Docker 安装 Kubernetes
- 创建三个虚拟机
- 设置Linux环境(三个节点都执行)
- 所有节点安装 docker、kubeadm、kubelet、kubectl
- 部署 k8s-master
- 安装 POD 网络插件(CNI)
- 加入 kubenetes 的 Node 节点
- Ingress
- DashBoard
- kubesphere
创建三个虚拟机
VM16 平台每次挂起都要重启,不然服务连不上
分别为 k8s-node1,k8s-node2 和 k8s-node3.
设置Linux环境(三个节点都执行)
关闭防火墙
sudo systemctl stop firewalld
sudo systemctl disable firewalld
关闭 selinux
sudo sed -i 's/enforcing/disabled/' /etc/selinux/config
sudo setenforce 0
关闭 swap
sudo swapoff -a #临时关闭
sudo sed -ri 's/.*swap.*/#&/' /etc/fstab #永久关闭
free /g #验证,swap必须为0
添加主机名与IP对应关系:
查看主机名:
hostname
如果主机名不正确,可以通过命令来进行修改。
hostnamectl set-hostname newhostname
修改 hosts 文件
vim /etc/hosts
192.168.52.132 k8s-node1
192.168.52.133 k8s-node2
192.168.52.134 k8s-node3
将桥接的IPV4流量传递到iptables的链:
sudo cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
应用规则:
sysctl --system
date 查看时间(可选)
yum -y install ntpupdate
ntpupdate time.window.com #同步最新时间
所有节点安装 docker、kubeadm、kubelet、kubectl
安装 Docker
参考安装 Docker
Kubenetes 默认CRI(容器运行时)为 Docker,因此先安装 Docker。
添加Yum源
- 阿里云K8s源
sudo cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
- 华为源K8s源
sudo cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://repo.huaweicloud.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://repo.huaweicloud.com/kubernetes/yum/doc/yum-key.gpg https://repo.huaweicloud.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
- 腾讯K8s源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.cloud.tencent.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
EOF
- 清华大学K8s源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=kubernetes
baseurl=https://mirrors.tuna.tsinghua.edu.cn/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
EOF
安装 kubeadm,kubelet 和 kubectl
检查 yum 源是否有 kube
yum list|grep kube
安装
yum install -y --nogpgcheck kubelet-1.17.3 kubeadm-1.17.3 kubectl-1.17.3 kubernetes-cni-0.7.5
# 修改版本
yum downgrade kubernetes-cni-0.7.5-0.x86_64
开机启动
systemctl enable kubelet
systemctl start kubelet
查看kubelet的状态:
systemctl status kubelet
查看kubelet版本:
kubelet --version
[root@k8s-node2 ~]# Kubernetes v1.17.3
部署 k8s-master
查看 kubeadm 所需要的镜像版本
kubeadm config images list
master 节点初始化
在 Master 节点上,创建并执行 master_images.sh
#!/bin/bash
images=(
kube-apiserver:v1.17.17
kube-proxy:v1.17.17
kube-controller-manager:v1.17.17
kube-scheduler:v1.17.17
coredns:1.6.5
etcd:3.4.3-0
pause:3.1
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
done
# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName
初始化kubeadm,并不要清楚打印信息
kubeadm init \
--apiserver-advertise-address=192.168.52.132 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.17.3 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--token-ttl 0 \
-v6
参数说明:
- --apiserver-advertise-address=192.168.52.132 这个参数就是 master 主机的IP地址,例如我的 Master 主机的IP是:192.168.52.132
- --image-repository=registry.aliyuncs.com/google_containers 这个是镜像地址,由于国外地址无法访问,故使用的阿里云仓库地址:registry.aliyuncs.com/google_containers
- --kubernetes-version=v1.17.3 这个参数是下载的 k8s 软件版本号
- --service-cidr=10.96.0.0/12 这个参数后的 IP 地址直接就套用 10.96.0.0/12 ,以后安装时也套用即可,不要更改
- --pod-network-cidr=10.244.0.0/16 k8s 内部的 pod 节点之间网络可以使用的IP段,不能和 service-cidr 写一样,如果不知道怎么配,就先用这个10.244.0.0/16`
- -v6 打印详细信息
注:
- --apiserver-advertise-address=192.168.52.132 :这里的IP地址是master主机的地址,为上面的 eth0 网卡的地址;
