


数据整理与命令行环境
数据整理
正则表达式
简介
- 正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等
- 正则表达式通常以(尽管并不总是) / 开始和结束
简单字符
- 没有特殊意义的字符都是简单字符,简单字符就代表自身,绝大部分字符都是简单字符
/abc/ // 匹配 abc /123/ // 匹配 123 /-_-/ // 匹配 -_- /梦幻/ // 匹配 梦幻
普通字符
| 字符 | 描述 |
|---|---|
| [ABC] | 匹配 [...] 中的所有字符,例如 [aeiou]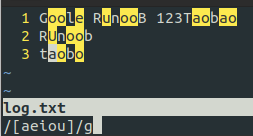 |
| [^ABC] | 匹配除了 [...] 中字符的所有字符,例如 [^aeiou] 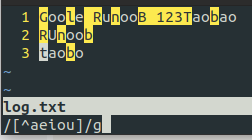 |
| [A-Z] | [A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母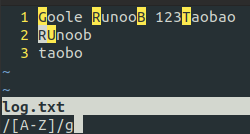 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]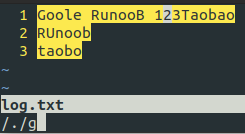 |
| [\s\S] | 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行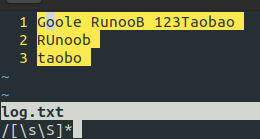 |
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9]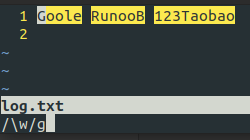 |
元字符
| 元字符 | 含义 | 举例 | 说明 |
|---|---|---|---|
| ^ | 匹配行首字符 | ^x |
以字符x开始的字符串 |
$ | 匹配行尾字符 | x$ |
以字符x结尾的字符串 | ||
| . | 匹配除换行符之外的任意单个字符 | l..e |
love,life,live ... |
| ? | 匹配任意一个可选字符 | xy? |
x,xy |
| * | 匹配前面字符零次或多次重复 | xy* |
x,xy,xyy,xyyy ... |
| + | 匹配前面字符一次或多次重复 | xy+ |
xy,xyy,xyyy ... |
| [...] | 匹配任意一个字符 | [xyz] |
x,y,z |
| () | 对正则表达式进行分组 | (xy)+ |
xy,xyxy,xyxyxy ... |
| 元字符 | 含义 | 举例 | 说明 |
|---|---|---|---|
\{n\} |
匹配n次 | go\{2\}gle |
|
\{n,\} |
匹配最少n次 | go\{2,\}gle |
google,gooogle,goooogle ... |
\{n,m\} |
匹配n到m次 | go\{2,4\} |
google,gooogle,goooogle |
{n} |
匹配n次 | go{2}gle |
|
{n,} |
匹配最少n次 | go{2,}gle |
google,gooogle,goooogle ... |
{n,m} |
匹配n到m次 | go{2,4}gle |
google,gooogle,goooogle |
| |
以或逻辑连接多个匹配 | good|bon |
匹配good或bon |
\ |
转义字符 | \* |
* |
注意,凡是表示范围的量词,都优先匹配上限而不是下限
a{1, 3} // 匹配字符串'aaa'的话,会匹配aaa而不是a a{1, 3}? // 匹配字符串'aaa'的话,会匹配a而不是aaa
修饰符(标记)
- 标记也称为修饰符,正则表达式的标记用于指定额外的匹配策略
- 标记不写在正则表达式里,标记位于表达式之外
| 修饰符 | 含义 | 描述 |
|---|---|---|
| i | ignore - 不区分大小写 | 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别 |
| g | global - 全局匹配 | 查找所有的匹配项 |
| m | multi line - 多行匹配 | 使边界字符 ^ 和 ` |
| ------ | ----------------------------------- | ------------------------------------------------------------ |
| i | ignore - 不区分大小写 | 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别 |
