
AI 预测:基于流计算 Oceanus(Flink) 实现病症的实时预测
 带你轻松构建机器学习全流程!
带你轻松构建机器学习全流程!
作者:于乐,腾讯 CSIG 工程师
一、方案描述
1.1 概述
近年来,人工智能的风潮为医疗行业带来一场全新革命,AI 在辅助诊断、疾病预测、疗法选择等方面发挥着重要作用。机器学习领域的特征选择和有监督学习建模方法越来越多地用于疾病预测和辅助诊断,常用的算法如决策树、随机森林、逻辑回归等。乳腺癌是目前发病率仅次于肺癌的常见癌症,机器学习算法能够分析已有的临床乳腺癌数据,得到与乳腺癌发病关系最密切的特征,这能够极大地帮助医生进行早期诊断,及时拯救患者。本方案结合智能钛机器学习平台(TI-ONE)、智能钛弹性模型服务(TI-EMS)、腾讯云流计算 Oceanus(Flink)、消息队列 CKafka、云数据仓库 ClickHouse、对象存储(COS)针对乳腺癌预测案例使用决策树分类算法实现全流程解决方案,包括离线模型训练、实时特征工程及实时在线预测功能。

1.2 方案架构
首先由 TI-ONE 进行离线模型训练,将模型文件存放在 COS 上,然后由 TI-EMS 将模型文件封装成一个 PMML 模型服务供流计算 Oceanus 调用。流计算 Oceanus 利用 Datagen Connector 模拟实时生成特征数据后存放在 CKafka 上,之后流计算 Oceanus 取 CKafka 的特征数据经过数据转换传入到 TI-EMS 的 PMML 模型服务中调用决策树分类模型并返回预测结果,最后将预测结果存储在 ClickHouse 中。

涉及产品列表:
-
流计算 Oceanus(Flink)
-
智能钛机器学习平台(TI-ONE)
-
智能钛弹性模型服务(TI-EMS)
-
消息队列 CKafka
-
云数据仓库 ClickHouse
-
对象存储(COS)
二、前置准备
2.1 创建私有网络 VPC
私有网络(VPC)是一块您在腾讯云上自定义的逻辑隔离网络空间,在构建流计算 Oceanus、CKafka、COS、ClickHouse 集群等服务时选择的网络建议选择同一个 VPC,网络才能互通。否则需要使用对等连接、NAT 网关、VPN 等方式打通网络。私有网络 VPC 创建步骤请参考 帮助文档 [1] 。
2.2 创建流计算 Oceanus 集群
流计算 Oceanus 是大数据产品生态体系的实时化分析利器,是基于 Apache Flink 构建的具备一站开发、无缝连接、亚秒延时、低廉成本、安全稳定等特点的企业级实时大数据分析平台。流计算 Oceanus 以实现企业数据价值最大化为目标,加速企业实时化数字化的建设进程。
在流计算Oceanus 控制台 [2] 的【集群管理】->【新建集群】页面创建集群,选择地域、可用区、VPC、日志、存储,设置初始密码等。VPC 及子网使用刚刚创建好的网络。创建完后 Flink 的集群如下:

2.3 创建 CKafka 实例
进入 CKafka 控制台 [3],选择左侧【实例列表】,单击【新建】进行购买,注意【地域】需选择 VPC 所在地域,VPC 选择及子网选择之前创建的 VPC 和子网。新建成功后,单击实例进入实例详情页面,单击【topic 管理】新建 topic。
2.4 创建 COS 实例
进入 COS 控制台 [4],选择左侧【存储桶列表】,单击【创建存储桶】,【所属地域】选择 VPC 所在地域,具体操作细节可参考 COS 控制台快速入门 [5]。
2.5 创建 ClickHouse 集群
进入 ClickHouse 控制台 [6],单击【新建集群】创建 ClickHouse 集群,注意地域、可用区和网络的选择。创建成功之后选择一台与其同 VPC 的 CVM 进入,在该 CVM 下下载 ClickHouse 客户端,创建数据库和表。具体操作可参考 ClickHouse 快速入门 [7]。
# 下载 ClickHouse-Client 命令wget https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/clickhouse-client-20.7.2.30-2.noarch.rpmwget https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/clickhouse-common-static-20.7.2.30-2.x86_64.rpm# 安装客户端rpm -ivh *.rpm# 使用 tcp 端口登陆 ClickHouse 集群,IP 地址可通过控制台查看clickhouse-client -hxxx.xxx.xxx.xxx --port 9000
-- 创建数据库CREATE DATABASE IF NOT EXISTS testdb ON CLUSTER default_cluster;-- 创建表CREATE TABLE testdb.model_predict_result_1 on cluster default_cluster (res String,Sign Int8) ENGINE = ReplicatedCollapsingMergeTree('/clickhouse/tables/{layer}-{shard}/testdb/model_predict_result_1', '{replica}',Sign) ORDER BY res;
