
chapter02 svm对手写体数字的数码图像进行识别
#coding=utf8 # 从sklearn.datasets里导入手写体数字加载器。 from sklearn.datasets import load_digits # 从sklearn.cross_validation中导入train_test_split用于数据分割。
#此处sklearn.cross_validation 已被弃用
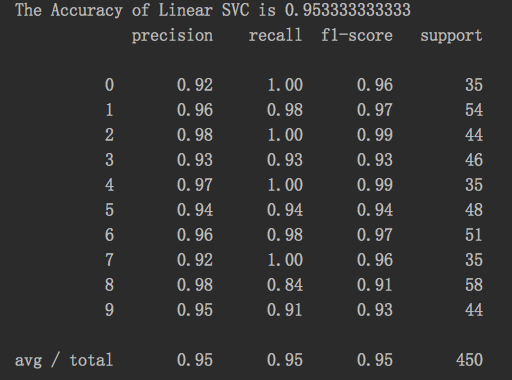
from sklearn.model_selection import train_test_split # 从sklearn.preprocessing里导入数据标准化模块。 from sklearn.preprocessing import StandardScaler # 从sklearn.svm里导入基于线性假设的支持向量机分类器LinearSVC。 from sklearn.svm import LinearSVC # 依然使用sklearn.metrics里面的classification_report模块对预测结果做更加详细的分析。 from sklearn.metrics import classification_report # 从通过数据加载器获得手写体数字的数码图像数据并储存在digits变量中。 digits = load_digits() # 随机选取75%的数据作为训练样本;其余25%的数据作为测试样本。 X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, test_size=0.25, random_state=33) # 从仍然需要对训练和测试的特征数据进行标准化。 ss = StandardScaler() X_train = ss.fit_transform(X_train) X_test = ss.transform(X_test) # 初始化线性假设的支持向量机分类器LinearSVC。 lsvc = LinearSVC() #进行模型训练 lsvc.fit(X_train, y_train) # 利用训练好的模型对测试样本的数字类别进行预测,预测结果储存在变量y_predict中。 y_predict = lsvc.predict(X_test) # 使用模型自带的评估函数进行准确性测评。 print 'The Accuracy of Linear SVC is', lsvc.score(X_test, y_test) print classification_report(y_test, y_predict, target_names=digits.target_names.astype(str))
结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号