
1、配置ssh免密登录
(本人使用的是centOS7虚拟机)
(本人未在root用户下安装,建议使用root用户,不然很麻烦!!)
① 本机无密钥登录
1.进入~/.ssh目录(若无,则执行一次ssh localhost),
2.执行ssh-keygen -t rsa命令(回车即可),

我弄过了所以已经有啦!
3.再执行cat ./id_rsa.pub >> ./authorized_keys命令,把id_rsa.pub追加到授权的key里面,
4.给authorized_keys授权chmod 644 authorized_keys, ls -al ~/.ssh命令看权限,
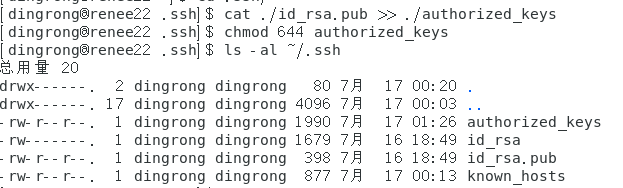
5.重启 sudo service sshd restart,

6.连接 ssh localhost(yes/no,手动输入yes)
7.退出 exit
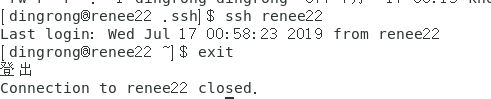
我这里主机名为renee22,用户名为dingrong
② 与其他机子的无密钥登录
1.其他机子一样执行①中1、2,
2.本机把authorized_keys分发到其他机子上(会提示输入密码,输入密码即可),scp ./authorized_keys username(用户名)@(ip地址/主机名):/root/.ssh (目录根据自己机子来)

我这里另一个机子的主机名为renee13,用户名为dingr
3.在其他机子上执行①中步骤4授权
4.尝试连接其他机子,ssh 用户名@ip地址/域名

③ 若有错误
1.进入/etc/ssh/sshd_config文件,

RSAAuthentication yes
PubkeyAuthentication yes
这两个注释去掉

2.authorized_keys文件权限问题,记得授权
3.本机能不能访问22端口,命令lsof -i:22

4.分发authorized_keys时,注意用户名和主机名要对应上,不然密码输入会错误。
④主机直接域名通信(需要通信的主机都要改)
ifconfig查看ip

在虚拟机的菜单-编辑->虚拟网络编辑器中能看到gateway

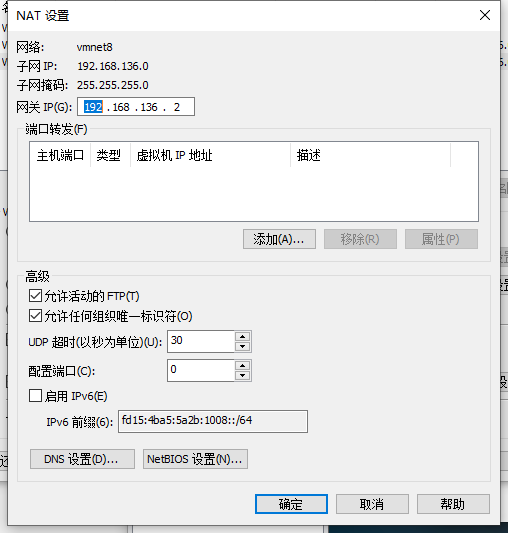
编辑配置文件,sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33,将ip信息添加进去


我这里主机ip为192.168.136.133,另一个是192.168.136.130
ping一下,看看能不能通(如果不通,检查一下防火墙有没有关)

