Python-实现逻辑回归
Python-实现逻辑回归
1 逻辑回归
感知器的缺点是只能做线性可分的分类任务,如果任务不是完全可以线性可分的,那么感知器是永远不能收敛的,因为每次更新都会有至少一个错误。现在我们来看下另外一个解决二分类问题的算法逻辑回归。注意:它是分类模型,不是回归模型。
本次写的适用于二分类上的模型,但是其也可以用\(OvR\)技术扩展到多元分类上。
OvR很好理解,我们将需要分类出来的类设为正类,其他类全设为负类,若总共有N个类,则最后只需要对自己的目标训练N个分类器就能实现N分类
在介绍逻辑回归的原理之前,首先需要了解让步比(odds ratio),在统计学中让步比是用来衡量一个特定群体中,属性A的出现与否和属性B的出现与否的关联性大小的特征值。
让步比定义为:
其中,\(p\)代表自己要预测的事物的概率,在二分类中可以认为是正类1的概率。
在《统计学习方法》中这被称为几率(odds)
然后进一步定义\(logit\)函数,这没有意义,仅仅是让步比的对数形式:
在计算机中\(log\)是自然对数。
因为\(p\)是概率所以\(logit\)函数输入值范围为\(0 \sim 1\)之间,而计算结果值为整个实数范围,所以,可以用它来表示特征值和对数概率(log-odds)之间的线性关系:
这里需要解释一下\(p(y=1 \mid \boldsymbol{x})\),首先需要理解\(P(A \mid B)\),其代表着在已知给定事件\(B\)下,事件\(A\)发生的概率为多少。所以\(p(y=1 \mid \boldsymbol{x})\)意味着在给定的样本特征\(x\)下,样本属于\(1\)类的概率为多少。
而实际上我们所需要的是预测某个样本属于某个特定类的概率,也就是\(p(y=1 \mid \boldsymbol{x})\),也即\(logit\)的逆形式:
这个公式被称为逻辑sigmoid函数,由于其特别的S形,有时干脆简称为sigmoid函数。
其中\(z\)为净输入,也就是:\(z=\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}=w_0 x_0+w_1 x_1+\cdots+w_m x_m\),\(\phi(z)\)为\(p(y=1 \mid \boldsymbol{x})\)。
这里进行公式推导:
\[\begin{aligned} logit(p(y=1 \mid x)) & =z \\ \log (\phi(z)) & =z \\ \log \left(\frac{\phi(z)}{1-\phi(z)}\right) & =z \\ \frac{\phi(z)}{1-\phi(z)} & =e^z \\ \frac{1}{\phi(z)}-1 & =e^{-z} \\ \frac{1}{\phi(z)} & =e^{-z}+1 \\ \phi(z) & =\frac{1}{1+e^{-z}} \end{aligned} \]
下面画出\(sigmoid\)函数的图形:
import matplotlib.pyplot as plt
import numpy as np
#建立sigmoid函数
def sigmoid(z):
return 1.0 / (1.0 + np.exp(-z))
#画出z属于-7~7的sigmoid函数图像
#每个坐标点的y为sigmoid(z)
z = np.arange(-7,7,0.1)
phi_z = sigmoid(z)
plt.plot(z, phi_z)
#设置垂直线的位置
plt.axvline(0.0, color='k')
plt.ylim(-0.1, 1.1)
plt.xlabel('z')
plt.ylabel('$\phi (z)$')
#设置水平线的位置
plt.yticks([0.0,0.5,1.0])
ax = plt.gca()
# 单独设置Y坐标轴上(水平方向)的网格线
ax.yaxis.grid(True)
plt.show()
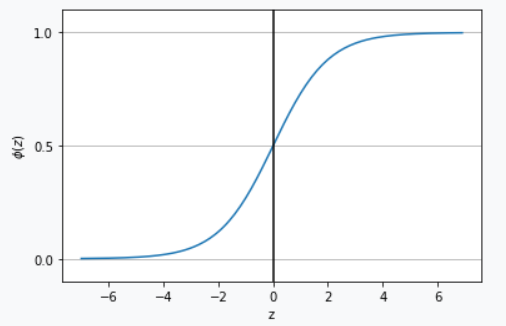
从图中可以看出S函数以实数作为输入,并在截距为\(\phi (z) = 0.5\)的时候转化为范围在[0,1]之间的值。
现在我们将逻辑回归替代Adaline的激活函数,这样S函数的输出被翻译成属于第1类的概率,然后通过阈值函数转化为二元输出:
结合上面的S函数图等同于下述结果:
2 代价函数
