BERT和GPT
Word Embedding和Word2Vec
Word2Vec是用来产生Word Embedding的一组技术、模型。
- Word Embedding
词嵌入(Word embedding)是自然语言处理(NLP)中语言模型与表征学习技术的统称。概念上而言,它是指把一个维数为所有词的数量的高维空间(one-hot-encoding)嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。—— From Wiki
如下图所示,Word Embedding可以体现单词间的similarity。可以将word embedding看成word的feature。
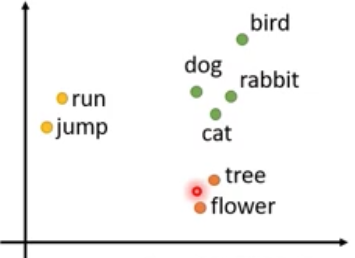
但是对于同一个word而言,它可能有多种意思,比如下面的4个bank是4个不同的word token,但它们有着一样的word type。其中前两个token表示银行,后两个token表示岸边。在过去的word embedding中,每个word type有一个embedding,但这并不合理,因为它不能很好地处理一词多义的情况。

现在的contextualized word embedding可以保证每个word token都有它自己的embedding,且word tokens的embedding和它的上下文是有关的。
- Word2Vec
Word2vec is a technique for natural language processing published in 2013. The word2vec algorithm uses a neural network model to learn word associations from a large corpus of text. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. As the name implies, word2vec represents each distinct word with a particular list of numbers called a vector. The vectors are chosen carefully such that a simple mathematical function (the cosine similarity between the vectors) indicates the level of semantic similarity between the words represented by those vectors.
Word2vec is a group of related models that are used to produce word embeddings. These models are shallow, two-layer neural networks that are trained to reconstruct linguistic contexts of words.
Word2vec can utilize either of two model architectures to produce a distributed representation of words: continuous bag-of-words (CBOW) or continuous skip-gram. ——Frrom wikipedia
常见的NLP任务
参考资料:
1 NLP-progress
2 GitHub-NLP-progress
- QA(Question Answering: 问答系统): 针对问题给出答案
- NER(Named Entity Recognition: 命名实体识别): 找出文中的命名实体,并对其进行分类
- Machine Translation(机器翻译): 将一种语言的句子翻译成另外一种语言。Transformer论文中的Transformer结构包括Encoder和Decoder,就是为了解决机器翻译这一任务。
- LM(Language Modelling: 语言模型): 根据已知序列,推测文本中下一个单词是什么
- NLI(Natural Language Inference: 自然语言推理): 在给定前提(premise)的情况下,判断假设(hypothesis)是真、假还是不确定,举个例子
![image]()

Many important downstream tasks such as Question Answering and Natural Language Inference are based on understanding the relationship between two sentences, which is not directly captured by language modelling. (Language Modelling主要捕捉的是word token之间的关系)
BERT
BERT是Bidirectional Encoder Representation from Transformer的缩写,它的主要结构就是Transformer中的Encoder,每个word token经过BERT都可以得到一个contextualized embedding。BERT的训练主要分成两个部分:首先是pre-training过程,这是一个无监督的过程,可以利用大量无标注的语料进行pre-traininig;然后是根据特定downstream task的fine-tuning过程。
