
唯品会专场监控系统
唯品会的对于数据的封锁是很严重的,例如某个界面:
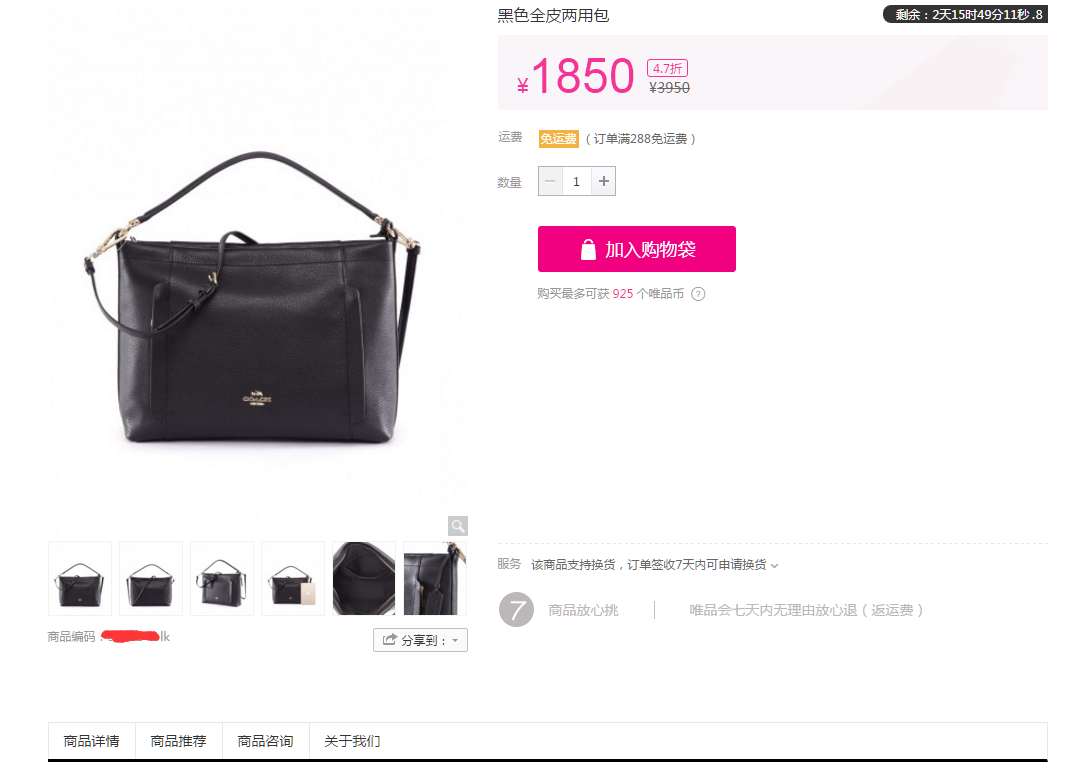
一片空白!!!
身为一个数据分析师,没有数据更谈不上分析了,所以数据挖掘下还是有的:
果断F12,突然发现了一个页面:
1 http://stock.vip.com/list/?callback=te_list&brandId=813542
最后面的813542是这个店铺的ID,前边都是一样的
打开页面:

很醒目的:sold_out
数据是要自己找的,所以就可以发挥一下自己的小特长来搞个数据监控,顺便为自己的数据分析提供点帮助
这样子就可以做一个售罄的监控系统,监控别家店铺的售罄情况,最后得到的效果图如下:

你们在我眼里是没有秘密的!