- 由于默认拉取镜像地址 k8s.gcr.io 国内无法访问,这里指定阿里云镜像仓库地址。可以手动按照我们的 images.h 先拉取镜像,地址变为 registry.aliyuncs.om/gogle_containers 也可以。
科普:无类别域间路由(Clasles Inter-Domain Routing、CIDR)是一个用于给用户分配 IP
地址以及在互联网上有效地路由 IP 数据包的对 IP 地址进行归类的方法。
拉取可能失败,需要下载镜像。
运行完成提前复制:加入集群的令牌
执行结果:
[root@k8s-node1 k8s]
kubeadm init \
--apiserver-advertise-address=192.168.52.132 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.17.3 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--token-ttl 0 \
-v6
W0503 14:07:12.594252 10124 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[init] Using Kubernetes version: v1.17.3
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-node1 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.52.129]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-node1 localhost] and IPs [192.168.52.129 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-node1 localhost] and IPs [192.168.52.129 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
W0503 14:07:30.908642 10124 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[control-plane] Creating static Pod manifest for "kube-scheduler"
W0503 14:07:30.911330 10124 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 22.506521 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.18" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node k8s-node1 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node k8s-node1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: sg47f3.4asffoi6ijb8ljhq
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
#表示kubernetes已经初始化成功了
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.52.132:6443 --token xlx9lk.8xwxuojy7cp2neqp \
--discovery-token-ca-cert-hash sha256:a1b1190cb9b70f63126d68e126e9bd8c3521319986d4367736ba22f77f72a7c1
[root@k8s-node1 opt]#
由于默认拉取镜像地址 k8s.cr.io 国内无法访问,这里指定阿里云仓库地址。可以手动按照我们的 images.sh 先拉取镜像。
地址变为:registry.aliyuncs.com/googole_containers也可以。
科普:无类别域间路由(Classless Inter-Domain Routing 、CIDR)是一个用于给用户分配IP地址以及在互联网上有效第路由IP数据包的对IP地址进行归类的方法。
拉取可能失败,需要下载镜像。
运行完成提前复制:加入集群的令牌。
测试Kubectl(主节点执行)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
详细部署文档:https://kubernetes.io/docs/concepts/cluster-administration/addons/
kubectl get nodes #获取所有节点
目前Master状态为notready。等待网络加入完成即可。
journalctl -u kubelet #查看kubelet日志
初始化完成打印里面有,并且这个 token 两个小时有效
kubeadm join 192.168.52.132:6443 --token xlx9lk.8xwxuojy7cp2neqp \
--discovery-token-ca-cert-hash sha256:a1b1190cb9b70f63126d68e126e9bd8c3521319986d4367736ba22f77f72a7c1
如果 token 过期
生成 token
过期时间两个小时
kubeadm token create --print-join-command
不会过期
kubeadm token create --ttl 0 --print-join-command
安装 POD 网络插件(CNI)
在 master 节点上执行按照POD网络插件
kubectl apply -f \
https://raw.githubusercontent.com/coreos/flanne/master/Documentation/kube-flannel.yml
以上地址可能被墙,可以直接获取本地已经下载的flannel.yml运行即可,如:
[root@k8s-node1 k8s] kubectl apply -f kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds-amd64 created
daemonset.apps/kube-flannel-ds-arm64 created
daemonset.apps/kube-flannel-ds-arm created
daemonset.apps/kube-flannel-ds-ppc64le created
daemonset.apps/kube-flannel-ds-s390x created
[root@k8s-node1 k8s]#
同时 flannel.yml 中指定的 images 访问不到可以去 docker hub 找一个 wget yml 地址
vi 修改 yml 所有 amd64 的地址修改了即可
等待大约3分钟
kubectl get pods -n kube-system 查看指定名称空间的 pods
kubectl get pods --all-namespaces 查看所有名称空间的 pods