上面我们已经拟定好模型分类的规则了,接下来我们应该思考如何更新权重\(w\)来拟合模型,拟合模型首先需要我们定义一个判断模型拟合好坏的函数。一般我们会选择平方损失函数\(J(\theta)=\frac{1}{2}(y-\bar{y})^2\)或者似然函数作为代价函数。
对于逻辑回归算法,我们使用似然函数作为代价函数:
这里我们来讨论一下为什么用似然函数作为代价函数,在此之前先看看我们可以利用的已知条件是什么。
现在我们有初始化的权重\(w\),每一个样本的特征\(x\),和其真实类别\(y\)。现在我们通过净输入函数得到\(z\),希望利用\(z\)通过激活函数\(\phi (z)\)(现在我们的激活函数是S函数,其输出是一个\(0 \sim 1\)之间的值,代表该样本属于二分类中的哪一类)求解出这个样本属于正类的概率是多少。
我们做代价函数的目的是为了得到一个良好的权重\(w\),它可以最大程度上使我们最后拟合出的模型代表现实情况,所以\(w\)是现在需要求解的目标参数。怎么求解这个目标参数?
权重\(w\)使用在激活函数中,查看现在的激活函数——逻辑回归算法,而逻辑回归是一个概率模型。权重\(w\)是这个概率模型需要求解的未知参数值,模型迭代是通过每次计算反推最具有可能(最大概率)导致这些样本结果出现的参数。
而似然函数是用来描述已知随机变量输出结果时,未知参数的可能取值,是一个概率值。我们需要取的是最能代表所给数据的权重\(w\),即似然函数取得最大值。
而极大似然估计是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值(模型已定,参数未知)
所以我们使用似然函数作为代价函数一步步迭代模型的权重\(w\)。
统计学中,似然函数是一种关于统计模型参数的函数。给定输出\(x\)时,关于参数\(θ\)的似然函数\(L(θ|x)\)(在数值上)等于给定参数\(θ\)后变量\(X\)的概率:\(L(θ|x)=P(X=x|θ)\)。即算法上与算概率是一样的。
为了方便对似然函数最大值的求解,将似然函数对数化:
对数化可以将乘积求导转变为求和求导,其次可以降低数值下溢的可能性,这种情况可以在似然率非常小的情况可能发生。
现在,我们的代价函数\(J\),就变为:
这里变负号是为了方便理解,一般求解都是最小化代价函数,而求解似然函数是为了对\(l(w)\)求极大值。
这里我们计算一个样本训练实例的代价:
如果\(y=0\),第一项为零,如果\(y=1\),第二项为零:
下面通过图例观察:
#损失函数第一项
def cost_1(z):
return -np.log(sigmoid(z))
#损失函数第二项
def cost_0(z):
return -np.log(1 - sigmoid(z))
z = np.arange(-10, 10, 0.1)
phi_z = sigmoid(z)
c1 = [cost_1(x) for x in z]
plt.plot(phi_z, c1, label='J(w) if y = 1')
c0 = [cost_0(x) for x in z]
plt.plot(phi_z, c0, linestyle='--', label='J(w) if y = 0')
plt.ylim(0.0, 5.1)
plt.xlim([0, 1])
plt.xlabel('$\phi (z)$')
plt.ylabel('$J(w)$')
plt.legend(loc='best')
plt.show()
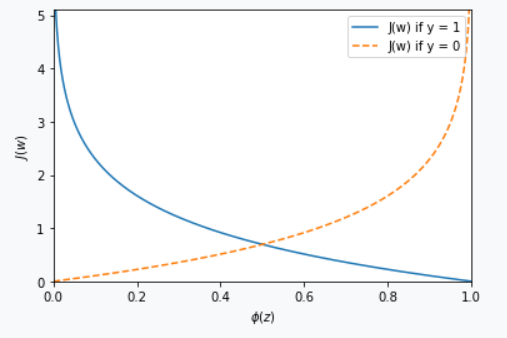
从图中可以看到如果正确的预测\(y=1\)则代价会接近0(实线),否则代价会趋无穷,正确预测\(y=-1\)(虚线)类似。
3 实现逻辑回归
要实现逻辑回归的话,可以使用Python-构建自适应线性神经元中的代码,调整其中的损失函数,激活函数就可以了。
class LogisticRegressionGD(object):
def __init__(self, eta = 0.05, n_iter = 100, random_state = 1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
def fit(self, X, y):
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])
self.cost_ = []
