
Dubbo
Dubbo
1.分布式系统中的相关概念
如果理解了分布式系统的相关概念,那么对于后期我们学习服务框架是很有帮助的。
因为服务框架就是为了解决企业中比较棘手的问题而存在的,有问题必定有需求,而描述需求和问题的就是这些概念。
1.1互联网项目架构目标
1.1.1什么是互联网项目
说起互联网项目,那就不得不提到它的兄弟:传统项目。
传统项目和互联网项目分别是什么呢?
- 传统项目就是企业内部使用的项目,如CRM、OA、HR、学校选课系统等。
- 互联网项目则是我们日常生活中使用的项目,如微信、淘宝、B站等。
两者有什么不同呢?
- 用户群体不同:
- 传统项目的用户群体是企业内部员工
- 互联网项目的用户群体是广大的网民们
- 用户数量不同:
- 传统项目所面对的内部员工可能只是几千几万级别的
- 互联网项目所面对的网民会是上亿级别的,这就涉及到高并发的问题了
- 用户的忍耐力不同:
- 即使传统项目UI不美观,反应速度慢,甚至会报404、500,内部员工还是得使用,因为是依靠公司生活的。
- 而假如互联网项目出现功能异常,网络用户可随时更换其他企业的同类型产品,没有忍耐这一说。
互联网项目为了保证用户不流失,需要提高用户体验,而影响用户体验的主要有以下四点:
- 美观:一个漂亮的用户界面很重要,如果做的界面很丑,用户就不爱用你家的产品。
- 功能:产品的功能要完善、实用。
- 响应速度:响应速度很重要,如果一个页面几十秒才能打开,那么用户的耐心会消耗光。
- 稳定性:保证系统的稳定,不出现404或者500等错误。
以上四点,前两点和我们关系不大,因为美不美观是UI、美工说了算的,功能是产品经理说了算的。
后两点,响应速度和稳定性是我们负责的。稳定性不用说了,响应速度的标准很重要。
衡量一个网站速度是否快:
- 打开一个新页面一瞬间完成(约0.36秒)
- 页面内跳转一刹那间完成(约0.018秒)
1.1.2互联网项目特点
- 用户多
- 流量大,并发高
- 海量数据
- 易受攻击:面向公网,任何人都能访问
- 功能繁琐
- 变更快:当出现热点时,需要快速开发出相应功能,抢占市场
1.1.3互联网项目的架构目标
面对互联网项目的特点,在设计项目架构的时候,需要达到怎样的目标呢?
1.高性能:提供快速的访问体验
-
衡量一个网站的性能指标:
-
响应时间:指从开始执行一个请求到最后收到响应数据所花费的总时间
-
并发数:指系统同时能处理的请求数量
- 并发连接数:指客户端向服务端发起请求,并建立了TCP连接。每秒服务器连接的总TCP数量
- 请求数:也被称为QPS(Query Per Second)指每秒多少请求
- 并发用户数:单位时间内可以容纳多少用户访问系统
- 请求数 >= 连接数

-
吞吐量:指单位时间内系统能处理的请求数量
- QPS:Query Per Second 每秒查询数
- TPS:Transactions Per Second 每秒事务数
- 一个事务指一个客户机向服务器发送请求然后服务器作出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
- 一个页面的一次访问,只会形成一个TPS;但一次页面请求,可能产生多次对服务器的请求,就会有多个QPS。故:
QPS >= 并发连接数 >= TPS
-
2.高可用:保证网站服务一直可以正常访问,比如说淘宝、京东,必须24小时不间断提供服务。
3.可伸缩:通过硬件增加/减少,提高/降低处理能力
4.高可扩展性:系统间耦合低,可以便捷地通过新增/移除方式,增加/减少新的功能或者模块
5.安全性:提供网站安全访问和数据加密,安全存储等策略
6.敏捷性:随需应变,快速响应
1.2集群和分布式
- 集群:很多“人”一起,干一样的事
- 分布式:很多“人”一起,干不一样的事。这些不一样的事,合起来是一件大事
1.2.1生活中的集群和分布式
比如说我开了一个饭店,先雇佣了一个大厨,这个大厨负责洗菜、切菜、炒菜。

随着饭店的发展,顾客越来越多,大厨一个人力不从心,忙不过来。为了增加效率,我又雇佣了一名厨师。
原来的大厨和现在新雇的范厨师都要洗菜、切菜、炒菜,做的活是一样的,于是形成了一个集群。
有了这样的一个集群之后,好处就显而易见了:
- 高性能:原来的大厨一个小时能做10份菜,新雇的范厨师一小时也能做10份菜,现在我们整个饭店一小时能对外提供20份菜,效率是原来的2倍。
- 高可用:假如范厨师生病了,没法做菜,那么我们饭店还有原来的大厨能做菜,不会歇业。

又过了一段时间,我去参加了一个管理培训,发现原来的经营方式效率太低了。
我的厨师贵在炒菜能力上,但现在他们浪费了大量的时间在洗菜和切菜上。为了让他们专注于炒菜,我又分别为这两个大厨配了专门洗菜和切菜的人。
现在,范厨师、洗菜的人、切菜的人做的工作是不一样的,但他们的工作合起来就是做饭这件大事,那么他们三个人之间就构成了一个分布式。同样,原来的大厨、洗菜的人、切菜的人也构成了一个分布式。
同时,共同洗菜的人和共同切菜的人也构成了相应的集群。

