
Windows7下安装pyspark
安装需要如下东西:
java
spark
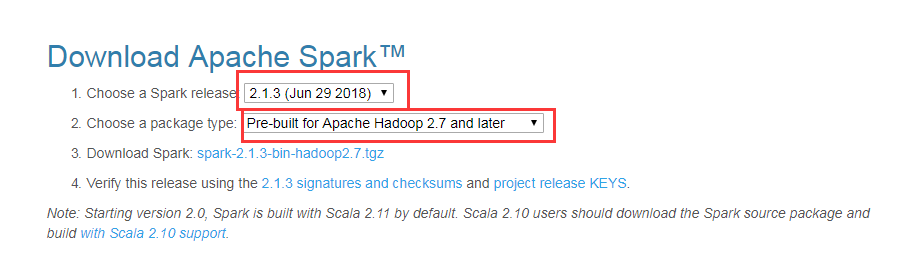
hadoop(版本要与spark的一致,这里都是hadoop2.7)
Anaconda(这个是为了预防python出现api-ms-win-crt-runtime-l1-1-0.dll错误,且安装了vc_redist.2015.exe还无法解决时需要安装)
Anaconda3-2.4.1-Windows-x86_64.exe
python
pycharm
pycharm-community-2016.1.4.exe
安装JDK
** 千万不要用默认路径Program Files,这个有空格后面会很坑!新建路径在C:\Java,Java安装在这里!**
- 新建环境变量名:JAVA_HOME,变量值:C:\Java\jdk1.8.0_11
- 打开PATH,添加变量值:%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin
- 新建环境变量名:CLASSPATH,变量值:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
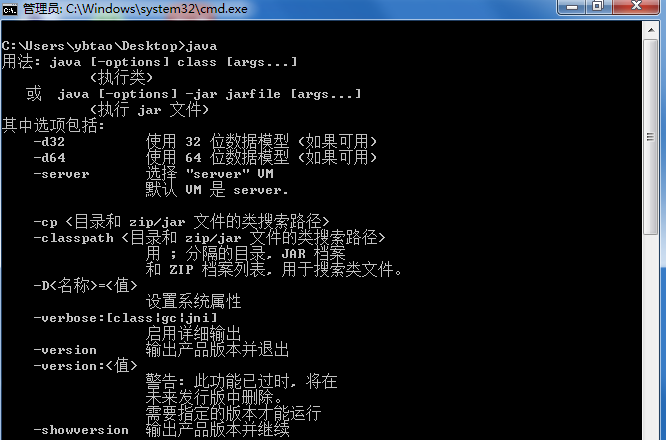
在 cmd 中输入 java 出现如下信息就算安装成功了
安装spark
在C盘新建Spark目录,将其解压到这个路径下
- 新建环境变量名:SPARK_HOME,变量值:C:\Spark
- 打开PATH,添加变量值:%SPARK_HOME%\bin
安装hadoop
在C盘新建Hadoop目录,将其解压到这个路径下
- 新建环境变量名:HADOOP_HOME,变量值:C:\Hadoop
- 打开PATH,添加变量值:%HADOOP_HOME%\bin
去网站下载Hadoop在Windows下的支持winutils
https://github.com/steveloughran/winutils
根据版本来选择,这里用的是 hadoop2.7,所以选择2.7的bin下载下来,将其覆盖到 C:\Hadoop\bin
修改C:\Hadoop\etc\hadoop下的hadoop-env.cmd为set JAVA_HOME=C:\Java\jdk1.8.0_11
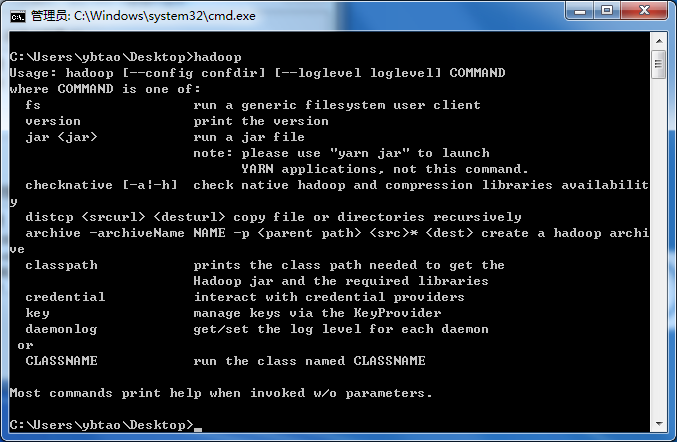
在 cmd 中输入 hadoop 出现如下信息就算安装成功了
安装python
安装路径为 C:\Python35
在C盘或者代码盘新建\tmp\hive路径,输入命令
winutils.exe chmod -R 777 C:\tmp\hive
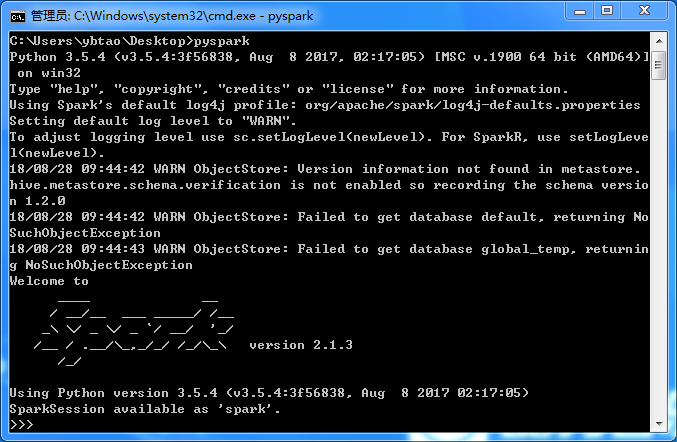
验证pyspark
cmd输入pyspark得到如下画面
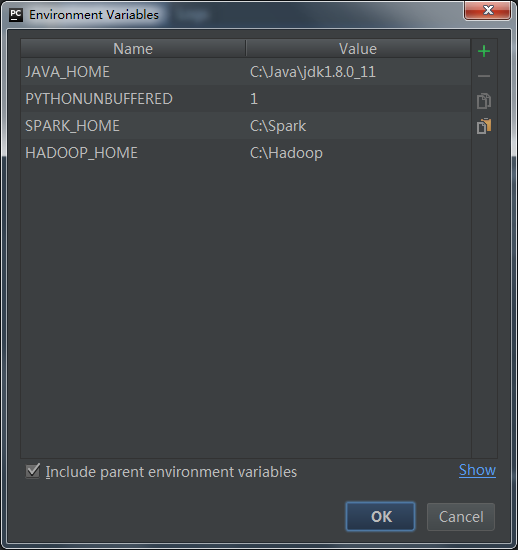
配置pycharm
在如下路径添加环境变量
- JAVA_HOME
- SPARK_HOME
- HADOOP_HOME
Run->Edit Configurations->Environment variables

 浙公网安备 33010602011771号
浙公网安备 33010602011771号