代码解析:
确定专场ID、监控的时间间隔、监控的次数:
1 info_data_id = input('请输入需要监控专场的ID:') 2 3 ##设置间隔时长 4 try: 5 info_time_interval = int(input('请输入监控时间间隔分钟(min)(默认3分钟):')) 6 if info_time_interval < 0: 7 print('间隔太短') 8 info_time_interval = 3 * 60 9 else: 10 info_time_interval = info_time_interval * 60 11 except: 12 info_time_interval = 3 * 60 13 14 ##设置监控次数 15 try: 16 info_time_frequency = int(input('请输入监控次数(默认2次):')) 17 if info_time_frequency > 50: 18 print('不要监控那么久,不能超过50次') 19 info_time_frequency = 2 20 except: 21 info_time_frequency = 2
由于
time.sleep(second)
所以要乘以60变成分钟
给定频率最开始的代码是
frequency = 0
while frequency < info_time_frequency:
time.sleep(info_time_interval)
frequency = frequency + 1
在睡眠里面加入代码:
1 url = 'http://stock.vip.com/list/?callback=te_list&brandId=' + info_data_id 2 info_data = (get_all(getHtml(url).decode('UTF-8', 'ignore'))) # ('UTF-8')('unicode_escape')('gbk','ignore') 3 4 ##下面是判断 5 if frequency == 0: 6 info_data_new = info_data[0][1].split(',') 7 print('######导入售罄情况开始监控######') 8 elif len(info_data_new) == len(info_data[0][1].split(',')): 9 print('######售罄情况没什么变化######') 10 elif len(info_data_new) > len(info_data[0][1].split(',')): 11 for j in range(0, len(info_data_new)): 12 info_data_name = [] 13 info_html_jpg = [] 14 if info_data_new[j] in info_data[0][1].split(','): 15 pass 16 else: 17 print('该商品异常,估计被下了订单或者被取消付款:' + info_data_new[j]) 18 19 ##图片名字,包括专场名称、商品名称 20 namepath = get_data(getHtml( 21 'http://www.vip.com/detail-' + info_data_id + '-' + info_data_new[j] + '.html').decode( 22 'UTF-8', 'ignore')) 23 rstr = '[’!"#$///%&\'*+,./:;<=>?@[\\]\\\^_`//{|}~]+' 24 info_data_name = re.sub(rstr, "", namepath[0][1]) 25 name = time.strftime('%Y%m%d%H%S', time.localtime()) # 当时时间 26 27 ##得到图片网址 28 jpgpath = get_jpg(getHtml( 29 'http://www.vip.com/detail-' + info_data_id + '-' + info_data_new[j] + '.html').decode( 30 'UTF-8', 'ignore')) 31 32 # 图片放大 33 try: 34 info_html_jpg = jpgpath[0][1].replace('95x120', '720x720') 35 except: 36 info_html_jpg = jpgpath[0][1] 37 38 pic = urllib.request.urlopen(info_html_jpg) # 解析图片网址 39 40 ##下面是保存图片 41 file = 'C:\\Users\\Administrator\\Desktop\\monitor\\' + time.strftime('%Y%m%d', 42 time.localtime()) + '-' + info_data_id + '\\' 43 filess = open(file + name + info_data_name + info_data_new[j] + '异常.jpg', 'wb') 44 filess.write(pic.read()) 45 filess.close() 46 47 info_data_new = info_data[0][1].split(',') ##更新数组 48 continue
分段解释:
getHtml#解析头,爬虫的都知道
正则表达式得到商品的ID,附上:
1 ##解析网址的正则表达式,将售罄的product_id搞出来 2 def get_all(html_all): 3 reg = r'(sold_out":")(.+?)(","sold_chance)' 4 all = re.compile(reg); 5 alllist = re.findall(all, html_all) 6 return alllist
得到店铺ID,那么我要用商品的的名称来,再去看商品的product_id解析情况:

那么正则写为:
1 def get_data(html_all): 2 reg = r'(keywords" content=")(.+?)(" />)' 3 all = re.compile(reg); 4 alllist = re.findall(all, html_all) 5 return alllist
图片的网址也要,要下载图片来看看什么东西那么好卖:
那么正则写为:
1 def get_jpg(html_all): 2 reg = r'(<img src=")(.+?)(" width=)' 3 all = re.compile(reg); 4 alllist = re.findall(all, html_all) 5 return alllist