经营一段时间后,我发现只分配两个人去洗菜还是不太够用,为了提升总体洗菜的效率,我又雇了一个人来洗菜。
这种操作就是可伸缩,哪个模块效率低,我就给它多分配资源。

又过了一段时间,市面上新推出了切菜机器人,比人的效率高出几倍。为了提升切菜效率,我把原来的两个负责切菜的人开除了,买了两台切菜机器人负责切菜。
这种操作就是高扩展性,哪个模块过时了,我就把它替换为新的模块。

1.2.2互联网中的集群和分布式
早期单机架构(只有一个大厨):
把项目模块A、B、C、D都部署在一个web服务器里,对外提供服务。
效率很低,有很多问题。

搭建集群(请多个大厨):
我们搞三个web服务器,每个服务器里都部署一份项目。而为了能对外提供服务,需要一个软件来做负载均衡,当接收到请求时,自动转发到节点中去。
搭建集群后,整个项目的效率和可用性都大大提升了。但是目前A、B、C、D模块都是放在一个服务器里的,伸缩和扩展做起来都比较麻烦。

集群分布式(给大厨分工):
我们在原来的基础上,把AB和CD模块分别放到不同服务器里去。如此一来,部署AB模块的服务器与部署CD模块的服务器就构成了一个分布式。
同时,整个项目里还存在其他同样功能的服务器,于是就形成了集群分布式。

集群分布式的好处:
1)可伸缩
如果说部署AB模块的服务器集群效率不够高,我们就可以再加一个部署AB模块的服务器

2)高扩展性
模块拆分后,模块间耦合度大大降低了。如果现在需要新加一个模块E,我们只需要在项目里加入一个部署了E模块的服务器即可,对其他模块没有影响。

总结集群和分布式:
- 集群:
- 很多“人”一起,干一样的事
- 一个业务模块,部署在多台服务器上
- 分布式:
- 很多“人”一起,干不一样的事。这些不一样的事,合起来是一件大事
- 一个很大的业务系统,拆分称小的业务模块,分别部署在不同的机器上
1.3架构演进
架构的演进:

1.3.1单体架构
单体架构就是把项目模块A、B、C、D都部署在一个服务器里,对外提供服务。
当然,这里说的单体架构只是不拆分业务模块的意思,我们还可以对其搭建集群。如果不搭建集群,那么就是单机架构。

单体架构的优点:开发和部署都很简单,小项目首选
单体架构的缺点:
- 项目启动慢:所有模块都放在一块,负荷高。
- 可靠性差:如果项目里一个模块挂了,其他模块也会跟着挂。
- 可伸缩性差:如果C模块的访问量大,需要提升C模块的效率,那么就只能再添加一个部署了所有模块的服务器。
- 扩展性和可维护性差:如果想要添加新的功能模块,就只能和原有的所有模块放在一起,添加的过程会影响其他所有模块。
- 性能低:同时运行所有模块肯定没有运行单个模块的效率高。
1.3.2垂直架构
垂直架构就是将单体架构里的多个模块拆分成多个独立的项目,形成多个独立的单体架构。
当然,我们不能将其称之为分布式,因为项目与项目之间是独立的,不进行交互的。

垂直架构的优点:
- 项目启动快:拆分模块后,单个项目启动的负荷变小。
- 可靠性强:即使有模块挂了,也不会影响其他项目里的模块。
- 可伸缩性强:如果某个模块效率低,可以对其搭建集群。
- 扩展性和可维护性高:如果想要添加新的功能模块,不会影响过多其他模块。
- 性能高:单个项目运行的模块量小了,效率自然就高了。
垂直架构的缺点:重复功能太多
假如说原本单体架构时,ABCD四个模块都需要访问数据库,就需要加入一个数据访问模块E

而改成垂直架构后,分离的AB模块项目和CD模块项目还是需要访问数据库,就需要在两个项目中都加一个模块E

这样就有了重复模块,当独立的项目变多时,会造成极大的资源浪费。
1.3.3分布式架构
分布式架构是在垂直架构的基础上,将公共业务模块抽取出来,作为独立的服务,供其他调用者消费,以实现服务的共享和重用。其中,服务消费者是通过RPC来调用服务提供者的。
RPC: Remote Procedure Call 远程过程调用。有非常多的协议和技术都实现了RPC的过程。比如:HTTP REST风格,Java RMI规范、WebService SOAP协议、Hession等等。
我们要学的Dubbo框架就是用于实现RPC的。

分布式架构解决了垂直架构重复功能多的问题,但也有缺点:
服务提供者一旦变更,所有服务消费者都要随着变更。

1.3.4SOA架构
现在有A到F六个服务,服务之间需要相互调用。
如果按照分布式架构,当一个服务改变时,会影响到其他服务

那么我们就不让它们相互调用了,在所有服务之间,设置一个总线ESB,让所有服务都通过这个ESB来通信。

SOA:(Service-Oriented Architecture,面向服务的架构)是一个组件模型,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和契约联系起来。
ESB:(Enterparise Servce Bus) 企业服务总线,服务中介。主要是提供了一个服务于服务之间的交互。ESB 包含的功能如:负载均衡,流量控制,加密处理,服务的监控,异常处理,监控告急等等。
ESB就好比是一个中介,当服务A要调用服务D时,会访问ESB,ESB会找到服务D的地址并将服务A的请求转发给服务D。
SOA架构解决了分布式架构的问题,当服务提供者发生变更时,其他服务不需要改变。
1.3.5微服务架构
微服务架构是在 SOA 上做的升华,微服务架构强调的一个重点是“业务需要彻底的组件化和服务化”,原有的单个业务系统会拆分为多个可以独立开发、设计、运行的小应用。这些小应用之间通过服务完成交互和集成。
微服务架构 = 80%的SOA服务架构思想 + 100%的组件化架构思想 + 80%的领域建模思想