2.6 注册开通 TI-ONE 服务
智能钛机器学习平台是为 AI 工程师打造的一站式机器学习服务平台,为用户提供从数据预处理、模型构建、模型训练、模型评估到模型服务的全流程开发及部署支持。
进入 TI-ONE 控制台 [8],在弹出的页面上开通【角色授权】。
-
单击【前往访问管理】,页面将跳转至访问管理控制台。
-
单击【同意授权】,即可创建服务预设角色并授予智能钛机器学习平台相关权限。
角色授权开通后,返回 TI-ONE 控制台 [8],开通所需地区的后付费计费模式。 具体步骤可参考 TI-ONE 的官方文档 注册与开通服务 [9]。
2.7 注册开通 TI-EMS 服务
智能钛弹性模型服务(Tencent Intelligence Elastic Model Service,TI-EMS)是具备虚拟化异构算力和弹性扩缩容能力的无服务器化在线推理平台。
角色授权: 进入 TI-EMS 控制台 [10],参考上面步骤进行【角色授权】 创建专用资源组: TI-EMS 平台目前提供公共资源组和专用资源组两种模式,关于两种模式的优缺点可参见官网文档 资源组管理 [11]。本例子通过流计算 Oceanus 调用 TI-EMS 服务,需打通相对应的 VPC,因此需选用专用资源组。关于专用资源组的开通方式可参见官网文档 资源组管理 [11]。
三、方案实现
本文通过 TI-ONE 平台,利用决策树算法搭建乳腺癌预测模型(决策树分类模型),将模型结果保存在 COS 上 (用户也可以自己在本地训练完成后将训练好的模型文件保存在本地或者 COS,之后通过 TI-EMS 创建模型服务配置即可调用)。然后由流计算 Oceanus 模拟生成实时特征数据,以 CSV 格式存储在 CKafka,再通过流计算 Oceanus 取 CKafka 的特征数据作为入参,结合 TI-EMS 进行乳腺癌模型的实时调用,预测结果保存在 ClickHouse 中。
3.1 离线模型训练
3.1.1 数据集介绍
本次任务我们采用公开的 乳腺癌数据集 [12],该数据集共包含 569 个样本,其中 357 个阳性(y = 1)样本,212 个阴性(y = 0)样本;每个样本有 32 个特征,但本次实验中选取其中 10 个特征。数据信息及模型训练流程请参考 TI-ONE 最佳实践 乳腺癌预测 [13]。数据集具体字段信息如下:
| 特征和标签(Attribute) | 取值范围(domain) |
| Clump Thickness | 0 ≤ n ≤ 10 |
| Uniformity of Cell Size | 0 ≤ n ≤ 10 |
| Uniformity of Cell Shape | 0 ≤ n ≤ 10 |
| Marginal Adhsion | 0 ≤ n ≤ 10 |
| Single Epithelial Cell Size | 0 ≤ n ≤ 10 |
| Bare Nuclei | 0 ≤ n ≤ 10 |
| Bland Chromation | 0 ≤ n ≤ 10 |
| Normal Nucleoli | 0 ≤ n ≤ 10 |
| Mitoses | 0 ≤ n ≤ 10 |
| (标签y)Class | 0 , 1 |
数据集具体内容抽样展示如下(前9列:特征,第10列:标签):
| 列1 | 列2 | 列3 | 列4 | 列5 | 列6 | 列7 | 列8 | 列9 | 列10 |
| 3 | 2 | 3 | 0 | 0 | 2 | 1 | 0 | 1 | 1 |
| 4 | 1 | 3 | 0 | 1 | 0 | 1 | 4 | 1 | 0 |
| 4 | 1 | 7 | 0 | 1 | 1 | 0 | 1 | 1 | 1 |
3.1.2 离线模型训练
模型训练: 进入 TI-ONE 控制台 [8],点击左侧【工程列表】,单击【新建工程】,【COS Bucket】选择之前创建好的 COS。进入【工作流编辑页面】,按需拖拽对应的输入、算法、输出等模块到右侧页面即可快速构建一个完整的模型训练框架,具体构建方法可参考官网文档 使用可视化建模构建模型 [14]。 当然,用户也可以自行编写代码上传到【Notebook】页面进行模型训练,具体请参考官网 使用 Notebook 构建模型 [15],另外也可以 使用 TI SDK 构建模型 [16]。

模型效果: 运行成功后,右键单击【二分类任务评估】>【评估指标】,即可查看模型效果。
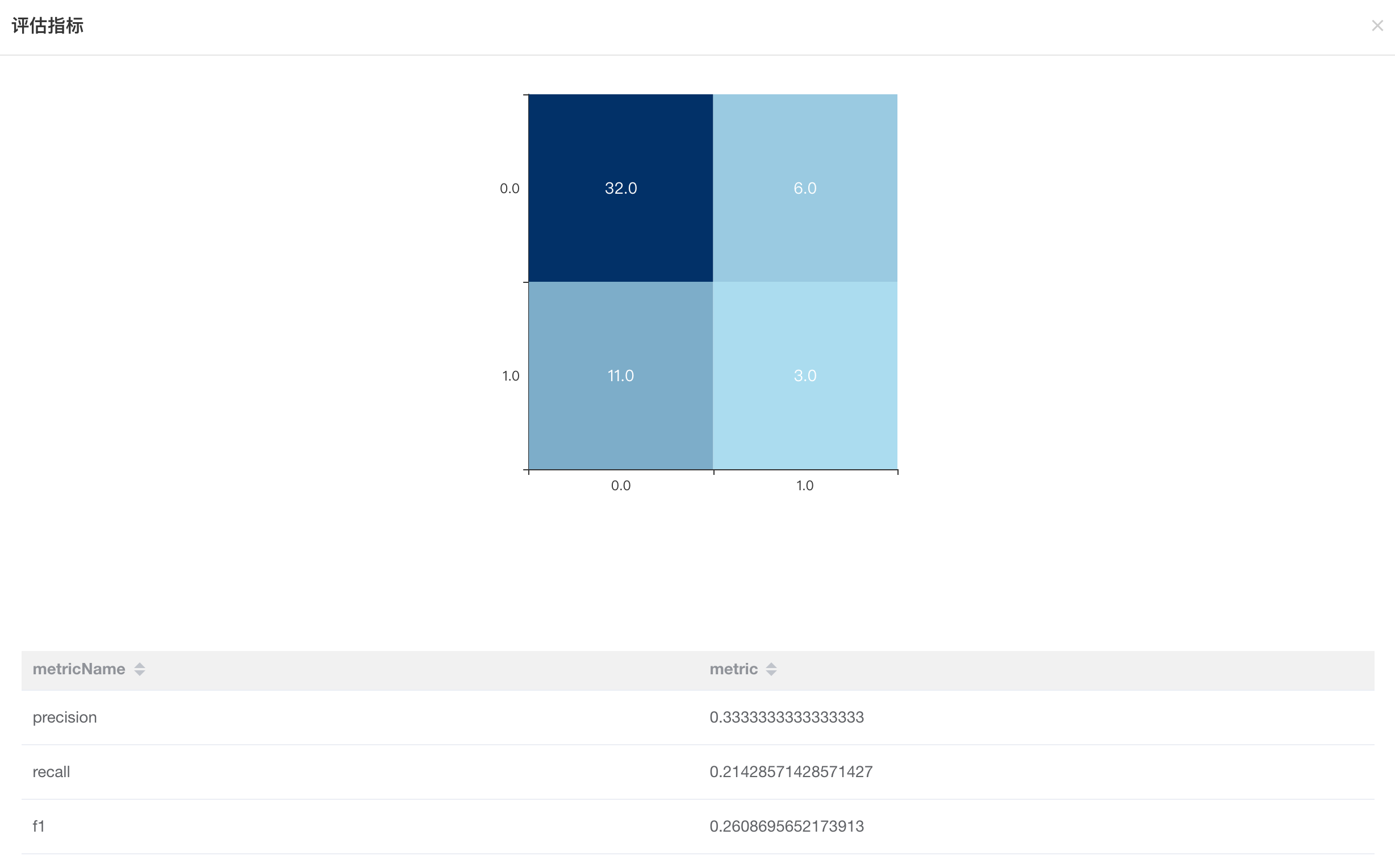
模型保存: 右键单击模型文件(【决策树分类】左侧小圆圈),点击【模型操作】>【保存到模型仓库】,保存成功后返回【模型仓库】页面,查看保存的模型服务。