| g | global - 全局匹配 | 查找所有的匹配项 |
| 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾 | ||
| s | 特殊字符圆点 . 中包含换行符 \n |
默认情况下的圆点 . 是 匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n |
拾遗
常见正则表达式
IPv4地址:((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}
端口:((6[0-4]\d{3}|65[0-4]\d{2}|655[0-2]\d|6553[0-5])|[0-5]?\d{0,4})
获取本机IP:ip a | grep inet | grep -v inet6 | awk -F 'inet ' '{print $2}' | awk -F '/' '{print $1}'
排序命令
sort
sort [-fbnrtuk] [file or stdin]
- -f:忽略大小写
- -b:忽略最前面的空格字符部分
- -n:使用【纯数字】进行排序(默认是以文字形式来排序的)
- -r:反向排序
- u:相同的数据中,仅出现一行代表
- -t:分隔符号,默认是用[Tab]键来分隔
- -k:以哪个区间(field)来进行排序的意思
cat /etc/passwd | sort # 将记录在/etc/passwd下的个人账号进行排序
cat /etc/passwd | sort -t ':' -k 3 # 以:来分隔,以第三栏来排序
uniq
- 排序完成后,将重复的数据仅列出一个显示
uniq [-ic]
- -i:忽略大小写
- -c:进行计数
last | cut -d ' ' -f1 | sort | uniq # 使用last将账号列出,仅取出账号栏,进行排序后仅取出一位
last | cut -d ' ' -f1 | sort | uniq -c # 计算每个人的登陆总次数
sed
简介
- Sed是一种功能强大的流式文本编辑器
- 每次仅读取一行内容
- Sed 默认不会直接修改源文件数据,而是会将数据复制到缓冲区中,修改也仅限于缓冲区中的数据
- Sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等
常用命令
- 替换
sed 's/book/books/' file # book部分是我们需要使用的正则表达式 # books是用于替换匹配结果的文本
- 文本注入
sed -i 's/book/books/g' file # 使用后缀 /g 标记会替换每一行中的所有匹配 # 匹配file文件中每一行的所有book替换为books
- 打印特定的行
sed -n 's/test/TEST/p' file # 表示只打印那些发生替换的行
awk
简介
-
简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
-
默认情况下,awk 会将如下变量分配给它在文本行中发现的数据字段:
-
$0 代表整个文本行;
-
$1 代表文本行中的第 1 个数据字段;
-
$2 代表文本行中的第 2 个数据字段;
-
$n 代表文本行中的第 n 个数据字段。
-
基本格式
awk [选项] '条件类型{操作}' filename
例子
- 假设last -n 5的输出如下
[root@www ~]$ last -n 5 <==仅取出前五行 root pts/1 192.168.1.100 Tue Feb 10 11:21 still logged in root pts/1 192.168.1.100 Tue Feb 10 00:46 - 02:28 (01:41) root pts/1 192.168.1.100 Mon Feb 9 11:41 - 18:30 (06:48) dmtsai pts/1 192.168.1.100 Mon Feb 9 11:41 - 11:41 (00:00) root tty1 Fri Sep 5 14:09 - 14:10 (00:01)
- 如果只是显示最近登录的5个帐号
$ last -n 5 | awk '{print $1}' root root root dmtsai root
- 如果只是显示/etc/passwd的账户
$ cat /etc/passwd |awk -F ':' '{print $1}' root daemon bin sys
- 如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割
$ cat /etc/passwd |awk -F ':' '{print $1"\t"$7}' root /bin/bash daemon /bin/sh bin /bin/sh sys /bin/sh