特点:
- 服务实现组件化:开发者可以自由选择开发技术。也不需要协调其他团队
- 服务之间交互一般使用REST API
- 去中心化:每个微服务有自己私有的数据库持久化业务数据
- 自动化部署:把应用拆分成为一个一个独立的单个服务,方便自动化部署、测试、运维
1.3.5总结
- Dubbo是SOA时代的产物
- SpringCloud是微服务时代的产物
2.Dubbo概述
2.1Dubbo的概念
Apache Dubbo 是一款高性能、轻量级的开源Java RPC框架。
提供了六大核心能力:面向接口代理的高性能RPC调用,智能容错和负载均衡,服务自动注册和发现,高度可扩展能力,运行期流量调度,可视化的服务治理与运维。
Dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。
官网地址:https://dubbo.apache.org/zh/

特性:

2.2Dubbo的架构

- Container:服务运行容器,负责启动、加载、运行服务提供者。
- Provider:服务提供者,暴露服务的服务提供方。服务提供者在启动时,向注册中心注册自己提供的服务。
- Consumer:服务消费者,调用远程服务的服务消费方。服务消费者在启动时,向注册中心订阅自己需要的服务。服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- Register:注册中心,返回服务提供者的地址列表给消费者。如果有变更,注册中心将基于长连接推送变更数据给消费者。
- Monitor:监控中心,监控调用服务的次数。服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
流程描述:
- 服务提供者向注册中心注册自己提供的服务
- 服务消费者需要调用服务提供者的服务,但是不能直接调用,需要先从注册中心订阅自己需要的服务
- 注册中心接收到服务消费者的订阅后,返回服务消费者需要调用的服务提供者地址
- 服务消费者接收到地址后,根据地址调用服务提供者。调用的过程使用的就是RPC,Dubbo框架内部已经实现好了,我们直接使用Dubbo即可。
3.Dubbo快速入门
3.1安装Zookeeper服务器
Zookeeper服务器可作为Dubbo架构的注册中心使用,这也是官方推荐的。
ZooKeeper服务器需要部署在linux系统上。
ZooKeeper服务器是用Java创建的,它运行在JVM之上,需要在linux系统上安装jdk1.8及以上版本。
3.1.1在linux上安装jdk
1.准备相关软件
1)本人使用的是linux系统是:CentOS-6.7-i386
链接:https://pan.baidu.com/s/1LIFL80C2vD4HBJCy-MJ-VQ
提取码:2333

挂载的虚拟机密码:itcast
2)使用的jdk是:jdk-8u5-linux-i586.tar.gz
链接:https://pan.baidu.com/s/1Wm6UAxlNWPWoCz08k0fgoQ
提取码:2333
官网下载地址:https://www.oracle.com/java/technologies/downloads/#java8
3)使用的远程访问工具是:finalshell
下载地址:https://www.jb51.net/softs/717120.html
2.上传jdk到Linux虚拟机
开启虚拟机,查询ip地址,使用finalshell连接到虚拟机,对虚拟机进行操作。
在linux的/usr/local目录下新建一个文件夹,命名为jdk,
把jdk文件上传到linux的/usr/local/jdk目录下

3.卸载linux自带的jdk
linux系统在安装时自带了open-jdk,不过我们不需要,卸载后安装我们自己的。
查看jdk版本:
java -version
查看已安装的jdk信息:
rpm -qa | grep java
卸载jdk:
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.35-1.13.7.1.el6_6.i686
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.79-2.5.5.4.el6.i686
4.解压缩上传的jdk文件
我们在linux上安装的软件通常都放在/usr/local目录下,由于我们之前直接把jdk文件上传到了该目录下,所以不需要再将jdk文件转移到这里了。
转移文件命令(切换到文件所在目录):
mv jdk-8u5-linux-i586.tar.gz /usr/local/jdk/
切换到/usr/local/jdk,也就是jdk所在目录,然后直接解压:
tar -zxvf jdk-8u5-linux-i586.tar.gz
5.配置jdk环境变量
1)打开profile文件
vim /etc/profile
2)在末尾添加如下命令:
JAVA_HOME=/usr/local/jdk/jdk1.8.0_05
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
保存退出
3)刷新profile文件,使profile文件立即生效
source /etc/profile
3.1.2在linux上安装ZooKeeper
1.准备ZooKeeper
链接:https://pan.baidu.com/s/1TZ1H3rSUVYawIEzTVOPkqg
提取码:2333
2.上传ZooKeeper到linux虚拟机
1)在/opt目录下创建zookeeper目录
cd /opt#切换到opt目录
mkdir zookeeper#新建zookeeper目录
2)将ZooKeeper文件上传到/opt/zookeeper目录下
3.解压
将tar包解压到/opt/zookeeper目录下
tar -zxvf apache-zookeeper-3.5.6-bin.tar.gz
4.配置
1)进入到解压缩后的conf目录下,拷贝zoo_sample.cfg为zoo.cfg
#进入到conf目录
cd /opt/zookeeper/apache-zookeeper-3.5.6-bin/conf/
#拷贝
cp zoo_sample.cfg zoo.cfg
2)配置zoo.cfg
#打开目录
cd /opt/zookeeper/
#创建zooKeeper存储数据目录
mkdir zkdata
#修改zoo.cfg
vim /opt/zookeeper/apache-zookeeper-3.5.6-bin/conf/zoo.cfg
修改数据存储目录:dataDir=/opt/zookeeper/zkdata

