
// 反相
th1 = 255 - th1;
// 确定连通区轮廓
std::vector<std::vector<cv::Point> > contours; // 创建轮廓容器
std::vector<cv::Vec4i> hierarchy;
cv::findContours(th1, contours, hierarchy, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_NONE, cv::Point());
// 遍历轮廓显示矩形框
for (int i = 0; i < contours.size(); ++i)
{
cv::Rect rect = cv::minAreaRect(cv::Mat(contours[i]));
cv::rectangle(result, rect, Scalar(255), 1);
}
imshow("original", src);
imshow("thresh", th1);
imshow("result", result);
waitKey(0);
return 0;
}
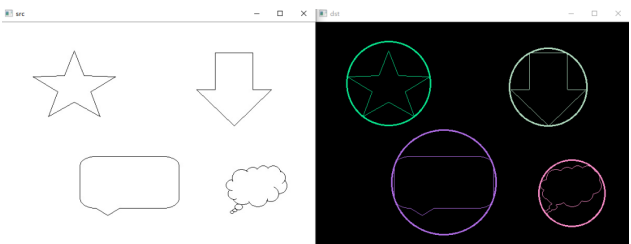
minEnclosingCircle---最小包围圆
void minEnclosingCircle(InputArray points, //输入点集,vector或者mat
Point2f& center, //圆心
float& radius); //半径
在使用时,先创建个与contours.size()一样大的圆心集,半径集
//省略之前步骤,假设得到了一个contours向量组
vector<Point2f> center(contours.size()) //圆心
vector<float>radius(contours.size()); //半径
minEnclosingCircle(contours[i], centers[i], radius[i]);
之后再通过circle画圆即可
circle(dst, centers[i], radius[i], colors, 2);
arcLength()----轮廓周长
arcLength( Inputarray curve; //输入 vector 或者 mat类
bool closed;
)
(43条消息) OpenCV-计算轮廓周长cv::arcLength_翟天保Steven的博客-CSDN博客
contourArea()---轮廓面积
计算原理:格林公式

可以见工科数学分析课本
double contourArea( InputArray contour, //输入轮廓,要求闭合,不然也没面积一说。 可以是vector或者Mat类
bool oriented = false //如果是true的话则会根据轮廓方向,来输出一个带有正负号的面积,具体原理还是格林公式);
oriented,面向区域标识符。有默认值 false。若为 true,该函数返回一个带符号的面积值,正负取决于轮廓的方向(顺时针还是逆时针)。若为 false,表示以绝对值返回。
仿射变换
(43条消息) 一文解决!opencv中的仿射变换(仿射变化的原理,使用,提升拓展的总结)_仿射变换矩阵改分辨率_西瓜6的博客-CSDN博客
仿射变换的变换方式是,是指在几何中,一个向量空间进行一次线性变换并接上一个平移,变换为另一个向量空间。相对直接来说,就是源图像矩阵乘一个旋转矩阵,然后加上一个列向量,最后得到生成的新图像矩阵。从图像层面上来看,仿射变换可以使图像进行平移(Translation)、缩放(Scale)、翻转(Flip)、旋转(Rotation)和错切(Shear)。
warpAffine()---仿射变换函数
void cv::warpAffine ( InputArray src, //输入
OutputArray dst, //输出
InputArray M, //变换矩阵,代表着要对图像进行平移,还是旋转,翻转等操作
Size dsize, //目标图像大小
int flags = INTER_LINEAR,//插值方法的组合(int 类型!)
int borderMode = BORDER_CONSTANT, //边界像素模式(int 类型!)
