数据结构——希尔排序(使用Java)
一、简介
希尔排序是希尔(Donald Shell)于1959年提出的一种排序算法。而该排序法直接以发明者命名。其排序的原理有点像插入排序,但他可以减少数据搬运的次数。排序的原则是将数据区分割成特定间隔的几个小块,以插入排序法排完区域块内的数据后再渐渐减少间隔距离
二、核心思想
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量
![]() =1(
=1(
![]() <
<
![]() …<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
该方法实质上是一种分组插入方法
比较相隔较远距离(称为增量)的数,使得数移动时能跨过多个元素,则进行一次比[2] 较就可能消除多个元素交换。D.L.shell于1959年在以他名字命名的排序算法中实现了这一思想。算法先将要排序的一组数按某个增量d分成若干组,每组中记录的下标相差d.对每组中全部元素进行排序,然后再用一个较小的增量对它进行,在每组中再进行排序。当增量减到1时,整个要排序的数被分成一组,排序完成。
一般的初次取序列的一半为增量,以后每次减半,直到增量为1。
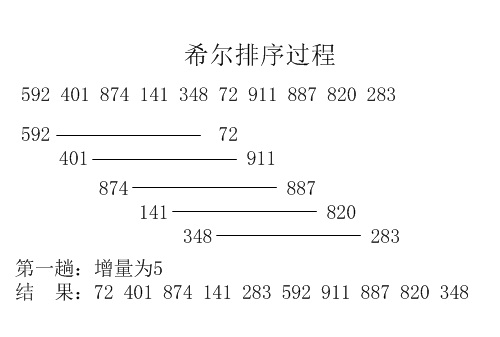
三、实例说明

四、核心代码


1 private static void Shell(int[] a) { 2 int n=a.length;//数组长度 3 int jemp=n/2;//增量,用来记录间隔位移量 4 int temp=0;//用来交换数据 5 while(jemp!=0){//将增量逐渐缩小到间隔位移量为1 6 for (int i = jemp; i < n; i++) { 7 temp=a[i]; 8 int j=i-jemp; 9 while (j>=0&&a[j]>temp) {//使用插入排序方法进行交换 10 a[j+jemp]=a[j]; 11 j=j-jemp; 12 } 13 a[j+jemp]=temp; 14 } 15 jemp=jemp/2;//控制循环数 16 } 17 } 18 public static void main(String[] args) { 19 int[]a=new int[10]; 20 Random ran=new Random(); 21 System.out.println("排序前数组"); 22 //使用Random方法生成一个随机数组并输出 23 for (int i = 0; i < a.length; i++) { 24 a[i]=ran.nextInt(100); 25 System.out.print(a[i]+" "); 26 } 27 //调用排序方法 28 Shell(a); 29 //输出排序后方法 30 System.out.println("排序后数组"); 31 for (int i = 0; i < a.length; i++) { 32 33 System.out.print(a[i]+" "); 34 } 35 }
五、算法分析
- 任何情况下时间复杂度均为O(n3/2)。
- 希尔排序和插入排序均是稳定排序。
- 只需一个额外空间,所以空间复杂度是最佳的。
- 此算法适用于数据大部分都已经排完的情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号