【Python3爬虫】微博用户爬虫
此次爬虫要实现的是爬取某个微博用户的关注和粉丝的用户公开基本信息,包括用户昵称、id、性别、所在地和其粉丝数量,然后将爬取下来的数据保存在MongoDB数据库中,最后再生成几个图表来简单分析一下我们得到的数据。
一、具体步骤:
这里我们选取的爬取站点是https://m.weibo.cn,此站点是微博移动端的站点,我们可以直接查看某个用户的微博,比如https://m.weibo.cn/profile/5720474518。
然后查看其关注的用户,打开开发者工具,切换到XHR过滤器,一直下拉列表,就会看到有很多的Ajax请求。这些请求的类型是Get类型,返回结果是Json格式,展开之后就能看到有很多用户的信息。
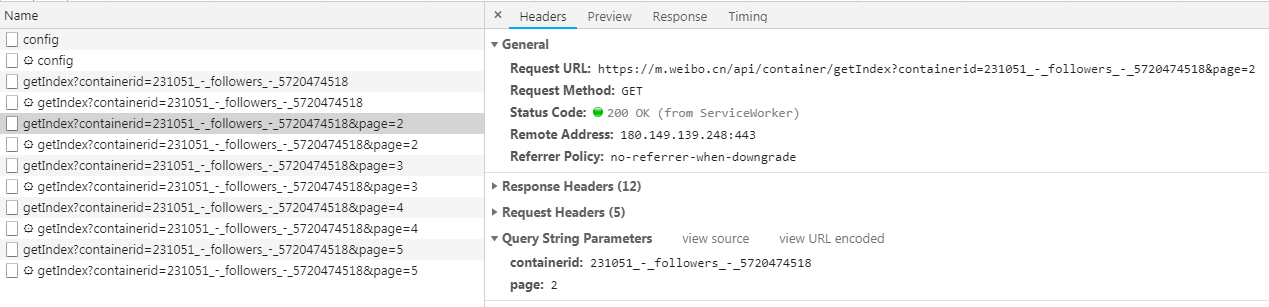
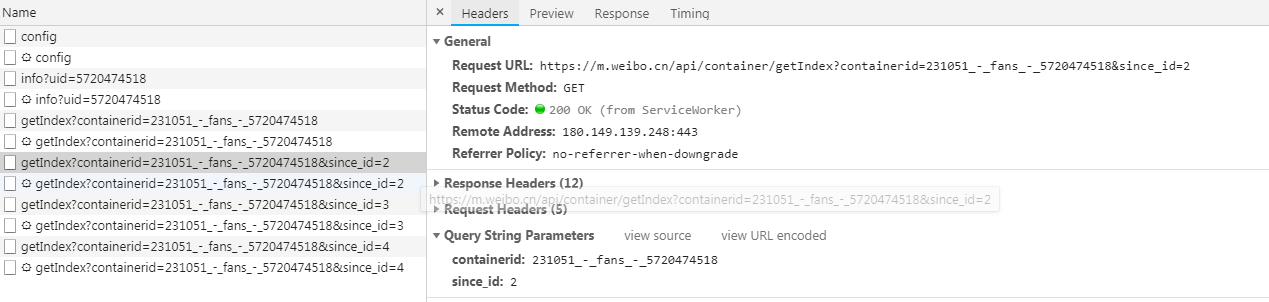
这些请求有两个参数,containerid和page,通过改变page的数值,我们就能得到更多的请求了。获取其粉丝的用户信息的步骤是一样的,除了请求的链接不同之外,参数也不同,修改一下就可以了。
由于这些请求返回的结果里只有用户的名称和id等信息,并没有包含用户的性别等基本资料,所以我们点进某个人的微博,然后查看其基本资料,比如这个,打开开发者工具,可以找到下面这个请求:
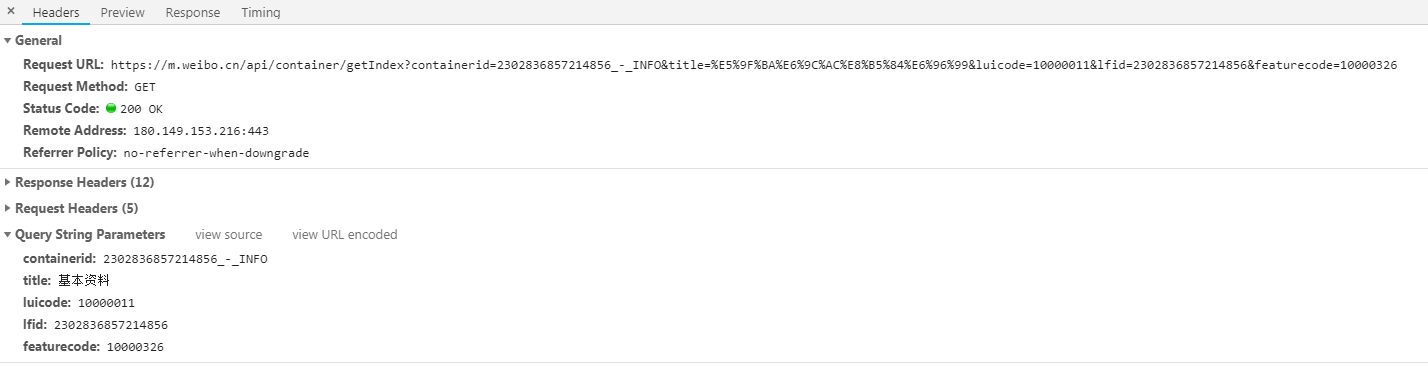
由于这个人的id是6857214856,因此我们可以发现当我们得到一个人的id的时候,就可以构造获取基本资料的链接和参数了,相关代码如下(uid就是用户的id):
1 uid_str = "230283" + str(uid) 2 url = "https://m.weibo.cn/api/container/getIndex?containerid={}_-_INFO&title=%E5%9F%BA%E6%9C%AC%E8%B5%84%E6%96%99&luicode=10000011&lfid={}&featurecode=10000326".format(uid_str, uid_str) 3 data = { 4 "containerid": "{}_-_INFO".format(uid_str), 5 "title": "基本资料", 6 "luicode": 10000011, 7 "lfid": int(uid_str), 8 "featurecode": 10000326 9 }