保存退出,至此,Zookeeper已安装完毕。
3.1.3启动ZooKeeper
1.启动ZooKeeper
#进入ZooKeeper的bin目录
cd /opt/zookeeper/apache-zookeeper-3.5.6-bin/bin/
#启动
./zkServer.sh start

看到上图表示ZooKeeper成功启动
2.查看ZooKeeper状态
./zkServer.sh status

zookeeper启动成功。standalone代表zk没有搭建集群,现在是单节点
3.2Dubbo快速入门项目
3.2.1思路分析

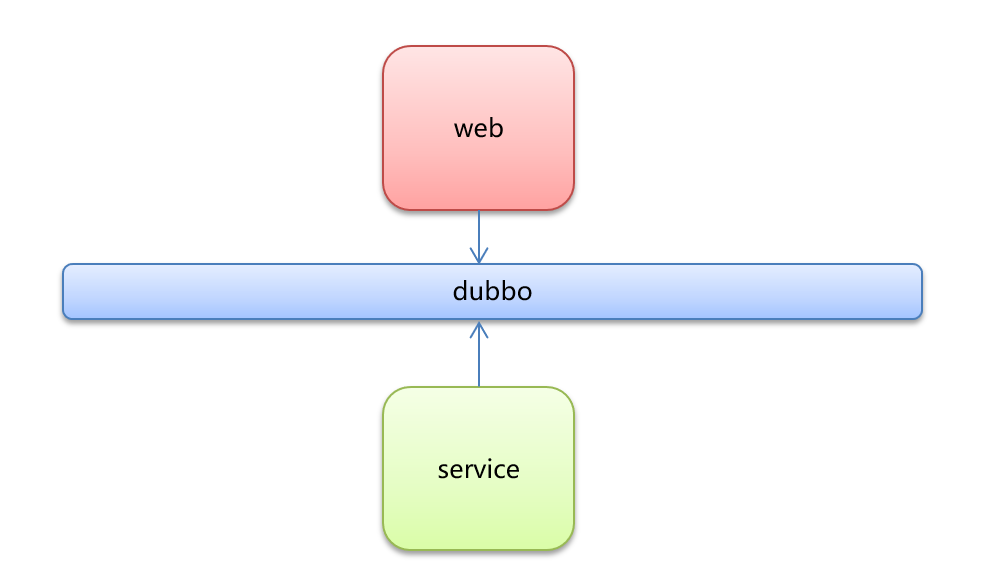
我们来看架构图,作为注册中心(Registry)的Zookeeper我们已经安装并启动好了,只需要实现服务提供方和服务消费方即可。
实现步骤:
- 创建服务提供者Provider模块
- 创建服务消费者Consumer模块
- 在服务提供者模块里编写UserServiceImpl提供服务
- 在服务消费者模块里编写UserController远程调用UserServiceImpl提供的服务
- 分别启动两个服务,测试
服务提供方和服务消费方是两个项目,但为了方便,我们在idea中将两者作为两个模块先创建好,再把他们改造成Dubbo的方式。
3.2.2创建Spring和SpringMVC整合项目
1.创建一个空项目
2.创建服务提供者模块和服务消费者模块
服务提供者:

服务消费者:

3.添加依赖
在dubbo-web模块和dubbo-service模块的pom文件里分别添加如下依赖
<properties>
<spring.version>5.1.9.RELEASE</spring.version>
<dubbo.version>2.7.4.1</dubbo.version>
<zookeeper.version>4.0.0</zookeeper.version>
<!--设置jdk-->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- servlet3.0规范的坐标 -->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
<!--spring的坐标-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
</dependency>
<!--springmvc的坐标-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>${spring.version}</version>
</dependency>
<!--日志-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.21</version>
</dependency>
<!--Dubbo的起步依赖,版本2.7之后统一为rg.apache.dubb -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
<version>${dubbo.version}</version>
</dependency>
<!--ZooKeeper客户端实现 -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>${zookeeper.version}</version>
</dependency>
<!--ZooKeeper客户端实现 -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>${zookeeper.version}</version>
</dependency>
</dependencies>
4.在dubbo-service模块里编写Service
(1)创建Service接口及其实现类
1)在dubbo-service模块的main/java目录下新建com.tsccg.service.UserService接口,定义一个抽象方法

