
Javase学习12-集合
Java学习12-集合
1. 集合概述
1.1 什么是集合?有什么用?
数组就是一个集合。集合就是一个能够容纳其他数据的容器。
集合常在开发时使用:
集合是一个容器,一个载体,可以容纳多个对象。在实际开发中,假设连接一个数据库,数据库中有十条数据,假设查询十个数据,那么我们的java程序就会把这十个数据封装进十个java对象,放到某个集合中,然后把集合发送到前端,遍历集合,将数据一个一个显示出来。
1.2 集合具体能存储什么?
集合不能直接存储基本数据类型,也不能直接存储java对象,集合存储的是java对象的内存地址(引用)。
list.add(11); // 自动装箱Integer
注意:
- 集合本身也是一个对象
- 集合在任何时候存储的都是内存地址(引用);

1.3 集合底层对应的数据结构
在java中每一个不同的集合,底层都会对应了不同的数据结构。往不同的集合中存放数据,就等于将数据存放到了不同的数据结构中。
常见的数据结构有 数组、链表、二叉树、hashMap、图等。
使用不同的集合等于使用不同的数据结构。
在java中,数据结构已经实现了,已经写好了常用的集合类,我们只需要知道在什么情况下选择使用哪一个集合即可。
new LinkedList(); 创建了一个集合对象,底层是链表
new ArrayList();创建了一个集合对象,底层是数组
1.4 集合在Java JDK中哪个包下?
java.util.*;
所有的集合类和集合接口都在java.util包下
1.5 集合继承图
在Java中集合分为两大类:
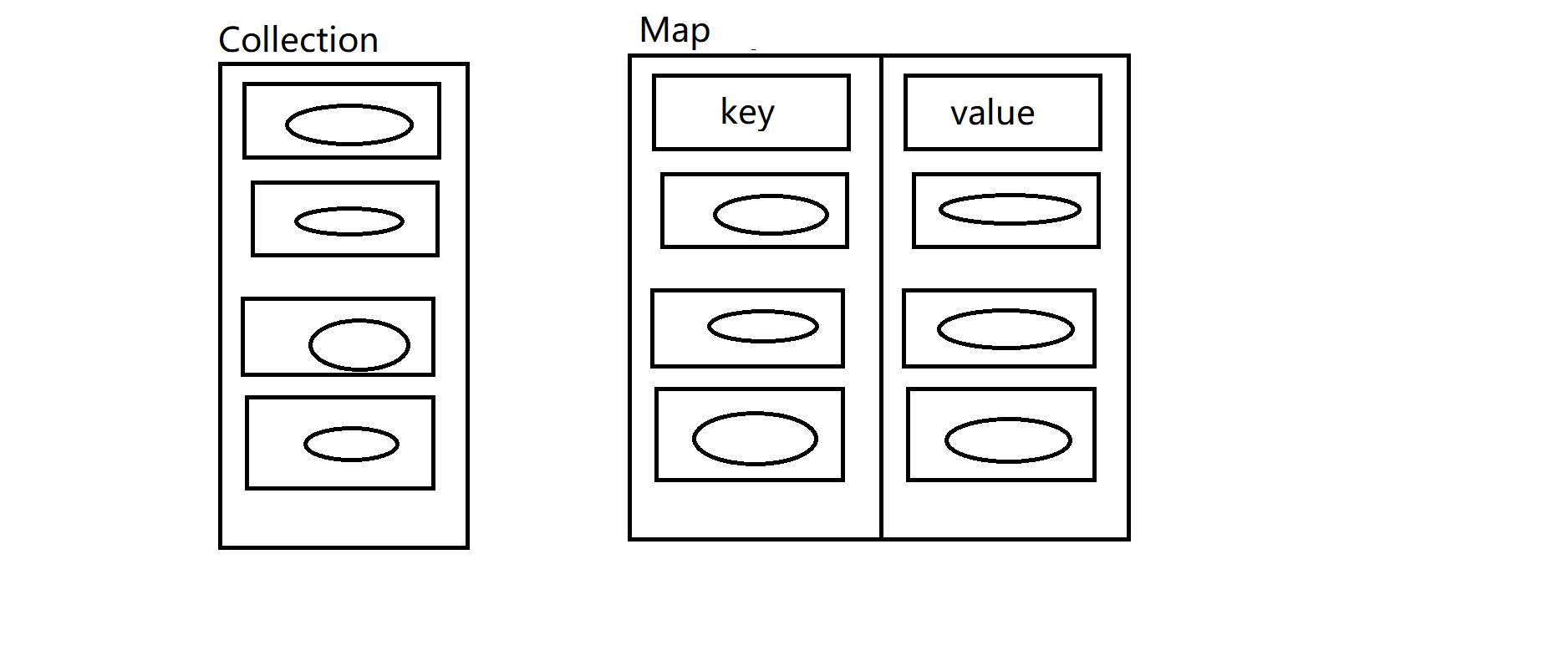
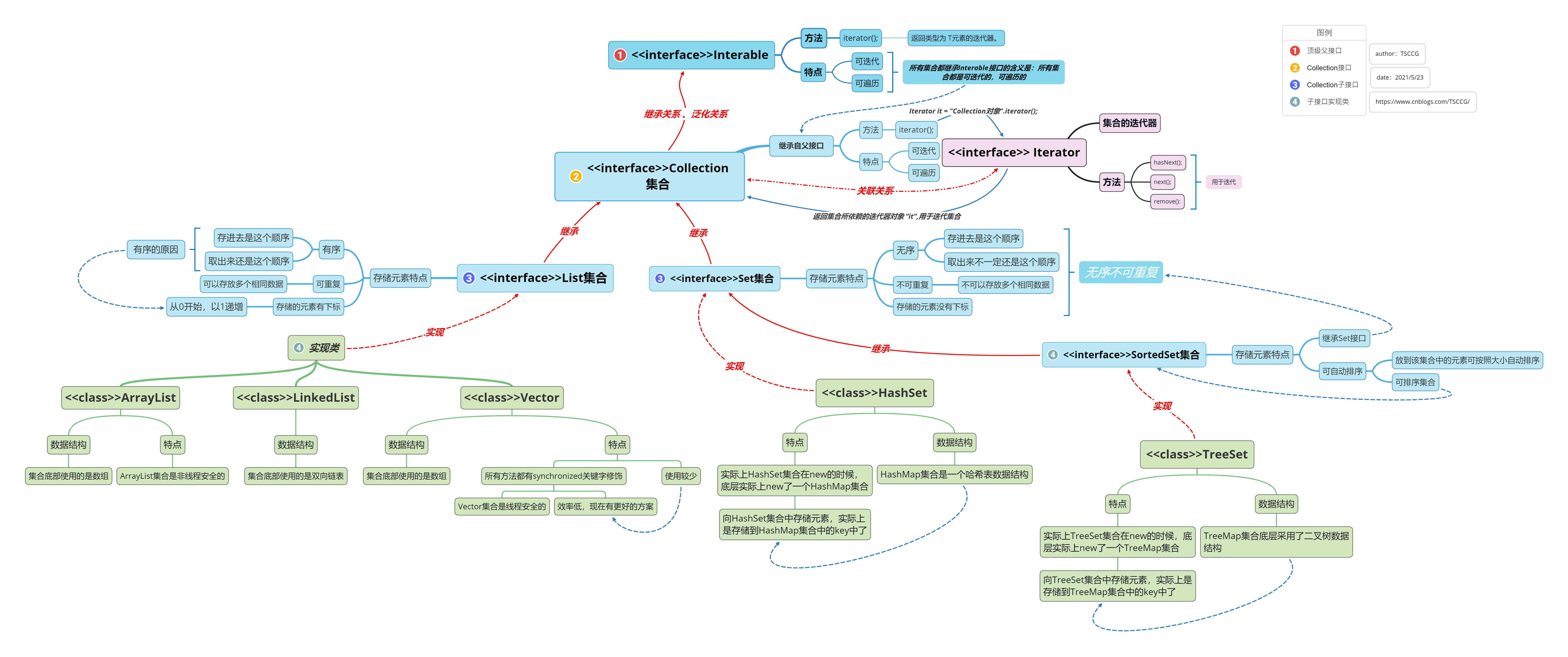
- 单个方式存储元素:超级父接口:java.util.Collection;
Collection集合继承脑图:
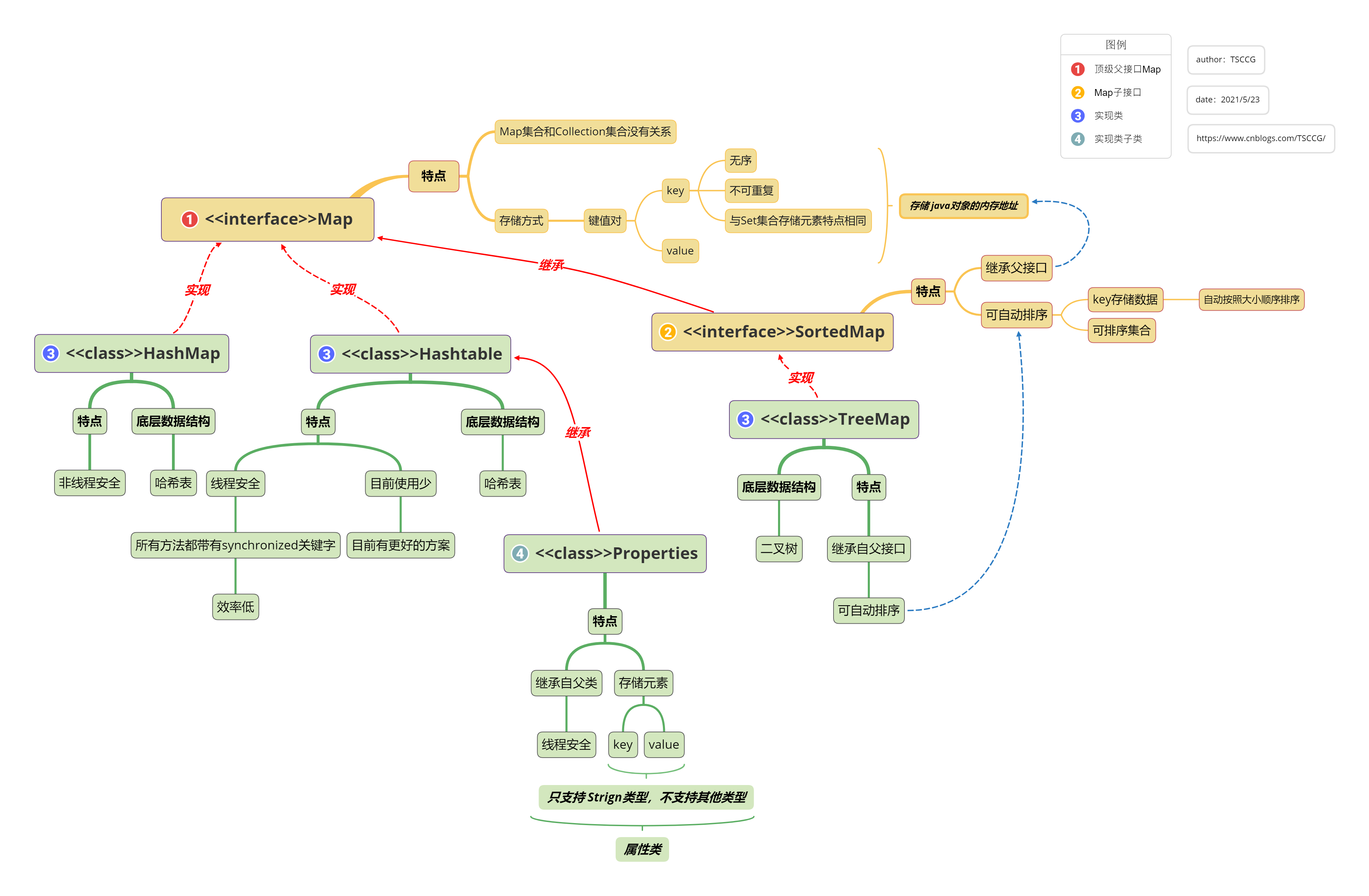
- 以键值对的方式存储元素:超级父接口:java.util.Map;
Map集合继承脑图:
1.6 总结
1.6.1 Collection:
1) List:有序可重复
-
有序:存入和取出的顺序相同,每一个元素都有下标
-
可重复:存入一个张三,还可以再存入一个张三
-
实现类:
-
ArrayList: 底层是数组,线程不安全
-
Linkedlist: 底层是双向链表
-
Vector: 底层是数组,线程安全,效率较低,使用较少
-
2) Set:无序不可重复
- 无序:存入和取出的顺序不一定相同,Set元素都没有下标
- 不可重复:不能存两个张三
- 实现类:
- HashSet: 底层是HashMap,放到HashSet集合中的元素实际上都会进入HashMap的key部分
- TreeSet: 底层是TreeMap,放到TreeSet集合中的元素实际上都会进入TreeMap的key部分
3) SortedSet(SortedMap):
继承Set,无序不可重复,但SortedSet集合中的元素是可排序的
- 无序:存入和取出的顺序不一定相同,Set元素都没有下标
- 不可重复:不能存两个张三
- 可排序:可以按照大小顺序排序
1.6.2 Map:
Map中的key就是一个Set集合,往Set集合中存放数据,实际放到了Map集合中的key部分
- HashMap: 底层是哈希表
- Hashtable: 底层是哈希表,线程安全,效率较低,使用较少
- Properties: 继承自Hashtable线程安全,key和value只能存放String类型
SortedMap:
无序不可重复,但SortedSet集合中的元素是可排序的
- 无序:存入和取出的顺序不一定相同,Set元素都没有下标