awk工作流程是这样的:读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键",所以3表示登录用户ip,以此类推
命令行环境
任务控制
-
Shell使用Unix提供的信号机制执行进程间通信
-
当一个进程接收到信号时,它会停止执行、处理该信号并基于信号传递的信息来改变其执行
-
<Ctrl-C>:结束进程 -
<Ctrl-Z>:暂停进程 -
fg:前台继续 -
bg:后台继续
jobs
- 列出当前终端会话中尚未完成的全部任务
- 基本格式:
jobs [options]
- 常用选项及含义
| 选项 | 含义 |
|---|---|
| -l | 列出进程的 PID 号 |
| -n | 只列出上次发出通知后改变了状态的进程 |
| -p | 只列出进程的 PID 号 |
| -r | 只列出运行中的进程 |
| -s | 只列出已停止的进程 |
&后缀
- &后缀让命令直接在后台运行
- 一般格式:
./test.sh &
- 注意,后台的进程仍然是终端进程的子进程,一旦关闭终端,后台的进程也会停止
nohup
- 用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行
- nohup 命令,在默认情况下(非重定向时),会输出一个名叫 nohup.out 的文件到当前目录下,如果当前目录的 nohup.out 文件不可写,输出重定向到 $HOME/nohup.out 文件中
一般格式:
nohup ./test.sh &
终端多路复用
介绍
- 在终端同时执行多个任务
- 例如:在终端运行编辑器,同时在终端的另一侧执行程序
tmux
- 我们每次打开一个 终端窗口 (screen),可以看作在终端窗口和用户之间建立了一次 会话 (session),用户在终端窗口中输入命令执行会创建 进程 ,默认情况下窗口和会话是“绑定的”,也就是说窗口关闭,会话及会话下面的所有进程都会结束。我们经常通过ssh远程连接到服务器,并且执行一些长时间运行的程序,如果网络断开,终端窗口关闭,那么与该窗口关联的会话及其下面的进程都会关闭,这是十分不方便的。
- tmux可以允许我们基于面板和标签分割出多个终端窗口,这样便可以同时与多个shell会话进行交互
- tmux可以将窗口和会话分离,窗口的关闭不会影响到会话的状态,会话中运行的进程也不会被中止,在合适的时候,可以新建窗口连接到之前的会话 。
结构和工作流
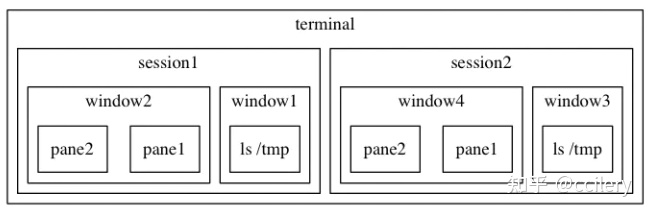
会话(session)
- 每一个会话都是一个独立的工作区,其中包含一个或多个窗口
tmux开始一个新的会话tmux new -s name以指定名称开始一个新的会话tmux ls列出当前所有会话
窗口(window)
- 相当于编辑器或是浏览器中的标签页,从视觉上将一个会话分割为多个部分
<Ctrl-B> c创建一个新窗口,使用<Ctrl-D>关闭<Ctrl-B> N跳转到第N个窗口<Ctrl-B> p切换到前一个窗口<Ctrl-B> n切换到下一个窗口<Ctrl-B> ,重命名当前窗口<Ctrl-B> w列出当前所有窗口
面板(pan)
-
像Vim中的分屏一样,面板使我们可以在一个屏幕里显示多个shell
-
<Ctrl-B> "水平分割 -
<Ctrl-B> %垂直分割 -
<Ctrl-B> <方向>切换到指定方向的面板 -
<Ctrl-B> z切换当前面板的缩放 -
<Ctrl-B> <space>在不同的面板排布间切换 -
tmux快速入门教程请看这里,以及这里(包含
screen命令)
别名
alias
- 对命令重命名
alias showmeit="ps -aux" # 注意,=两边是没有空格的
- 解除使用
unaliax showmeit
- 列出目前已有的命令别名
alias
注意,在默认情况下shell并不会保存别名,为了让别名持续生效,需要将配置放进shell的启动文件里
远端设备
SSH服务
简介
- SSH 是 Secure Shell protocol 的简写 (安全的壳程序协议),它可以透过数据封包加密技术,将等待传输的封包加密后再传输到网络上
连接服务器
- 一般格式
[root@www ~]# ssh [-f] [-o 参数项目] [-p 非正规埠口] [账号@]IP [指令] 选项与参数: -f :需要配合后面的 [指令] ,不登入远程主机直接发送一个指令过去而已; -o 参数项目:主要的参数项目有: ConnectTimeout=秒数 :联机等待的秒数,减少等待的时间 StrictHostKeyChecking=[yes|no|ask]:预设是 ask,若要让 public key 主动加入 known_hosts ,则可以设定为 no 即可。 -p :如果你的 sshd 服务启动在非正规的埠口 (22),需使用此项目; [指令] :不登入远程主机,直接发送指令过去。但与 -f 意义不太相同。