const Scalar & borderValue = Scalar()
) //(重点!)边界填充值; 默认情况下,它为0。
2、flages表示插值方式,默认为 flags=cv2.INTER_LINEAR,表示线性插值,此外还有:cv2.INTER_NEAREST(最近邻插值) cv2.INTER_AREA (区域插值) cv2.INTER_CUBIC(三次样条插值) cv2.INTER_LANCZOS4(Lanczos插值)
我们通常使用 3×2 矩阵来表示仿射变换的变换矩阵
getAffineTransform()----获取变换矩阵(得到仿射变换核)
如果我们能通过这样两组三个点求出仿射变换(你能选择自己喜欢的点), 接下来我们就能把仿射变换应用到图像中所有的点。
Mat getAffineTransform( const Point2f src[] // (x,y)二维坐标数组,至少三个坐标
const point2f dst[] //同理,这是已知的目标图像,
)
根据原始图像和目标图像,就能求出对应变换的矩阵
remap函数
(33条消息) 【OpenCV入门教程之十七】OpenCV重映射 & SURF特征点检测合辑_opencv remap 注释_浅墨_毛星云的博客-CSDN博客
(33条消息) OpenCV:remap()简单重映射_cv::remap 单个像素的位置_SSS_369的博客-CSDN博客
C++:
void remap(InputArray src, //输入图像
OutputArraydst, //输出图像
InputArray map1,//第一个映射
InputArray map2, //第二个映射
int interpolation, //插值
intborderMode=BORDER_CONSTANT,
const Scalar& borderValue=Scalar()
)
-
src : 原始图像;
-
dst : 目标图像,大小和map1的大小相同,数据类型和src的数据类型一样;
-
map1:表示(x,y)坐标点或者是x坐标,类型为CV_16SC2,CV_32FC1或者CV_32FC2;
-
map2: 表示y坐标,类型是CV_16UC1, CV_32FC1,当map1是(x,y)坐标时,map2可以为空;
-
Interpolation:表示插值算法,枚举类型主要。暂不支持INTER_AREA 插值算法。插值算法有一下几种:
| 类型 | 说明 |
|---|---|
| INTER_NEAREST | 最近邻插值 |
| INTER_LINEAR | 双线性插值 |
| INTER_CUBIC | 双三次插值 |
| INTER_AREA | 利用像素面积关系重采样。这可能是图像抽取的首选方法,因为它可以得到无云纹的结果。但当图像被放大时,它类似于最近邻法。 |
| INTER_LANCZOS4 | 8x8邻域上的Lanczos插值 |
| INTER_LINEAR_EXACT | 位精确双线性插值 |
| INTER_NEAREST_EXACT | 位最近邻插值算法。在PIL,scikit-image和Matlab中效果和最近邻插值算法一样 |
| INTER_MAX | 插值算法掩码 |
| WARP_FILL_OUTLIERS | 标志,填充目标图像。如果目标图像的一部分是异常值,那么他们被设置为0 |
| WARP_INVERSE_MAP | 标志,逆变换 |
-
borderMode: 边界插值类型;
-
borderValue: 表示边界插值数据。
代码如下:
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include <iostream>
//-----------------------------------【命名空间声明部分】--------------------------------------
// 描述:包含程序所使用的命名空间
//-----------------------------------------------------------------------------------------------
using namespace cv;
//-----------------------------------【main( )函数】--------------------------------------------
// 描述:控制台应用程序的入口函数,我们的程序从这里开始执行
//-----------------------------------------------------------------------------------------------
int main( )
{
//【0】变量定义
Mat srcImage, dstImage;
Mat map_x, map_y;
//【1】载入原始图
srcImage = imread( "1.jpg", 1 );
if(!srcImage.data ) { printf("读取图片错误,请确定目录下是否有imread函数指定的图片存在~! \n"); return false; }
imshow("原始图",srcImage);
//【2】创建和原始图一样的效果图,x重映射图,y重映射图
dstImage.create( srcImage.size(), srcImage.type() );
map_x.create( srcImage.size(), CV_32FC1 );
map_y.create( srcImage.size(), CV_32FC1 );
//【3】双层循环,遍历每一个像素点,改变map_x & map_y的值
for( int j = 0; j < srcImage.rows;j++)
{
for( int i = 0; i < srcImage.cols;i++)
{
//改变map_x & map_y的值.
