Python-构建自适应线性神经元
Python-构建自适应线性神经元
1 自适应线性神经元
自适应性神经元(Adaline)可以视为感知器的优化和改进。
该算法说明了定义最小化连续性代价函数的关键概念。这为理解如逻辑回归、支持向量机和回归模型等更高级的机器学习算法奠定了基础。
1.1 Adaline与感知器的区别
Adaline的权重更新是基于线性激活函数,而感知器是基于单位阶跃函数,Adaline的线性激活函数\(\phi(z)\)是净输入的等同函数,即:
虽然线性激活函数可用于学习权重,但仍然使用阈值函数做最终的预测,这点和单位阶跃函数有点类似。感知机与自适应算法的主要区别图示如下:
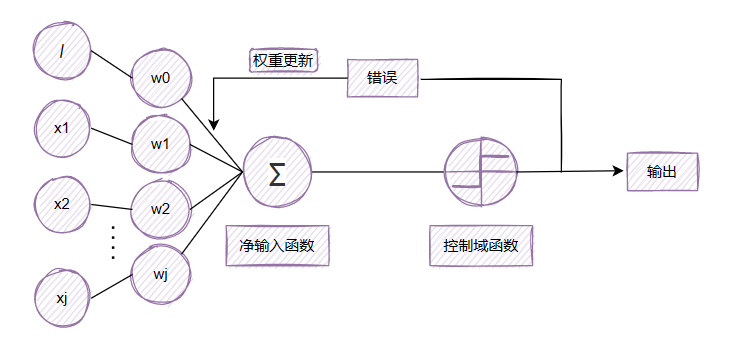
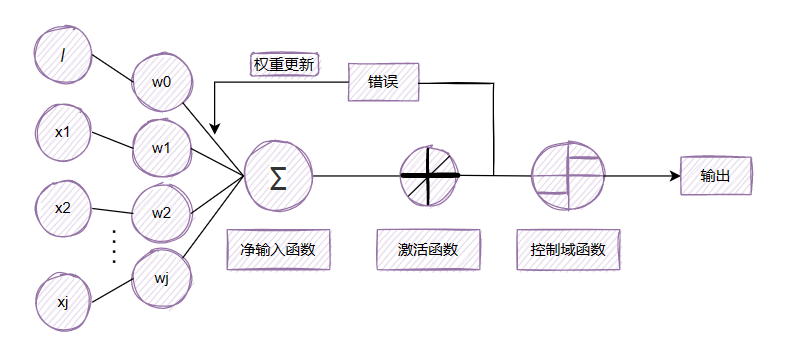
由图看出,在自适应神经元中,我们在激活函数后对模型权重进行更新,而在感知机中,我们在得出最终结果后才进行权重更新。这样我们的处理目标就发生了改变,在感知器中我们处理的是一个离散值,而在Adaline中,我们处理的是一个连续函数。
这样的处理是有好处的,一个光滑的函数我们有很多方法进行处理对他进行最优化处理。对单位阶跃函数来说,取值为离散值处理起来没有连续函数灵活,更主要的是在0处,单位阶跃函数是不可导的。
而对光滑函数来说其收敛速度更快,更能达到我们的目标。
Adaline中的\(\phi(z)\)的输出是一个实数,而感知机的\(\phi(z)\)是一个整数的二分类标签。并且Adaline的权重更新是基于所有的样本数据进行计算,感知器中的权重更新是根据单个样本的计算值进行更新。
1.2 梯度下降最小化代价函数
监督学习算法的一个关键是在学习过程中能够优化目标函数,自适应线性神经元的目标函数\(J\)定义为在计算结果和真正的分类标签之间的误差平方和(SSE):
公式前的\(\frac{1}{2}\)没有意义,只是为了方便。
Q:您猜是方便了什么?