ip link set cni0 down 如果网络出现问题,关闭cni0,重启虚拟机继续测试
执行 watch kubectl get pod -n kube-system -o wide 监控pod进度
等待3-10分钟,完全都是 running 以后继续
查看命名空间:
[root@k8s-node1 k8s] kubectl get ns
NAME STATUS AGE
default Active 30m
kube-node-lease Active 30m
kube-public Active 30m
kube-system Active 30m
[root@k8s-node1 k8s]#
[root@k8s-node1 k8s] kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-546565776c-9sbmk 0/1 Pending 0 31m
kube-system coredns-546565776c-t68mr 0/1 Pending 0 31m
kube-system etcd-k8s-node1 1/1 Running 0 31m
kube-system kube-apiserver-k8s-node1 1/1 Running 0 31m
kube-system kube-controller-manager-k8s-node1 1/1 Running 0 31m
kube-system kube-flannel-ds-amd64-6xwth 1/1 Running 0 2m50s
kube-system kube-proxy-sz2vz 1/1 Running 0 31m
kube-system kube-scheduler-k8s-node1 1/1 Running 0 31m
[root@k8s-node1 k8s]#
查看 master 上的节点信息:
[root@k8s-node1 k8s] kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready master 34m v1.17.3 #status为ready才能够执行下面的命令
[root@k8s-node1 k8s]#
最后再次执行,并且分别在“k8s-node2”和“k8s-node3”上也执行这里命令:
kubeadm join 192.168.52.132:6443 --token xlx9lk.8xwxuojy7cp2neqp \
--discovery-token-ca-cert-hash sha256:a1b1190cb9b70f63126d68e126e9bd8c3521319986d4367736ba22f77f72a7c1
[root@k8s-node1 opt] kubectl get nodes;
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready master 47m v1.17.3
k8s-node2 NotReady <none> 75s v1.17.3
k8s-node3 NotReady <none> 76s v1.17.3
[root@k8s-node1 opt]#
监控 pod 进度
watch kubectl get pod -n kube-system -o wide
等到所有的 status 都变为 running 状态后,再次查看节点信息:
[root@k8s-node1 ~] kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready master 3h50m v1.17.3
k8s-node2 Ready <none> 3h3m v1.17.3
k8s-node3 Ready <none> 3h3m v1.17.3
[root@k8s-node1 ~]#
加入 kubenetes 的 Node 节点
在 node 节点中执行,向集群中添加新的节点,执行在 kubeadm init 输出的 kubeadm join 命令;
确保 node 节点成功:
Ingress
通过 Ingress 发现 pod 进行关联。基于域名访问
通过 Ingress controller 实现 POD 负载均衡
支持 TCP/UDP 4 层负载均衡和 HTTP 7 层负载均衡
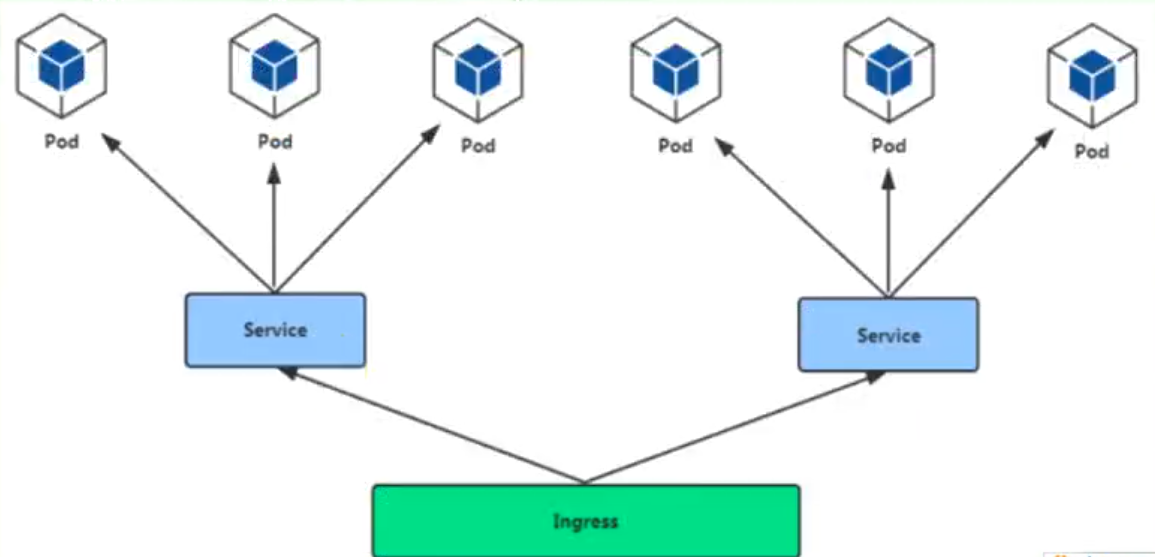
步骤:
(1)部署 Ingress controller
执行“k8s/ingress-controller.yaml”
[root@k8s-node1 k8s] kubectl apply -f ingress-controller.yaml
namespace/ingress-nginx created
configmap/nginx-configuration created
configmap/tcp-services created
configmap/udp-services created
serviceaccount/nginx-ingress-serviceaccount created
clusterrole.rbac.authorization.k8s.io/nginx-ingress-clusterrole created
role.rbac.authorization.k8s.io/nginx-ingress-role created
rolebinding.rbac.authorization.k8s.io/nginx-ingress-role-nisa-binding created
clusterrolebinding.rbac.authorization.k8s.io/nginx-ingress-clusterrole-nisa-binding created
daemonset.apps/nginx-ingress-controller created
service/ingress-nginx created
[root@k8s-node1 k8s]#
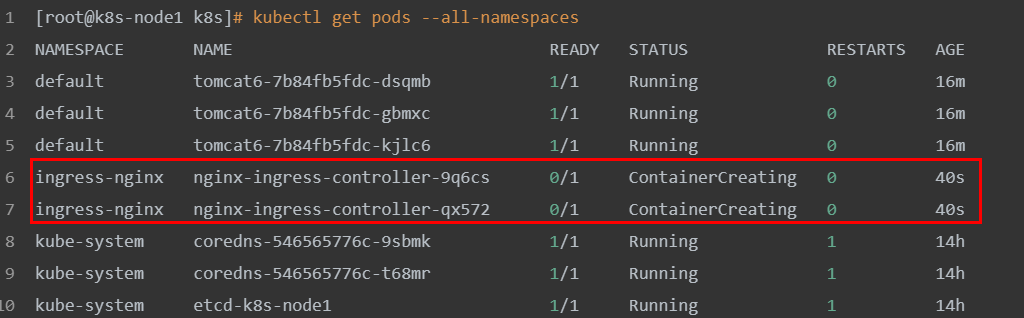
查看
[root@k8s-node1 k8s] kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
default tomcat6-7b84fb5fdc-dsqmb 1/1 Running 0 16m
default tomcat6-7b84fb5fdc-gbmxc 1/1 Running 0 16m
default tomcat6-7b84fb5fdc-kjlc6 1/1 Running 0 16m
ingress-nginx nginx-ingress-controller-9q6cs 0/1 ContainerCreating 0 40s
ingress-nginx nginx-ingress-controller-qx572 0/1 ContainerCreating 0 40s
kube-system coredns-546565776c-9sbmk 1/1 Running 1 14h
kube-system coredns-546565776c-t68mr 1/1 Running 1 14h
kube-system etcd-k8s-node1 1/1 Running 1 14h
kube-system kube-apiserver-k8s-node1 1/1 Running 1 14h