将得到的product_id按照“,”号来分开存入一个新数组里面,这个心的数组用来作为下次循环的判断依据,即下一次循环得到的数组和这个新数组进行比较:
info_data_new = info_data[0][1].split(',')
如果两个数组长度一样就不判断了
因为解析得到的是售罄的情况
假如售罄的商品不增加还变少了,那么就可以判断是别人下单后取消订单了
因为这里下单后会假如没有库存了就会被判断为售罄
但是别人取消订单,那么售罄状态解除
如果是正常的变多,那就遍历一次就行了,找到没有的
再把判断数组更新就行
info_data_new = info_data[0][1].split(',')
这一段的代码如下:
1 if frequency == 0: 2 info_data_new = info_data[0][1].split(',') 3 print('######导入售罄情况开始监控######') 4 elif len(info_data_new) == len(info_data[0][1].split(',')): 5 print('######售罄情况没什么变化######') 6 elif len(info_data_new) > len(info_data[0][1].split(',')): 7 for j in range(0, len(info_data_new)): 8 info_data_name = [] 9 info_html_jpg = [] 10 if info_data_new[j] in info_data[0][1].split(','): 11 pass 12 else: 13 print('该商品异常,估计被下了订单或者被取消付款:' + info_data_new[j])
解析也能得到图片的网址,那么就要把图片保存下来:
1 ##图片名字,包括专场名称、商品名称 2 namepath = get_data(getHtml( 3 'http://www.vip.com/detail-' + info_data_id + '-' + info_data_new[j] + '.html').decode( 4 'UTF-8', 'ignore')) 5 rstr = '[’!"#$///%&\'*+,./:;<=>?@[\\]\\\^_`//{|}~]+' 6 info_data_name = re.sub(rstr, "", namepath[0][1]) 7 name = time.strftime('%Y%m%d%H%S', time.localtime()) # 当时时间 8 9 ##得到图片网址 10 jpgpath = get_jpg(getHtml( 11 'http://www.vip.com/detail-' + info_data_id + '-' + info_data_new[j] + '.html').decode( 12 'UTF-8', 'ignore')) 13 14 # 图片放大 15 try: 16 info_html_jpg = jpgpath[0][1].replace('95x120', '720x720') 17 except: 18 info_html_jpg = jpgpath[0][1] 19 20 pic = urllib.request.urlopen(info_html_jpg) # 解析图片网址 21 22 ##下面是保存图片 23 file = 'C:\\Users\\Administrator\\Desktop\\monitor\\' + time.strftime('%Y%m%d', 24 time.localtime()) + '-' + info_data_id + '\\' 25 filess = open(file + name + info_data_name + info_data_new[j] + '异常.jpg', 'wb') 26 filess.write(pic.read()) 27 filess.close()
图片的名字为:当时下载的时间+图片本来的名称+product_id
上面代码没什么特别,无非就是
去掉名字里面的不合字符
把图片变大一点
存入生成的文件夹里面,搞定
上面是异常售罄的情况
后面要写正常售罄的代码
1 else: 2 info_data_linshi = [] 3 info_data_linshi = info_data[0][1].split(',') 4 for i in range(0, len(info_data[0][1].split(','))): 5 info_data_name = [] 6 info_html_jpg = [] 7 if info_data_linshi[i] in info_data_new: 8 pass 9 else: 10 print('新增售罄商品:' + info_data_linshi[i]) 11 ##图片名字,包括专场名称、商品名称 12 namepath = get_data(getHtml( 13 'http://www.vip.com/detail-' + info_data_id + '-' + info_data_linshi[i] + '.html').decode( 14 'UTF-8', 'ignore')) 15 rstr = '[’!"#$///%&\'*+,./:;<=>?@[\\]\\\^_`//{|}~]+' 16 info_data_name = re.sub(rstr, "", namepath[0][1]) 17 name = time.strftime('%Y%m%d%H%S', time.localtime()) # 当时时间 18 19 ##得到图片网址 20 jpgpath = get_jpg(getHtml( 21 'http://www.vip.com/detail-' + info_data_id + '-' + info_data_linshi[i] + '.html').decode( 22 'UTF-8', 'ignore')) 23 24 # 图片放大 25 try: 26 info_html_jpg = jpgpath[0][1].replace('95x120', '720x720') 27 except: 28 info_html_jpg = jpgpath[0][1] 29 30 pic = urllib.request.urlopen(info_html_jpg) # 解析图片网址 31 32 ##下面是保存图片 33 file = 'C:\\Users\\Administrator\\Desktop\\monitor\\' + time.strftime('%Y%m%d', 34 time.localtime()) + '-' + info_data_id + '\\' 35 filess = open(file + name + info_data_name + info_data_linshi[i] + '.jpg', 'wb') 36 filess.write(pic.read()) 37 filess.close() 38 39 info_data_new.append(info_data_linshi[i]) ##更新数组
