忘光了,所以复习【STR】
字符串
本文字符串下标从
速通
哈希
没什么可说的,我也不喜欢用。
trie
顾名思义,就是一个像字典一样的树。
基础
01trie
在一些题目中,可以用 trie 维护 01 串。
给定一棵
个点的带权树,求异或和最大的简单路径。
。
solution
考虑树上两点路径的异或和可以转化为根到两点的异或和异或起来。
于是转化为求寻找两点使两点的权值的异或和最大。
用 trie 维护:不断插入一个数,查询这个数与已插入的数的最大异或和是多少(只要尽量保证前缀是 1)。
自动机
定义
自动机是一个对信号序列进行判定的数学模型。
比如说,你在初始状态,可以往几条路走,通过这几条路可以走到其他状态。
一个确定有限状态自动机(DFA,deterministic finite automation)由以下五部分构成:
(另外有个东西叫做 NFA,以后可能会提到)
- 字符集(
- 状态集合(
- 起始状态(
- 接受状态集合(
- 转移函数(
以上的字符串均为广义的。
想要更快的理解,可以把 DFA 看做一个有向图,但是 DFA 只是一个数学模型。
另外不难发现 trie 也是自动机,我称其为广义前缀自动机。下面就拿 01trie 举个例子。
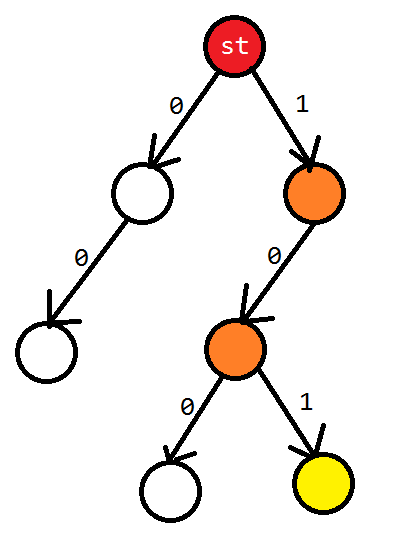
边可以看做状态转移。
序列自动机
对于字符串
转移(
可以通过记录下一个字符出现位置来实现。
给你两个由小写英文字母组成的串
和 ,求:
的一个最短的子串,它不是 的子序列。 的一个最短的子序列,它不是 的子序列。
solution
第一个相对简单。直接枚举起点跑就行。
设
表示在 中到第 位,在 中到第 位的答案。 那么
KMP
设
对于字符串
处理出
模式串在匹配文本串的时候,如果是以下这个状态:

发现到第五位时失配了,我们接下来肯定是想让它从蓝色这个状态继续匹配。
可以发现,跳到
由于每次只往后移动一格,往前跳的次数一定小于等于往后走的次数,复杂度
怎么求
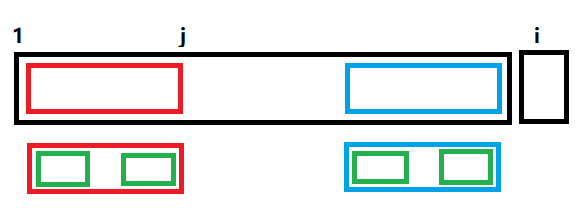
假设当前位是
否则,贪心地令
最后,不难发现 kmp 的过程与求
int j=0;
for(int i=2;i<=m;i++){
while(j&&b[i]!=b[j+1])j=pre[j];
j+=(b[i]==b[j+1]);pre[i]=j;
}
j=0;
for(int i=1;i<=n;i++){
while(j&&a[i]!=b[j+1])j=pre[j];
j+=(a[i]==b[j+1]);
if(j==m)write(i-m+1,'\n'),j=pre[j];
}
KMP自动机
用 KMP 建出的自动机,转移:
求有多少个
位数字文本串满足:没有一个子串为给定模式串。 模式串长度为
,对 取模。
solution
dp,设
表示文本串中匹配到第 位,模式串中匹配到第 位的方案数。 那么:
设矩阵
有: ,就可以把转移看做向量乘上矩阵。 又发现
与 无关,于是矩阵快速幂。
失配树
border
任意长度相同前后缀。
失配树
考虑一个问题:
给定
, 次询问 ,求 前缀和 前缀的最长公共 border。
首先,根据 KMP 中
而仔细思考后发现一个点向它的
而两段前缀的最长公共 border 转化为了失配树上的 LCA。
求出对于
每个前缀的不相交 border 个数。
对于一个前缀
求不相交 border 可以转化为长度 ,所以我们就可以在失配树上往上跳,跳到符合条件,深度就是答案。 可以不用显式建树。
Z 函数
令
对于字符串
Z 函数其实也很好求:
从某个位置
我们维护当前
假设我们已经求出
根据定义,有
如果还有机会继续拓展(
l=1,r=0;