3.2 实时特征工程
本示例基于流计算 Oceanus SQL 作业生成,使用 Datagen 连接器模拟生成实时特征数据,并将结果以 CSV 格式存储在 CKafka 中,供之后进行模型调用。 用户可以根据实际业务情况自行选择 SQL、ETL、JAR 作业方式进行实时特征数据的输出。
3.2.1 创建 Source
-- random source 用于模拟患者病历实时特征数据CREATE TABLE random_source (ClumpThickness INT,UniformityOfCellSize INT,UniformityOfCellShape INT,MarginalAdhsion INT,SingleEpithelialCellSize INT,BareNuclei INT,BlandChromation INT,NormalNucleoli INT,Mitoses INT) WITH ('connector' = 'datagen','rows-per-second'='1', -- 每秒产生的数据条数'fields.ClumpThickness.kind'='random', -- 无界的随机数'fields.ClumpThickness.min'='0', -- 随机数的最小值'fields.ClumpThickness.max'='10', -- 随机数的最大值'fields.UniformityOfCellSize.kind'='random', -- 无界的随机数'fields.UniformityOfCellSize.min'='0', -- 随机数的最小值'fields.UniformityOfCellSize.max'='10', -- 随机数的最大值'fields.UniformityOfCellShape.kind'='random', -- 无界的随机数'fields.UniformityOfCellShape.min'='0', -- 随机数的最小值'fields.UniformityOfCellShape.max'='10', -- 随机数的最大值'fields.MarginalAdhsion.kind'='random', -- 无界的随机数'fields.MarginalAdhsion.min'='0', -- 随机数的最小值'fields.MarginalAdhsion.max'='10', -- 随机数的最大值'fields.SingleEpithelialCellSize.kind'='random', -- 无界的随机数'fields.SingleEpithelialCellSize.min'='0', -- 随机数的最小值'fields.SingleEpithelialCellSize.max'='10', -- 随机数的最大值'fields.BareNuclei.kind'='random', -- 无界的随机数'fields.BareNuclei.min'='0', -- 随机数的最小值'fields.BareNuclei.max'='10', -- 随机数的最大值'fields.BlandChromation.kind'='random', -- 无界的随机数'fields.BlandChromation.min'='0', -- 随机数的最小值'fields.BlandChromation.max'='10', -- 随机数的最大值'fields.NormalNucleoli.kind'='random', -- 无界的随机数'fields.NormalNucleoli.min'='0', -- 随机数的最小值'fields.NormalNucleoli.max'='10', -- 随机数的最大值'fields.Mitoses.kind'='random', -- 无界的随机数'fields.Mitoses.min'='0', -- 随机数的最小值'fields.Mitoses.max'='10' -- 随机数的最大值);
3.2.2 创建 Sink
CREATE TABLE `KafkaSink` (ClumpThickness INT,UniformityOfCellSize INT,UniformityOfCellShape INT,MarginalAdhsion INT,SingleEpithelialCellSize INT,BareNuclei INT,BlandChromation INT,NormalNucleoli INT,Mitoses INT) WITH ('connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector'topic' = 'topic-decision-tree-predict-1', -- 替换为您要消费的 Topic'properties.bootstrap.servers' = '172.28.28.211:9092', -- 替换为您的 Kafka 连接地址'properties.group.id' = 'RealTimeFeatures', -- 必选参数, 一定要指定 Group ID'format' = 'csv');