- 直接联机登陆到对方主机
ssh foo@bar.mit.edu # 尝试以用户名foo登陆服务器bar.mit.edu
- 服务器可以通过URL指定(例如bar.mit.edu),也可以使用IP指定(例如foobar@192.168.1.42)
密钥
简介
- 公钥 (public key):提供给远程主机进行数据加密的行为,也就是说,大家都能取得你的公钥来将数据加密的意思
- 私钥 (private key):远程主机使用你的公钥加密的数据,在本地端就能够使用私钥来进行解密。由于私钥是这么的重要, 因此私钥是不能够外流的!只能保护在自己的主机上
- 由于每部主机都应该有自己的密钥 (公钥与私钥),且公钥用来加密而私钥用来解密, 其中私钥不可外流。但因为网络联机是双向的,所以,每个人应该都要有对方的『公钥』
# 产生新的服务器端的 ssh 公钥与服务器自己使用的成对私钥 [root@www ~]# rm /etc/ssh/ssh_host* # 删除密钥档 [root@www ~]# /etc/init.d/sshd restart 正在停止 sshd: [ 确定 ] 正在产生 SSH1 RSA 主机密钥: [ 确定 ] # 底下三个步骤重新产生密钥! 正在产生 SSH2 RSA 主机密钥: [ 确定 ] 正在产生 SSH2 DSA 主机密钥: [ 确定 ] 正在激活 sshd: [ 确定 ] [root@www ~]# date; ll /etc/ssh/ssh_host* Mon Jul 25 11:36:12 CST 2011 -rw-------. 1 root root 668 Jul 25 11:35 /etc/ssh/ssh_host_dsa_key -rw-r--r--. 1 root root 590 Jul 25 11:35 /etc/ssh/ssh_host_dsa_key.pub -rw-------. 1 root root 963 Jul 25 11:35 /etc/ssh/ssh_host_key -rw-r--r--. 1 root root 627 Jul 25 11:35 /etc/ssh/ssh_host_key.pub -rw-------. 1 root root 1675 Jul 25 11:35 /etc/ssh/ssh_host_rsa_key -rw-r--r--. 1 root root 382 Jul 25 11:35 /etc/ssh/ssh_host_rsa_key.pub # 看一下上面输出的日期与档案的建立时间,刚刚建立的新公钥、私钥系统!
密钥生成
- 用户的密钥一般都放在主目录的
.ssh目录里面
ssh-keygen -o -b 4096 [-t rsa|dsa] # 可选 rsa 或 dsa ssh-keygen -o -a 100 -t ed25519 ssh-keygen # 用预设的方法建立密钥(rsa)
基于密钥的认证机制
-
用户公钥保存在服务器的
~/.ssh/authorized_keys文件。你要以哪个用户的身份登录到服务器,密钥就必须保存在该用户主目录的~/.ssh/authorized_keys文件。只要把公钥添加到这个文件之中,就相当于公钥上传到服务器了 -
ssh会查询~/.ssh/authorized_keys来确认哪些用户可以被允许登陆
cat ~/.ssh/id_rsa.pub | ssh user@host "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys" # 文件不存在的情况下 cat .ssh/id_ed25519.pub | ssh foobar@remote 'cat >> ~/.ssh/authorized_keys' ssh-copy-id -i .ssh/id_ed25519.pub foobar@remote # 自动将公钥拷贝到远程服务器的~/.ssh/authorized_keys文件。如果~/.ssh/authorized_keys文件不存在,ssh-copy-id命令会自动创建该文件
- 注意,
authorized_keys文件的权限要设为644,即只有文件所有者才能写。如果权限设置不对,SSH 服务器可能会拒绝读取该文件
通过SSH复制文件
模拟 FTP 的文件传输方式: sftp
- 这个指令的用法与 ssh 很相似,只是 ssh 是用在登入而 sftp 在上传/下载文件而已
[root@www ~]# sftp student@localhost Connecting to localhost... student@localhost's password: <== 这里请输入密码啊! sftp> exit <== 这里就是在等待你输入 ftp 相关指令的地方了!