其实和上面是一样的,这样就算搞定了,附上全部代码:
1 #print('python 的空白页,用来打开PyCharm') 2 # -*- coding:utf-8 -*- 3 import re 4 import urllib.request, urllib.parse, http.cookiejar 5 import os, time, re 6 import http.cookies 7 import time 8 import xlsxwriter 9 import datetime 10 11 12 ############################################################这里是解析网址的东西################################################################### 13 ## 说明 14 ## 安装包 15 ## pip3 install bs4 16 ## pip3 install -U selenium 17 ## 抓取不会变的网址用getHtml,否则getFirefox() 18 19 ## 这个函数可以用Post,Get等方式获取网页内容 20 ## 例子一: 21 ## 如果网站有使用cookie登录的话可以加载cookie,或者如果网站反爬虫可以加头部 22 ## 例子二: 23 ## 被封了Ip,你就无法抓取了,此时你可以设置代理ip,下面那个‘’表示不使用代理,代理可以去网上找,很多 24 ## 例子三: 25 ## 有些抓取需要发送一些数据过去,才能获取到内容,此时下面的{}表示数据 26 27 ## 一般使用就是 url=”xxxxxxx“ getHtml(url) 其他不用管 28 ## 得到原始网页 29 def getHtml(url, daili='', postdata={}): 30 """ 31 抓取网页:支持cookie 32 第一个参数为网址,第二个为POST的数据(这句话看得懂吧) 33 """ 34 # COOKIE文件保存路径 35 filename = 'cookie.txt' 36 37 # 声明一个MozillaCookieJar对象实例保存在文件中 38 cj = http.cookiejar.MozillaCookieJar(filename) 39 # cj =http.cookiejar.LWPCookieJar(filename) 40 41 # 从文件中读取cookie内容到变量 42 # ignore_discard的意思是即使cookies将被丢弃也将它保存下来 43 # ignore_expires的意思是如果在该文件中 cookies已经存在,则覆盖原文件写 44 # 如果存在,则读取主要COOKIE 45 if os.path.exists(filename): 46 cj.load(filename, ignore_discard=True, ignore_expires=True) 47 # 建造带有COOKIE处理器的打开专家 48 proxy_support = urllib.request.ProxyHandler({'http': 'http://' + daili}) 49 # 开启代理支持 50 if daili: 51 print('代理:' + daili + '启动') 52 opener = urllib.request.build_opener(proxy_support, urllib.request.HTTPCookieProcessor(cj), 53 urllib.request.HTTPHandler) 54 else: 55 opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) 56 57 # 打开专家加头部----与post的数据格式一样,下面是头部,表示我用ipad浏览器! 58 opener.addheaders = [('User-Agent', 59 'Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5'), 60 ] 61 62 # 分配专家 63 urllib.request.install_opener(opener) 64 # 有数据需要POST 65 if postdata: 66 # 数据URL编码 67 postdata = urllib.parse.urlencode(postdata) 68 69 # 抓取网页 70 html_bytes = urllib.request.urlopen(url, postdata.encode(), timeout=30).read() 71 else: 72 html_bytes = urllib.request.urlopen(url, timeout=30).read() 73 74 # 保存COOKIE到文件中 75 cj.save(ignore_discard=True, ignore_expires=True) 76 return html_bytes 77 78 79 ############################################################这里是函数,也是正则表达式################################################################### 80 ##解析网址的正则表达式,将售罄的product_id搞出来 81 def get_all(html_all): 82 reg = r'(sold_out":")(.+?)(","sold_chance)' 83 all = re.compile(reg); 84 alllist = re.findall(all, html_all) 85 return alllist 86 87 88 ##解析网址的正则表达式,将变动商品的专场以及名称搞出来 89 def get_data(html_all): 90 reg = r'(keywords" content=")(.+?)(" />)' 91 all = re.compile(reg); 92 alllist = re.findall(all, html_all) 93 return alllist 94 95 96 def get_jpg(html_all): 97 reg = r'(<img src=")(.