for(int i=2;i<=m;i++){
if(i<r)z[i]=min(z[i-l+1],r-i+1);
while(i+z[i]<=m&&b[i+z[i]]==b[z[i]+1])++z[i];
if(i+z[i]-1>=r)r=i+z[i]-1,l=i;
}
匹配另一个串
拼起来再做一遍即可。
但是注意拼起来时中间放一个随便什么引荐字符,避免匹配到后面的串。
给字符串
,求 的方案数,设 表示 中出现奇数次的字符数量,有 。定义乘法为前后拼接。
solution
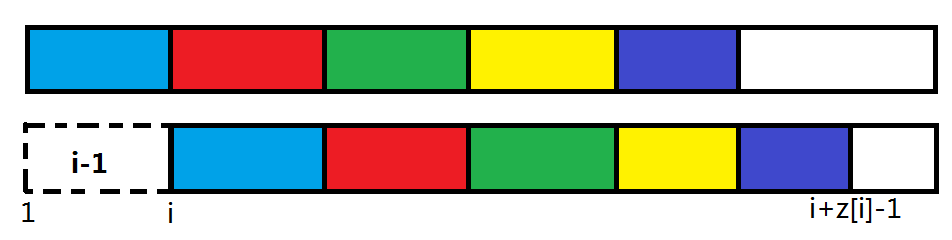
枚举循环节长度:
如图为长度为
的循环节,不难发现有颜色的段是完全相同的,而且不能再往后延伸一段。 可以得出,最大循环节段数为
。注意:为了最后留至少一个字符给 ,所以如果循环节把整串排满了,要 。 设
表示 中出现奇数次的字符数量, 表示 中出现奇数次的字符数量。 对循环节段数
奇偶分类讨论:
不难发现,段数为奇数时,
保持不变(两个不同的奇数 对应的串 只差偶数段循环节,正好抵消了)。 所以,我们只要找到
使得 (算 时的 )。 这部分的贡献为:满足条件的
的个数 满足条件的 的个数。
段数为偶数时
也保持不变(原因同上),且等于 。 所以,我们只要找到
使得 。 这部分的贡献为:满足条件的
的个数 满足条件的 的个数。 然后发现做完了。
🐴拉🚗
求
中最长回文串长度。
先把字符串变成
模仿 Z 函数,设
我们维护当前
可以考虑把
然后跟 Z 函数类似地右移
int mid=0,r=0;
for(int i=1;i<n;i++){
if(i<=r)manacher[i]=min(manacher[(mid<<1)-i],r-i+1);
while(s[i-manacher[i]]==s[i+manacher[i]])++manacher[i];
if(manacher[i]+i-1>=r)r=manacher[i]+i-1,mid=i;
}
AC 自动机
多模式串
先将模式串
记
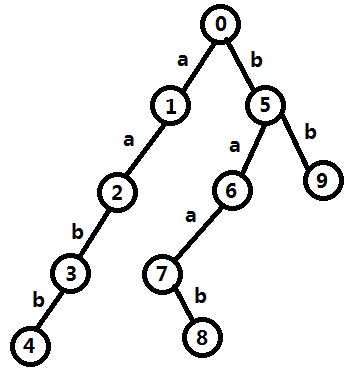
构建方法:设当前求
具体的,设当前在点
- 若
- 否则,令
inline void init(){
L=1,R=0;
for(int i=0;i<26;i++)
if(trie[0][i])q[++R]=trie[0][i];
while(L<=R){
int u=q[L++],t=fail[u];
for(int i=0;i<26;i++){
int v=trie[u][i];
if(v)fail[v]=trie[t][i],q[++R]=v;
else trie[u][i]=trie[t][i];
}
}
}
第二个操作可以使不断往上跳
匹配方法:如果文本串在树上匹配到了一个串,那么一定能匹配到跳
给定
个模式串 和一个文本串 ,求有多少个不同的模式串在文本串里出现过。
, 。
如果一个串出现过了,那么它的所有
都出现过,所以我们只要在节点上打个 tag,如果访问过了,就不继续。 复杂度
。
fail 树
不难发现,AC 自动机的
有
个由小写字母组成的模式串 以及一个文本串 。你需要找出哪些模式串在文本串 中出现的次数最多。
这题暴力可过,但是同样可以在 fail 树上树形 dp。
【模板】AC 自动机(二次加强版) 要树形 dp 才能过。
复杂度
。
非速通
SAM
一个字符串
从初始状态出发,转移到了一个终止状态,则路径上所有转移连起来一定是
结束位置(endpos)
对于
对于字符串
可能存在两个
SAM 中的每个状态对应一个或多个
所以 SAM 中的状态数等于所有子串的等价类的个数,再加上初始状态。
由
-
