
Greenplum 性能优化之路 --(三)ANALYZE
一、为什么需要 ANALYZE
首先介绍下 RBO 和 CBO,这是数据库引擎在执行 SQL 语句时的2种不同的优化策略。
RBO(Rule-Based Optimizer)
基于规则的优化器,就是优化器在优化查询计划的时候,是根据预先设置好的规则进行的,这些规则无法灵活改变。举个例子,索引优先于扫描,这是一个规则,优化器在遇到所有可以利用索引的地方,都不会选择扫描。这在多数情况下是正确的,但也不完全如此:
比如 一张个人信息表中性别栏目加上索引,由于性别是只有2个值的枚举类,也就是常说的基数非常低的列,在这种列上使用索引往往效果还不如扫描
因此 RBO 的优化方式是死板的,粗放的,目前已逐渐被 CBO 方式取代。
CBO(Cost Based Optimizer)
基于代价的优化器,就是优化器在优化查询计划的时候,是根据动态计算出来的 Cost(代价)来判断如何进行选择。那如何计算代价呢?这里一般是基于代价模型和统计信息,代价模型是否合理,统计信息是否准确都会影响优化的效果。
还是拿上面员工性别统计为例,在 CBO 的优化方式下,物理计划就不会选择走索引。当然上面的例子比较简单,在 Greenplum 运行的复杂 SQL 中,优化器最核心的还是在 scan 和 join 的各种实现方式中做出选择,这才是能大幅提升性能的关键点。
前面提到 CBO 需要一个代价模型和统计信息,代价模型和规则一样,需要预先设置好,那统计信息是如何收集的?多数基于 CBO 优化的计算引擎,包括 Greenplum,Oracle,Hive,Spark 等都类似,除了可以按一定规则自动收集统计信息外,还都支持手动输入命令进行收集,通常这个命令都叫 ANALYZE。
结论:由于 CBO 优化的需求,因此我们需要使用 ANALYZE 命令去收集统计信息。
二、ANALYZE 怎么使用
说明
ANALYZE 是 Greenplum 提供的收集统计信息的命令。
ANALYZE 支持三种粒度,列,表,库,如下:
限制
ANALYZE 会给目标表加 SHARE UPDATE EXCLUSIVE 锁,也就是与 UPDATE,DELETE,还有 DDL 语句冲突。
速度
ANALYZE 是一种采样统计算法,通常不会扫描表中所有的数据,但是对于大表,也仍会消耗一定的时间和计算资源。
采样统计会有精度的问题,因此 Greenplum 也提供了一个参数 default_statistics_target,调整采样的比例。简单说来,这个值设置得越大,采样的数量就越多,准确性就越高,但是消耗的时间和资源也越多。

default_statistics_target.png
直接修改服务器的参数会影响整个集群,通常不建议这样操作。如果确实有需要,可以尝试只修改某列的对应参数,如下:
时机
根据上文所述,ANALYZE 会加锁并且也会消耗系统资源,因此运行命令需要选择合适的时机尽可能少的运行。根据 Greenplum 官网建议,以下3种情况发生后建议运行 ANALYZE
-
批量加载数据后,比如 COPY
-
创建索引之后
-
INSERT, UPDATE, and DELETE 大量数据之后
自动化
除了手动运行,ANALYZE 也可以自动化。实际上默认情况下,我们对空表写入数据后, Greenplum 也会自动帮我们收集统计信息,不过之后在写入数据,就需要手动操作了。
有2个参数可以用来调整自动化收集的时机,gp_autostats_mode 和 gp_autostats_on_change_threshold。gp_autostats_mode 默认是 on_no_stats,也就是如果表还没有统计信息,这时候写入数据会导致自动收集,这之后,无论表数据变化多大,都只能手动收集了。如果将 gp_autostats_mode 修改为 on_change ,就是在数据变化量达到 gp_autostats_on_change_threshold 参数配置的量之后,系统就会自动收集统计信息。
分区表
Greenplum 官网对于分区表的 ANALYZE 专门进行了讲解,其实只要保持默认值,不去修改系统参数 optimizer_analyze_root_partition,那么对于分区表的操作并没有什么不同,直接在 root 表上进行 ANALYZE 即可,系统会自动把所有叶子节点的分区表的统计信息都收集起来。
如果分区表的数目很多,那在 root 表上进行 ANALYZE 可能会非常耗时,通常的分区表都是带有时间维度的,历史的分区表并不会修改,因此单独 ANALYZE 数据发生变化的分区,是更好的实践。
三、统计信息去了哪里
pg_class
表的大小是统计信息里面最直观,也几乎是最重要的,这个信息是放在 pg_catalog.pg_class 系统表中,reltuples 代表元组数(行数),relpages 代表实际占用的 page 数目(Greenplum中一个 page 为32KB)。
需要注意以下3点
1. reltuples 不是准确值,获取表的准确行数还是需要 count。
2. reltuples 和 relpages 需要通过 ANALYZE 进行收集,对于已有数据的表,系统不会自动更新。
3. reltuples 和 relpages 不一定能对齐,比如条数看起来不多的表,实际占用的 page 数目很大,这种一般是由于数据膨胀(bloat)造成,这时候需要 vacuum 等操作。
pg_statistic
关于列的统计信息都是存放在 pg_catalog.pg_statistic 系统表中。其中表的每一列(如果有统计)都会有一行对应的数据。了解并掌握 pg_statistic 的内容,对于深入理解查询优化非常重要。
列的统计信息内容很丰富,但是目的都是让优化器估算出,一个查询条件,能够过滤多少数据。
以下列举了 pg_statistic 的重要字段:

对于 stakindN 字段中的统计方式,这里选择3个最常见的进行说明:
1. STATISTIC_KIND_MCV
高频值,在一个列中出现最频繁的值。
高频值统计在很多场景下都有价值,这里举一个数据倾斜的 hash join 例子,如下代码:
hash join 场景下,我们需要尽可能的把 inner table 构建在内存中,但内存资源是有限的,因此我们需要做出一些选择,什么内容优先放入内存中。如果外表有高频值,那我们可以考虑把高频值对应的内表信息优先放入到内存中,在实践中,Greenplum 是单独构建一个 skew hash table 与 main hash table 并存。
2. STATISTIC_KIND_HISTOGRAM
直方图,使用等频直方图来描述一个列中的数据的分布。
直方图主要用于数据分布不均匀的情况下,对按列过滤后能返回多少数据进行预估。
举个例子,一个有3种产品的订单表,商品 A 很热销,订单量在90%,商品 B 一般,订单量在9%,商品 C 只有1%,则该列的 NDV(Number of Distinct Value)值为3,如果一共有1000000条数据,在没有直方图统计的情况下,如果查询商品 C 的订单,优化器会预计要扫描1000000/3≈330000,因此可能选择全表 scan,如果含有直方图统计,优化器就知道实际上 C 商品可能就几千条数据,因此会选择走索引。当然这个例子很简单,实际情况会复杂很多。
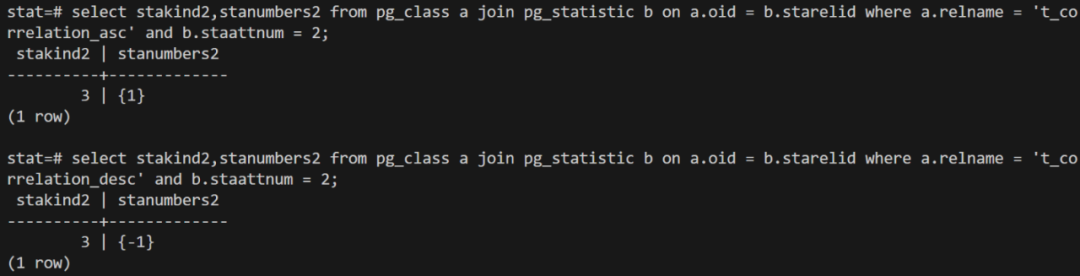
3. STATISTIC_KIND_CORRELATION
相关系数,记录的是当前列未排序的数据分布和排序后的数据分布的相关性。
用于估算索引扫描代价的,统计值在-1到1,值越大,表示相关性越高,也就是使用索引扫描代价越低。
举个例子,初始化如下2张表
在查看表对应的统计信息,可以看出在 number 列,你按升序写入1000个数,该列物理存储的数据实际上就是按升序排序的,反过来降序写入1000个数,由于顺序是相反的,所以相关性是-1
correlation.png
四、例子
以下将会构造一个大小表 join 的场景,来说明统计信息的收集对于查询计划的影响。
1. 初始化表结构和数据:
pg_class 中对应的数据如下:

small_table.png

big_table.png
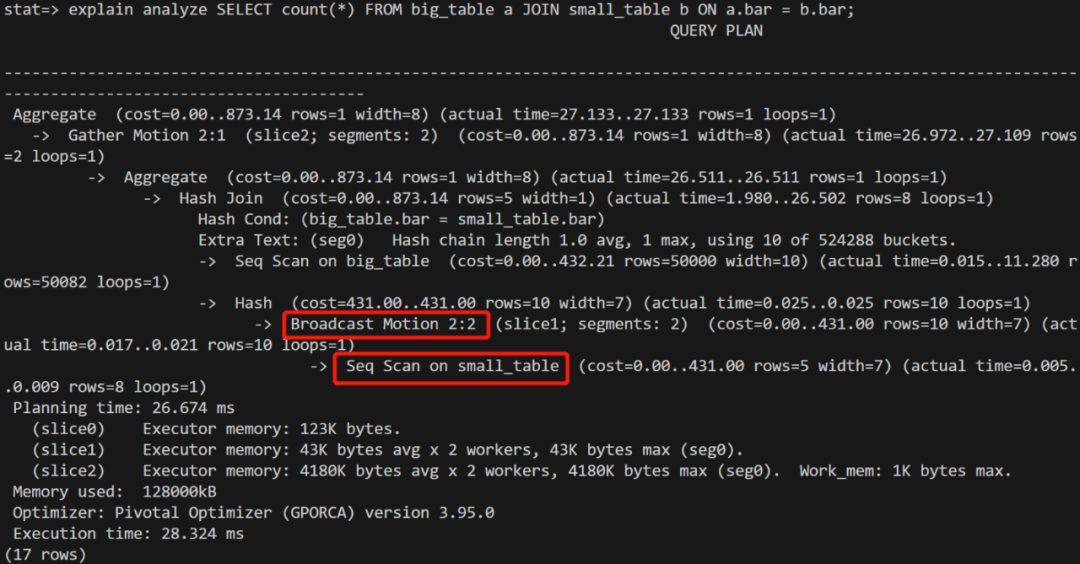
2. 大小表 join
注意为了构造小表广播的场景,这里关联键需要选择非分布键。
explain1.png
3. 给小表插入数据
这里给小表插入数据后,小表的数据量超过大表
在没有 ANALYZE 的情况下,pg_class 中的数据没有发生变化,因此查询计划也没有发生变化。
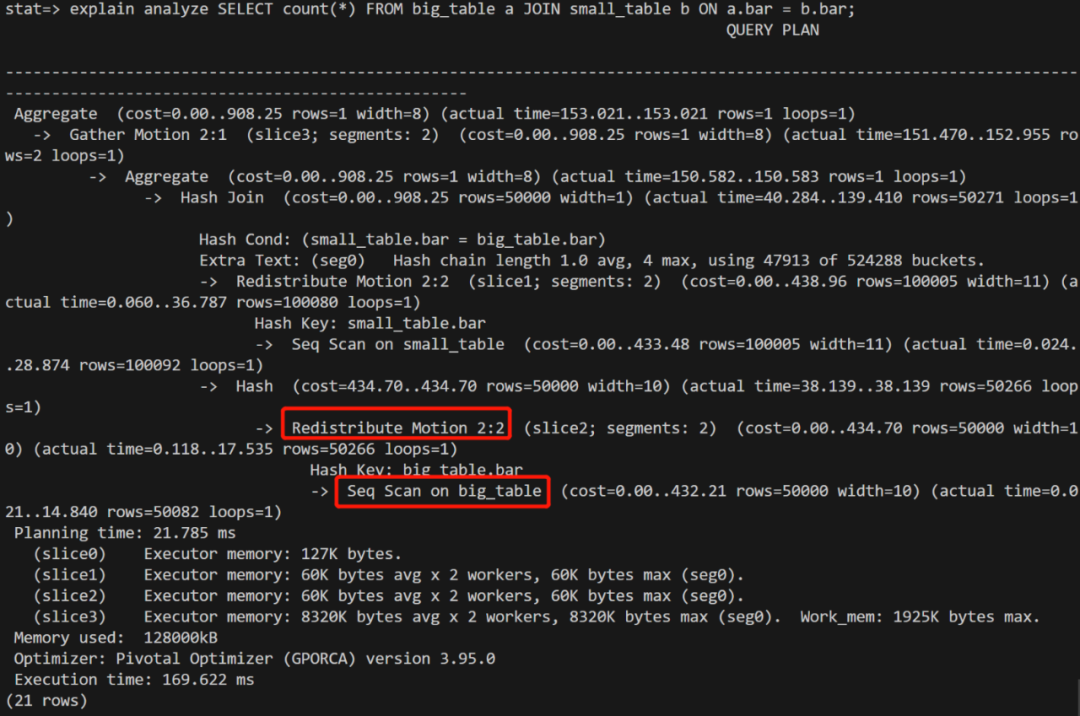
4. 收集统计信息
运行 ANALYZE 收集小表的统计信息,如下:

new_small_table.png
在运行 join 语句,查询计划发生变化:
explain2.png
结论:查询优化器在收到新的统计信息之后,发现是2张数据量差不多的表进行 join,因此选择重分布而不是小表广播。

关注“腾讯云大数据”公众号,技术交流、最新活动、服务专享一站Get~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号