+?)(" width=)' 98 all = re.compile(reg); 99 alllist = re.findall(all, html_all) 100 return alllist 101 102 103 ###########################################################这里是杂七杂八的东西################################################################### 104 def timetochina(longtime, formats='{}天{}小时{}分钟{}秒'): 105 day = 0 106 hour = 0 107 minutue = 0 108 second = 0 109 try: 110 if longtime > 60: 111 second = longtime % 60 112 minutue = longtime // 60 113 else: 114 second = longtime 115 if minutue > 60: 116 hour = minutue // 60 117 minutue = minutue % 60 118 if hour > 24: 119 day = hour // 24 120 hour = hour % 24 121 return formats.format(day, hour, minutue, second) 122 except: 123 raise Exception('时间非法') 124 125 ############################################################这里是主函数################################################################### 126 if __name__ == '__main__': 127 128 a = time.clock() # 程序测速,后面会有个b = time.clock(),那么b-a就是时间 129 130 info_data_id = input('请输入需要监控专场的ID:') 131 132 ##设置间隔时长 133 try: 134 info_time_interval = int(input('请输入监控时间间隔分钟(min)(默认3分钟):')) 135 if info_time_interval < 0: 136 print('间隔太短') 137 info_time_interval = 3 * 60 138 else: 139 info_time_interval = info_time_interval * 60 140 except: 141 info_time_interval = 3 * 60 142 143 ##设置监控次数 144 try: 145 info_time_frequency = int(input('请输入监控次数(默认2次):')) 146 if info_time_frequency > 50: 147 print('不要监控那么久,不能超过50次') 148 info_time_frequency = 2 149 except: 150 info_time_frequency = 2 151 152 frequency = 0 153 info_data_new = [] 154 155 if os.path.exists(r'C:\\Users\\Administrator\\Desktop\\monitor'): # 建立一个文件夹在桌面,文件夹为monitor 156 print('monitor文件夹已经在桌面存在,继续运行程序……') 157 else: 158 print('monitor文件夹不在桌面,新建文件夹monitor') 159 os.mkdir(r'C:\\Users\\Administrator\\Desktop\\monitor') 160 print('文件夹建立成功,继续运行程序') 161 162 if os.path.exists(r'C:\\Users\\Administrator\\Desktop\\monitor\\' + time.strftime('%Y%m%d', 163 time.localtime()) + '-' + info_data_id): 164 print(time.strftime('%Y%m%d', time.localtime()) + '-' + info_data_id + '文件夹已经在桌面存在,继续运行程序……') 165 else: 166 print(time.strftime('%Y%m%d', time.localtime()) + '-' + info_data_id + '文件夹不在桌面,新建文件夹' + time.strftime( 167 '%Y%m%d', time.localtime()) + '-' + info_data_id) 168 os.mkdir(r'C:\\Users\\Administrator\\Desktop\\monitor\\' + time.strftime('%Y%m%d', 169 time.localtime()) + '-' + info_data_id) 170 print('文件夹建立成功,继续运行程序') 171 172 while frequency < info_time_frequency: 173 url = 'http://stock.vip.com/list/?callback=te_list&brandId=' + info_data_id 174 info_data = (get_all(getHtml(url).decode('UTF-8', 'ignore'))) # ('UTF-8')('unicode_escape')('gbk','ignore') 175 176 ##下面是判断 177 if frequency == 0: 178 info_data_new = info_data[0][1].split(',') 179 print('######导入售罄情况开始监控######') 180 elif len(info_data_new) == len(info_data[0][1].split(',')): 181 print('######售罄情况没什么变化######') 182 elif len(info_data_new) > len(info_data[0][1].split(',')): 183 for j in range(0, len(info_data_new)): 184 info_data_name = [] 185 info_html_jpg = [] 186 if info_data_new[j] in info_data[0][1].split(','): 187 pass 188 else: 189 print('该商品异常,估计被下了订单或者被取消付款:' + info_data_new[j]) 190 191 ##图片名字,包括专场名称、商品名称 192 namepath = get_data(getHtml( 193 'http://www.vip.com/detail-' + info_data_id + '-' + info_data_new[j] + '.html').decode( 194 'UTF-8', 'ignore')) 195 rstr = '[’!"