A:为了抵消后面对损失函数求导出来后公式前的常数\(2\),您就说方没方便吧。
其实在以前机器学习方面计算中没有自动求导工具,为了方便计算,使公式变得更简洁所以做了这样的处理。现在都用深度学习框架自动求导,这样做的意义就不大了。
下面开始推导梯度,与单位阶跃函数相反,这种连续线性激活函数的主要优点是代价函数变得可分。代价函数的另一个优点是其凸起,凸起函数的主要特点是有极值点,因此可以用被称为梯度下降的简单而强大的优化算法来寻找权重,使代价函数取得最小。
梯度下降:
梯度下降(Gradient descent)是一个一阶最优化算法,通常也称为最陡下降法,但是不该与近似积分的最陡下降法(Method of steepest descent)混淆。要使用梯度下降找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点;这个过程则被称为梯度上升法。[1]
一般我们将梯度下降的逻辑描述为走下坡路直到局部或全局最小为止,而我们在训练中设置的学习率\(\eta\)与梯度斜率的乘积就是每次迭代步幅。
现在我们通过梯度下降代价函数\(J(w)\)的梯度\(\nabla J(\boldsymbol{w})\)朝反方向上迈出一步来更新权重:
其中将\(\Delta \boldsymbol{w}\)定义为负的梯度乘以学习率\(\eta\):
现在的目标是寻找\(w\)使得我们的代价函数\(J(w)\)最小,现在我们改变代价函数的形式,将\(w\)放入\(J(w)\)中:
对每个权重\(w_j\)求导:
这里求导后公式前的\(\frac{1}{2}\)就被抵消了。
这样权重\(w_j\) 的更新写为:
然后,同时更新所有权重,所以Adaline的学习规则就成为:
在这可能会产生这样的思考:所有权重是基于训练集中的所有样本计算,同时更新,在数据量小的时候计算机还能算过来,但是当数据量过大的时候,这样的计算是否效率过低。
实际情况也是这样,我们将权重更新基于训练集中所有样本计算,而不是在每个样本之后逐步更新权重的方法称为批量梯度下降。为了解决这个问题,一种常见的方法是使用随机梯度下降来替代批量梯度下降,这有时也被称为迭代或在线梯度下降。
该方法不是基于所有样本\(x^{(i)}\)的累积误差之和来更新权重:
\[\Delta \boldsymbol{w}=\eta \sum_i\left(y^{(i)}-\phi\left(z^{(i)}\right)\right) \boldsymbol{x}^{(i)} \]而是为每个训练样本逐渐更新权重:
\[\eta\left(y^{(i)}-\phi\left(z^{(i)}\right)\right) x^{(i)} \]这和感知机的权重更新过程类似。
1.3 代码
class AdalineGD(object):
def __init__(self, eta = 0.01, n_iter = 50, random_state = 1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
#训练函数
def fit(self, X, y):
#权重初始化
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])
self.cost_ = []
#开始迭代
for i in range(self.n_iter):
#通过净输入函数,这里的返回值是一个和X大小相等的一维长度为100的数组
net_input = self.net_input(X)
#通过激活函数
output = self.activation(net_input)
#计算J(w)中:y^{(i)} - w^T*x
errors = (y - output)
#更新权重
self.w_[1:] += self.eta * X.T.dot(errors)
self.w_[0] += self.eta * errors.sum()
#计算损失
cost = (errors**2).sum() / 2.0
#记录每一轮的损失
