
Agens层次聚类
层次聚类是另一种主要的聚类方法,它具有一些十分必要的特性使得它成为广泛应用的聚类方法。它生成一系列嵌套的聚类树来完成聚类。单点聚类处在树的最底层,在树的顶层有一个根节点聚类。根节点聚类覆盖了全部的所有数据点。层次聚类分为两种:
- 合并(自下而上)聚类(agglomerative)
- 分裂(自上而下)聚类(divisive)
目前 使用较多的是合并聚类 ,本文着重讲解合并聚类的原理。
Agens层次聚类原理
合并聚类主要是将N个元素当成N个簇,每个簇与其 欧氏距离最短 的另一个簇合并成一个新的簇,直到达到需要的分簇数目K为止,示意图如下:

举个例子,作者将26个字母随机分配了坐标(x,y),如:
# {'K': {'y': 34, 'x': 81}, 'V': {'y': 68, 'x': 50}, 'G': {'y': 1, 'x': 10}, 'C': {'y': 2, 'x': 9}, 'T': {'y': 78, 'x': 40}, 'A': {'y': 20, 'x': 12}, 'B': {'y': 21, 'x': 39}, 'N': {'y': 37, 'x': 67}, 'S': {'y': 92, 'x': 56}, 'Q': {'y': 7, 'x': 62}, 'D': {'y': 18, 'x': 4}, 'E': {'y': 0, 'x': 38}, 'Z': {'y': 92, 'x': 46}, 'H': {'y': 30, 'x': 32}, 'I': {'y': 21, 'x': 35}, 'U': {'y': 71, 'x': 51}, 'L': {'y': 1, 'x': 96}, 'W': {'y': 99, 'x': 59}, 'F': {'y': 10, 'x': 14}, 'O': {'y': 16, 'x': 97}, 'J': {'y': 37, 'x': 76}, 'X': {'y': 86, 'x': 49}, 'Y': {'y': 67, 'x': 50}, 'P': {'y': 17, 'x': 76}, 'M': {'y': 32, 'x': 88}, 'R': {'y': 6, 'x': 70}}
点的位置如下:
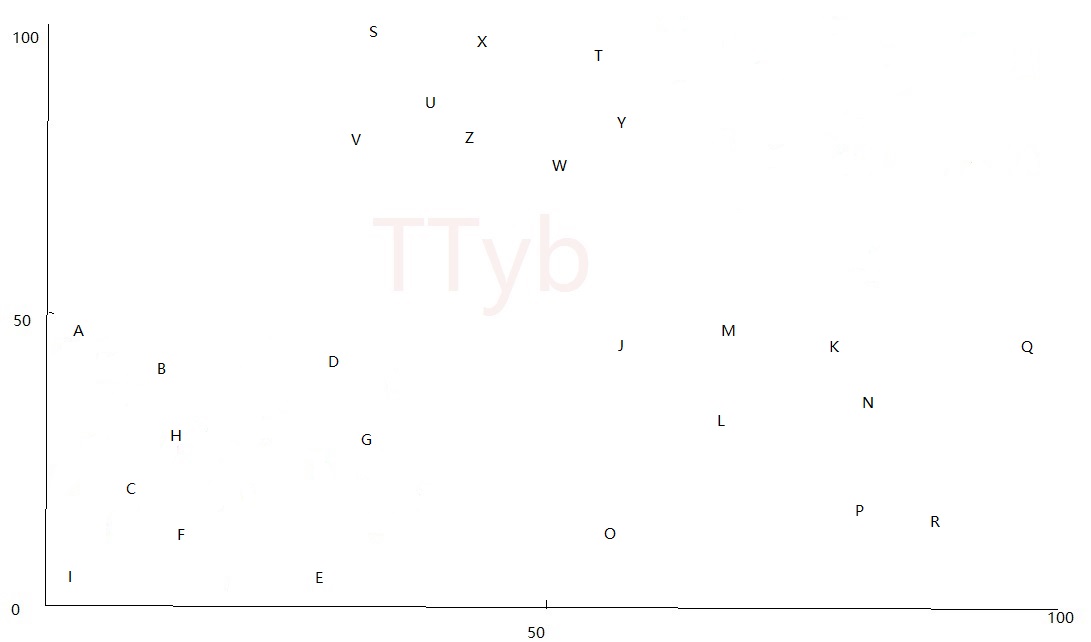
- 假设要分成1个簇,即
K=1,那么平面上的所有点都在一起,如下图红色点:
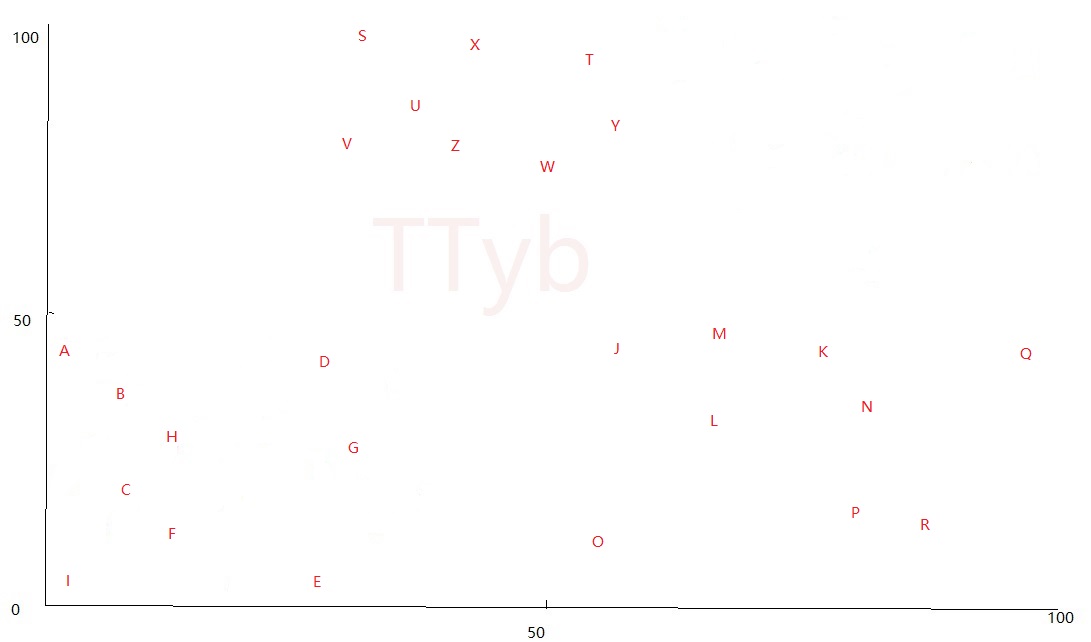
- 假设要分成2个簇,即
K=2,则根据欧式距离公式,首先将字母分成了红色的点和绿色的点,黑色的点为未分配:
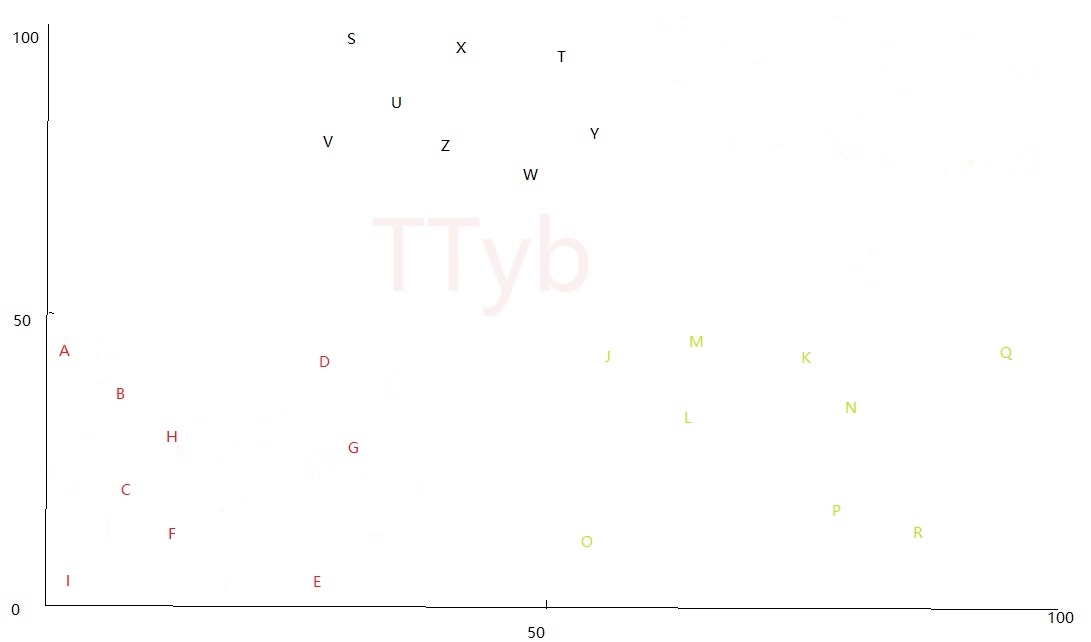
而黑色的点可能一部分与红色的点距离较近,所以一部分变成了红色,一部分变成了绿色:

- 假设要分成3个簇,即
K=3,如下图红色、绿色、紫色的点:
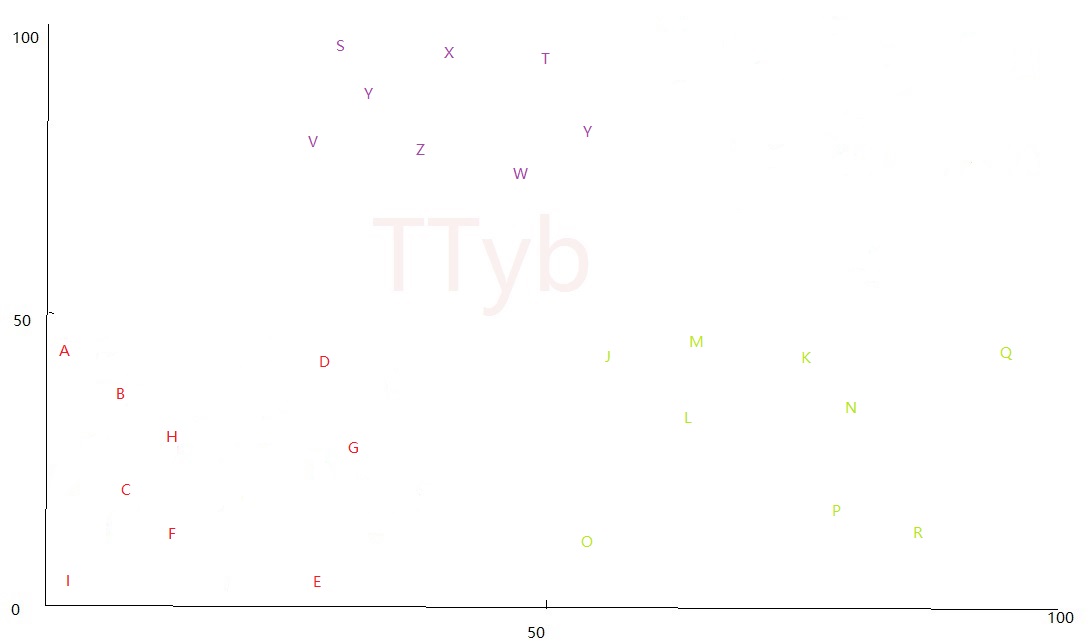
假设 K=3 ,合并的步骤为:
- 26个字母首先被分配成 26 个簇
- 两两欧氏距离最近的两个簇合并,此时簇变成了 13 个
- 再次两两欧氏距离最近的两个簇合并,此时一共有 12 个簇合并成了6个簇,还余下一个簇,因此此时剩下
6+1=7个簇- 一直重复上一步的操作,直到簇的数量为 3 的时候,就算是分簇完成