针对远方服务器主机 (Server) 的命令
- 常规Linux命令
针对本机 (Client) 的命令
- 在命令前面加上l(L的小写)
针对资料上传/下载的命令
| 将档案由本机上传到远程主机 | put [本机目录或档案] [远程] put [本机目录或档案] 如果是这种格式,则档案会放置到目前远程主机的目录下! |
|---|---|
| 将档案由远程主机下载回来 | get [远程主机目录或档案] [本机] get [远程主机目录或档案] 若是这种格式,则档案会放置在目前本机所在的目录当中!可以使用通配符,例如: get * get *.rpm 亦是可以的格式! |
例如:
- 假设 localhost 为远程服务器,且服务器上有 student 这个使用者。你想要 (1)将本机的 /etc/hosts 上传到 student 家目录,并 (2)将 student 的 .bashrc 复制到本机的 /tmp 底下
[root@www ~]# sftp student@localhost sftp> lls /etc/hosts #先看看本机有没有这个档案 /etc/hosts sftp> put /etc/hosts #有的话,那就上传吧! Uploading /etc/hosts to /home/student/hosts /etc/hosts 100% 243 0.2KB/s 00:00 sftp> ls #有没有上传成功?看远程目录下的文件名 hosts sftp> ls -a #那有没有隐藏档呢? . .. .bash_history .bash_logout .bash_profile .bashrc .mozilla hosts sftt> lcd /tmp #切换本机目录到 /tmp sftp> lpwd #只是进行确认而已! Local working directory: /tmp sftp> get .bashrc #没问题就下载吧! Fetching /home/student/.bashrc to .bashrc /home/student/.bashrc 100% 124 0.1KB/s 00:00 sftp> lls -a #看本地端档案档名 . .font-unix keyring-rNd7qX .X11-unix .. .gdm_socket lost+found scim-panel-socket:0-root .bashrc .ICE-unix mapping-root .X0-lock sftp> exit #离开吧!
档案异地直接复制: scp
- 通常使用 sftp 是因为可能不知道服务器上面有什么档名的档案存在,如果已经知道服务器上的档案档名了, 那么最简单的文件传输则是透过 scp 这个指令
[root@www ~]# scp [-pr] [-l 速率] file [账号@]主机:目录名 <==上传 [root@www ~]# scp [-pr] [-l 速率] [账号@]主机:file 目录名 <==下载 选项与参数: -P : 指定远程主机的端口号 -p :保留原本档案的权限数据; -r :复制来源为目录时,可以复制整个目录 (含子目录) -l :可以限制传输的速度,单位为 Kbits/s ,例如 [-l 800] 代表传输速限 100Kbytes/s # 1. 将本机的 /etc/hosts* 全部复制到 127.0.0.1 上面的 student 家目录内 [root@www ~]# scp /etc/hosts* student@127.0.0.1:~ student@127.0.0.1's password: <==输入 student 密码 hosts 100% 207 0.2KB/s 00:00 hosts.allow 100% 161 0.2KB/s 00:00 hosts.deny 100% 347 0.3KB/s 00:00 # 文件名显示 进度 容量(bytes) 传输速度 剩余时间 # 你可以仔细看,出现的讯息有五个字段,意义如上所示。 # 2. 将 127.0.0.1 这部远程主机的 /etc/bashrc 复制到本机的 /tmp 底下 [root@www ~]# scp student@127.0.0.1:/etc/bashrc /tmp
端口转发
本地端口转发
- 通过本地计算机访问远程计算机
ssh -L 8080:127.0.0.1:80 user@webserver # -L参数表示本地转发,8080是本地端口,80是远程端口
curl http://localhost:8080 # 访问本机的8080端口,就是访问webserver的80端口
注意,本地端口转发采用 HTTP 协议,不用转成 SOCKS5 协议
远程端口转发
- 通过远程计算机访问本地计算机
ssh -R 10123:127.0.0.1:123 user@webserver # -R参数表示远程端口转发,10123是远程端口,123是本地端口
SSH配置
-
服务器密钥系统:/etc/ssh/ssh_host*
-
服务器公钥记录文件:~/.ssh/known_hosts
-
sshd 服务器细部设定:/etc/ssh/sshd_config
-
本机SSH配置:~/.ssh/config
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。














【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现