- 不可重复:不能存两个张三
- 可排序:可以按照大小顺序排序
- TreeMap: 底层是二叉树,TreeMap集合中的key可以按大小自动排序
2. 集合中的常用方法
增删改查常用英语单词:
- 1.增:add、save、new
- 2.删:delete、drop
- 3.改:update、set、modify
- 4.查:get、select、find、query
2.1 Collection
2.1.1 Collection接口常用方法:
| 返回值类型 | 方法名及传入参数类型 | 描述 |
|---|---|---|
| boolean | add(E e) | 在集合末尾添加一个元素 |
| int | size() | 返回此集合中的元素数 |
| boolean | contains(Object o) | 查询集合中指定的元素,如果存在,返回true,反之返回false |
| boolean | remove(Object o) | 删除一个指定值的元素 |
| void | clear() | 删除集合中的所有元素 |
| boolean | isEmpty() | 判断集合是否为空,如果为空,返回true,反之返回false |
| Object[] | toArray() | 返回一个包含此集合中所有元素的数组。 |
| Iterator | iterator() | 返回此集合中的元素的迭代器 |
- add(E e):
向集合中添加一个元素,集合中不能直接存放基本数据类型,也不能存放对象,只能存放对象的内存地址
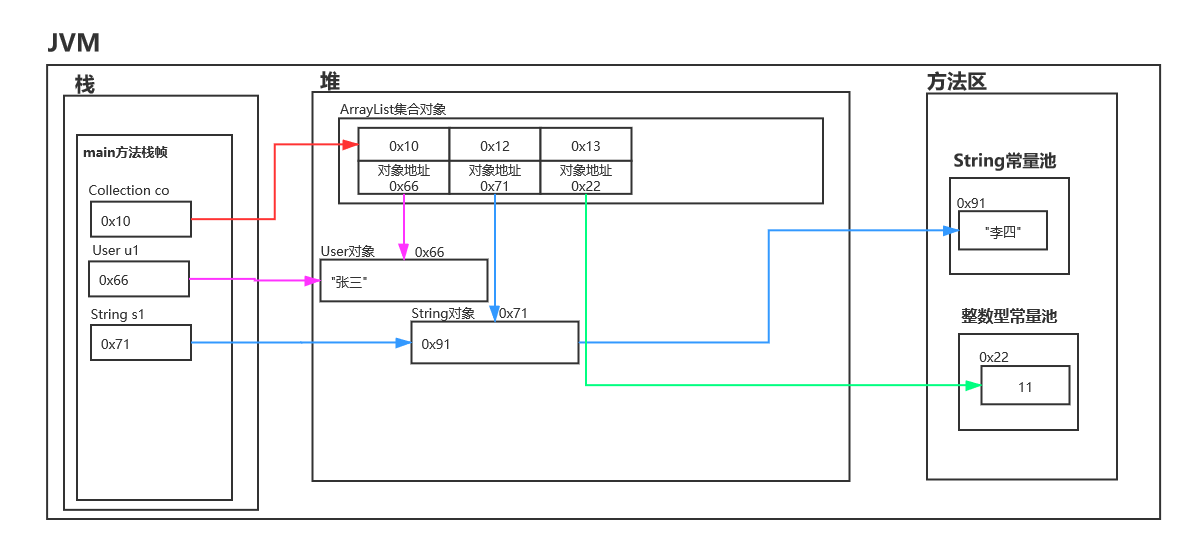
public class ContainsDemo01 {
public static void main(String[] args) {
Collection<Object> co = new ArrayList<>();
User u1 = new User("张三");
co.add(u1);
String s1 = new String("李四");
co.add(s1);
//自动装箱 Integer integer = 11;
co.add(11);
}
}
class User {
private String name;
public User(String name) {
this.name = name;
}
}
- contains(Object o):
查询集合中指定的元素,如果存在,返回true,反之返回false
例子:
public class ContainsDemo01 {
public static void main(String[] args) {
Collection<Object> co = new ArrayList<>();
User u1 = new User("张三");
co.add(u1);
String s1 = new String("李四");
co.add(s1);
User u2 = new User("张三");
System.out.println("集合中是否包含张三? " + co.contains(u2));
String s2 = new String("李四");
System.out.println("集合中是否包含李四? " + co.contains(s2));
}
}
class User {
private String name;
public User(String name) {
this.name = name;
}
}
结果:
集合中是否包含张三? false
集合中是否包含李四? true
为什么查询张三结果为false,李四结果为true呢?