设置dns就可以域名通信了
进入到配置文件中sudo vim /etc/resolv.conf


修改hostname主机名
hostnamectl set-hostname 主机名 #修改三种主机名
hostnamectl –static set-hostname 主机名 #只会修改static主机名
修改配置文件,sudo vim /etc/hosts(每个主机都要改)

ping 主机名

2、安装jdk(两个机子都要装)
先删除centos7自带的openjdk
①rpm -qa | grep java
②rpm -e --nodeps Openjdk
(我装的是jdk1.8.0_221)
jdk下载地址
需要登录哦!!!
1.下载完成后解压到/usr/local/java目录下(没有java目录就创建)
tar -xzvf jdk-8u221-linux-x64.tar.gz
2.配置环境变量
sudo vim /etc/profile
JAVA_HOME=/usr/local/java/jdk1.8.0_221
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
source /etc/profile(使文件生效)
3.验证
java -version
3、安装hadoop
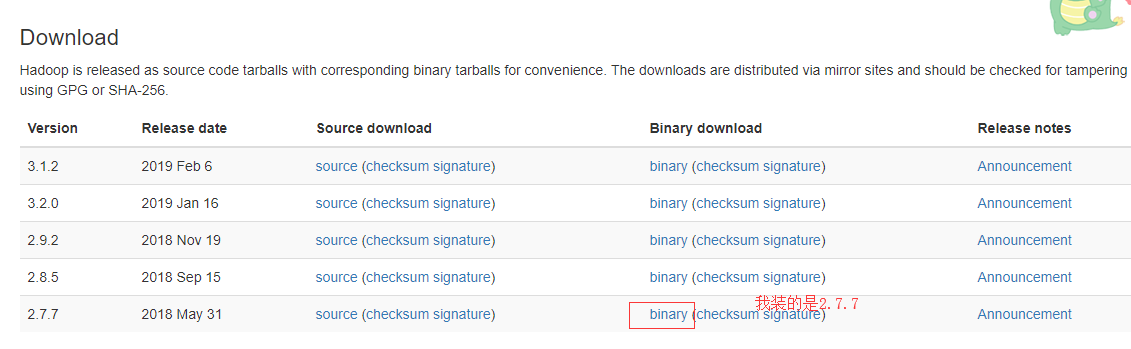
1.同样解压,我设的目录是/usr/local/hadoop
2.配置环境变量
sudo vim /etc/profile
JAVA_HOME=/usr/local/java/jdk1.8.0_221
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME JRE_HOME CLASS_PATH HADOOP_HOME HADOOP_COMMON_LIB_NATIVE_DIR PATH
source /etc/profile(使文件生效)
在上面jdk环境变量下添加就好。
3.修改hadoop的配置文件
进入到/usr/local/hadoop/hadoop-2.7.7/etc/hadoop/目录下,在hadoop-env.sh和yarn-env.sh两个文件中添加JAVA_HOME
cd /usr/local/hadoop/hadoop-2.7.7/etc/hadoop
sudo vim hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HDFS_NAMENODE_USER=dingrong
export HDFS_DATANODE_USER=dingrong
export HDFS_SECONDARYNAMENODE_USER=dingrong
export YARN_RESOURCEMANAGER_USER=dingrong
export YARN_NODEMANAGER_USER=dingrong
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"(更改hadoop_opts)
source hadoop-env.sh(使文件生效)
sudo vim yarn-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
source yarn-env.sh
另外还有四个site.xml的文件需要配置
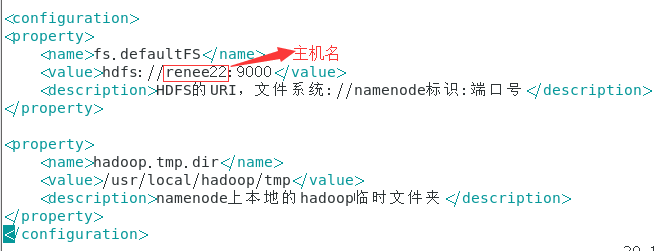
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://renee22:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
</property>
</configuration>

yarn-site.xml
先执行 hadoop classpath命令,并复制返回的地址


mapred-site.xml

slaves文件中添加你的主机和节点
4.将hadoop分发到其他节点,用scp命令

5.格式化namenode
进入hadoop-2.7.7下的sbin目录下执行 命令
hdfs namenode -format

如果格式化错误为
ERROR namenode.NameNode: java.io.IOException: Cannot create directory /export/home/dfs/name/current
ERROR namenode.NameNode: java.io.IOException: Cannot remove current directory: /usr/local/hadoop/hdfsconf/name/current
执行命令
sudo chmod -R a+w /usr/local/hadoop