self.cost_.append(cost)
return self
#净输入函数
def net_input(self, X):
return np.dot(X, self.w_[1:]) + self.w_[0]
#激活函数
def activation(self, X):
return X
#阈值函数
def predict(self, X):
return np.where(self.activation(self.net_input(X)) >= 0.0, 1, -1)
在上一篇中没有说明,在此说明一下,在本次训练中,X的大小是(100,2),100个数据,2个特征。self.w_的大小是(3,1),也就是\(w_0,w_1,w_2\),三个权重,np.dot(X, self.w_[1:]) + self.w_[0]产生的是一个大小为(100,1)的数据。
#创建两个图表,设置子图的行列数,figsize设置子图的大小
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10, 4))
#实例化模型,学习率为0.01,训练,并返回每轮迭代的损失大小
ada1 = AdalineGD(n_iter=10, eta=0.01).fit(X, y)
#横坐标的大小为1~len(ada1.cost_),纵坐标的大小为0~log10(ada1.cost_)
ax[0].plot(range(1, len(ada1.cost_) + 1), np.log10(ada1.cost_), marker='o')
ax[0].set_xlabel('Epoch')
ax[0].set_ylabel('log(Sum-squared-error)')
ax[0].set_title('Adaline - Learning rate 0.01')
#实例化模型,学习率为0.0001
ada2 = AdalineGD(n_iter=10, eta=0.0001).fit(X, y)
#横坐标的大小为1~len(ada2.cost_),纵坐标的大小为0~(ada2.cost_)
ax[1].plot(range(1, len(ada2.cost_) + 1), ada2.cost_, marker='o')
ax[1].set_xlabel('Epoch')
ax[1].set_ylabel('Sum-squared-error')
ax[1].set_title('Adaline - Learning rate 0.0001')
plt.show()
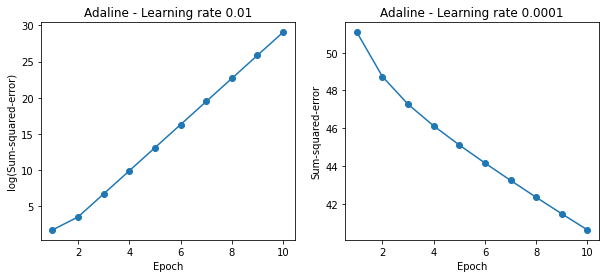
左图显示,当选择的学习率过大时,无法最小化代价函数,误差经过每次迭代变得越来越大。右图显示,当选择的学习率过小时,虽然损失函数可以收敛但是所需的迭代次数太多。
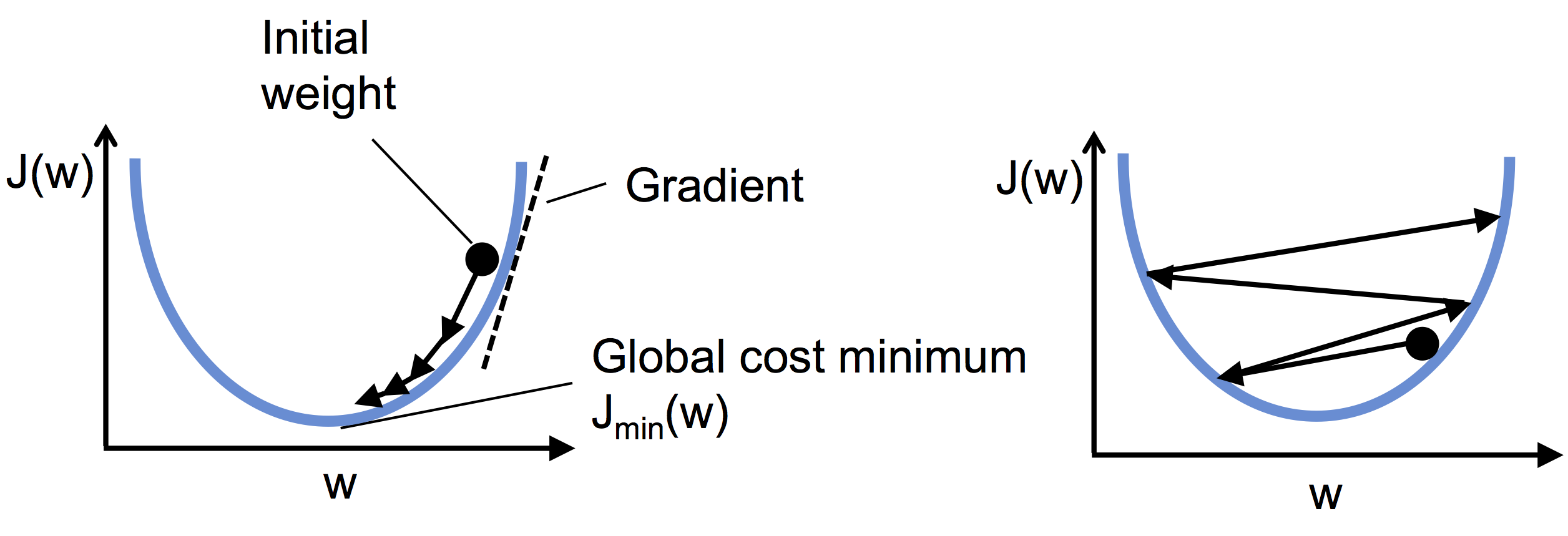
下图是对上面两图的形象解释:
2 通过调整特征改善梯度下降
一般来说,通过对某些特征进行调整是可以优化性能的。在本次所使用的数据来说,通过标准化特征尺度的方法可以加快收敛,这样可以使数据具有标准正态分布的特性,这有助于梯度下降学习。标准化可以改变每个特征的平均值以使其居中为零,而且每个特征的偏差为1。对于第\(j\)个特征,标准化的公式为:
使用时,应对数据集的每个特征\(j\)都进行标准化。
2.1代码
#标准化
X_std = np.copy(X)
X_std[:, 0] = (X[:, 0] - X[:, 0].mean()) / X[:, 0].std()
X_std[:, 1] = (X[:, 1] - X[:, 1].mean()) / X[:, 1].std()
#训练模型
ada = AdalineGD(n_iter=15, eta=0.01)
ada.fit(X_std, y)
#画出决策边界,plot_decision_regions函数是在上一篇实现感知器的文章中实现的
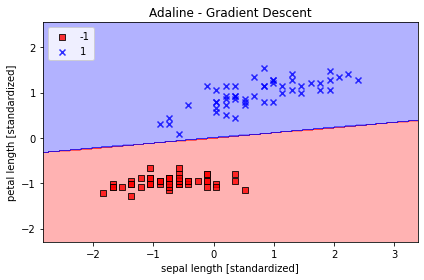