查看ArrayList contains()方法源码:
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
return indexOfRange(o, 0, size);
}
int indexOfRange(Object o, int start, int end) {
Object[] es = elementData;
if (o == null) {
for (int i = start; i < end; i++) {
if (es[i] == null) {
return i;
}
}
} else {
for (int i = start; i < end; i++) {
if (o.equals(es[i])) {
return i;
}
}
}
return -1;
}
由o.equals(es[i])可知,contains方法调用了equals方法来比较元素。
我们知道,我们上面所写的User类并没有重写equals方法,故查找User类型的"张三"时,我们比较的是两个对象的内存地址,故为false.
而String类重写了equals方法,使得可以比较String对象的值,故为true.

故可以得出结论:
存放在集合中的类型,一定要重写equals方法
例:
class User {
private String name;
public User(String name) {
this.name = name;
}
@Override
public boolean equals(Object obj) {
//判断是否是User类型的元素
if (!(obj instanceof User)) {
return false;
}
//比较内存地址
if (this == obj) {
return true;
}
//强转成User类型
User user = (User)obj;
//比较值
return user.name.equals(this.name);
}
}
- remove(Object o):
从该集合中删除指定元素的单个实例(如果存在)
例子:
public class RemoveDemo {
public static void main(String[] args) {
Collection<Object> co = new ArrayList<>();
User u1 = new User("张三");
co.add(u1);
System.out.println("删除前集合中元素个数:" + co.size());
User u2 = new User("张三");
co.remove(u2);
System.out.println("删除后集合中元素个数:" + co.size());
}
}
class User {
private String name;
public User(String name) {
this.name = name;
}
}
结果:
删除前集合中元素个数:1
删除后集合中元素个数:1
显然不对。查看ArrayList remove()方法源码:
public boolean remove(Object o) {
final Object[] es = elementData;
final int size = this.size;
int i = 0;
found: {
if (o == null) {
for (; i < size; i++)
if (es[i] == null)
break found;
} else {
for (; i < size; i++)
if (o.equals(es[i]))
break found;
}
return false;
}
fastRemove(es, i);
return true;
}
可以看出,同样调用了equals方法来判断集合中是否包含要删除的元素,同上,需要重写equals方法
- iterator():
返回此集合中的元素的迭代器,迭代器可以对集合进行迭代/遍历
-------------对集合Collection进行迭代/遍历过程-----------------
第一步,集合对象调用iterator()方法拿到一个迭代器对象it.
迭代器对象可以调用boolean hasNext();和Object next();两个方法对集合进行迭代。
第二步,迭代器对象it调用hasNext()判断集合的下一个元素是否为空,如果为空,返回false并结束迭代,
如果不为空,返回true,然后调用next()使迭代器指向集合中的下一个元素并返回该元素。
注意:
1.迭代器一开始并不是指向集合中第一个元素
2.迭代器在所有Collection集合中是通用的
Iterator<Object> it = co.iterator();
// 判断集合中是否有元素可以进行迭代,如果有,往后走一个输出一个
while (it.hasNext()) {
//无论存入什么数据,取出来的时候都是Object类型
System.out.println(it.next());
}
方法调用例子(总):
package Collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* @Author TSCCG
* @Date 2021/5/24 9:58
*/
public class CollectionDemo01 {
public static void main(String[] args) {
/**
* Collection collection1 = new Collection();
* 接口是抽象的,无法实例化,故这里使用多态,new一个ArrayList对象
* 来测试Collection中的常用方法
*/
Collection<Object> co = new ArrayList<>();
// 1.add 向集合中添加一个元素
// 集合中不能直接存放基本数据类型,也不能存放对象,只能存放对象的内存地址
User u1 = new User("张三");
co.add(u1);
String s1 = new String("李四");
co.add(s1);
//自动装箱 Integer integer = new Integer(11);
co.add(11);
//2.size 返回此集合中的元素数
System.out.println("集合中元素的个数是:" + co.size());
//3.contains 查询某一个元素
User u2 = new User("张三");
System.out.println("集合中是否包含张三? " + co.contains(u2));
String s2 = new String("李四");
System.out.println("集合中是否包含李四? " + co.contains(s2));
//4.remove 删除此集合中指定的元素
co.remove(u2);
System.out.println("删除张三后,集合中元素的个数是:" + co.size());
//判断集合是否为空 false
System.out.println("集合此时为空吗?" + co.isEmpty());
//5.clear 删除此集合中所有元素
co.clear();
System.out.println("删除全部元素后,集合中元素的个数是:" + co.size());
//6.isEmpty 判断集合是否为空 true
System.out.println("集合此时为空吗?" + co.isEmpty());
//重新输入元素
co.add("香蕉");
co.add("野兽");
co.add("野兽");
co.add(new User("阿巴"));
co.add(new Object());
//7.toArray 将集合转换成数组
Object[] obj = co.toArray();
System.out.println("-----------遍历数组------------");
for (int i = 0; i < obj.length; i++) {
//默认调用toString方法
System.out.println(obj[i]);
}
//8.iterator 迭代集合
Iterator<Object> it = co.iterator();
// 判断集合中是否有元素可以进行迭代
System.out.println("-----------迭代集合------------");
while (it.hasNext()) {
//无论存入什么数据,取出来的时候都是Object类型
System.out.println(it.next());
}
}
}
class User {
private String name;
public User(String name) {
this.name = name;
}
@Override
public boolean equals(Object obj) {
//判断是否是User类型的元素
if (!(obj instanceof User)) {
return false;
}
//比较内存地址
if (this == obj) {
return true;
}
//强转成User类型
User user = (User)obj;
//比较值
return user.name.equals(this.name);
}
}
结果:
集合中元素的个数是:3
集合中是否包含张三? true
集合中是否包含李四? true
删除元素11后,集合中元素的个数是:2
集合此时为空吗?false
删除全部元素后,集合中元素的个数是:0
集合此时为空吗?true
-----------遍历数组------------
香蕉
野兽
野兽
Collection.User@4fca772d
java.lang.Object@9807454
-----------迭代集合------------
香蕉
野兽
野兽
Collection.User@4fca772d
java.lang.Object@9807454
2.1.2 List
2.1.2.1 List接口特色方法:
| 返回值类型 | 方法名及传入参数类型 | 描述 |
|---|---|---|
| void | add(int index, E element) | 将指定的元素插入此列表中的指定位置 |
| E | get(int index) | 返回此列表中指定位置的元素 |
| int | indexOf(Object o) | 返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1 |
| int | lastIndexOf(Object o) | 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1 |
| E | remove(int index) | 删除该列表中指定位置的元素 |
| E | set(int index, E element) | 用指定的元素(可选操作)替换此列表中指定位置的元素 |
- add(int index, E element)
将指定的元素插入此列表中的指定位置.