kube-system kube-controller-manager-k8s-node1 1/1 Running 1 14h
kube-system kube-flannel-ds-amd64-5xs5j 1/1 Running 2 13h
kube-system kube-flannel-ds-amd64-6xwth 1/1 Running 2 14h
kube-system kube-flannel-ds-amd64-fvnvx 1/1 Running 1 13h
kube-system kube-proxy-7tkvl 1/1 Running 1 13h
kube-system kube-proxy-mvlnk 1/1 Running 2 13h
kube-system kube-proxy-sz2vz 1/1 Running 1 14h
kube-system kube-scheduler-k8s-node1 1/1 Running 1 14h
[root@k8s-node1 k8s]#
这里 master 节点负责调度,具体执行交给 node2 和 node3 来完成,能够看到它们正在下载镜像
(2)创建 Ingress 规则
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: web
spec:
rules:
- host: tomcat6.kubenetes.com
http:
paths:
- backend:
serviceName: tomcat6
servicePort: 80
[root@k8s-node1 k8s] touch ingress-tomcat6.yaml
#将上面的规则,添加到ingress-tomcat6.yaml文件中
[root@k8s-node1 k8s] vi ingress-tomcat6.yaml
[root@k8s-node1 k8s] kubectl apply -f ingress-tomcat6.yaml
ingress.extensions/web created
[root@k8s-node1 k8s]#
修改本机的 hosts 文件,添加如下的域名转换规则:
192.168.56.102 tomcat6.kubenetes.com
测试: http://tomcat6.kubenetes.com/
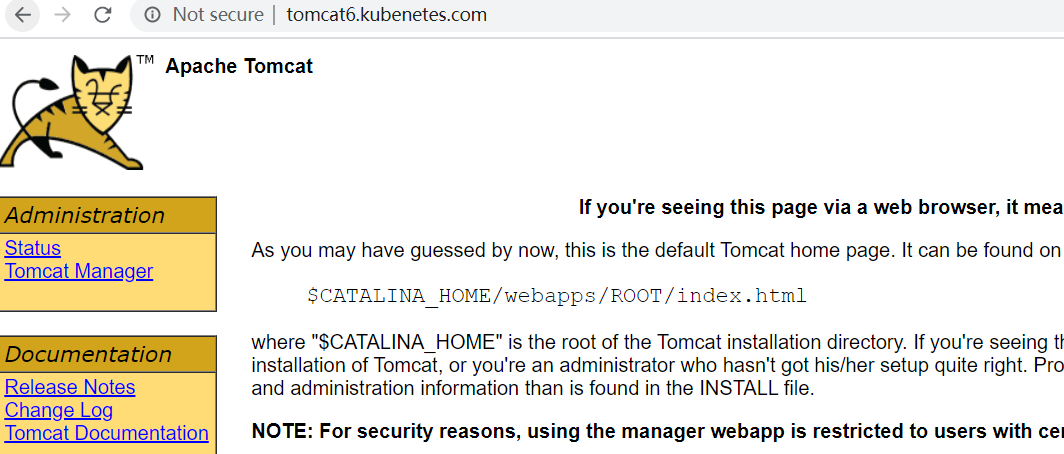
并且集群中即便有一个节点不可用,也不影响整体的运行。
DashBoard
1、部署 DashBoard
kubectl appy -f kubernetes-dashboard.yaml
文件在“k8s”源码目录提供
2、暴露 DashBoard 为公共访问
默认 DashBoard 只能集群内部访问,修改 Service 为 NodePort 类型,暴露到外部
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 3001
selector:
k8s-app: kubernetes-dashboard
访问地址:http://NodeIP:30001
3、创建授权账号
kubectl create serviceaccount dashboar-admin -n kube-sysem
kubectl create clusterrolebinding dashboar-admin --clusterrole=cluter-admin --serviceaccount=kube-system:dashboard-admin
kubectl describe secrets -n kube-system $( kubectl -n kube-system get secret |awk '/dashboard-admin/{print $1}' )
使用输出的 token 登录 dashboard
kubesphere
默认的 dashboard 没啥用,我们用 kubesphere 可以打通全部的 devops 链路, kubesphere 集成了很多套件,集群要求比较高
https://kubesphere.io
kuboard 也很不错,集群要求不高
https://kuboard.cn/support/
1、简洁
kubesphere 是一款面向云原声设计的开源项目,在目前主流容器调度平台kubernets 智商构建的分布式多用户容器管理平台,提供简单易用的操作界面以及向导式操作方式,在降低用户使用容器调度平台学习成本的同时,极大降低开发、测试、运维的日常工作的复杂度。
2、安装前提条件
1、安装 helm(master 节点执行)
helm 是 kubernetes 的包管理器。包管理器类似于在 Ubuntu 中使用的 apt,centos 中的 yum 或者 python 中的 pip 一样,能够快速查找,下载和安装软件包。Helm 有客户端组件helm和服务端组件 Tiller 组成,能够将一组 K8S 资源打包统一管理,是查找、共享和使用为 Kubernetes 构建的软件的最佳方式。
1)安装
curl -L https://git.io/get_helm.sh|bash
由于被墙的原因,使用我们给定的 get_helm.sh。
[root@k8s-node1 k8s] ll
total 68
-rw-r--r-- 1 root root 7149 Feb 27 01:58 get_helm.sh
-rw-r--r-- 1 root root 6310 Feb 28 05:16 ingress-controller.yaml
-rw-r--r-- 1 root root 209 Feb 28 13:18 ingress-demo.yml
-rw-r--r-- 1 root root 236 May 4 05:09 ingress-tomcat6.yaml
-rwxr--r-- 1 root root 15016 Feb 26 15:05 kube-flannel.yml
-rw-r--r-- 1 root root 4737 Feb 26 15:38 kubernetes-dashboard.yaml
-rw-r--r-- 1 root root 3841 Feb 27 01:09 kubesphere-complete-setup.yaml
-rw-r--r-- 1 root root 392 Feb 28 11:33 master_images.sh
-rw-r--r-- 1 root root 283 Feb 28 11:34 node_images.sh
-rw-r--r-- 1 root root 1053 Feb 28 03:53 product.yaml
-rw-r--r-- 1 root root 931 May 3 10:08 Vagrantfile
[root@k8s-node1 k8s] sh get_helm.sh
Downloading https://get.helm.sh/helm-v2.16.6-linux-amd64.tar.gz
Preparing to install helm and tiller into /usr/local/bin
helm installed into /usr/local/bin/helm
tiller installed into /usr/local/bin/tiller
Run 'helm init' to configure helm.