2)在同级目录下新建其实现类:impl.UserServiceImpl,实现抽象方法,返回一个“Hello Dubbo!”
使用@Service注解修饰该实现类

(2)创建配置文件
1)在resources目录下新建一个属性配置文件:log4j.properties,添加如下内容
作用是在控制台上打印日志
# DEBUG < INFO < WARN < ERROR < FATAL
# Global logging configuration
log4j.rootLogger=info, stdout,file
# My logging configuration...
#log4j.logger.com.tocersoft.school=DEBUG
#log4j.logger.net.sf.hibernate.cache=debug
## Console output...
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p %d %C: %m%n
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=../logs/iask.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %l %m%n
2)在resources目录下新建spring文件夹,在其中创建Spring配置文件applicationContext.xml,添加如下内容
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo" xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<!--扫描@Service-->
<context:component-scan base-package="com.tsccg.service"/>
</beans>
5.在dubbo-web模块里编写Controller
(1)修改dubbo-web为web模块
由于dubbo-web模块是一个web模块,所以需要指定其打包方式为war,然后补全web模块所缺的目录及文件

web.xml:
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<!-- 1.注册spring监听器 -->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath*:spring/applicationContext*.xml</param-value>
</context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<!-- 2.注册SpringMVC中央调度器 -->
<servlet>
<servlet-name>springmvc</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<!-- 指定加载的配置文件 ,通过参数contextConfigLocation加载-->
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring/springmvc.xml</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>springmvc</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
</web-app>
(2)创建配置文件
web.xml里注册的Spring监听器和SpringMVC的中央调度器分别需要读取Spring和SpringMVC的配置文件。
1)指定Spring配置文件
Spring的配置文件位于dubbo-service模块,dubbo-web模块需要在其pom文件里添加dubbo-service模块的坐标才能读取到Spring配置文件。

2)创建SpringMVC配置文件
在dubbo-web的resources目录下新建spring/springmvc.xml文件,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc.xsd
http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<!--声明注解驱动-->
<mvc:annotation-driven/>
<!--扫描Controller对象-->
<context:component-scan base-package="com.tsccg.controller"/>
</beans>
3)同样,在resources目录下添加log4j.properties属性配置文件
# DEBUG < INFO < WARN < ERROR < FATAL
# Global logging configuration
log4j.rootLogger=info, stdout,file
# My logging configuration...
#log4j.logger.com.tocersoft.school=DEBUG
#log4j.logger.net.sf.hibernate.cache=debug
## Console output...
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p %d %C: %m%n
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=../logs/iask.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %l %m%n
(3)在main/java目录下创建处理器类:com.tsccg.controller.UserController
package com.tsccg.controller;
import com.tsccg.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @Author: TSCCG
* @Date: 2021/10/21 20:15
*/
@RestController//处理方法返回String时,只会表示字符串
@RequestMapping("/user")
public class UserController {
@Autowired//自动注入dubbo-service模块里的UserService对象
private UserService service;
@RequestMapping("/sayHello.do")
public String sayHello() {
//调用UserService对象的方法
return service.fun1();
}
}
(4)编写发送请求页面
在webapp目录下新建index.jsp,添加一个超链接,发送相对地址请求:user/sayHello.do

(5)发布dubbo-web到Tomcat服务器上
设置端口号为8000,模块名为dubbo_web

6.测试
先把dubbo-service模块进行安装,生成dubbo-web依赖的jar包

开启服务器,通过浏览器发送请求

访问成功。
以上是Spring和SpringMVC的一个整合,目前由dubbo-web模块启动对外服务,依赖于dubbo-service模块。
这还只是单体架构,因为分布式架构或者SOA架构要求每个服务模块都能独立地启动,独立地对外提供服务,而目前dubbo-service模块只是一个java模块,不能独立启动服务。

接下来要做的就是在项目里加入Dubbo,把项目改造成SOA架构。
3.2.3改造dubbo-service模块为服务提供者
1.添加依赖
在dubbo-service模块的pom里加入dubbo相关依赖(这一步我们已经做过了,故省略)
<!--Dubbo的起步依赖,版本2.7之后统一为rg.apache.dubb -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
<version>${dubbo.version}</version>
</dependency>
<!--ZooKeeper客户端实现 -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>${zookeeper.version}</version>
</dependency>
<!--ZooKeeper客户端实现 -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>${zookeeper.version}</version>
</dependency>
2.将dubbo-service模块改造成一个web模块
在pom里指定打包方式为war,并加入webapp及子文件

web.xml内容:
由于我们在dubbo-service模块里不需要写Controller,故不需要注册SpringMVC的中央调度器
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<!--注册Spring监听器:ContextLoaderListener-->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring/applicationContext.xml</param-value>
</context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
</web-app>
3.使用Dubbo提供的@Service注解修饰UserServiceImpl类
Spring提供的@Service注解作用:创建该类对象,并放入Spring的IOC容器里。
Dubbo提供的@Service注解作用:将该类提供的方法(服务)对外发布。将访问的地址(ip,端口,路径)注册到注册中心(zookeeper)里。