此方法需要移动数组,效率较低,使用较少;
一般添加数据时都添加到列表末尾
ArrayList add(int index,E element)方法底层源码:
public void add(int index, E element) {
//判断添加的下标是否越界
rangeCheckForAdd(index);
modCount++;
//定义临时数组长度
final int s;
//定义临时数组
Object[] elementData;
//判断是否需要扩展数组
if ((s = size) == (elementData = this.elementData).length)
elementData = grow();
//将需要插入的位置原本的元素及其后面的元素后移一位
System.arraycopy(elementData, index,
elementData, index + 1,
s - index);
//将新元素添加到目标位置
elementData[index] = element;
size = s + 1;
}
测试方法:
public class ListDemo01 {
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
//添加元素
//在集合末尾添加元素
list.add("大娃");
list.add("二娃");
list.add("三娃");
list.add("四娃");
System.out.println("---------在下标为1的位置添加指定元素前-------");
print(list);
//在指定位置添加元素
list.add(1,"爷爷");
System.out.println("---------在下标为1的位置添加指定元素后-------");
print(list);
}
public static void print(List<Object> list) {
Iterator<Object> it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
结果:
---------在下标为1的位置添加指定元素前-------
大娃
二娃
三娃
四娃
---------在下标为1的位置添加指定元素后-------
大娃
爷爷
二娃
三娃
四娃
- get(int index)
返回此列表中指定位置的元素.
public class ListDemo01 {
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
//添加元素
//在集合末尾添加元素
list.add("大娃");
list.add("二娃");
list.add("三娃");
list.add("四娃");
//查询下标为1的元素
System.out.println(list.get(1));
}
}
结果:
二娃
- indexOf(Object o)
返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1
public class ListDemo01 {
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
//添加元素
list.add("大娃");
list.add(new User("二娃"));
list.add(new User("二娃"));
list.add("三娃");
list.add("三娃");
list.add("四娃");
System.out.println("二娃第一次出现的索引为:" + list.indexOf(new User("二娃")));
System.out.println("三娃第一次出现的索引为:" + list.indexOf("三娃"));
}
}
class User {
private String name;
public User(String name) {
this.name = name;
}
}
结果:
二娃第一次出现的索引为:-1
三娃第一次出现的索引为:3
查看底层得知索引时使用了equals方法,故需要在User类中重写equals方法
- lastIndexOf(Object o)
返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1
public class ListDemo01 {
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
//添加元素
list.add(new User("大娃"));
list.add(new User("二娃"));
list.add(new User("二娃"));
list.add("三娃");
list.add("三娃");
list.add(new User("四娃"));
System.out.println("二娃最后一次出现的索引为:" + list.lastIndexOf(new User("二娃")));
System.out.println("三娃最后一次出现的索引为:" + list.lastIndexOf("三娃"));
}
}
class User {
private String name;
public User(String name) {
this.name = name;
}
}
结果:
二娃最后一次出现的索引为:-1
三娃最后一次出现的索引为:4
看底层ArrayList lastIndexOf方法知同样使用equals方法,需要重写equals方法
- remove(int index)
删除该列表中指定位置的元素
public class ListDemo01 {
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
//添加元素
//在集合末尾添加元素
list.add("大娃");
list.add("二娃");
list.add("三娃");
list.add("四娃");
System.out.println("---------删除下标为1的元素前--------");
print(list);
list.remove(1);
System.out.println("---------删除下标为1的元素后--------");
print(list);
}
public static void print(List<Object> list) {
Iterator<Object> it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
结果:
---------删除下标为1的元素前--------
大娃
二娃
三娃
四娃
---------删除下标为1的元素后--------
大娃
三娃
四娃
- set(int index, E element)
用指定的元素(可选操作)替换此列表中指定位置的元素
public class ListDemo01 {
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
//添加元素
//在集合末尾添加元素
list.add("大娃");
list.add("二娃");
list.add("三娃");
list.add("四娃");
System.out.println("---------替换下标为1的元素前--------");
print(list);
list.set(1,"六娃");
System.out.println("---------替换下标为1的元素后--------");
print(list);
}
public static void print(List<Object> list) {
Iterator<Object> it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
结果:
---------替换下标为1的元素前--------
大娃
二娃
三娃
四娃
---------替换下标为1的元素后--------
大娃
六娃
三娃
四娃
2.1.2.2 ArrayList
1. 初始化容量:
1.ArrayList集合底层是一个Object[]的数组
2.初始化容量默认为10(先创建一个长度为0的数组,当添加第一个元素的时候初始化容量为10)
3.构造方法:
- new ArrayList() //构造一个初始容量为十的空列表。
- new ArrayList(20) // 构造具有指定初始容量的空列表。
- new ArrayList(Collection<? extends E> c) //构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序。
4.ArrayList集合不是线程安全的
package Collection.list.implements_class;
import java.util.*;
/**
* @Author TSCCG
* @Date 2021/5/29 10:20
*/
public class ArrayListDemo01 {
public static void main(String[] args) {
//默认初始化容量为10
List<Object> list1 = new ArrayList<>();
//指定初始化容量为100
List<Object> list2 = new ArrayList<>(100);
//HashSet集合
Collection<Object> c = new HashSet<>();
//添加元素到HashSet集合中
c.add("张三");
c.add("李四");
c.add("王五");
c.add("赵六");
//构造一个包含HashSet集合的元素的ArrayList集合,按照它们由HashSet集合的迭代器返回的顺序存储。
List<Object> list3 = new ArrayList<>(c);
for (int i = 0; i < list3.size(); i++) {
System.out.println(list3.get(i));
}
}
}
结果:
李四
张三
王五
赵六
2. ArrayList集合的扩容
每次扩容1.5倍 //int newCapacity = oldCapacity + (oldCapacity >> 1)
00000100:4 ----右移1位---->00000010:2
长度倍数增长为:(4 + 2)/ 4 = 1.5
ArrayList集合底层是数组,数组的扩容效率很低,在实际应用中,应尽量减少扩容来进行优化,建议在创建数组时根据数据量指定一个初始化容量。
3. ArrayList优缺点
ArrayList的优点:
- 检索效率高。每个元素占用空间相同,内存地址是连续的,知道首元素地址,知道下标,可以通过数学表达式计算出元素的内存地址。
ArrayList的缺点:
- 随机增删元素效率较低(向数组末尾添加元素效率较高,不受影响)
- 数组不能存储较大的数据量,因为很难找到巨大且连续的内存空间
4. 面试常问问题:
在所有的集合中,你用哪个集合最多?