3.2.3 编写业务 SQL
INSERT INTO `KafkaSink`SELECT * FROM `random_source`
3.2.4 选择 Connector
点击【作业参数】,在【内置 Connector】选择 flink-connector-kafka,点击【保存】>【发布草稿】运行作业。
3.2.5 查询数据
进入 CKafka 控制台 [3],选择相应的 CKafka 示例进入,单击【topic 管理】,选择对应的 topic,查询写入数据。

3.3 实时预测
本示例基于流计算 Oceanus JAR 作业方式演示,首先将存储在 CKafka 的特征数据提取出来,经过简单的数据格式转换发送到 TI-EMS 服务进行模型调用,并将返回结果存储在 ClickHouse 中。本示例 使用单一的在线推理服务,用户可根据自己实际需求做负载均衡。
3.3.1 启动模型服务
进入 TI-ONE 控制台 [8],点击左侧【模型仓库】,选择对应的模型服务单击【启动模型服务】,【资源组】选择之前创建好的专用资源组。 创建成功之后返回 TI-EMS 控制台 [10],在左侧的【模型服务】>【在线推理】页面查看所创建的模型服务。

3.3.2 公网调用模型测试
-
单击右侧【更多】>【调用】,创建公网调用地址。

-
启动控制台,新建
data.json文件,在某一文件夹下运行如下代码:
# 请将 <访问地址>/<密钥> 替换为实际的 IP 地址/密钥curl -H "Content-Type: application/json" \-H "x-Auth-Token: <密钥>" \-X POST <访问地址>/v1/models/m:predict -d
data.json 数据格式如下:
{"instances" : [{"_c0": 3, "_c1": 2, "_c2": 3, "_c3": 0, "_c4": 0, "_c5": 2, "_c6": 1, "_c7": 0, "_c8": 1}]}模型调用返回结果如下:
{"predictions": [{"pmml(prediction)":"1","probability(0)":"0.47058823529411764","probability(1)":"0.5294117647058824","prediction":"1.0","label":"1"}]}3.3.3 通过流计算 Oceanus 调用模型服务
除了可以使用公网调用模型外,还可以使用 VPC 方式调用模型。本小节着重介绍如何使用流计算 Oceanus JAR 作业的方式调用模型进行实时预测。
-
本地代码开发、调试。
-
进入流计算Oceanus 控制台 [2],单击左侧【依赖管理】新建依赖并上传 JAR 包。
-
进入【作业管理】页面,创建 JAR 作业,选择之前创建好的流计算 Oceanus 集群。
-
单击【开发调试】指定相应的主程序包和主类,点击【作业调试】,【内置 Connector】选择
flink-connector-clickhouse和flink-connector-kafka。
ClickHouse 数据查询:

Java 代码如下:
import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.common.restartstrategy.RestartStrategies;import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.api.java.utils.ParameterTool;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.CheckpointConfig;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.source.SourceFunction;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import org.apache.flink.table.api.Table;import org.apache.flink.util.Collector;import org.apache.http.HttpEntity;import org.apache.http.HttpResponse;import org.apache.http.client.HttpClient;import org.apache.http.client.methods.HttpPost;import org.apache.http.entity.StringEntity;import