[root@k8s-node1 k8s]#
如果都不行,指定版本
./get_helm.sh --version v2.16.6
2)验证版本
helm version
3)创建权限(master 执行)
创建 helm-rbac.yaml,写入如下内容
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kube-system
应用配置:
[root@k8s-node1 k8s] kubectl apply -f helm-rbac.yaml
serviceaccount/tiller created
clusterrolebinding.rbac.authorization.k8s.io/tiller created
[root@k8s-node1 k8s]#
2、安装 Tilller(Master 执行)
1、初始化
[root@k8s-node1 k8s] helm init --service-account=tiller --tiller-image=sapcc/tiller:v2.16.3 --history-max 300 --stable-repo-url=https://charts.helm.sh/stable
Creating /root/.helm
Creating /root/.helm/repository
Creating /root/.helm/repository/cache
Creating /root/.helm/repository/local
Creating /root/.helm/plugins
Creating /root/.helm/starters
Creating /root/.helm/cache/archive
Creating /root/.helm/repository/repositories.yaml
Adding stable repo with URL: https://kubernetes-charts.storage.googleapis.com
Adding local repo with URL: http://127.0.0.1:8879/charts
$HELM_HOME has been configured at /root/.helm.
Tiller (the Helm server-side component) has been installed into your Kubernetes Cluster.
Please note: by default, Tiller is deployed with an insecure 'allow unauthenticated users' policy.
To prevent this, run `helm init` with the --tiller-tls-verify flag.
For more information on securing your installation see: https://v2.helm.sh/docs/securing_installation/
[root@k8s-node1 k8s]#
--tiller-image 指定镜像,否则会被墙,等待节点上部署的 tiller 完成即可。
可能会报错---Error: error initializing: Looks like "https://kubernetes-charts.storage.googleapis.com" is not a valid chart repository or cannot be reached: Get https://kubernetes-charts.storage.googleapis.com/index.yaml:
添加:--stable-repo-url=https://charts.helm.sh/stable
原因:https://kubernetes-charts.storage.googleapis.com/index.yaml 已经弃用,新的仓库是 https://charts.helm.sh/stable
[root@k8s-node1 k8s] kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-546565776c-9sbmk 1/1 Running 3 23h
coredns-546565776c-t68mr 1/1 Running 3 23h
etcd-k8s-node1 1/1 Running 3 23h
kube-apiserver-k8s-node1 1/1 Running 3 23h
kube-controller-manager-k8s-node1 1/1 Running 3 23h
kube-flannel-ds-amd64-5xs5j 1/1 Running 4 22h
kube-flannel-ds-amd64-6xwth 1/1 Running 5 23h
kube-flannel-ds-amd64-fvnvx 1/1 Running 4 22h
kube-proxy-7tkvl 1/1 Running 3 22h
kube-proxy-mvlnk 1/1 Running 4 22h
kube-proxy-sz2vz 1/1 Running 3 23h
kube-scheduler-k8s-node1 1/1 Running 3 23h
kubernetes-dashboard-975499656-jxczv 0/1 ImagePullBackOff 0 7h45m
tiller-deploy-8cc566858-67bxb 1/1 Running 0 31s
[root@k8s-node1 k8s]#
查看集群的所有节点信息:
kubectl get node -o wide
[root@k8s-node1 k8s] kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-node1 Ready master 23h v1.17.3 10.0.2.15 <none> CentOS Linux 7 (Core) 3.10.0-957.12.2.el7.x86_64 docker://19.3.8
k8s-node2 Ready <none> 22h v1.17.3 10.0.2.4 <none> CentOS Linux 7 (Core) 3.10.0-957.12.2.el7.x86_64 docker://19.3.8
k8s-node3 Ready <none> 22h v1.17.3 10.0.2.5 <none> CentOS Linux 7 (Core) 3.10.0-957.12.2.el7.x86_64 docker://19.3.8
[root@k8s-node1 k8s]#
查看是否有 NoSchedule
kubectl describe node k8s-node1 | grep Taint
去除 NoSchedule
kubectl taint nodes k8s-node1 node-role.kubernetes.io/master:NoSchedule-
2、安装 OpenEBS
- 创建 OpenEBS 的namespace,OpenEBS 相关资源将创建在这个 namespace 下
kubectl create ns openebs
- 安装 OpenEBS,以下列出两种方法,可参考其中任意一种进行创建
A. 若集群已安装了 Helm,可通过 Helm 命令来安装 OpenEBS:
helm repo add openebs https://openebs.github.io/charts
helm repo update
helm repo list
helm install --namespace openebs --name openebs stable/openebs --version 1.5.0 --repo https://charts.helm.sh/stable
报错:Error: release openebs failed: namespaces "openebs" is forbidden: User "system:serviceaccount:kube-system:tiller" cannot get resource "namespaces" in API group "" in the namespace "openebs"