答:ArrayList集合
因为ArrayList集合的查询效率较高,在数组末尾增添元素的过程中也不会影响到过多元素的位置,效率不受很大的影响。
写程序的过程中进行检索或查找某一个元素的操作次数比较多,所以使用较多。
2.1.2.3 LinkedList
1.特点:
-
LinkedList底层是一个双向链表
-
链表在内存空间中的内存地址是不连续的
-
LinkedList集合底层也是有下标的,如:
LinkedList link = new LinkedList();
link.add("a");
link.add("b");
link.add("c");
for (int i = 0; i < link.size(); i++) {
System.out.println(link.get(i));
}
注意:
ArrayList之所以检索效率高,不单单是因为有下标,主要还是底层数组发挥的作用。
LinkedList集合照样有下标,但是检索某个元素的效率较低,因为只能从头结点开始一个一个遍历。
2.LinkedList优缺点
LinkedList的优点:
- 由于链表上的元素在空间存储上内存地址不连续,所以随机增删元素的时候不会有过多元素发生位移,因此随机增删效率较高。
- 在以后的开发中,如果遇到随机增删集合中元素的业务比较多时,建议使用linkedList。
LinkedList的缺点:
- 不能通过数学表达式计算被查找元素的内存地址,每一次查找都是从头节点开始遍历,直到找到为止。所以linkedList集合检索的效率较低。
更多详细内容请查看讲解链表的这篇博客
2.1.2.4 Vector
1.Vector概述
Vector特点:
-
底层也是一个Object数组。
-
初始化容量为10。
-
默认扩容原容量的2倍,也可以指定每次扩容的大小。
int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity); -
Vector中所有方法都由synchronized关键字修饰,虽然因此而线程安全,但是线程同步使得执行效率低,使用较少。
Vector构造方法:
- public vector() 数组默认容量为10,默认扩容2倍。
- public vector(int initialcapacity) 指定初始容量,默认扩容两倍。
- public vector(int initialcapacity,int capacityIncrement) 指定初始容量和每次扩容值,利用这个功能可以优化存储。
package Collection.list.implements_class;
import java.util.Iterator;
import java.util.Vector;
/**
* @Author: TSCCG
* @Date: 2021/07/07 15:51
*/
public class VectorDemo01 {
public static void main(String[] args) {
//创建Vector对象
Vector vector = new Vector();
Vector vector2 = new Vector(5,2);
//添加元素
vector.add(1);
vector.add(2);
vector.add(3);
vector.add(4);
vector.add(5);
vector.add(6);
vector.add(7);
vector.add(8);
vector.add(9);
vector.add(10);
//超出默认容量,扩容2倍 10---->20
vector.add(11);
//迭代集合
Iterator it = vector.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
2.将一个线程不安全的集合转换为线程安全
使用集合工具类:java.util.Collections。
- java.util.Collection 是集合接口。
- java.util.Collections 是集合工具类。
List mylist = new LinkedList();//非线程安全
Collections.synchronizedList(mylist);//线程安全的
mylist.add(1);
mylist.add(2);
mylist.add(3);
2.1.3 Set
Set接口特点:无序不可重复。
1. HashSet
特点:
-
无序不可重复。
- 无序指的是存入的顺序和取出的顺序不一致,并且没有下标。
- 无法存储重复的元素。
-
放到HashSet集合中的元素实际上是放到了HashMap集合中的key部分了。
-
public boolean add(E e) { return map.put(e, PRESENT)==null; }
-
package Collection.set;
import java.util.HashSet;
import java.util.Set;
/**
* @Author: TSCCG
* @Date: 2021/07/07 16:44
* HashSet无序不可重复
*/
public class HashSetDemo01 {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("张三");
set.add("李四");
set.add("王五");
set.add("赵六");
set.add("李四");
set.add("李四");
for (String s : set) {
System.out.println(s);
}
}
}
结果:
李四
张三
王五
赵六
2. TreeSet
SortedSet接口:
- 继承Set接口。
- 可自动按照元素的值进行排序,称为可排序集合。
TreeSet实现SortedSet接口。
TreeSet特点:
-
无序不可重复。
-
可自动按照元素的值进行排序。
-
放到TreeSet集合中的元素实际上是放到了TreeMap集合中的key部分了。
-
public boolean add(E e) { return m.put(e, PRESENT)==null; }
-
package Collection.set;
import java.util.Set;
import java.util.TreeSet;
/**
* @Author: TSCCG
* @Date: 2021/07/07 16:54
*/
public class TreeSetDemo01 {
public static void main(String[] args) {
Set<String> treeSet = new TreeSet<>();
treeSet.add("4");
treeSet.add("5");
treeSet.add("2");
treeSet.add("3");
treeSet.add("5");
treeSet.add("1");
for (String s : treeSet) {
System.out.println(s);
}
}
}
结果:
1
2
3
4
5
2.2 Map
2.2.1 Map结构
- Map和Collection之间没有继承关系。
- Map集合以key和value的方式存储数据:键值对。
- key和value都是引用数据类型。
- key和value都是存储对象的内存地址。
- key起到主导地位,value是key的一个附属品。
2.2.2 Map接口中的常用方法
| 返回值 | 方法名 | 作用 |
|---|---|---|
| V | put(K key,V value) | 向Map集合中添加键值对 |
| V | get(Object key) | 通过key获取value |
| void | clear() | 清空Map集合 |
| boolean | containKey(Object key) | 判断Map集合中是否包含某个key |
| boolean | containValue(Object value) | 判断Map集合中是否包含某个value |
| boolean | isEmpty() | 判断Map集合中元素的个数是否为0 |
| set< K > | keySet() | 获取Map集合中所有的key(所有的键是一个Set集合) |
| V | remove(Object key) | 通过key删除Map集合中某个键值对 |
| int | size() | 获取Map集合中所有键值对的个数 |
| Collection< V > | values() | 获取Map集合中所有的value,返回一个Collection集合 |
| Set<Map.Entry<K,V>> | entrySet() | 将Map集合转换成Set集合 |
1.V put(K key,V value)
向Map集合中添加键值对
Map<Integer,String> map1 = new HashMap<>();
map1.put(1,"张三");
map1.put(2,"李四");
map1.put(3,"王五");
map1.put(4,"赵六");
2.V remove(Object key)
通过key删除Map集合中某个键值对
Map<Integer,String> map1 = new HashMap<>();
map1.put(1,"张三");
map1.put(2,"李四");
map1.put(3,"王五");
map1.put(4,"赵六");
map1.remove(2);
3.V get(Object key)
通过key获取value
Map<Integer,String> map1 = new HashMap<>();
map1.put(1,"张三");
map1.put(2,"李四");
map1.put(3,"王五");
map1.put(4,"赵六");
System.out.println(map1.get(3));
王五
4.boolean isEmpty()
判断Map集合中元素的个数是否为0,是为true,否为false
Map<Integer,String> map1 = new HashMap<>();
System.out.println(map1.isEmpty());
map1.put(1,"张三");
map1.put(2,"李四");
map1.put(3,"王五");
map1.put(4,"赵六");
System.out.println(map1.isEmpty());
true
false
5.void clear()
清空Map集合
Map<Integer,String> map1 = new HashMap<>();
map1.put(1,"张三");
map1.put(2,"李四");
map1.put(3,"王五");
map1.put(4,"赵六");
System.out.println(map1.isEmpty());
map1.clear();
System.out.println(map1.isEmpty());
false
true
6.int size()
获取Map集合中所有键值对的个数
Map<Integer,String> map1 = new HashMap<>();
map1.put(1,"张三");
map1.put(2,"李四");
map1.put(3,"王五");
map1.put(4,"赵六");
System.out.println(map1.size());
4
7.boolean containKey(Object key)
判断Map集合中是否包含某个key
底层调用的equals方法,自定义类型需要重写equals方法
Map<Integer,String> map1 = new HashMap<>();
map1.put(1,"张三");
map1.put(2,"李四");
map1.put(3,"王五");
map1.put(4,"赵六");
System.out.println(map1.containsKey(2));