然后这个返回的结果也是Json格式,提取起来就很方便,因为很多人的基本资料都不怎么全,所以我提取了用户昵称、性别、所在地和其粉丝数量。而且因为一些账号并非个人账号,就没有性别信息,对于这些账号,我选择将其性别设置为男性。不过在爬取的时候,我发现一个问题,就是当页数超过250的时候,返回的结果就已经没有内容了,也就是说这个方法最多只能爬250页。对于爬取下来的用户信息,全都保存在MongoDB数据库中,然后在爬取结束之后,读取这些信息并绘制了几个图表,分别绘制了男女比例扇形图、用户所在地分布图和用户的粉丝数量柱状图。
二、主要代码:
由于第一页返回的结果和其他页返回的结果格式是不同的,所以要分别进行解析,而且因为部分结果的json格式不同,所以可能报错,因此采用了try...except...把出错原因打印出来。
爬取第一页并解析的代码如下:
1 def get_and_parse1(url): 2 res = requests.get(url) 3 cards = res.json()['data']['cards'] 4 info_list = [] 5 try: 6 for i in cards: 7 if "title" not in i: 8 for j in i['card_group'][1]['users']: 9 user_name = j['screen_name'] # 用户名 10 user_id = j['id'] # 用户id 11 fans_count = j['followers_count'] # 粉丝数量 12 sex, add = get_user_info(user_id) 13 info = { 14 "用户名": user_name, 15 "性别": sex, 16 "所在地": add, 17 "粉丝数": fans_count, 18 } 19 info_list.append(info) 20 else: 21 for j in i['card_group']: 22 user_name = j['user']['screen_name'] # 用户名 23 user_id = j['user']['id'] # 用户id 24 fans_count = j['user']['followers_count'] # 粉丝数量 25 sex, add = get_user_info(user_id) 26 info = { 27 "用户名": user_name, 28 "性别": sex, 29 "所在地": add, 30 "粉丝数": fans_count, 31 } 32 info_list.append(info) 33 if "followers" in url: 34 print("第1页关注信息爬取完毕...") 35 else: 36 print("第1页粉丝信息爬取完毕...") 37 save_info(info_list) 38 except Exception as e: 39 print(e)