map_x.at<float>(j,i) = static_cast<float>(i);
map_y.at<float>(j,i) = static_cast<float>(srcImage.rows - j);
}
}
//【4】进行重映射操作
remap( srcImage, dstImage, map_x, map_y, CV_INTER_LINEAR, BORDER_CONSTANT, Scalar(0,0, 0) );
//【5】显示效果图
imshow( "【程序窗口】", dstImage );
waitKey();
return 0;
}
getRotationMartix2D()----创建旋转矩阵
Mat cv::getRotationMatrix2D ( Point2f center, //中心
double angle, //旋转角度
double scale //旋转后的s
)
warpPerspective()----透视变换
对图像进行透视变换,就是变形
void cv::warpPerspective ( InputArray src,
OutputArray dst,
InputArray M,
Size dsize,
int flags = INTER_LINEAR,
int borderMode = BORDER_CONSTANT,
const Scalar & borderValue = Scalar()
)
绘图函数
学过地画线,画圆,等不再赘述,可见8.绘图函数 · 算法文档 · 看云 (kancloud.cn)
python看自己写过的代码Tanگگ - 博客园 (cnblogs.com)
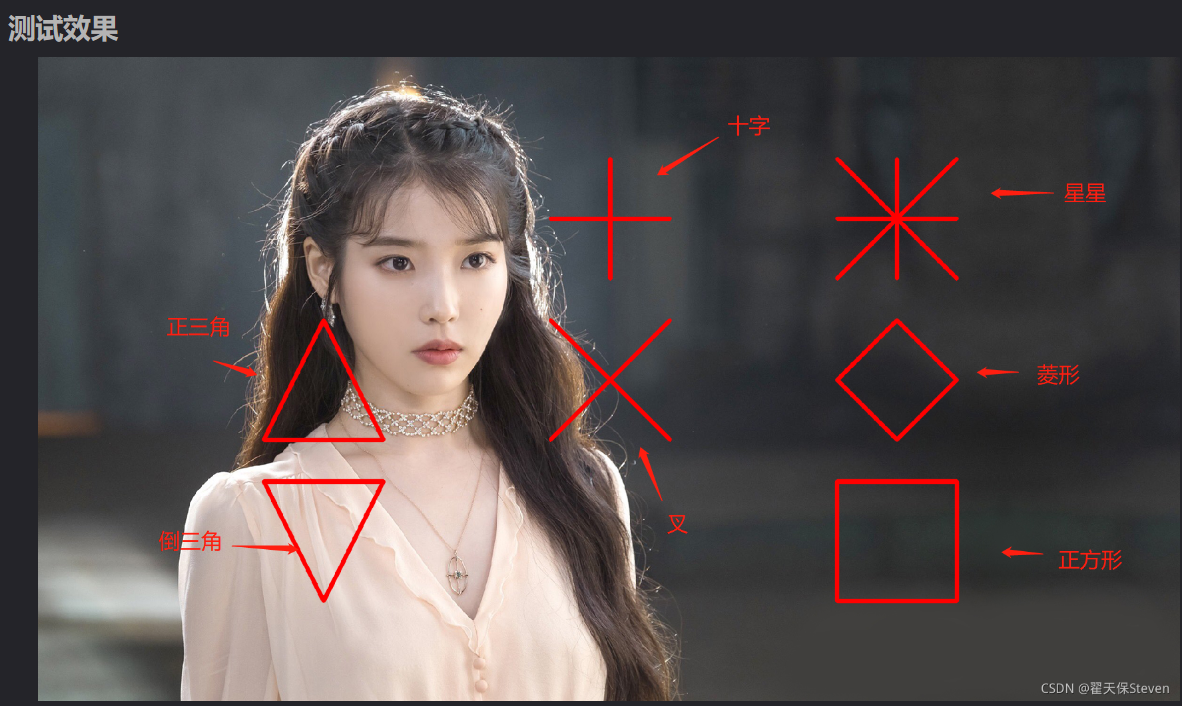
drawMarker绘制标记
void cv::drawMarker ( InputOutputArray img,
Point position, //绘制图片中心点
const Scalar & color, //文字颜色
int markerType = MARKER_CROSS, //标记符类型
int markerSize = 20, //标记符尺寸
int thickness = 1, //线条宽度
int line_type = 8
)
drawMarker总共可以绘制的图形我都绘制出来了。
MARKER_CROSS为十字,
MARKER_TILTED_CROSS为叉,
MARKER_STAR为星星,
MARKER_DIAMOND为菱形,
MARKER_SQUARE为正方形,
MARKER_TRIANGLE_UP为正三角,
MARKER_TRIANGLE_DOWN为倒三角
#include <iostream>
#include <string>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main()
{
cv::Mat src = imread("test.jpg");
cv::Mat result = src.clone();
drawMarker(result, Point(src.cols / 2,src.rows / 4), Scalar(0,0,255), MARKER_CROSS, 200, 5, 16);
drawMarker(result, Point(src.cols / 2, src.rows / 2), Scalar(0, 0, 255), MARKER_TILTED_CROSS, 200, 5, 16);
drawMarker(result, Point(3 * src.cols / 4, src.rows / 4), Scalar(0, 0, 255), MARKER_STAR, 200, 5, 16);
drawMarker(result, Point(3 * src.cols / 4, src.rows / 2), Scalar(0, 0, 255), MARKER_DIAMOND, 200, 5, 16);
drawMarker(result, Point(3 * src.cols / 4, 3 * src.rows / 4), Scalar(0, 0, 255), MARKER_SQUARE, 200, 5, 16);
drawMarker(result, Point(src.cols / 4, src.rows / 2), Scalar(0, 0, 255), MARKER_TRIANGLE_UP, 200, 5, 16);