解决办法
执行下面两行命令
kubectl create clusterrolebinding tiller-cluster-rule --clusterrole=cluster-admin --serviceaccount=kube-system:tiller
kubectl patch deploy --namespace kube-system tiller-deploy -p '{"spec":{"template":{"spec":{"serviceAccount":"tiller"}}}}'
B. 除此之外还可以通过 kubectl 命令安装
kubectl apply -f https://openebs.github.io/charts/openebs-operator-1.5.0.yaml
- 安装 OpenEBS 后将自动创建 4个 StorageClass,查看创建的 StorageClass:
[root@k8s-node1 k8s] kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
openebs-device openebs.io/local Delete WaitForFirstConsumer false 57s
openebs-hostpath openebs.io/local Delete WaitForFirstConsumer false 57s
openebs-jiva-default openebs.io/provisioner-iscsi Delete Immediate false 58s
openebs-snapshot-promoter volumesnapshot.external-storage.k8s.io/snapshot-promoter Delete Immediate false 57s
- 如下将 openebs-hostpath 设置为 默认的 StorageClass:
kubectl patch storageclass openebs-hostpath -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
storageclass.storage.k8s.io/openebs-hostpath patched
- 至此,OpenEBs 的LocalPV 已作为默认的存储类型创建成功。由于在文档开头手动去掉了 master 节点的 Taint,我们以在安装完 OpenEBS 后将 master 节点 Taint 加上,避免业务相关的工作负载调度到 master 节点抢占 master 资源:
kubectl taint nodes k8s-node1 node-role.kubernetes.io=master:NoSchedule
3、测试
helm install stable/nginx-ingress --name nginx-ingress
最小化安装 KubeSphere
所有节点 docker 都要换源。用 docker 原始源有下载限制
若集群可用 CPU > 1 Core 且可用内存 > 2 G,可以使用以下命令最小化安装 KubeSphere:
kubectl apply -f https://raw.githubusercontent.com/kubesphere/ks-installer/master/kubesphere-minimal.yaml
提示:若您的服务器提示无法访问 GitHub,可将 kubesphere-minimal.yaml 或 kubesphere-complete-setup.yaml 文件保存到本地作为本地的静态文件,再参考上述命令进行安装。
- 查看滚动刷新的安装日志,请耐心等待安装成功。
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
说明:安装过程中若遇到问题,也可以通过以上日志命令来排查问题。
成功:
#####################################################
### Welcome to KubeSphere! ###
#####################################################
Console: http://192.168.52.132:30880
Account: admin
Password: P@88w0rd
NOTES:
1. After logging into the console, please check the
monitoring status of service components in
the "Cluster Status". If the service is not
ready, please wait patiently. You can start
to use when all components are ready.
2. Please modify the default password after login.
#####################################################
# 删除 Evicted 状态
kubectl get pods --all-namespaces | grep Evicted | awk '{system("kubectl delete pod "$2" -n "$1"")}'
# 删除 ErrImagePull 和 ImagePullBackOff 状态
kubectl get pods --all-namespaces | grep -E "ErrImagePull | ImagePullBackOff" | awk '{system("kubectl delete pod "$2" -n "$1"")}'
journalctl -u kubelet
docker rm $(docker ps -aqf "status=exited")
for i in `ls ./`;
do
sed -i "s/\r//g" "${i}"
done
master监控Node各节点
watch kubectl get pod -n kube-system -o wide
watch kubectl get pods --all-namespaces -o wide
安装可插拔的功能组件
最小化安装后安装可插拔的功能组件(根据需要安装):https://v2-1.docs.kubesphere.io/docs/zh-CN/installation/install-metrics-server/
安装后如何开启 Metrics-server 安装
通过修改 ks-installer 的 configmap 可以选装组件,执行以下命令。
kubectl edit cm -n kubesphere-system ks-installer
参考如下修改 ConfigMap
metrics-server:
enabled: True
保存退出,参考 验证可插拔功能组件的安装 ,通过查询 ks-installer 日志或 Pod 状态验证功能组件是否安装成功。
-
Metrics-Server开启HPA【监控CPU使用率 弹性伸缩】:关闭
-
ogging日志系统:关闭
-
DevOps系统(Jenkins一站式部署):开启
- sonarqube:开启
-
Service Mesh微服务治理功能【熔断、限流、链路追踪】【前提是要开启日志】:关闭
-
notification告警通知系统:开启
-
alerting:开启
-
删除污点
-
修改配置部署文件,实现插拔安装:
kubectl edit cm -n kubesphere-system ks-installer
- 编辑yaml,开启以下功能,修改结束保存退出即可
- DevOps系统(Jenkins一站式部署)
- sonarqube
- notification
- alerting
- 监控安装过程
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