BERT在pre-training阶段主要进行了两个任务,它们分别是MLM(Masked Language Modelling)和NSP(Next Sentence Prediction)。
-
MLM随机将输入的token embedding(这个embedding是通过WordPiece算法得到的) mask掉15%(所谓mask掉就是将原来的token embedding换成一个表示[mask]的embedding),然后根据这些被mask掉的token的word embedding去判断原来的这个token是什么单词。但是这样处理存在以下问题: 1)pre-training会使用到[mask]这个token embedding,但是在fine-tuning阶段不会有这个token embedding;2) 专门的[mask] token embedding会泄漏对哪个token进行预测这一信息。为了解决这些问题,如果某个input token需要被mask掉,其对应的token embedding有80%的概率替换成[mask]这一token embedding,有10%的概率为任意一个其它(不包括它自己和[mask])的token embedding,还有10%的概率认为它原来的token embedding。
![image]()
-
NSP会将两个sentence作为BERT的输入,然后判断第二个sentence是不是第一个sentence的下一句。在进行MLM任务时,我们用到了[mask]这个特殊的token,在NSP任务中,我们会用到另外两个特殊的token,它们分别是[cls]合适[sep]。[sep]用来分隔开两个不同的sentence,而[cls]token的work embedding将用来分类。ViT(Vision Transfomer)就借鉴了BERT的这一处理,通过[cls]token的embedding来做分类。
![image]()
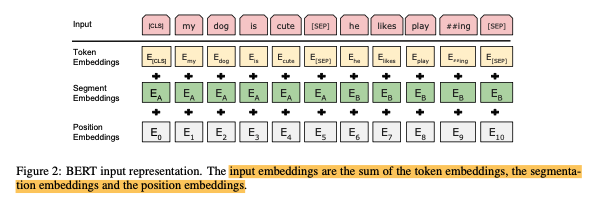
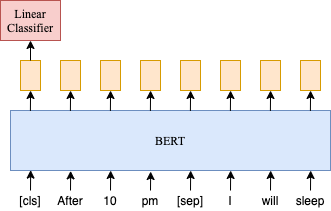
下面是阅读BERT论文过程记录的一些细节:
We use a gelu acti- vation (Hendrycks and Gimpel, 2016) rather than the standard relu, following OpenAI GPT. The training loss is the sum of the mean masked LM likelihood and the mean next sentence prediction likelihood. (1. 使用gelu激活函数;2. 同时进行MLM和NSP任务)
Longer sequences are disproportionately expensive because attention is quadratic to the sequence length. To speed up pretraing in our experiments, we pre-train the model with sequence length of 128 for 90% of the steps. Then, we train the rest 10% of the steps of sequence of 512 to learn the positional embeddings. (1. 不同于Transfomer中的position embedding, BERT的position embedding是学习得到的;2. 使用更长的序列学习position embedding)
GPT
GPT是Generative Pre-trained Transformer的缩写。和BERT相同的是,GPT也是采用无监督pre-training+针对特定下游任务进行fine-tuning的训练策略。和BERT不同的是,GPT是unidirectional,而不是bidirectional。BERT是google出品的,GPT系列是OpenAI出品的。
关于GPT,推荐阅读以下资料:
- OpenAI GPT-1:《Improving Language Understanding with Unsupervised Learning》
- OpenAI GPT-2:《Better Language Models and Their Implications》
GPT-2是在40GB的Internet语料上采用预测下一个单词的任务进行训练得到的,它有15亿参数(GPT-3有1750亿参数)。GPT-2相当于是个大型GPT,其参数量是GPT的10倍多,用于训练GPT-2的数据也是用于训练GPT的10倍多。
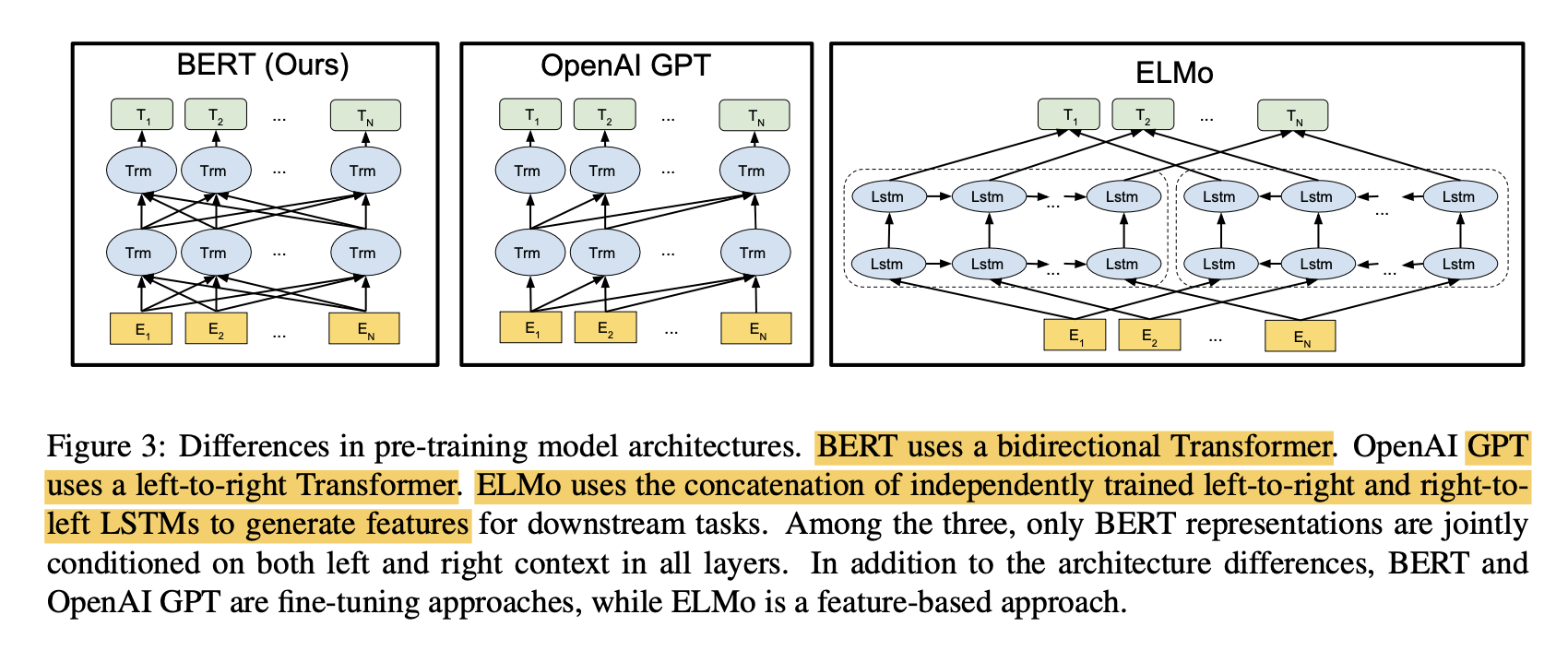
BERT、GPT和ELMo的比较
ELMo是Embeddings from Language Models的缩写,我们用BERT论文中的一张图来说明这三个模型的区别和联系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号