爬取其他页并解析的代码如下:
1 def get_and_parse2(url, data): 2 res = requests.get(url, headers=get_random_ua(), data=data) 3 sleep(3) 4 info_list = [] 5 try: 6 if 'cards' in res.json()['data']: 7 card_group = res.json()['data']['cards'][0]['card_group'] 8 else: 9 card_group = res.json()['data']['cardlistInfo']['cards'][0]['card_group'] 10 for card in card_group: 11 user_name = card['user']['screen_name'] # 用户名 12 user_id = card['user']['id'] # 用户id 13 fans_count = card['user']['followers_count'] # 粉丝数量 14 sex, add = get_user_info(user_id) 15 info = { 16 "用户名": user_name, 17 "性别": sex, 18 "所在地": add, 19 "粉丝数": fans_count, 20 } 21 info_list.append(info) 22 if "page" in data: 23 print("第{}页关注信息爬取完毕...".format(data['page'])) 24 else: 25 print("第{}页粉丝信息爬取完毕...".format(data['since_id'])) 26 save_info(info_list) 27 except Exception as e: 28 print(e)
三、运行结果:
在运行的时候可能会出现各种各样的错误,有的时候返回结果为空,有的时候解析出错,不过还是能成功爬取大部分数据的,这里就放一下最后生成的三张图片吧。
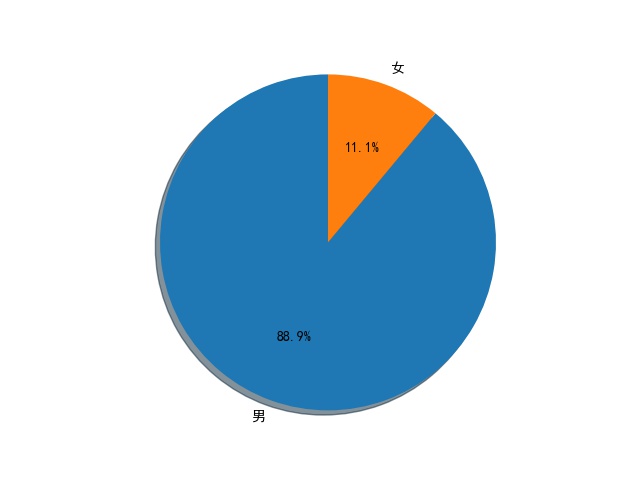
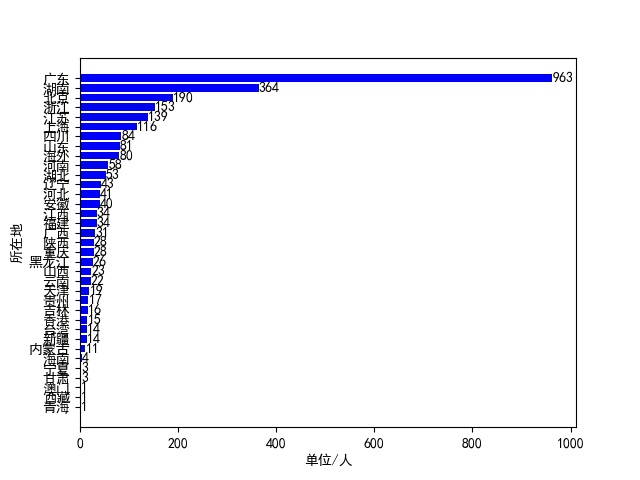

完整代码已上传到GitHub!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号