org.apache.http.impl.client.HttpClientBuilder;import org.apache.http.util.EntityUtils;import org.apache.kafka.clients.consumer.ConsumerConfig;import org.json.JSONObject;import org.slf4j.LoggerFactory;import org.slf4j.Logger;import java.util.ArrayList;import java.util.Properties;import org.apache.flink.table.api.EnvironmentSettings;import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;public class OnlinePredict {public static final Logger logger = LoggerFactory.getLogger(OnlinePredict.class);public static void main(String[] args) throws Exception {// kafka配置参数解析final ParameterTool parameterTool = ParameterTool.fromPropertiesFile(OnlinePredict.class.getResourceAsStream("/KafkaSource.properties"));// 实例化运行环境EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();StreamExecutionEnvironment streamEnv = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tableEnv = StreamTableEnvironment.create(streamEnv, settings);// checkpoint配置streamEnv.enableCheckpointing(parameterTool.getLong("flink.stream.checkpoint.interval", 30_000));streamEnv.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 重启策略streamEnv.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10_000));// source、transfer、sinkDataStream<String> stringResult = streamEnv.addSource(buildKafkaSource(parameterTool)).flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String paramInput = inputDataTransfer(value);String outputData = sendHttpData(paramInput);out.collect(outputData);}});Table tableResult = tableEnv.fromDataStream(stringResult);tableEnv.createTemporaryView("resultSink",tableResult);tableEnv.executeSql("CREATE TABLE `CKSink` (\n" +" res STRING,\n" +" PRIMARY KEY (`res`) NOT ENFORCED\n" +") WITH (\n" +" 'connector' = 'clickhouse',\n" +" 'url' = 'clickhouse://172.28.1.138:8123',\n" +" 'database-name' = 'testdb',\n" +" 'table-name' = 'model_predict_result_1',\n" +" 'table.collapsing.field' = 'Sign'\n" +")");tableEnv.executeSql("insert into CKSink select * from resultSink");}// kafka sourcepublic static SourceFunction<String> buildKafkaSource(ParameterTool parameterTool) throws Exception {Properties properties = new