#$///%&\'*+,./:;<=>?@[\\]\\\^_`//{|}~]+' 196 info_data_name = re.sub(rstr, "", namepath[0][1]) 197 name = time.strftime('%Y%m%d%H%S', time.localtime()) # 当时时间 198 199 ##得到图片网址 200 jpgpath = get_jpg(getHtml( 201 'http://www.vip.com/detail-' + info_data_id + '-' + info_data_new[j] + '.html').decode( 202 'UTF-8', 'ignore')) 203 204 # 图片放大 205 try: 206 info_html_jpg = jpgpath[0][1].replace('95x120', '720x720') 207 except: 208 info_html_jpg = jpgpath[0][1] 209 210 pic = urllib.request.urlopen(info_html_jpg) # 解析图片网址 211 212 ##下面是保存图片 213 file = 'C:\\Users\\Administrator\\Desktop\\monitor\\' + time.strftime('%Y%m%d', 214 time.localtime()) + '-' + info_data_id + '\\' 215 filess = open(file + name + info_data_name + info_data_new[j] + '异常.jpg', 'wb') 216 filess.write(pic.read()) 217 filess.close() 218 219 info_data_new = info_data[0][1].split(',') ##更新数组 220 continue 221 222 223 else: 224 info_data_linshi = [] 225 info_data_linshi = info_data[0][1].split(',') 226 for i in range(0, len(info_data[0][1].split(','))): 227 info_data_name = [] 228 info_html_jpg = [] 229 if info_data_linshi[i] in info_data_new: 230 pass 231 else: 232 print('新增售罄商品:' + info_data_linshi[i]) 233 ##图片名字,包括专场名称、商品名称 234 namepath = get_data(getHtml( 235 'http://www.vip.com/detail-' + info_data_id + '-' + info_data_linshi[i] + '.html').decode( 236 'UTF-8', 'ignore')) 237 rstr = '[’!"#$///%&\'*+,./:;<=>?@[\\]\\\^_`//{|}~]+' 238 info_data_name = re.sub(rstr, "", namepath[0][1]) 239 name = time.strftime('%Y%m%d%H%S', time.localtime()) # 当时时间 240 241 ##得到图片网址 242 jpgpath = get_jpg(getHtml( 243 'http://www.vip.com/detail-' + info_data_id + '-' + info_data_linshi[i] + '.html').decode( 244 'UTF-8', 'ignore')) 245 246 # 图片放大 247 try: 248 info_html_jpg = jpgpath[0][1].replace('95x120', '720x720') 249 except: 250 info_html_jpg = jpgpath[0][1] 251 252 pic = urllib.request.urlopen(info_html_jpg) # 解析图片网址 253 254 ##下面是保存图片 255 file = 'C:\\Users\\Administrator\\Desktop\\monitor\\' + time.strftime('%Y%m%d', 256 time.localtime()) + '-' + info_data_id + '\\' 257 filess = open(file + name + info_data_name + info_data_linshi[i] + '.jpg', 'wb') 258 filess.write(pic.read()) 259 filess.close() 260 261 info_data_new.append(info_data_linshi[i]) ##更新数组 262 263 # print(len(info_data_new)) 264 print('暂停' + str(info_time_interval / 60) + '分钟') 265 print('\n') 266 print('请等待...') 267 268 time.sleep(info_time_interval) 269 frequency = frequency + 1 270 271 b = time.clock() 272 print('运行时间:' + timetochina(b - a)) 273 input('请关闭窗口') ##防止运行完毕后窗口直接关闭而看不到运行时间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号