
Effective Python 并行与并发
本文是对《Effective Python》37、38、39条中关于python 多线程的总结。主要分为以下3个部分
- 并发与并行
- 多线程的数据共享和竞态
- 在阻塞式I/O任务中使用Queue来协调多线程
1 并发(concurrency)和并行(parallelism)
并发:计算机似乎在同一时间做了多个任务,但实际上只是在多个任务间快速切换。比如一个单核CPU上在1分钟处理了4个任务,实际上只是每个任务执行1s后就换另外一个任务。
并行:计算机确实在同一时间做着多个任务。比如在4核CPU上,每个核心处理一个任务,1分钟过后,每个任务都做了1分钟。而上面并发的例子中,每个任务只做了1/4分钟。
并行与并发的关键区别,就在于能不能提速(speedup)。
关于并发核并行的区别,geeksforgeeks总结得较好:

2 多线程的数据共享
比如有个程序,它做的操作只有一条cnt = cnt + 1,如果将这个程序写成多线程(假设两个),那么可能最后的输出是1,而不是2。
要理解背后的原因,需要将cnt = cnt + 1写成汇编形式
// 将共享变了cnt加载到accumulator register
movq cnt(%rip), %rdx
// 加1操作
addq %eax
// 将更行的值给回共享变量cnt
movq %eax, cnt(%rip)
如果执行顺序为:线程1执行step1,线程2执行step1,线程1执行step2,线程2执行step2,线程1执行step3,线程2执行step3,结果显然为1。为了解决多线程的数据竞争,需要对数据合理加锁。
对于上述多线程中的race condition问题,可以阅读CSAPP 12.5节《Synchronizing Threads with Semaphores》
实操一下《Effective Python》中的例子
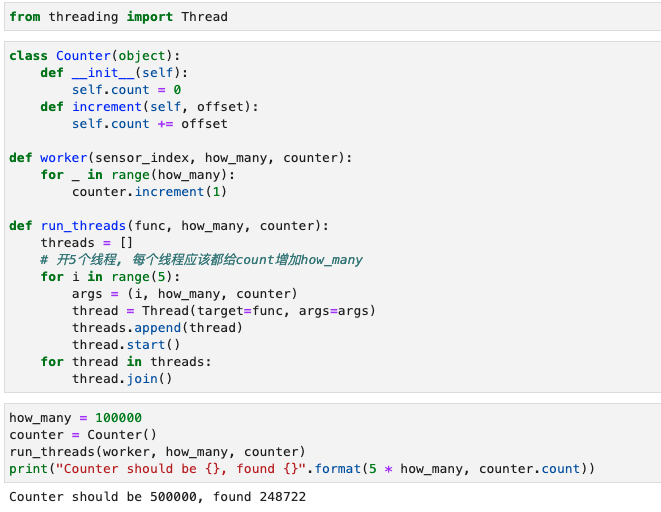
这里值得注意的是,虽然how_many设置为10000时,得到的结果并不是5倍的how_many,但是how_many很小时,比如1000,结果确实是5倍的how_many。这是因为第二个线程开始时,第一个线程已经完成了worker内的计算。
为了解决上述竞态问题,下面是经过数据加锁的代码,threading中的Lock类是用标准方法实现的互斥锁(mutex):
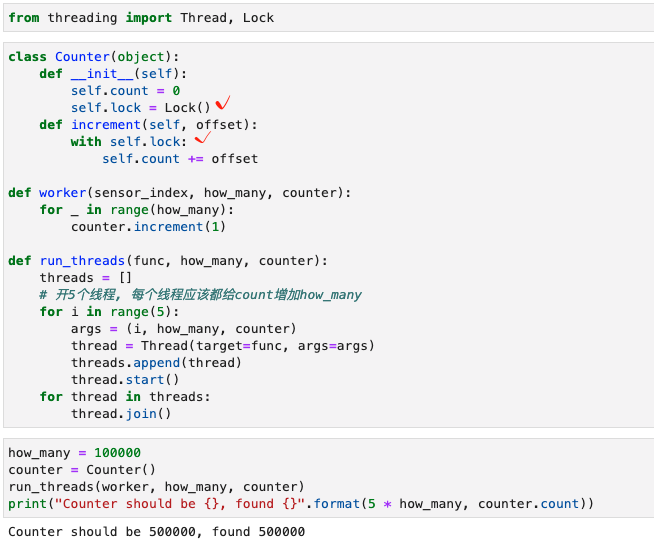
试了一下在counter.increment(1)处加锁,但是没有效果。
3 在阻塞式I/O中使用多线程
在做一些项目的过程中,会遇到有以下特点的任务:
- 整个任务可以划分成按序执行的多个阶段(可以表示成pipeline):
Task = stage1-> stage2 -> ... -> stageN - 其中有些stage是阻塞式I/O操作
举个例子:Stage1: 从网络下载图片;Stage 2: 判断图片是否包含小动物; Stage 3: 将包含小动物的图像通过网络传递给客户A。这个过程中Stage 1和Stage 3都是非计算密集型的I/O操作,它可能只需要一条接收或发送语句,接下来等待得到数据或对方接收到数据就行了,主要的计算在Stage 2中。