4.完成Dubbo的配置
为了能把访问地址注册到注册中心,必须先让项目知道注册中心的地址。
在Spring配置文件applicationContext.xml里声明Dubbo的配置信息:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<!--扫描@Service-->
<!-- <context:component-scan base-package="com.tsccg.service"/>-->
<!--Dubbo的配置-->
<!--1.声明服务名称-->
<dubbo:application name="dubbo-service">
<dubbo:parameter key="qos.port" value="33333"/>
</dubbo:application>
<!--2.声明注册中心地址-->
<dubbo:registry address="zookeeper://121.43.144.188:2181"/>
<!--3.声明dubbo包扫描,扫描@Service注解-->
<dubbo:annotation package="com.tsccg.service.impl"/>
</beans>
4.测试zookeeper能否连接
新建测试类:
public class Test01 {
private static String ip = "192.168.180.132:2181";
private static int session_timeout = 40000;
private static CountDownLatch latch = new CountDownLatch(1);
@Test
public void testZooKeeper() throws IOException, InterruptedException {
ZooKeeper zooKeeper = new ZooKeeper(ip, session_timeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
if(watchedEvent.getState() == Event.KeeperState.SyncConnected) {
//确认已经连接完毕后再进行操作
latch.countDown();
System.out.println("已经获得了连接");
}
}
});
//连接完成之前先等待
latch.await();
ZooKeeper.States states = zooKeeper.getState();
System.out.println(states);
}
}
3.2.4改造dubbo-web模块为服务消费者
1.添加依赖
在dubbo-web模块的pom里加入dubbo相关依赖(这一步我们已经做过了,故省略)
<!--Dubbo的起步依赖,版本2.7之后统一为rg.apache.dubb -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
<version>${dubbo.version}</version>
</dependency>
<!--ZooKeeper客户端实现 -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>${zookeeper.version}</version>
</dependency>
<!--ZooKeeper客户端实现 -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>${zookeeper.version}</version>
</dependency>
2.使dubbo-web模块不再依赖dubbo-service模块
SOA架构中,各个服务模块是部署到不同计算机里的,模块之间不可能相互依赖。
所以,我们的dubbo-web模块也要独立,删除pom文件里dubbo-service模块的坐标。

删除后,由于dubbo-web模块里没有UserService,所以UserController类声明UserService对象时就找不到接口,爆红。

同时,web.xml里的Spring监听器也找不到Spring配置文件。

为了让程序通过编译,我们在dubbo-web模块里定义一个相同的UserService接口:

如此程序就能通过编译了。

有红线是因为只是写了一个接口,没有实现类,Spring没有可管理的Service,@Autowired注解在本地容器中也就找不到Bean对象。
如此一来,Spring容器就没有用处了。删除web.xml里的Spring监听器:

3.使用dubbo提供的@Reference远程注入Service
既然Spring的@Autowired无法实现注入,那么就使用dubbo提供的实现远程注入的注解:@Reference
@Reference注解作用:
- 从ZooKeeper注册中心获取UserService的访问url
- 根据url进行远程调用(RPC)
- 将调用结果封装为一个代理对象,给变量赋值

4.配置dubbo
既然要从ZooKeeper注册中心获取url,那么必须告诉dubbo-web模块ZooKeeper的位置。
在SpringMVC配置文件中,配置dubbo:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc" xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/mvc https://www.springframework.org/schema/mvc/spring-mvc.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<!--扫描@Controller-->
<context:component-scan base-package="com.tsccg.controller"/>
<!--声明注解驱动-->
<mvc:annotation-driven/>
<!--Dubbo的配置,同dubbo-service的配置一样-->
<!--1.声明服务名称-->
<dubbo:application name="dubbo-web"/>
<!--2.声明注册中心地址-->
<dubbo:registry address="zookeeper://121.43.144.188:2181"/>
<!--3.声明dubbo包扫描,扫描@Controller注解-->
<dubbo:annotation package="com.tsccg.controller"/>
</beans>
至此,已将原本的单体架构改造成了分布式架构。
3.2.5运行测试
分别开启dubbo-service服务和dubbo-web服务。
但在启动dubbo-web服务时报错,说是qos-server无法绑定本地的端口22222。
qos是一个做远程调用监控的组件,高版本的dubbo会自动启动这个组件,默认的端口号就是22222。
出现这种问题说明端口号被占用了。

原因是我们在本地启动了两个服务,每个服务都会启动qos,占用22222端口

这种问题将来在开发中不会出现,因为在开发中,不同服务都部署到不同机器里了。
这里的解决方法:修改任何一个服务的qos端口号

重新启动:
dubbo-service模块:

dubbo-web模块:

通过浏览器发起请求:

成功访问到数据。
3.2.6分离公共接口
(1)缺陷分析
我们上面写的程序还有点小问题。
在解除dubbo-service模块依赖后,dubbo-web模块为了让程序编译通过,又在自己的模块里写了一个一模一样的UserService接口。
此时,两个模块内都有一个UserService接口。

如果整个项目存在很多模块,有很多公共接口,接口里又有很多方法,那么分别负责不同模块的开发团队就很难保持同步。
因此,我们要把公共接口抽离出来,单独作为一个依赖模块:

(2)代码实现
1)创建接口模块

2)在接口模块里创建UserService接口

3)在其他模块里删除UserService接口并添加dubbo-interface模块的依赖

4)运行测试

4.Dubbo高级特性
4.1监控中心
4.1.1dubbo-admin简介

在dubbo架构中,还有一个Monitor,监控中心。
监控中心一般用于统计服务的调用次数,但是官方声明Monitor还在开发中,仍不完善。
所以我们就用官方提供的另一个功能更强大的工具:dubbo-admin来做监控中心。
dubbo-admin:图形化的服务管理平台。可以从注册中心获取到所有的服务提供者和服务消费者,并进行配置管理:
- 路由规则
- 动态配置
- 服务降级
- 访问控制
- 权重调整
- 负载均衡等
4.1.2dubbo-admin的安装
1、环境准备
dubbo-admin 是一个前后端分离的项目。前端使用vue,后端使用springboot,安装 dubbo-admin 其实就是部署该项目。我们将dubbo-admin安装到开发环境上。要保证开发环境有jdk,maven,node
安装node(如果当前机器已经安装请忽略)
因为前端工程是用vue开发的,所以需要安装node。
下载地址
https://nodejs.org/en/
2、下载 Dubbo-Admin
进入gitee,搜索dubbo-admin
https://gitee.com/jinhaoliang/dubbo-admin?_from=gitee_search
下载文件到本地
3、把下载的zip包解压到指定文件夹(解压到哪个文件夹随意)