6.启动hadoop
执行这两个命令
./start-dfs.sh
./start-yarn.sh
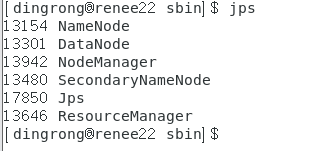
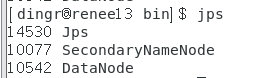
7.jps查看
8.访问浏览器
http://192.168.136.133:50070或者http://renee22:50070( 这个在两个虚拟机也就是两个节点上都能访问!)
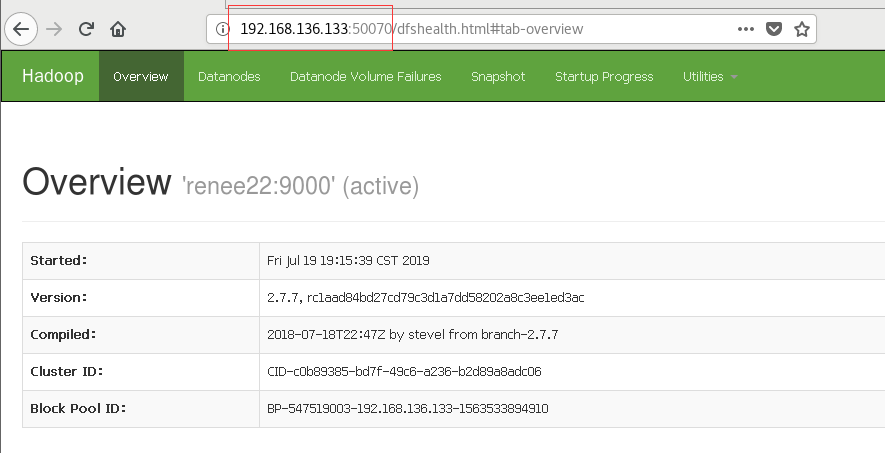
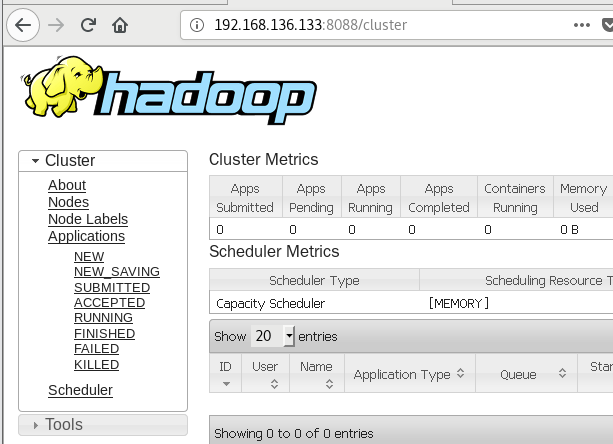
9.访问集群所有应用程序默认8088
4、安装zookeeper(主从节点都要)
1.同上步骤解压到/usr/local/zookeeper下
2.进入到目录conf下,执行cp zoo_sample.cfg zoo.cfg命令,复制 zoo_sample.cfg 到 zoo.cfg文件中

3.编辑zoo.cfg文件sudo vim zoo.cfg

4.进入到目录data下,创建myid文件并添加1(在dingrong@renee22中【换成自己的】),2(在dingr@renee13中)

5.编辑配置文件/etc/profile
ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.14

6.进入到bin目录下,执行 ./zkServer.sh start,启动zk服务
【注】:要两台都启动,可查看zookeeper.out日志文件查看错误
查看zookeeper状态,一个是leader,一个是follewer


