排序指标 --- 1、平均准确率均值 (Mean Average Precision-MAP) & 2、NDCG (normalized discounted CG-cumulative gain,累计增益)
NDCG(归一化折扣累积增益)和MAP(平均精度均值)两个评估指标的详细解释,结合它们在信息检索、推荐系统及RAG(检索增强生成)系统中的应用场景、计算方法和核心差异:
一、NDCG(Normalized Discounted Cumulative Gain)
1. 定义与核心思想
NDCG是一种衡量排序质量的指标,特别关注排名列表中相关项目的位置和相关性等级。其核心思想是:排名靠前的相关项目对用户的价值更高,因此需对高排名位置的相关性赋予更大权重,并通过归一化处理消除不同长度结果集的偏差。
2. 计算方法
-
![]()
-
DCG(折扣累积增益):计算前k个结果的累积增益,并对位置进行对数折扣。其中,reli表示位置i的相关性评分(如二元评分0/1或多级评分1-5)
![]()
-
IDCG(理想DCG):对同一查询的理想排序(相关项全部靠前)计算DCG值
-
![]()
NDCG:将实际DCG与理想DCG的比值作为最终结果:范围:0(最差)到1(完美排序)
-
![]()
特点与适用场景
- 优势: 处理多级相关性评分(如推荐系统中的“相关”“部分相关”“不相关”)
- 归一化特性便于不同长度结果集的横向比较。
- 局限性:
- 依赖人工标注的相关性数据,数据质量要求高
- 对部分反馈敏感,需数据清洗
- 典型场景:搜索引擎结果排序、推荐列表质量评估、RAG系统的检索组件优化

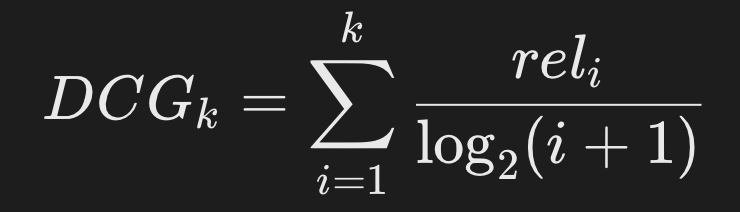

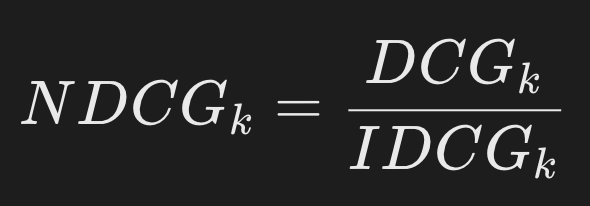


 浙公网安备 33010602011771号
浙公网安备 33010602011771号