System.out.println(map1.containsKey(6));
true
false
8.boolean containValue(Object value)
判断Map集合中是否包含某个value
底层调用的equals方法,自定义类型需要重写equals方法
Map<Integer,String> map1 = new HashMap<>();
map1.put(1,"张三");
map1.put(2,"李四");
map1.put(3,"王五");
map1.put(4,"赵六");
System.out.println(map1.containsValue("赵六"));
System.out.println(map1.containsValue("赵4"));
true
false
9.set< K > keySet()
获取Map集合中所有的key(所有的键是一个Set集合)
Map<Integer,String> map1 = new HashMap<>();
map1.put(1,"张三");
map1.put(2,"李四");
map1.put(3,"王五");
map1.put(4,"赵六");
Set<Integer> set1 = map1.keySet();
for (Integer s : set1) {
System.out.println(s);
}
1
2
3
4
10.Collection< V > values()
获取Map集合中所有的value,返回一个Collection集合
Map<Integer,String> map1 = new HashMap<>();
map1.put(1,"张三");
map1.put(2,"李四");
map1.put(3,"王五");
map1.put(4,"赵六");
Collection<String> values = map1.values();
for (String s : values) {
System.out.println(s);
}
张三
李四
王五
赵六
11.Set<Map.Entry<K,V>> entrySet()
将Map集合转换成Set集合
现在有一个Map集合,将其转换成一个Set集合。如下:
Map<Integer,String> map1 = new HashMap<>();
map1.put(1,"张三");
map1.put(2,"李四");
map1.put(3,"王五");
map1.put(4,"赵六");
Set<Map.Entry<Integer, String>> set = map1.entrySet();
for (Map.Entry<Integer,String> node : set) {
System.out.println(node.getKey() + "=" + node.getValue());
}
打印结果:
1=张三
2=李四
3=王五
4=赵六
map1集合对象:
| key | value |
|---|---|
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
| 4 | 赵六 |
set集合对象:
| Map.Entry<Integer,String> |
|---|
| node |
| node |
| node |
| node |
注意:
Map集合通过entrySet()方法转换成的这个Set集合中,元素的类型是:Map.Entry<K,V>。
每个元素中有两个属性,分别是key和value。
Map.Entry是Map中的一个静态内部类。
静态内部类:
package map;
import java.util.HashSet;
import java.util.Set;
/**
* @Author: TSCCG
* @Date: 2021/07/07 20:32
* 静态内部类
*/
public class MyClass {
/**
* 静态内部类
*/
private static class InnerClass {
/*
静态内部类中的静态方法
*/
public static void m1() {
System.out.println("静态内部类中的静态方法m1执行");
}
/*
静态内部类中的实例方法
*/
public void m2() {
System.out.println("静态内部类中的实例方法m2执行");
}
}
public static void main(String[] args) {
//类名叫做 MyClass.InnerClass
MyClass.InnerClass.m1();
//创建静态内部类对象
MyClass.InnerClass inner = new MyClass.InnerClass();
inner.m2();
//创建一个Set集合:
//该Set集合中存储的对象是MyClass.InnerClass类型的
Set<MyClass.InnerClass> set1 = new HashSet<>();
//该Set集合中存储的对象是String类型的
Set<String> set2 = new HashSet<>();
}
}
2.2.3 遍历Map集合
1.通过遍历key来遍历value
获取所有的key,通过遍历key来遍历value
Map<Integer,String> map1 = new HashMap<>();
map1.put(1,"张三");
map1.put(2,"李四");
map1.put(3,"王五");
map1.put(4,"赵六");
//获取所有的key,所有的key是一个Set集合
Set<Integer> set1 = map1.keySet();
/*
通过foreach
*/
//遍历key
for (Integer s : set1) {
//通过key来获取value
System.out.println(s + "=" + map1.get(s));
}
/*
通过迭代器
*/
// Iterator<Integer> it = set1.iterator();
// while (it.hasNext()) {
// Integer key = it.next();
// System.out.println(key + "=" + map1.get(key));
// }
1=张三
2=李四
3=王五
4=赵六
2.把Map集合转换为Set集合再遍历
将Map集合直接转换为Set集合。
Set集合中元素的类型是:Map.Entry<K,V>
底层是Node节点,有key和value两个属性。
Map<Integer,String> map1 = new HashMap<>();
map1.put(1,"张三");
map1.put(2,"李四");
map1.put(3,"王五");
map1.put(4,"赵六");
//将Map集合转换成Set集合
Set<Map.Entry<Integer, String>> set = map1.entrySet();
//迭代器
Iterator<Map.Entry<Integer,String>> it = set.iterator();
while (it.hasNext()) {
//遍历Set集合,每次取出一个Node
Map.Entry<Integer,String> node = it.next();
Integer key = node.getKey();
String value = node.getValue();
System.out.println(key + "=" + value);
}
//增强for
//for (Map.Entry<Integer,String> node : set) {
// System.out.println(node.getKey() + "=" + node.getValue());
//}
1=张三
2=李四
3=王五
4=赵六
3.总结
使用第二种方式遍历的效率比较高。
- 第一种方法获取到key后,再通过key在哈希表里找对应的元素,这是需要耗费一定时间的。
- 这种方式适用于数据量较小的情况下。
- 第二种方法是把key和value放一块了,对象中就有这两种属性,可以直接获取。
- 这种方式适用于数据量较大的情况下。
2.2.3 HashMap
1.HashMap底层数据结构
-
HashMap底层的数据结构是一个哈希表/散列表。
-
哈希表是一维数组和单向链表的结合体。

- 数组:在查询方面效率很高,随机增删效率很低。
- 单向链表:在查询方面效率很低,随机增删效率很高。
- 哈希表将上面两种数据结构糅合到了一起,让它们充分发挥各自的优势。
- 哈希表/散列表:实际上是一个一维数组,这个数组中每一个元素都是一个单向链表。(数组和链表的结合体)
-
为什么说哈希表的随机增删以及查询效率都比较高?
-
增删是在链表上完成的。
-
查询也不需要全部扫描,只需要局部扫描。
-
哈希表查询的效率不如纯粹的数组。
-
哈希表随机增删的效率不如纯粹的链表。
-
-
HashMap集合的默认初始化容量是16,默认加载因子是0.75,扩容后是原容量的2倍
- 这个默认加载因子是当HashMap集合底层数组的容量达到75%时,数组开始扩容。
- 重点:HashMap集合初始化容量必须是2的倍数,这也是官方推荐的。
- 这是因为达到散列均匀,为了提高HashMap集合的存取效率所必须的。
-
HashMap底层源码
-
public class HashMap { //HashMap底层是一个一维数组 Node<K,V>[] table; //静态内部类HashMap.Node static class Node<K,V> implements Map.Entry<K,V> { final int hash;//哈希值,哈希值是key的hashCode()方法的执行结果。hash值通过哈希函数/算法,可以返回一个下标 final K key;//存储到Map集合中的key V value;//存储到Map结合中的value Node<K,V> next;//下一个节点的内存地址 } }
-
2.HashMap中元素的存取

-
存:map.put(key,value)
- 首先将key和value封装到一个Node对象里。
- 然后底层会调用key的hashCode()方法得出key的hash值。
- 然后通过哈希算法/哈希函数将hash值转换成数组的下标。
- 如果下标位置上没有任何元素,那么就将该Node添加到该下标位置上。
- 如果下标对应位置上有链表,那么此时会调用equals方法将key和该链表上所有节点进行比较:
- 如果返回结果都是false,那么就将该Node添加到该链表的末尾。
- 如果其中有一个equals返回了true,那么该链表里的这个节点中的value将被新节点的value所覆盖。
-
取:v = map.get(key)
- 先调用key的hashCode()方法得出key的hash值。
- 然后通过哈希算法/哈希函数将hash值转换成数组的下标。
- 然后通过下标快速定位到数组的某个位置上。
- 如果下标对应位置上没有任何元素,那么会返回null。
- 如果下标对应位置上有链表,那么此时会调用equals方法将key和该链表上所有节点进行比较:
- 如果返回结果都是false,那么就返回null。
- 如果其中有一个equals返回了true,那么该链表里的这个节点中的value就是我们要找的value。
通过以上过程,我们可以得出结论:
HashMap集合中的key,会先后调用两个方法,分别是hashCode()和equals(),这两个方法都要重写。
3.HashMap集合中key部分特点(去重)
无序,不可重复。
- 无序:存入时不一定挂到哪个单向链表上。
- 不可重复:equals方法来保证HashMap集合中的key不可重复,如果key重复了,value会覆盖。
放在HashMap集合中key部分的元素其实是放到HashSet集合中了,
所以HashSet集合中的元素也要同时重写hashCode()和equals()方法。
4.散列分布均匀
什么是散列分布不均匀?
