基于GCN的人脸聚类算法2——GCN-VE
简介
L-GCN在构造子图和进行linke merge的过程中采用了一些启发式操作,比如1-hop和2-hop个数(K1、K2)的选择以及merge中截断阈值的选择,这些启发式的操作往往很难达到最优甚至局部最优。此外,L-GCN为每个节点都构造一个子图,子图间的overlap较大,从计算效率的角度看也有待改进。针对上述两个问题,GCN-VE提出一个完全基于学习的人脸聚类框架,在聚类效果和计算效率上都取得了很大提升。
如下图所示,GCN-VE可以分成两个阶段。第一阶段是vertex confidence estimation,它的输入是所有节点构成的KNN affinity graph,输出是每个节点属于某一特定cluster的概率;第二阶段是edge connectivity estimation,它的输入是以某个节点为pivot形成的子图,输出是子图中其它点于pivot存在连边的概率。第二阶段和前面介绍的L-GCN在功能上是一样的,因此处理方式也有相同之处,比如通过减去pivot特征来编码其它点和pivot的关系。
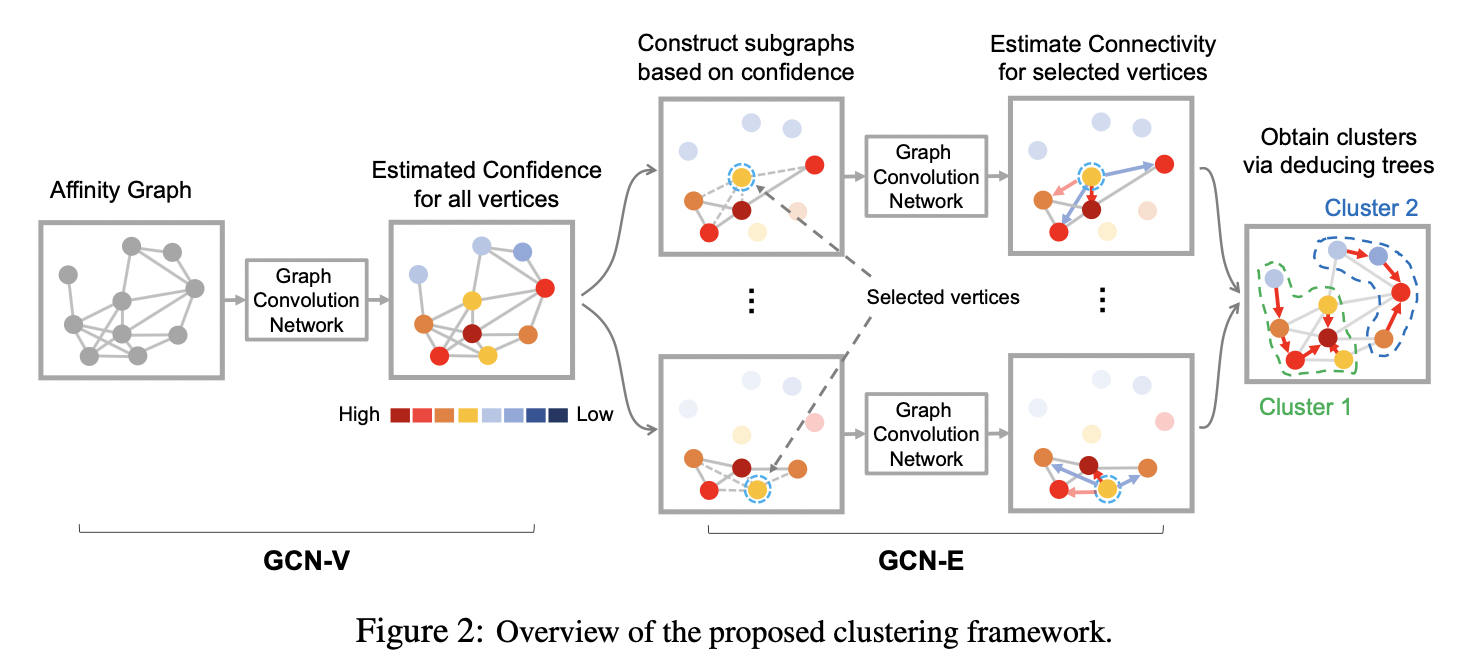
GCN-V模块
GCN-V模块的输入是一张affinity graph,它包含所有\(N\)个节点,每个节点只和它的\(KNN\)存在连边。节点最初的特征为它所代表的人脸图像特征,经GCN-V进行特征变换后,对每个节点的vertex confidence进行回归。
节点的ground truth vertex confidence通过公式\(c_{i}=\frac{1}{\left|\mathcal{N}_{i}\right|} \sum_{v_{j} \in \mathcal{N}_{i}}\left(\mathbb{1}_{y_{j}=y_{i}}-\mathbb{1}_{y_{j} \neq y_{i}}\right) \cdot a_{i, j}\)计算得到,其中\(a_{i,j}\)表示节点i和节点j的特征相似度。训练阶段的损失函数为预测值和ground truth的MSE(Mean Square Loss):\(\mathcal{L}_{V}=\frac{1}{N} \sum_{i=1}^{N}\left|c_{i}-c_{i}^{\prime}\right|^{2}\)。
GCN-E模块
GCN-E和L-GCN的功能都是预测边的存在性,但GCN-E和L-GCN存在以下不同点:
- L-GCN为所有节点构造子图;GCN-E只对vertex confidence高于一定阈值的节点构造子图。这样可以减少需要推理的子图数量,避免子图间存在过多overlap,提高计算效率。但是阈值不能过大,过大则存在子图数量过少,存在节点不属于任何子图的情况。
- 构造子图的方式不同,GCN-E围绕pivot,选取confidence比它还高的邻居点形成子图。
- 损失函数不同,L-GCN使用cross-entropy损失,GCN-E使用MSE损失。