kubectl get pods --all-namespaces
6.设置污点
kubectl taint nodes k8s-node1 node-role.kubernetes.io/master=:NoSchedule
90b9af22f787173b76dbced1706049dcef567d57
http://60.204.212.110:32880/devops_webhook/git/?url=https://gitee.com/tmesh/devops-java-sample
搭建 mysql 主从集群
如果没有指定的都选择默认值
一、创建主机
1、创建配置
- tmeshmall-mysql-master-cnf,别名:master 配置
- 配置设置
key:my.cnf
value:
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
server-id=1
log-bin=mysql-bin
read-only=0
binlog-do-db=tmeshmall_oms
binlog-do-db=tmeshmall_pms
binlog-do-db=tmeshmall_sms
binlog-do-db=tmeshmall_ums
binlog-do-db=tmeshmall_wms
binlog-do-db=tmeshmall_admin
replicate-ignore-db=mysql
replicate-ignore-db=sys
replicate-ignore-db=performance_schema
replicate-ignore-db=information_schema
2、创建pvc
名称: tmeshmall-mysql-master-pvc
单节点读写+10Gi
创建
3、创建有状态服务
- 名称 mysql-master 别名:mysql 主节点
- 选择:容器组分散部署
- 添加容器镜像
- mysql:5.7
- 使用默认端口
- 高级设置:
- CPU 0.5
- 内存 2000Mi
- 环境变量,选择之前设置的密钥 root 密码【密文】
- MYSQL_ROOT_PASSWORD
- 挂载配置文件
- 读写 /etc/mysql
- 选择特定的键和路径
- my.cnf my.cnf【选择 key 为 my.cnf 的挂载到 /etc/mysql 的 my.cnf 文件中】
- 挂载存储,master-pvc【mysql 数据放的路径】
- 选择已有存储卷
- 读写 /var/lib/mysql
- 开启会话保持
4、创建成功,查看服务 mysql-master
- 查看 DNS: mysql-master.tmeshmall
- 随便进入一个容器的终端: ping mysql-master.tmeshmall可以 ping 通
二、创建从机
- 创建 pvc:tmeshmall-mysql-slaver-pvc
- 读写:10Gi
- 创建配置:mysql-slaver-cnf
- key:my.cnf
- value:
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
server-id=2
log-bin=mysql-bin
read-only=1
binlog-do-db=tmeshmall_oms
binlog-do-db=tmeshmall_pms
binlog-do-db=tmeshmall_sms
binlog-do-db=tmeshmall_ums
binlog-do-db=tmeshmall_wms
binlog-do-db=tmeshmall_admin
replicate-ignore-db=mysql
replicate-ignore-db=sys
replicate-ignore-db=performance_schema
replicate-ignore-db=information_schema
3、创建有状态服务
- 名称 mysql-slaver 别名:mysql 从节点
- 选择:容器组分散部署
- 添加容器镜像
- mysql:5.7
- 使用默认端口
- 高级设置:
- CPU 0.5
- 内存 2000Mi
- 环境变量,选择之前设置的密钥 root 密码
- MYSQL_ROOT_PASSWORD
- 挂载配置文件
- 读写 /etc/mysql
- 选择特定的键和路径
- my.cnf my.cnf【选择 key 为 my.cnf 的挂载到 /etc/mysql 的 my.cnf 文件中】
- 挂载存储,master-pvc【mysql 数据放的路径】
- 选择已有存储卷
- 读写 /var/lib/mysql
- 开启会话保持
4、创建成功,查看服务 mysql-master
- 查看 DNS: mysql-master.tmeshmall
- 随便进入一个容器的终端: ping mysql-master.tmeshmall 可以 ping 通
三、为 master 授权用户来他的同步数据
1、进入 master 容器,进入容器终端
mysql -uroot -proot
- 授权 root 可以远程访问(主从无关,方便我们可以远程链接 mysql)(可忽略)
grant all privileges on *.* to 'root'@'%' IDENTIFIED BY 'root' with grant option;
flush privileges;
- 添加同步用户,链接 master 数据库,在 master 授权一个 复制权限的 用户
GRANT REPLICATION SLAVE ON *.* TO 'backup'@'%' IDENTIFIED BY '123456';
- 查看 master 状态,复制文件夹名字,例如 mysql-bin.000001
show master status;
- 配置 slaver 同步 master 数据
进入 slaver 容器
mysql -uroot -p root
- 授权 root 可以远程访问(主从无关,方便我们可以远程链接 mysql)
grant all privileges on *.* to 'root'@'%' IDENTIFIED BY 'root' with grant option;
flush privileges;
- 设置主库连接,这里的 master-host 填写之前的 DNS
change master to master_host='mysql-master.tmeshmall',master_user='backup',master_password='root',master_log_file='mysql-bin.000001',master_log_pos=0,master_port=3306;
- 启动从库同步
start slave;
- 查看从库状态
show slave status;
搭建 redis 主从集群
1、创建 redis 配置
tmeshmall-redis-conf
key:redis-conf
value:
appendonly yes
2、创建pvc
tmeshmall-redis-pvc
单个节点读写,5Gi
3、创建有状态服务
- 设置基本信息
- 名称:redis
- 添加镜像:redis:5.0.7
- 使用默认端口
- CPU:0.5
- 内存:500Mi
- 启动命令:这个不是环境变量【参照 docker 语句】
- 运行命令:redis-server
- 参数:/etc/redis/redis.conf
- 挂载 pvc【挂载的目录就是 redis 数据存储的地方,具体可以查看 docker hub】
- 读写 /data
- 挂载配置文件
- 读写 /etc/redis
- 选择特定的键和路径
- 选择键:redis-conf【就是创建配置的时候的 key】
- 挂载路径:redis.conf【/etc/redis/redis.conf】
搭建elasticsearch主从集群
1、创建配置
名称:tmeshmall-elasticsearch-conf
key:http.host
value:0.0.0.0
其次docker run -e 指定的环境变量都可以用 key-value 指定,而不是之前的整个文件的形式存储值