Properties();properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, parameterTool.get("kafka.source.bootstrap.servers"));properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, parameterTool.get("kafka.source.auto.offset.reset", "latest"));properties.put(ConsumerConfig.GROUP_ID_CONFIG, parameterTool.get("kafka.source.group.id"));FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<String>(parameterTool.get("kafka.source.topic"),new SimpleStringSchema(),properties);consumer.setStartFromGroupOffsets();return consumer;}// kafka 数据格式转换// 返回数据格式:{"instances" : [{"_c0": 3, "_c1": 2, "_c2": 3, "_c3": 0, "_c4": 0, "_c5": 2, "_c6": 1, "_c7": 0, "_c8": 1}]}public static String inputDataTransfer(String value) {String[] input = value.split(",");ArrayList<JSONObject> dataListMap = new ArrayList<JSONObject>();JSONObject jsondata = new JSONObject();for (int i = 0; i < input.length; i++) {jsondata.put("_c" + i, Double.parseDouble(input[i]));}dataListMap.add(jsondata);String param = "{\"instances\":" + dataListMap.toString() + "}";return param;}// TI-EMS 模型在线推理服务调用// 返回数据格式如下:{"predictions": [{"pmml(prediction)":"1","probability(0)":"0.47058823529411764","probability(1)":"0.5294117647058824","prediction":"1.0","label":"1"}]}public static String sendHttpData(String paramJson) throws Exception {String data = null;try {// 请将 xx.xx.xx.xx:xxxx 替换为实际的 IP 地址,参考 3.2.2 图中所示 创建 VPC 调用String url = "http://xx.xx.xx.xx:xxxx/v1/models/m:predict";HttpClient client = HttpClientBuilder.create().build();HttpPost post = new HttpPost(url);post.addHeader("Content-type", "application/json");post.addHeader("Accept", "application/json");// 请将 xxxxxxxxxx 替换为实际密钥,参考 3.2.2 图中所示 创建 VPC 调用post.addHeader("X-AUTH-TOKEN", "xxxxxxxxxx");StringEntity entity = new StringEntity(paramJson, java.nio.charset.Charset.forName("UTF-8"));post.setEntity(entity);HttpResponse response = client.execute(post);// 判断是否正常返回if (response.getStatusLine().getStatusCode() == 200) {// 解析数据HttpEntity resEntity = response.getEntity();data = EntityUtils.toString(resEntity);} else {data = "error input";}System.out.print(data);System.out.println(data);} catch (Throwable e) {logger.error("", e);}return data;}}