- 假设有100个元素,10条单向链表。如果每条链表上都挂10个元素,那么这种情况是最完美的,我们称之为:散列分布均匀。
同一个单向链表上所有节点的hash值相同,因为它们的数组下标是一样的。但同一个链表上的节点的key不同。
HashMap使用不当时无法发挥性能:
- 假设将所有的hashCode()方法返回值固定为某个值,那么会导致底层哈希表变成一个纯单向链表,这种情况我们称之为:散列分布不均匀。
- 假设将hashCode()方法所有的返回值都设定为不一样的值,这样会导致底层哈希表变成纯一维数组,也是散列分布不均匀。
- 散列分布均匀需要重写hashCode()方法时有一定技巧。
5.重写hashCode和equals方法
- 向Set集合中存元素的时候先调用hashCode方法,再调用equals方法
-
当数组下标为null时,不需要调用equals方法
-
- 向Set集合中取元素的时候也先调用hashCode方法,再调用equals方法
-
当数组下标为null时,不需要调用equals方法
-
- 如果两个元素的equals比较返回true,那么说明两个元素是一样的,是在同一条单向链表上比较的,而同一条单向链表上所有元素的哈希值都一样,所以hashCode和equals方法要一起重写
package map;
import java.util.HashSet;
import java.util.Set;
/**
* @Author: TSCCG
* @Date: 2021/07/08 09:50
*/
public class HashMapDemo01 {
public static void main(String[] args) {
Student s1 = new Student("张三");
Student s2 = new Student("张三");
//如果此处没有重写equals方法,返回值会是false
System.out.println(s1.equals(s2));//true
System.out.println("s1的哈希值:" + s1.hashCode());//685325104
System.out.println("s1的哈希值:" + s2.hashCode());//460141958
Set<Student> set1 = new HashSet<>();
set1.add(s1);
set1.add(s2);
/*
如果此处只重写了equals没有重写hashCode,
s1.equals(s2)结果会是true,这表示s1和s2是一样的,
往HashSet集合中放的话,按说只能放1个(HashSet结合无序不可重复),
但实际结果会放两个。
这是因为s1和s2的哈希值值不相等,调用哈希算法返回的数组下标不一致,不会存放到同一条链表里,更不会检验是否重复
*/
System.out.println(set1.size());//1
}
}
class Student {
private String name;
public Student() {
}
public Student(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Student student = (Student) o;
return Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name);
}
}
结论:
放在HashMap集合key部分以及放在HashSet集合中的元素,需要同时重写hashCode方法和equals方法。
6.JDK8对HashMap的改进
JDK8新特性:
当HashMap集合中单向链表长度大于8,会变成红黑树结构,当长度小于6,会变回单项链表。
单向链表过于长时,HashMap的检索效率也会降低,这样是为了提高检索效率。
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
7.哈希冲突(哈希碰撞)
对于哈希表数据结构来说:
- 如果o1和o2的hash值相同,那么一定是放在同一条单向链表上的
- 如果o1和o2的hash值不相同,但由于哈希算法计算结束之后转换的数组下标可能相同,此时会发生"哈希冲突(哈希碰撞)"
2.2.4 Hashtable
Hashtable和HashMap一样,底层都是哈希表。
Hashtable的初始化容量是11。
默认加载因子是:0.75f。
扩容是:原容量 * 2 + 1。
1.Hashtable和HashMap的不同之处
1) Hashtable是线程安全的
底层的方法都带有synchronized关键字,是线程同步的,是线程安全的。
但由于synchronized使得程序执行效率变低,以及目前已有其他更好的方案来解决线程安全问题,故Hashtable的使用较少。
2) Hashtable和HashMap中允许null吗?
-
HashMap集合key允许null,并且null值只能有一个。
-
Hashtable集合key和value都不允许null,不然会报空指针异常。
-
value不能为null:
if (value == null) {
throw new NullPointerException();
} -
key不能为null:int hash = key.hashCode();
-
HashMap:
Map map1 = new HashMap();
map1.put(null,null);
map1.put(null,200);
Set<Map.Entry> set1 = map1.entrySet();
for (Map.Entry entry : set1) {
System.out.println(entry.getKey() + "=" + entry.getValue());
}
结果:
null=200
Hashtable:
Map map1 = new Hashtable();
map1.put(null,null);
map1.put(null,200);
Set<Map.Entry> set1 = map1.entrySet();
for (Map.Entry entry : set1) {
System.out.println(entry.getKey() + "=" + entry.getValue());
}
结果:
Exception in thread "main" java.lang.NullPointerException
at java.util.Hashtable.put(Hashtable.java:459)
at map.HashMapDemo02.main(HashMapDemo02.java:28)
2.2.5 Properties
Properties是一个Map集合,继承Hashtable,是线程安全的。
Properties的key和value都只能存放String类型对象,被称为属性类。
package map;
import java.util.Properties;
/**
* @Author: TSCCG
* @Date: 2021/07/08 19:59
*/
public class PropertiesDemo01 {
public static void main(String[] args) {
//创建Properties对象
Properties pro = new Properties();
//多行编辑:alt + 鼠标拉拽
//存放数据
pro.setProperty("name","法外狂徒张三");
pro.setProperty("age","31");
pro.setProperty("sex","男");
pro.setProperty("address","河南");
pro.setProperty("education","本科");
//根据key取出value
System.out.println(pro.getProperty("name"));
System.out.println(pro.getProperty("age"));
System.out.println(pro.getProperty("sex"));
System.out.println(pro.getProperty("address"));
System.out.println(pro.getProperty("education"));
}
}
法外狂徒张三
31
男
河南
本科
2.2.6 TreeMap
1.TreeMap的底层结构
TreeSet集合中的元素特点:无序不可重复,但可以按照元素的大小顺序自动排序,称为可排序集合。
TreeSet集合底层实际上是一个TreeMap。
放到TreeSet集合里的元素实际上是放到TreeMap集合里的key部分了。
TreeMap的底层结构是二叉树。
K key;
V value;
Entry<K,V> left; //左子树
Entry<K,V> right; //右子树
Entry<K,V> parent; //根节点
1)TreeSet/TreeMap是自平衡二叉树
遵循左小右大的原则存放,所以在存放的时候要进行比较。
存放的过程就是排序的过程。
TreeMap中添加元素时进行比较的源码:
do {
parent = t;
cmp = k.compareTo(t.key);//调用comparaTo方法比较新节点与二叉树中的根节点大小
//如果新节点比根节点小,comparaTo返回一个负数,然后新节点移动到左子树上,再次与根节点进行比较,直到根节点的左子树或右子树为null
if (cmp < 0)
t = t.left;
//如果新节点比根节点大,comparaTo返回一个正数,然后新节点移动到右子树上。
else if (cmp > 0)
t = t.right;
//如果新节点等于根节点,comparaTo返回一个0,然后根节点被新节点覆盖
else
return t.setValue(value);
} while (t != null);
2)遍历二叉树的时候有三种方式:
- 前序遍历:根左右
- 中序遍历:左根右
- 后序遍历:左右根
注意:
- 前中后说的是根节点所在位置
- 根在前面就是前序,在中间就是中序,在后面就是后序。
3)TreeSet集合/TreeMap集合采用的是:中序遍历
Iterator迭代器采用的是中序遍历方式。
左根右。
4)将下列数字以二叉树的方式排列
70,200,20,10,40,100,60,400,50,800

5)采用中序遍历取出4)中的数据:
中序遍历遵循左根右的原则,先遍历左子树,然后遍历根节点,再然后遍历右子树。
10,20,40,50,60,70,100,200,400,800
2.TreeSet集合可以对String对象和Integer对象进行排序
String类和Integer类中都实现了Comparable接口,重写了compareTo方法,所以可以进行排序。
package map;
import java.util.TreeSet;
/**
* @Author: TSCCG
* @Date: 2021/07/08 20:31
*/
public class TreeSetDemo01 {
public static void main(String[] args) {
TreeSet<String> treeSet = new TreeSet<>();
treeSet.add("d");
treeSet.add("b");
treeSet.add("e");
treeSet.add("a");
treeSet.add("c");
for (String s : treeSet) {
System.out.println(s);
}
System.out.println("---------------------");