4、修改配置文件
解压后我们进入…\dubbo-admin-master\dubbo-admin\src\main\resources目录,找到 application.properties 配置文件 进行配置修改

修改zookeeper地址

5、打包项目
切换到dubbo-admin-master根目录,按住shift+右键,打开powershell窗口,然后执行打包命令
mvn clean package

出现下图即代表打包成功

6、启动后端
切换到目录dubbo-admin-master\dubbo-admin\target
同样shift+右键,打开powershell窗口,执行下面的命令启动 dubbo-admin
java -jar .\dubbo-admin-0.0.1-SNAPSHOT.jar

出现下图即表示项目启动成功

可以访问 dubbo-admin页面了,在浏览器地址栏输入如下网址:
http://localhost:7001
弹出登录框,用户名密码都是root,然后就可以登录到dubbo-admin监控页面了

4.1.3dubbo-admin的简单使用
1.监控服务
在上面的步骤中,我们已经进入了Dubbo-Admin的主界面,在【快速入门】例子中,我们定义了服务生产者、和服务消费者,下面我们从Dubbo-Admin管理界面找到这个两个服务。
开启dubbo-server和dubbo-web的服务,刷新监控中心页面:

2.查询服务
输入*查询所有服务(按服务名/按应用名/按ip地址):

查看服务信息:

20880是dubbo在本地机器占用的一个端口号,当我们要在本地启动多个服务时,需要设置为不同端口。
设置方式:
<!--修改dubbo服务端口,默认为20880-->
<dubbo:protocol port="20881"/>

点击ip地址,查看更详细的信息

4.2dubbo高级特性
4.2.1序列化

当服务消费者调用服务提供者的服务时,如果获取的是一个对象,那么就需要提供者将该对象序列化成流数据来传送给消费者,然后消费者再将流数据反序列化为对象。
由于提供者序列化和消费者反序列化的必须是同一个实体类对象,那么就需要将这个公共实体类抽离出来,作为一个单独的模块,然后由提供者和消费者共同依赖这个实体类模块。
我们新创建一个dubbo-pojo模块,在里面定义实体类User,实现Serializable接口(一个对象要想能被序列化,那么它的类必须实现Serializable接口)

在dubbo-interface、dubbo-service、dubbo-web模块里引入dubbo-pojo模块的坐标。

在dubbo-interface模块的接口里,新定义一个抽象方法,返回值为一个User对象

在dubbo-service模块的接口实现类里,实现该方法

在dubbo-web模块的index.jsp里,创建一个表单,携带请求参数id向该模块的服务器发送user/find.do的请求

在处理器类UserController里添加一个新方法,用于处理此请求。
该方法返回一个User对象的json格式字符串

测试:
执行dubbo-pojo、dubbo-interface模块的install,先后开启dubbo-service、dubbo-web模块的服务。
通过浏览器发送请求:

4.2.2地址缓存
问:注册中心挂了,服务是否可以正常访问?
可以。因为dubbo服务消费者在第一次调用时,会将服务提供方地址缓存到本地,以后再调用则不会访问注册中心。
当服务提供者地址发生变化时,注册中心会通知服务消费者。
演示:
1.开启服务,并调用

2.关闭zookeeper

3.继续调用服务
仍然能访问到

4.2.3超时与重试
1、超时
一次正常的访问流程:
- 用户发送请求给服务消费者
- 服务消费者创建一个线程,调用服务提供者
- 服务提供者返回服务给消费者
- 消费者接收到服务后,销毁线程,将处理结果返回给用户

但当服务消费者在调用服务提供者时,如果发生了阻塞、等待等情况,服务消费者会一直等待下去,线程不会被销毁,所占用的资源不会被释放。

请求少时,不会有什么大问题。但当处于某个峰值时刻,大量的请求都在同时请求服务消费者,会造成线程的大量堆积,势必会造成雪崩。

针对这个问题,dubbo使用了超时机制。设置一个超时时间,如果在时间段内,无法完成服务访问,会自动断开连接,销毁线程。

设置超时时间方式:
在dubbo提供的@Service和@Reference注解里有个timeout属性,默认值1000,单位毫秒。
代码演示超时机制:
在服务提供者,dubbo-service模块的UserServiceImpl类里,设置@Service的timeout属性值为2000,retries属性值为0。(retries:调用失败后的重试次数,稍后讲解)
访问数据库用了3秒,(用Thread.sleep模拟)

为了能看到秒数,我们在服务消费者,dubbo-web模块里新开一个线程,每隔一秒在后台输出一个数
@RestController//处理方法返回String时,只会是字符串
@RequestMapping("/user")
public class UserController {
@Reference
private UserService userService;
int i = 1;//设置初始值
@RequestMapping("/find.do")
public User findUserById(Integer id) {
//新开辟一个线程
new Thread(new Runnable() {
@Override
public void run() {
//设置死循环
while (true) {
//每隔一秒打印一个数
System.out.println(i++);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
return userService.find(id);
}
}
演示:
由于我电脑太渣,数据不太准确,但大体一致。