5、安装hbase
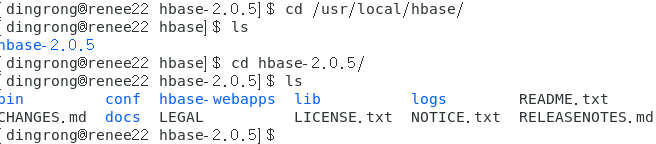
1.解压到/usr/local/hbase目录下
2.修改配置文件 ,到conf目录下
hbase-env.sh


hbase-site.xml
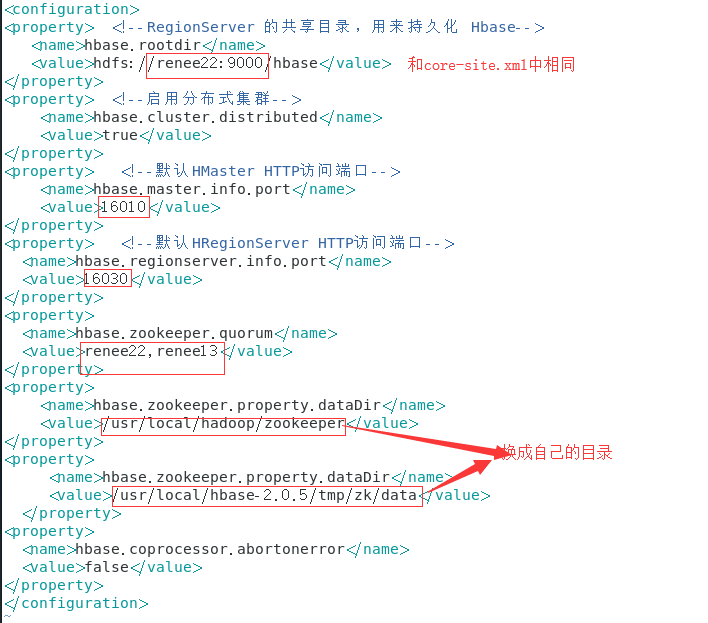
regionservers

/etc/profile
HBASE_HOME=/usr/local/hbase/hbase-2.0.5

(记得source生效)
3.scp拷到另一节点
dingrong@renee22执行
scp -r /usr/local/hbase dingr@renee13:/home/dingr
dingr@renee13执行
mv ~/hbase /usr/local/
【注】:root用户可直接拷贝至/usr/local/目录下,非root用户可先拷贝至home目录在移动
4.启动hbase
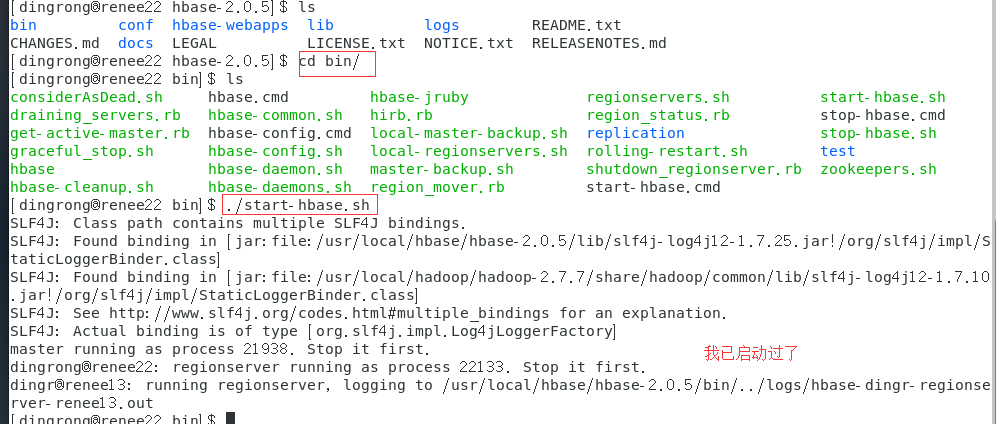
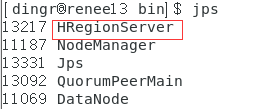
5.jps命令查看