plot_decision_regions(X_std, y, classifier=ada)
plt.title('Adaline - Gradient Descent')
plt.xlabel('sepal length [standardized]')
plt.ylabel('petal length [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
#画出代价下降图
plt.plot(range(1, len(ada.cost_) + 1), ada.cost_, marker='o')
plt.xlabel('Epoch')
plt.ylabel('Sum - squared - error')
plt.show()
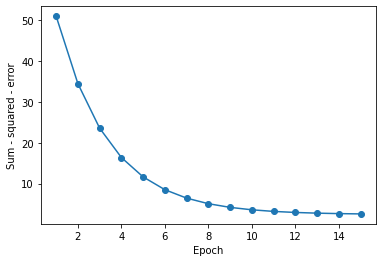
上图可以看出,当我们标准化后,先前不能使模型收敛的学习率已经可以使模型收敛了,并且收敛速度还挺快。
3 大规模机器学习与随机梯度下降
上述更新模型的过程是使用批量梯度下降来进行的,也就是权重每次更新是基于整个训练集计算代价梯度。但是当数据量太大的时候,这种更新权重的方法在计算上会相当昂贵,每向全局最小值走一步都需要重新评估整个训练集。
我们通过使用随机梯度下降来代替批量梯度下降,该方法不是基于所有样本\(x^{(i)}\)的累积误差之和来更新权重:
而是为每个训练样本逐渐更新权重:
这和感知机的权重更新过程类似。
虽然随机梯度下降可以看作梯度下降的近似,但因为权重更新更加频繁,所以通常收敛得更快。
我们可以进行合理思考,因为每次更新使用的都是单个数据,所以其在相同时间内权重更新的次数更多,这样的话模型收敛的速度更快。抽取随机的数据进行误差计算,其误差比批量梯度下降要大,由于单个样本得到的损失函数相对于用整个训练集得到的损失函数具有随机性,反而会有助于随机梯度下降算法避免陷入局部最小点。
在随机梯度下降中,我们通常使用不断减小的自适应学习率替代固定学习率\(\eta\),例如:
\[\frac{c_1}{\text { 【迭代数】+ } c_2} \]其中\(c_1,c_2\)为常数注意随机梯度下降没有达到全局最小值,但是在一个非常靠近这个点的区域。用适应性学习率可以把代价降到最低。
我们现在只需要对权重更新算法进行修改就能将实现随机梯度下降。第一个修改是fit方法内用每一个训练样本更新权重参数\(w\),第二个修改是增加partial_fit方法,第三个修改是增加shuffle方法打乱训练集顺序。
3.1 代码
class AdalineSGD(object):
def __init__(self, eta=0.01, n_iter = 10, shuffle=True, random_state = None):
self.eta = eta
self.n_iter = n_iter
self.w_initialized = False
self.shuffle = shuffle
self.random_state = random_state
def fit(self, X, y):
#初始化权重,权重大小为X.shape[1]
self._initialize_weights(X.shape[1])
#记录每次迭代的损失
self.cost_ = []
#开始迭代
for i in range(self.n_iter):
#随机梯度下降,将数据打乱
if self.shuffle:
X, y = self._shuffle(X, y)
cost = []
#通过_update_weights函数更新权重
for xi, target in zip(X, y):
cost.append(self._update_weights(xi, target))
#计算平均损失
avg_cost = sum(cost) / len(y)
self.cost_.append(avg_cost)
return self
def partial_fit(self, X, y):
#如果权重没有初始化
if not self.w_initialized:
self._initialize_weights(X.shape[1])
if y.ravel().shape[0] > 1:
for xi, target in zip(X, y):
self._update_weights(xi, target)
else:
self._update_weights(X, y)
return self
def _shuffle(self, X, y):
r = self.rgen.permutation(len(y))
return X[r], y[r]
def _initialize_weights(self, m):
#权重初始化
self.rgen = np.random.RandomState(self.random_state)
self.w_ = self.rgen.normal(loc=0.0, scale=0.01, size = 1 + m)
self.w_initialized = True
def _update_weights(self, xi, target):
#每个数据更新一次权重
output = self.activation(self.net_input(xi))
error = (target - output)
self.w_[1:] += self.eta * xi.dot(error)
self.w_[0] += self.eta * error
cost = 0.5 * error**2
return cost
#净输入函数
def net_input(self, X):
return np.dot(X, self.w_[1:]) + self.w_[0]
#激活函数
def activation(self, X):
return X
#阈值函数
def predict(self, X):
return np.where(self.activation(self.net_input(X)) >= 0.0, 1, -1)
仔细观察其实我们可以使用随机梯度下降实现在线学习,在模型训练好后,当有新的数据收集到,我们就将新的数据输入来更新权重,如此重复,这个过程被称为在线学习或增量学习,在线学习中,模型可以随着新训练数据的到来进行联机训练。在代码中使用额外的partial_fit()方法,不再重新初始化权重。为了检验算法训练后是否收敛,每次迭代计算训练样本的平均损失。
ada = AdalineSGD(n_iter=15, eta=0.01, random_state=1)
ada.fit(X_std, y)
plot_decision_regions(X_std, y, classifier=ada)
plt.title('Adaline - Stochastic Gradient Descent')
plt.xlabel('sepal length [standardized]')
plt.ylabel('petal length [standardized]')
plt.legend(loc='upper left')
plt.show()
plt.plot(range(1, len(ada.cost_) + 1), ada.cost_, marker='o')
plt.xlabel('Epoch')
plt.ylabel('Average Cost')
plt.show()
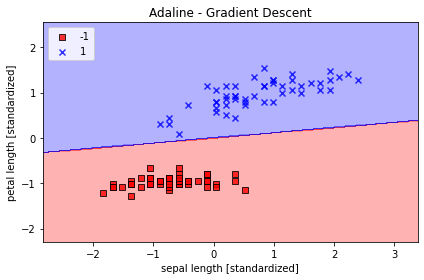
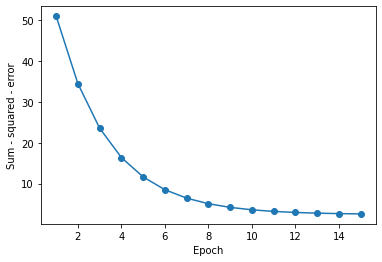
可以看到和平均代价下降的很快,最终的决策边界和批量梯度下降结果类似。如果以后有新的数据可以使用partial_fit()方法来更新模型。
相关博客
上一章:Python-构建感知器
下一篇:Python-实现逻辑回归
参考
-
[2] Sebastian Raschka. Python机器学习(第2版)[M]. 机械工业出版社, 2017.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号