drawMarker(result, Point(src.cols / 4, 3 * src.rows / 4), Scalar(0, 0, 255), MARKER_TRIANGLE_DOWN, 200, 5, 16);
imshow("original", src);
imshow("result", result);
waitKey(0);
system("pause");
return 0;
}
一些tips
-
图片名字不要有中文,否则imshow不出来
-
LINE_AA 与CV_AA:
在使用visual studio编译一些使用到了霍夫直线变换的OpenCV程序时出现此错误提示请检查OpenCV版本,若是2.4.9则将LINA_AA修改为CV_AA即可解决此问题,LINE_AA是CV3才有的,2.4.9所使用的是CV_AA -
上一条的拓展:(CV_未定义标识符)
最近在opencv学习的时候,老是遇到关于CV_定义符出现未定义标识符的情况,一方面是从网上找的opencv程序版本不一致,高版本对程序中一些定义做了简化和重新修改,导致不匹配情况。后来在网上搜索相关的问题,找到解决问题的办法。笔者遇到的:CV_RGB2GRAY 、CV_MINMAX、CV_WINDOW_AUTOSIZE等。
CV_RGB2GRAY 、CV_MINMAX未定义标识符的解决办法是:
在代码开头加入头文件:#include<opencv2/imgproc/types_c.h> #include<opencv2/opencv.hpp>
CV_WINDOW_AUTOSIZE未定义标识符的解决办法是:
在代码开头加入头文件#include <opencv2/highgui/highgui_c.h>
在原图中2选择块区域
Mat img = imread(".....");
Mat img = origin_image(Rect(x, y, weight, height));
这行代码是从原始图像(origin_image)中提取一个矩形区域(Rect)并保存到新的图像变量 image 中。Rect(x, y, width, height) 表示一个矩形,其中 (x, y) 是矩形的左上角坐标,width 是矩形的宽度,height 是矩形的高度。这样,origin_image(Rect(x, y, width, height)) 就表示从 origin_image 中裁剪出指定矩形区域的图像数据,并将其赋值给 image 变量。
一些不仅限于opencv的知识
C++:标准错误流Cerr
- 标准输出流ostream的对象:cout
- cerr:输出到标准错误的ostream对象,通常用来输出警告和错误信息给程序的使用者
- clog:也是输出标准错误流(和cerr是一样的),用于产生程序执行的一般信息,很少用到。
区别
cout经过缓冲后输出,默认情况下是显示器。这是一个被缓冲的输出,是标准输出;它在内存中对应开辟了一个缓冲区,用来存放流中的数据,当向cout流插入一个endl,不论缓冲区是否漫了,都立即输出流中所有数据,然后插入一个换行符. 可以被输出到文件,即可以重定向输出。
cerr不经过缓冲而直接输出,一般用于迅速输出出错信息,是标准错误,默认情况下被关联到标准输出流,但它不被缓冲,也就说错误消息可以直接发送到显示器,而无需等到缓冲区或者新的换行符时,才被显示。
clog流也是标准错误流,作用和cerr一样,区别在于cerr不经过缓冲区,直接向显示器输出信息,而clog中的信息存放在缓冲区,缓冲区满或者遇到endl时才输出.
(40条消息) 为什么输出错误时要用cerr?_ZHAOCHENHAO-的博客-CSDN博客
我的理解就是,当错误到来是,立即输出错误,不占用缓存,到来一个信息输出一个信息,比cout要快.
cerr对象与标准错误流相对应,可用于显示错误消息.在默认情况下,这个流被关联到标准输出设备(通常为显示器).这个流没有被缓冲,这意味着信息将被直接发送给屏幕,而不会等到缓冲区填满或新的换行符.
例:
Mat src;
// use default camera as video source
VideoCapture cap(0);
// check if we succeeded
if (!cap.isOpened()) {
cerr << "ERROR! Unable to open camera\n";
return -1;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号