6.浏览器查看

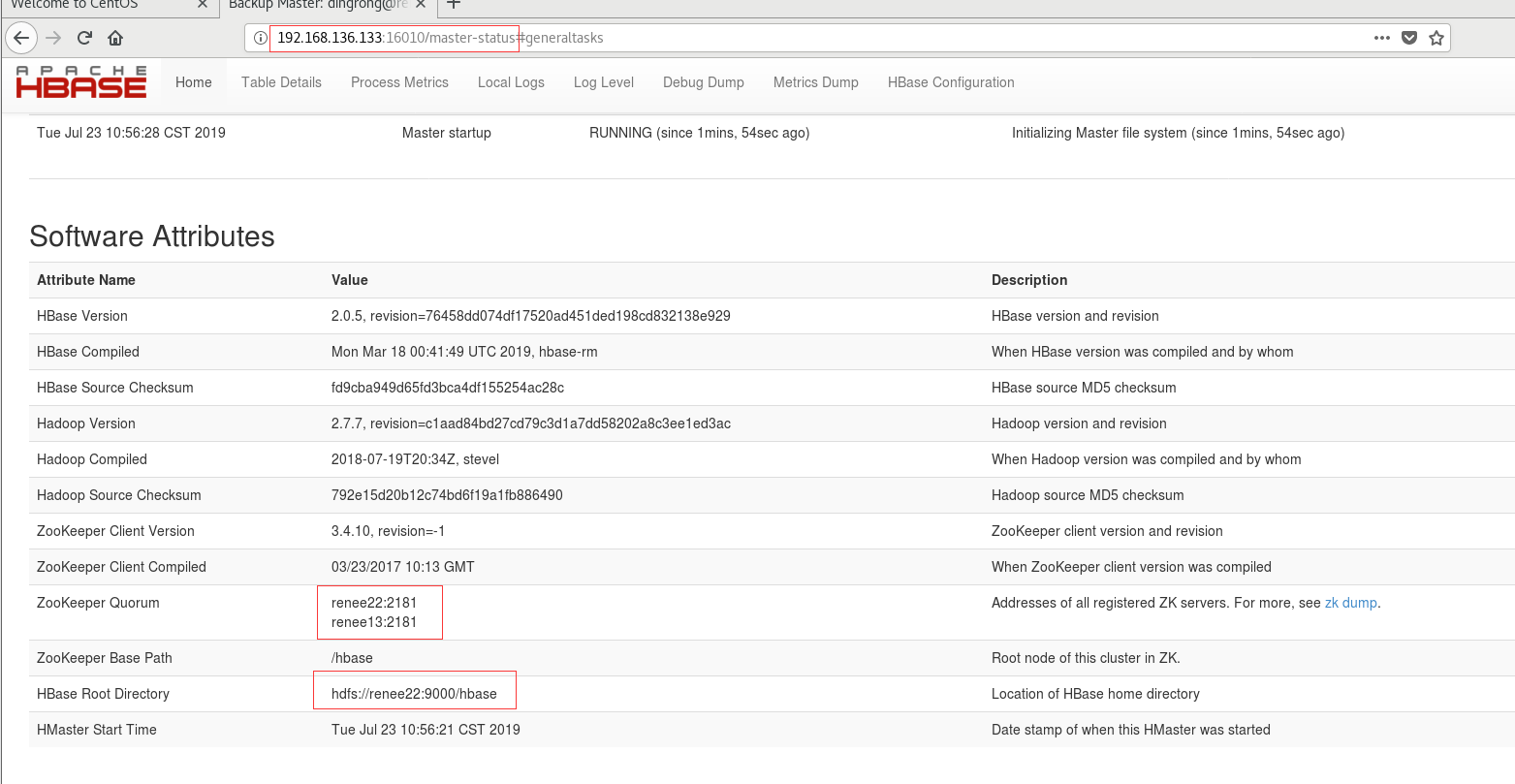

【注】:
查看时间命令 timedatectl
调整硬件时间和本地一致 timedatectl set-local-rtc 1
linux同步时间 ntpdate ntp.sjtu.edu.cn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号