key:ES_JAVA_OPTS
value:-Xms300m -Xmx300m
key:discovery.type=single-node
value:single-node
2、创建pvc
名称:tmeshmall-elasticsearch-pvc
单个节点读写+10Gi
3、创建有状态服务
- 名称:elasticsearch
添加镜像:elasticsearch:7.4.2
使用默认端口
0.5CPU+1500Mi - 添加环境变量:选择之前创建的配置,ES_JAVA_OPTS和discovery.type和http.host
- 挂载存储卷
- 读写 /usr/share/elasticsearch/data
- 验证
- 使用 admin 登录 kubesphere:192.168.56.100:30880/login
- admin/P@88w0rd
- 打开控制台:curl http://elasticsearch.tmeshmall:9200【服务的DNS,查看是否有打印】
- 使用 admin 登录 kubesphere:192.168.56.100:30880/login
4、安装kibana
docker run -name kibana -e ELASTICSEARCH_HOSTS=http://192.168.56.10:9200 -p 5601:5601 -d kibana:7.4.2
创建一个无状态服务
- 名称:kibana
- 镜像:kibana:7.4.2
- 环境变量:
- ELASTICSEARCH_HOSTS http://elasticsearch.tmeshmall:9200【DNS 地址】
- 选中外网访问
- NodePort
访问192.168.56.100:32157
- NodePort
搭建 rabbitmq 主从集群
1、创建 pvc
tmeshmall-rabbitmq-pvc
10Gi
2、创建有状态服务
名称:rabbitmq-management
镜像:rabbitmq:management
环境变量:RABBITMQ_ERLANG_COOKIE tmesh
挂载pvc
读写 /var/lib/rabbitmq
k8s搭建Nacos
nacos 的数据可以配置到数据库中,参考/nacos/conf/application.properties.example
docker 启动 Nacos 容器语句:
docker run --env MODE=standalone --name nacos \
-v /mydata/nacos/conf:/home/nacos/conf -d -p 8848:8848 nacos/nacos-server:2.1.1
1、创建pvc
tmeshmall-nacos-pvc
1Gi
2、创建有状态服务
- 名称:nacos
- 镜像:nacos/nacos-server:2.1.1
- 使用默认端口
- 环境变量:MODE standalone【单机模式】
- 挂载 pvc
- 读写 /home/nacos/data
3、后期可以配合 nginx 对外暴露
4、改成无状态的服务的方法:【对外暴露端口】
- 删除对外暴露的 service,但是不钩中 有状态副本集,此时容器组中还存在该nacos
- 创建服务 => 自定义创建 => 指定工作负载
- 名称:tmeshmall-nacos-2
- 指定工作负载
- 选中有状态副本集,刚刚创建的 nacos-wrnw3c 容器
- 指定端口
- 协议类:HTTP 名称:http-8848 容器端口:8848 服务端口:8848
- 选中外网访问
- NodePort
5、然后看service暴露的端口:8848
192.168.56.132:8848/nacos
username:nacos
password:nacos
重点:这里无状态服务开启对外服务是 NodePod 随机端口的方式对外暴露,所以在其他 pod 节点上使用域名是访问不到的,例如在 zipkin 容器中 ping nacos.tmeshmall :失败
所以后面部署的应用服务的配置 spring.cloud.nacos.discovery.server-addr 不能直接使用 nacos.tmeshmall
问题解决:
1、创建服务 => 自定义创建 => 指定工作负载
名称:nacos-service
访问类型:Headless【以域名的方式访问】
端口
HTTP http-nacos-8848 8848 8848
不选中外网访问
2、测试
进入zipkin终端
ping nacos-service.tmeshmall
3、修改各项目配置文件中
spring.cloud.nacos.discovery.server-addr=nacos-service.tmeshmall:8848
总结:这里一个 pod 对外暴露了两个 service,一个是外网访问,一个是内部集群域名访问
k8s 搭建 zipkin【Spring Sleuth】
链路追踪可视化界面
【无状态】
docker run -d -p 9411:9411 openzipkin/zipkin:2.22
或者
【有状态】
docker run --env STORAGE_TYPE=elasticsearch --env ES_HOSTS=192.168.56.132:9200 openzipkin/zipkin:2.22
1、创建无状态服务【数据适用 es 存储】
- 名称:zipkin
- 镜像:openzipkin/zipkin:2.22
- 环境变量:
- STORAGE_TYPE elasticsearch
- ES_HOSTS elasticsearch.tmeshmall:9200
- 设置外网访问
- NodePort
2、查看 service 对外暴露的端口32067
访问:192.168.56.132:32067
问题解决:
1、创建服务 => 自定义创建 => 指定工作负载
名称:zipkin-service
访问类型:Headless【以域名的方式访问】
端口
HTTP http-zipkin 9411 9411
不选中外网访问
2、测试
进入 Nacos 终端
ping zipkin-service.tmeshmall
3、修改各项目配置文件中
spring.zipkin.base-url=http://zipkin-service.tmeshmall:9411/
总结:这里一个 pod 对外暴露了两个 service,一个是外网访问,一个是内部集群域名访问
k8s 部署 dashboard【sentinel】
熔断、限流、降级
sentinel官方没有镜像,可以自己制作一个镜像并启动它,暴露访问【后面每一个业务代码我们都会制作镜像,可以参考】
docker run --name sentinel -d -p 8858:8858 -d bladex/sentinel-dashboard:1.8.6
docker run --name sentinel -d -p 8858:8858 -d bladex/sentinel-dashboard:1.6.3
1、创建无状态服务
- 名称:sentinel
- 指定端口
- 协议类:TCP 名称:tcp-8858 容器端口:8858 服务端口:8333
- 【这里应该是HTTP,但是老师是TCP,未验证】
- 外网访问
- NodePort
2、查看 service 暴露的端口
访问:192.168.56.132:31987
问题解决:
1、创建服务 => 自定义创建 => 指定工作负载
名称:sentinel-service
访问类型:Headless【以域名的方式访问】
端口
HTTP http-sentinel 8858 8333
不选中外网访问
2、测试
进入zipkin终端
ping sentinel-service.tmeshmall
3、修改各项目配置文件中
spring.cloud.sentinel.transport.dashboard=sentinel-service.tmeshmall:8333
总结:这里一个 pod 对外暴露了两个 service,一个是外网访问,一个是内部集群域名访问

 浙公网安备 33010602011771号
浙公网安备 33010602011771号