字符串
证明:如果
-
对于字符串
证明:如果
-
一个
证明:
令等价类中长度最小的字符串为
对于
又有
即满足条件的
后缀链接 (link)
令
一个后缀链接
不难发现,
一些性质(对于一个字符串
-
共有
证明:没有点会链接到前缀对应的等价类,非前缀不是属于前缀所在状态,就是能通过 link 。
-
后缀链接树(SAM)的节点个数最多为
-
任意串的后缀全部位于该串所在状态的后缀链接路径上。
-
一个状态的
后缀链接树上的边可以看做
线性构造
后缀链接树不够用,建出 SAM 才行。(建 SAM 的算法叫 Blumer 算法)
令
假设当前已经完成了
- 设
- 从
- 如果跳到了有
- 否则,构造一个新点
- 最后,要从
复杂度证明:
不难发现,一次加点最多加两个,再加上前两个点不可能加点,一共
发现转移数也是
其它部分的复杂度显然,主要是两次跳
第一次比较显然,最多创建转移数条新边。
对于第二次:
不难发现,第二次跳
设
- 引理:若
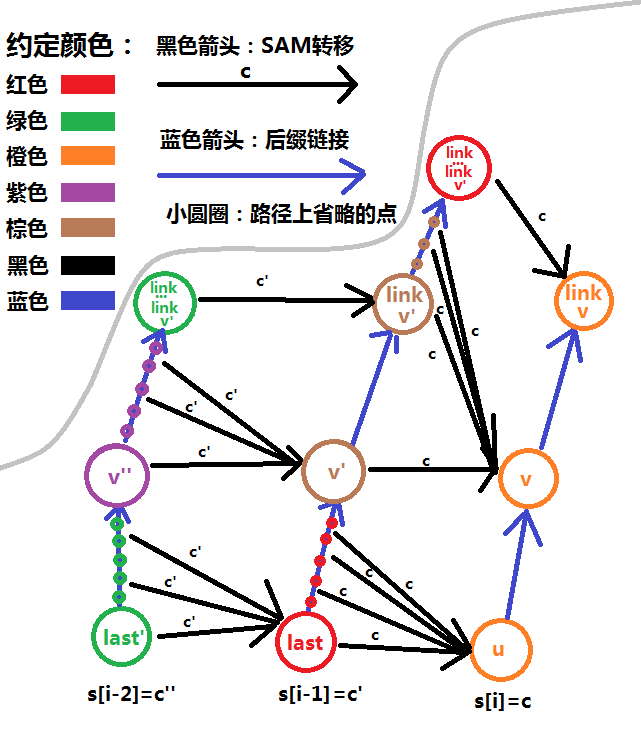
在构建
构建
不难发现,构建
引理
这说明,构建一个点时第二次开始跳的位置的深度,最多是构建上一个点时第二次结束的位置的深度
不难发现深度最多
瓶颈在于复制。
朴素的构造是 memcpy)或 std::map)的。
当然也可以开一个 std::vector,在每次加转移时把字符压进去。这样可以均摊
但是由于常数问题,
代码:
inline void add(int c){
int p=last,u=++cnt;last=u;
clear(u);len[u]=len[p]+1;
while(p&&!son[p][c])son[p][c]=u,p=link[p];
if(!p){link[u]=1;return;}
int q=son[p][c];
if(len[q]==len[p]+1){link[u]=q;return;}
int v=++cnt;copy(v,q);len[v]=len[p]+1;link[u]=link[q]=v;
while(p&&son[p][c]==q)son[p][c]=v,p=link[p];
}
本文字符串下标从
应用
检查字符串是否出现
给定
个模式串 和一个文本串 ,求有多少个不同的模式串在文本串里出现过。
, 。
直接根据建出来的 SAM 转移即可。
计算字符串出现次数
显然,一个字符串
而如果
于是树形 dp 即可。
有 N 个由小写字母组成的模式串 si 以及一个文本串 S,求每个模式串在文本串中的出现次数。
, , 。
上面已经讲了,但是被卡空间了。【模板】后缀自动机 (SAM) 也类似。
本质不同的子串个数
一个子串就是一条从
但是有更优美的做法,每个状态对应的
所以只需求出每个点的等价类大小,即对于点
给一个的字符串,求不同的子串的个数。
直接来即可。
共进行
次操作,每次在数组 的末尾加入一个数 。每次操作求出, 的不同子串个数。
。
由于
比较大,用 std::map即可。每次末尾加一个数,注意一下即可。
本质不同子串总长度
拓扑排序的方法同样行得通,转移方程(
第二种同样行得通,因为
求字典序第 k 大子串
求出
给定的长度为
的字符串,求出它的第 小子串是什么。
为 则表示不同位置的相同子串算作一个, 为 则表示不同位置的相同子串算作多个。
, , 。
时 还需改动一下。
求第一次出现的位置
维护
当加入新点时
复制一个点时
第一次出现位置即为查询的字符串对应状态的
求每一次出现的位置
每一次出现位置对应这后缀链接树上子树内所有叶子节点的位置。
暴力就可以了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?