Agens层次聚类实现:
- 随机生成26个字母:
# 生成坐标字典
def buildclusters():
clusters = {}
keys = [chr(i) for i in range(ord('A'), ord('Z') + 1)]
# ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
# 生成第一个分簇坐标
for i in range(0, 9):
# A-I
temp = {}
x = random.randint(0, 40)
y = random.randint(0, 40)
temp["x"] = x
temp["y"] = y
clusters[keys[i]] = temp
# 生成第二个分簇坐标
for i in range(9, 18):
# J-R
temp = {}
x = random.randint(60, 100)
y = random.randint(0, 40)
temp["x"] = x
temp["y"] = y
clusters[keys[i]] = temp
# 生成第三个分簇坐标
for i in range(18, 26):
# S-Z
temp = {}
x = random.randint(40, 60)
y = random.randint(60, 100)
temp["x"] = x
temp["y"] = y
clusters[keys[i]] = temp
return clusters
得到的结果为:
{'K': {'y': 34, 'x': 81}, 'V': {'y': 68, 'x': 50}, 'G': {'y': 1, 'x': 10}, 'C': {'y': 2, 'x': 9}, 'T': {'y': 78, 'x': 40}, 'A': {'y': 20, 'x': 12}, 'B': {'y': 21, 'x': 39}, 'N': {'y': 37, 'x': 67}, 'S': {'y': 92, 'x': 56}, 'Q': {'y': 7, 'x': 62}, 'D': {'y': 18, 'x': 4}, 'E': {'y': 0, 'x': 38}, 'Z': {'y': 92, 'x': 46}, 'H': {'y': 30, 'x': 32}, 'I': {'y': 21, 'x': 35}, 'U': {'y': 71, 'x': 51}, 'L': {'y': 1, 'x': 96}, 'W': {'y': 99, 'x': 59}, 'F': {'y': 10, 'x': 14}, 'O': {'y': 16, 'x': 97}, 'J': {'y': 37, 'x': 76}, 'X': {'y': 86, 'x': 49}, 'Y': {'y': 67, 'x': 50}, 'P': {'y': 17, 'x': 76}, 'M': {'y': 32, 'x': 88}, 'R': {'y': 6, 'x': 70}}
- 欧氏距离公式:
# 两点间的距离公式/欧式距离
def distance(x1, x2, y1, y2):
distan = ((x1 - x2) ** 2 + (y1 - y2) ** 2) ** 0.5
return distan
- 第一次分簇:
# 计算各个分簇直到达到分簇的效果
def splitcluster(clusters):
dict = {}
newdict = {}
arr = []
i = 1
for key1 in clusters:
temp = {}
for key2 in clusters:
if key1 != key2:
if key1 in arr or key2 in arr:
pass
else:
name = str(key1 + "->" + key2)
temp[name] = distance(clusters[key1]["x"], clusters[key2]["x"], clusters[key1]["y"],
clusters[key2]["y"])
arr.append(key1)
arr.append(key2)
if temp:
# reverse=False值按照从小到大排序
temp = sorted(temp.items(), key=lambda d: d[1], reverse=False)
newdict[temp[0][0]] = temp[0][1]
newdict = sorted(newdict.items(), key=lambda d: d[1], reverse=False)
for item in newdict:
name = "cluster" + str(i)
i += 1
dict[name] = item[0]
return dict
成功的将其分成13个簇,得到的结果为:
{'cluster13': 'B->T', 'cluster11': 'U->M', 'cluster10': 'Z->H', 'cluster5': 'L->D', 'cluster1': 'F->E', 'cluster4': 'G->A', 'cluster12': 'I->S', 'cluster3': 'W->V', 'cluster8': 'C->R', 'cluster9': 'P->X', 'cluster2': 'K->N', 'cluster7': 'O->Q', 'cluster6': 'Y->J'}
- 迭代分簇,直到满足K为止:
# 判断分簇
def judgecluster(clusters, firstcluster, K):
dict = {}
i = 1
arr = []
for item in firstcluster:
temparr = firstcluster[item].split("->")
distan = {}
for judge in temparr:
if judge in arr:
pass
else:
for value in clusters:
if value in temparr:
pass
elif value in arr:
pass
else:
for key in temparr:
name = value + "->" + key
distan[name] = distance(clusters[key]["x"], clusters[value]["x"], clusters[key]["y"],
clusters[value]["y"])
if key in arr:
pass
else:
arr.append(key)
if distan:
distan = sorted(distan.items(), key=lambda d: d[1], reverse=False)
# print(distan)
element = distan[0][0].split("->")[0]
for ele in firstcluster:
elearr = firstcluster[ele].split("->")
if element in elearr:
values = firstcluster[item]
for va in elearr:
values = values + "->" + va
arr.append(va)
cluster = "cluster" + str(i)
i += 1
dict[cluster] = values
if len(arr) != 26:
# 生成26个字母
letters = [chr(i) for i in range(ord('A'), ord('Z') + 1)]
# 得到剩下没有被放到dict的字母
remain = []
for letter in letters:
if letter in arr:
pass
else:
remain.append(letter)
dis = {}
for letter in remain:
for item in dict:
elearr = dict[item].split("->")
for ele in elearr:
name = letter + "->" + ele
dis[name] = distance(clusters[letter]["x"], clusters[ele]["x"], clusters[letter]["y"],
clusters[ele]["y"])
if dis:
dis = sorted(dis.items(), key=lambda d: d[1], reverse=False)
element = dis[0][0].split("->")
for cluster in dict:
array = dict[cluster].split("->")
for item in element:
if item in array:
values = "->".join(remain)
dict[cluster] = dict[cluster] + "->" + values
if len(dict) == K:
print(dict)
# {'cluster1': 'M->X->P->Y->J->U->T->R->L->O', 'cluster3': 'V->B->W->N->E->A->I->G', 'cluster2': 'C->H->Q->F->D->S->Z->K'}
return dict
else:
judgecluster(clusters, dict, K)
本文选取的 K=3 ,最后得到的结果为:
{'cluster1': 'M->X->P->Y->J->U->T->R->L->O', 'cluster3': 'V->B->W->N->E->A->I->G', 'cluster2': 'C->H->Q->F->D->S->Z->K'}
由此可见,按照这个结果,作者手动画的图是错误的...
python代码在我的博客上面:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号