当然,在服务提供者的@Service和服务消费者的@Reference里都可以设置超时时间,但我们一般都在服务提供者里设置。理由:
- 因为作为服务提供者,知道要访问数据库可能会花很长时间,所以能以此延长超时时间。
- 而且@Service和@Reference里同时设置超时时间时,@Reference会覆盖@Service设置的超时时间。
2、重试
前面我们知道了,当在超时时间内无法完成服务的调用,那么连接就会自动断开。
如果出现网络抖动,这次的请求可能就会失败。
什么是网络抖动呢?就是网络有时会突然断开,然后突然连接上。就好比我们打lol时,有时网会突然断掉,当网络断的时间较长时,就会退出游戏。
为了解决这一问题,dubbo又提供了重试机制。当本次请求失败后,会重试几次,如果重试指定次数后,仍然请求失败,那么才彻底断开请求。
重试机制通过retries 属性来设置重试次数,默认为 2 次,连带第一次发送请求,共3次。
代码演示:

开启服务,发送请求:

4.2.4多版本

灰度发布:当出现新功能时,会让一部分用户先使用新功能,用户反馈没问题时,再将所有用户迁移到新功能。
那么,如何快速将所有用户迁移到新功能里去呢?
dubbo中使用version属性来设置和调用一个接口的不同版本。
代码演示:
我们在UserServiceImpl类的@Service注解里,设置version属性值为v1.0。
然后拷贝UserServiceImpl类为:UserServiceImpl2,作为新版本的服务,设置version属性值为v2.0。

在服务消费者的UserController类的@Reference注解里,先设置version属性值为v1.0,模拟服务未发布前

开启服务,发送请求:

此时,修改UserController的@Reference的version属性为v2.0,然后重启dubbo-web服务,实现版本的迁移:

4.2.5负载均衡
当一个服务提供者不够用时,我们可以对其搭建集群,创建多个提供相同服务的服务提供者。
而这种情况下,服务消费者调用服务时,该调用哪一个服务提供者就是一个问题,也就是负载均衡。

dubbo提供了四种负载均衡策略:
- Random(默认):按权重设置随机概率。
- RoundRobin:按权重轮询。
- LeastActive:最少活跃调用数,相同活跃数的随机
- 当服务消费者调用服务提供者前,先查看它们上一次完成服务访问花费的时间:
- 如果时间一致,那么随机调用
- 如果不一致,那么调用时间花费最短的。
- 当服务消费者调用服务提供者前,先查看它们上一次完成服务访问花费的时间:
- ConsistentHash:一致性Hash,相同参数的请求总是发到同一提供者
AbstractLoadBalance是四种负载均衡策略的抽象类
1、Random:按权重设置随机概率
按权重设置随机概率。
当所有服务提供者的权重相同,都为100时,服务消费者随机调用服务提供者,概率均为1/3

当第二个服务提供者的权重为200时,调用它的概率为1/2,调用其他服务提供者的概率为1/4

代码演示:
1)再创建两个相同的服务提供者

2)开启第一个服务提供者的服务
修改UserServiceImpl的fun1()方法返回1... 然后启动dubbo-service服务

监控中心:

3)开启第二个服务提供者的服务
修改fun1方法的返回值为2... 修改qos和dubbo端口号,然后启动dubbo-service (1)

监控中心:

4)开启第三个服务提供者
按同样方法开启第三个服务提供者,但设置权重为200
修改端口号:

修改权重:
在dubbo提供的@Service注解里设置weight属性值为200

监控中心:

当然,也可以通过监控中心dubbo-admin修改权重:

6)开启服务消费者:dubbo-web的服务
设置@Reference的loadbalance属性值为random(默认),启动服务

多次发送请求,查看调用情况:
调用2的概率居多

2、RoundRobin:按权重轮询
轮询就是挨个调用。
当权重都一样时,按顺序1、2、3的调用
当2的权重为200时,按顺序1、2、3、2的顺序调用
修改loadBalance属性值为:roundrobin,然后重启dubbo-web服务

设置所有服务提供者权重相同:

连续发送请求:

设置3的权重为200:

重新多次发送请求:

4.2.6集群容错

集群容错模式:
- Failover Cluster:失败重试。默认值。当出现失败,重试其它服务器 ,默认重试2次,使用 retries 配置。一般用于读操作
- Failfast Cluster :快速失败,只发起一次调用,失败立即报错。通常用于写操作。
- Failsafe Cluster :失败安全,出现异常时,直接忽略,返回一个空结果。通常用于日志。
- Failback Cluster :失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
- Forking Cluster :并行调用多个服务器,只要一个成功即返回。
- Broadcast Cluster :广播调用所有提供者,逐个调用,任意一台报错则报错。

4.2.7服务降级

机器B提供了三个服务:广告、日志、支付。其中支付服务最重要。
假如当A调用机器B的支付服务时,机器B性能到达了极限,CPU利用率达到了100%,马上就要崩溃了

那么为了能保证支付服务能正常被调用,需要将其他的相对不重要的广告和日志服务停掉。这就是服务降级。
服务降级方式:
1.强制返回null
消费方对该服务的方法调用都直接返回null值,不发起远程调用
@Reference(mock=focus:return null)
用于屏蔽不重要的服务不可用时对调用方法的影响。
2.失败返回null
消费方对该服务的方法调用在失败后,再返回null值,不抛出异常。
@Reference(mock=fail:return null)
用于容忍不重要的服务不稳定时对调用方的影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号