Kafka Source 参数配置:
kafka.source.bootstrap.servers=172.28.28.211:9092kafka.source.topic=topic-decision-tree-predict-1kafka.source.group.id=RealTimePredict1kafka.source.auto.offset.reset=latest
POM 依赖:
<properties><flink.version>1.11.0</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-clickhouse</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.11</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!--httpclient--><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.3</version><scope>compile</scope></dependency><dependency><groupId>org.json</groupId><artifactId>json</artifactId><version>20201115</version><scope>compile</scope></dependency></dependencies>
四、总结
-
新版 Flink 1.13 集群无需用户自己选择内置 Connector,平台将自动匹配。
-
除了使用 CKafka 及 ClickHouse 作为数据仓库外,还可以使用 Hive、Mysql、PG 等作为数仓,根据用户实际需求自行选择。
-
本方案最简化了实时特征工程,用户可以根据自身业务需求采用 SQL、JAR、ETL 作业的方式完成实时特征工程。
-
本方案只初始化了一个 PMML 服务提供流计算 Oceanus 调用,如遇数据背压情况可增多 PMML 服务循环调用。
-
TI-ONE、TI-EMS 平台暂时不支持实时训练模型,如需更新模型可以自行编写定时脚本拉取数据在 TI-ONE 平台训练更新。
五、参考地址
[1] VPC 帮助文档:https://cloud.tencent.com/document/product/215/36515
[2] Oceanus 控制台:https://console.cloud.tencent.com/oceanus/job
[3] CKafka 控制台:https://console.cloud.tencent.com/ckafka/overview
[4] COS 控制台:https://console.cloud.tencent.com/cos5
[5] COS 控制台快速入门:https://cloud.tencent.com/document/product/436/38484
[6] ClickHouse 控制台:https://console.cloud.tencent.com/cdwch
[7] ClickHouse 快速入门:https://cloud.tencent.com/document/product/1299/49824
[8] TI-ONE 控制台:https://console.cloud.tencent.com/tione
[9] 注册与开通 TI-ONE 服务:https://cloud.tencent.com/document/product/851/39086
[10] TI-EMS 控制台:https://console.cloud.tencent.com/tiems/overview
[11] TI-EMS 资源组管理:https://cloud.tencent.com/document/product/1120/38968
[12] 乳腺癌数据集:https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/
[13] 乳腺癌预测:https://cloud.tencent.com/document/product/851/35127
[14] 使用可视化建模构建模型:https://cloud.tencent.com/document/product/851/44432
[15] 使用 Notebook 构建模型:https://cloud.tencent.com/document/product/851/44434
[16] 使用 TI SDK 构建模型:https://cloud.tencent.com/document/product/851/44435 
关注“腾讯云大数据”公众号,技术交流、最新活动、服务专享一站 Get~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号