#开始迭代
for i in range(self.n_iter):
net_input = self.net_input(X)
output = self.activation(net_input)
errors = (y - output)
self.w_[1:] += self.eta * X.T.dot(errors)
self.w_[0] += self.eta * errors.sum()
#记录我们计算的逻辑回归的损失
cost = (-y.dot(np.log(output)) - ((1 - y).dot(np.log(1 - output))))
self.cost_.append(cost)
return self
def net_input(self, X):
return np.dot(X, self.w_[1:]) + self.w_[0]
def activation(self, z):
return 1.0 / (1 + np.exp(-np.clip(z, -250, 250)))
def predict(self, X):
return np.where(self.net_input(X) >= 0.0, 1, 0)
#二分类的数据
X_train_01_subset = X_train[(y_train == 0) | (y_train == 1)]
y_train_01_subset = y_train[(y_train == 0) | (y_train == 1)]
lrgd = LogisticRegressionGD(eta=0.05, n_iter=1000, random_state=1)
lrgd.fit(X_train_01_subset, y_train_01_subset)
from matplotlib.colors import ListedColormap
def plot_decision_regions(X, y, classifier, resolution=0.02):
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
#创建色度图,每类一种颜色
cmap = ListedColormap(colors[:len(np.unique(y))])
#设置网格图中的每个点xx1为x坐标,xx2为y坐标
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
#通过训练好的模型对图中每个点进行分类
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
#xx1.shape为(305, 235)就是网图中点的个数
Z = Z.reshape(xx1.shape)
#图中颜色会随z值变化,alpha是透明度
plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap)
#设置x轴和y轴的范围
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
#遍历每个y类(实际就两类)idx表示在数组np.unique(y)中的坐标,cl表示数组np.unique(y)中的值
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0],
y=X[y == cl, 1],
alpha=0.8,
c=colors[idx],
marker=markers[idx],
label=cl,
edgecolor='black')
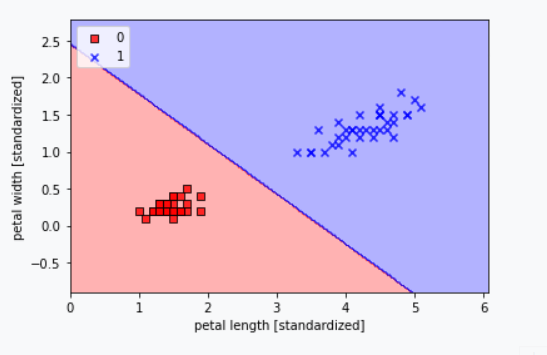
plot_decision_regions(X=X_train_01_subset, y=y_train_01_subset, classifier=lrgd)
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.show()
相关博客
参考
-
[1] Sebastian Raschka. Python机器学习(第2版)[M]. 机械工业出版社, 2017.
-
[2] 李航. 统计学习方法(第2版)[M]. 清华大学出版社, 2019.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号