TreeSet<Object> treeSet2 = new TreeSet<>();
treeSet2.add(3);
treeSet2.add(1);
treeSet2.add(5);
treeSet2.add(2);
treeSet2.add(4);
for (Object o : treeSet2) {
System.out.println(o);
}
}
}
a
b
c
d
e
---------------------
1
2
3
4
5
3.自定义类型实现Comparable接口实现排序
自定义类型需要实现Comparable接口,重写compareTo方法,制定排序规则,才能在TreeSet集合中实现排序。
TreeMap底层在存入元素时,会将传入的对象转换成Comparable类型,如果自定义类型没有实现Comparable接口,调用会报错。
Comparable<? super K> k = (Comparable<? super K>) key;
package map;
import java.util.TreeSet;
/**
* @Author: TSCCG
* @Date: 2021/07/08 20:46
*/
public class TreeSetDemo02 {
public static void main(String[] args) {
Person p1 = new Person("cc",20);
Person p2 = new Person("aa",20);
Person p3 = new Person("dd",30);
Person p4 = new Person("bb",10);
TreeSet<Person> ts1 = new TreeSet<>();
ts1.add(p1);
ts1.add(p2);
ts1.add(p3);
ts1.add(p4);
for (Person p : ts1) {
System.out.println(p);
}
}
}
/**
* 自定义类型需要实现Comparable接口
*/
class Person implements Comparable<Person>{
String name;
int age;
public Person() {
}
public Person(String name,int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
/**
* 按照年龄大小排序
* 如果年龄相同,按名字的字典顺序排序
*/
@Override
public int compareTo(Person p) {
if (this.age == p.age) {
//年龄是String类型,可以调用String类中重写过的compareTo直接比较
return this.name.compareTo(p.name);
} else {
/*
p1.comepareTo(p2)
如果p1的age大于p2的age
返回一个正数
如果p1的age小于p2的age
返回一个负数
如果p1的age等于p2的age
返回一个0
this就是p1,p就是p2
*/
return this.age - p.age;
}
}
}
Person{name='bb', age=10}
Person{name='aa', age=20}
Person{name='cc', age=20}
Person{name='dd', age=30}
4.自定义类型实现Comparator比较器接口实现排序
我们在创建TreeSet对象时,可以传入一个自己写的比较器进去来实现排序。
package map;
import java.util.Comparator;
import java.util.TreeSet;
/**
* @Author: TSCCG
* @Date: 2021/07/08 21:44
* 实现比较器接口
*
*/
public class TreeSetDemo03 {
public static void main(String[] args) {
//匿名内部类方式实现Comparator接口
// TreeSet<Cat> ts = new TreeSet<>(new Comparator<Cat>(){
// @Override
// public int compare(Cat o1, Cat o2) {
// return o1.age - o2.age;
// }
// });
TreeSet<Cat> ts = new TreeSet<>(new CatComparator());
ts.add(new Cat(3));
ts.add(new Cat(2));
ts.add(new Cat(4));
for (Cat t : ts) {
System.out.println(t);
}
}
}
class Cat {
int age;
public Cat(int age) {
this.age = age;
}
@Override
public String toString() {
return "Cat{" +
"age=" + age +
'}';
}
}
class CatComparator implements Comparator<Cat> {
@Override
public int compare(Cat o1, Cat o2) {
return o1.age - o2.age;
}
}
Cat{age=2}
Cat{age=3}
Cat{age=4}
TreeMap:
public class TreeSetDemo03 {
public static void main(String[] args) {
TreeMap<Integer,Cat> ts2 = new TreeMap<>(new CatComparator<Integer>());
ts2.put(2,new Cat(5));
ts2.put(1,new Cat(5));
ts2.put(5,new Cat(1));
ts2.put(3,new Cat(7));
Set<Map.Entry<Integer,Cat>> set = ts2.entrySet();
//迭代器
Iterator<Map.Entry<Integer,Cat>> it = set.iterator();
while (it.hasNext()) {
Map.Entry<Integer,Cat> entry = it.next();
System.out.println(entry.getKey() + "=" + entry.getValue());
}
//System.out.println("----------------");
//增强for
//for (Map.Entry<Integer, Cat> entry : set) {
// System.out.println(entry.getKey() + "=" + entry.getValue());
//}
}
}
class Cat {
int age;
public Cat(int age) {
this.age = age;
}
@Override
public String toString() {
return "Cat{" +
"age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Cat cat = (Cat) o;
return age == cat.age;
}
@Override
public int hashCode() {
return Objects.hash(age);
}
}
class CatComparator<I extends Number> implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);
}
}
1=Cat{age=5}
2=Cat{age=5}
3=Cat{age=7}
5=Cat{age=1}
5.总结
1)TreeMap底层数据结构是二叉树,遵循左小右大原则,存入的过程就是排序的过程。
2)放到TreeSet或TreeMap集合key部分的元素如果想要做到排序,包括两种方式:
- 放在集合中的元素实现Comparable接口。
- 在构造TreeSet或者TreeMap集合的时候给它传入一个比较器对象。
3)sComparable和Comparator该怎么选择呢?
- 当比较规则不会发生改变时,或者说比较规则只有一个时,建议实现Comparable接口。
- 当比较规则有多个,并且需要在多个比较规则之间频繁切换的时候,将以实现Comparator接口。
- Comparator接口的设计符合OCP原则。
2.3 集合工具类
集合工具类Collections
2.3.1 将非线程安全的集合转换为线程安全的
Collections.synchronizedList(集合对象) ;
将一个非线程安全的List集合转换为一个线程安全的集合。
例:
//ArrayList集合是非线程安全的
List<Integer> list1 = new ArrayList<>();
//将ArrayList集合转换为线程安全的
Collections.synchronizedList(list1);
list1.add(3);
list1.add(4);
list1.add(1);
list1.add(2);
2.3.2 对集合进行排序
Collections.sort(集合对象);
对集合中的元素进行排序。
如果是自定义类型,则需要实现Comparable接口,重写CompareTo方法,制定比较规则。
public class CollectionsDemo01 {
public static void main(String[] args) {
List<Integer> list1 = new ArrayList<>();
list1.add(3);
list1.add(4);
list1.add(1);
list1.add(2);
//将ArrayList排序
Collections.sort(list1);
for (Object o : list1) {
System.out.println(o);
}
System.out.println("----Cat----");
List<Cat> list2 = new ArrayList<>();
list2.add(new Cat(2));
list2.add(new Cat(4));
list2.add(new Cat(1));
list2.add(new Cat(3));
//如果是自定义类型,必须要继承Comparable接口,重写CompareTo方法
Collections.sort(list2);
for (Cat cat : list2) {
System.out.println(cat);
}
}
}
class Cat implements Comparable<Cat>{
int age;
public Cat(int age) {
this.age = age;
}
@Override
public String toString() {
return "Cat{" +
"age=" + age +
'}';
}
@Override
public int compareTo(Cat o) {
return this.age - o.age;
}
}
1
2
3
4
----Cat----
Cat{age=1}
Cat{age=2}
Cat{age=3}
Cat{age=4}
参考博客:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号