面对具有这样特点的任务,就可以考虑使用Pyhton中的多线程来提高速度。(注: Python中由于GIL的存在,如果这些stage都是计算密集型的任务,使用多线程无法提高效率,在3.2中我们会具体解释)
3.1 Queue
处理上述特点任务时,我们通常会使用Queue来协调各线程间的工作,下面简单介绍一下内置queue模块中的Queue类。
- task_done()方法:标识队列中的某个元素已经出队列了(某个任务已经完成了)
- join()方法:阻塞,直到队列中所有元素都出队列了(队列为空)
如果队列获取某个元素,并对其执行一系列操作后,并未调用task_done()进行标识,调用join()会一直阻塞。
举个例子,下面这段代码永远不会执行最后一句print语句
from queue import Queue
q = Queue()
for i in range(10):
q.put(i)
for i in range(10):
q.get()
# q.task_done()
q.join()
print("Ohh, Finished q.join")
3.2 为什么这类任务可以考虑多线程
还是举《Effective Python》中的例子,考虑一个3阶段的任务:1)从网络下载图片download;2)对图片进行处理resize;3)将图片上传upload。该任务有阻塞式I/O操作(图片还没完全下载下来,下一个步骤就进行不了)。
如果在编写代码时,将download、resize和upload3个函数进行如下实现

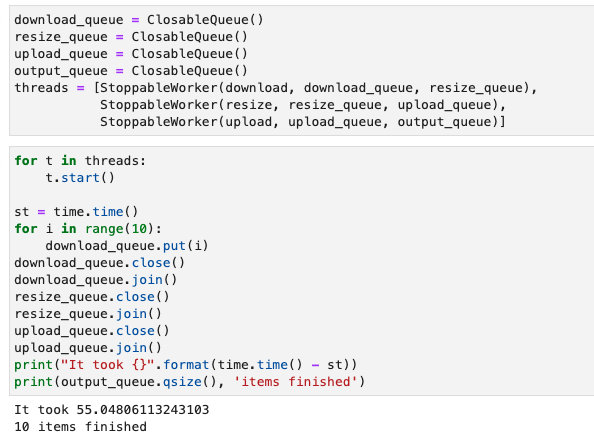
运行代码,得到的计算时间满足T = 10 + (N - 1) * 5。看到这个结果,有人可能会纳闷,不是说Python中由于GIL的存在,多个线程只有一个能获得对Python Interpreter的锁,相当于只使用了一个CPU核心吗,这样应该无法提速啊。其实应该注意到time.sleep()操作应该是不占用CPU的,sleep的过程和阻塞式I/O的等待过程类似,而这正是多线程为什么在这类任务上可以提高效率的原因。
如果将这3个函数实现为计算密集型版本(必须使用CPU),并重新计算花费的时间,在这种情况下,使用多线程就不能带来速度上的提升了。
def download(item):
number = 18769139
res = 0
for i in range(1, number + 1):
if number % i == 0:
res += 1
def resize(item):
number = 18769139 * 3
res = 0
for i in range(1, number + 1):
if number % i == 0:
res += 1
def upload(item):
number = 18769139 * 5
res = 0
for i in range(1, number + 1):
if number % i == 0:
res += 1

