Kafka 入门(一)--安装配置和 kafka-python 调用
一、Kafka 简介
1.基本概念
Kafka 是一个分布式的基于发布/订阅消息系统,主要应用于大数据实时处理领域,其官网是:http://kafka.apache.org/。Kafka 是一个分布式、支持分区的(Partition)、多副本的(Replica),基于 ZooKeeper 协调的发布/订阅消息系统。
Kafka 有以下三个基本概念:
- Kafka 作为一个集群运行在一个或多个服务器上;
- Kafka 集群存储的消息是以 Topic 为类别记录的;
- 每个消息是由一个 Key,一个 Value 和时间戳构成。
2.基本架构
Kafka 的基本架构图如下:
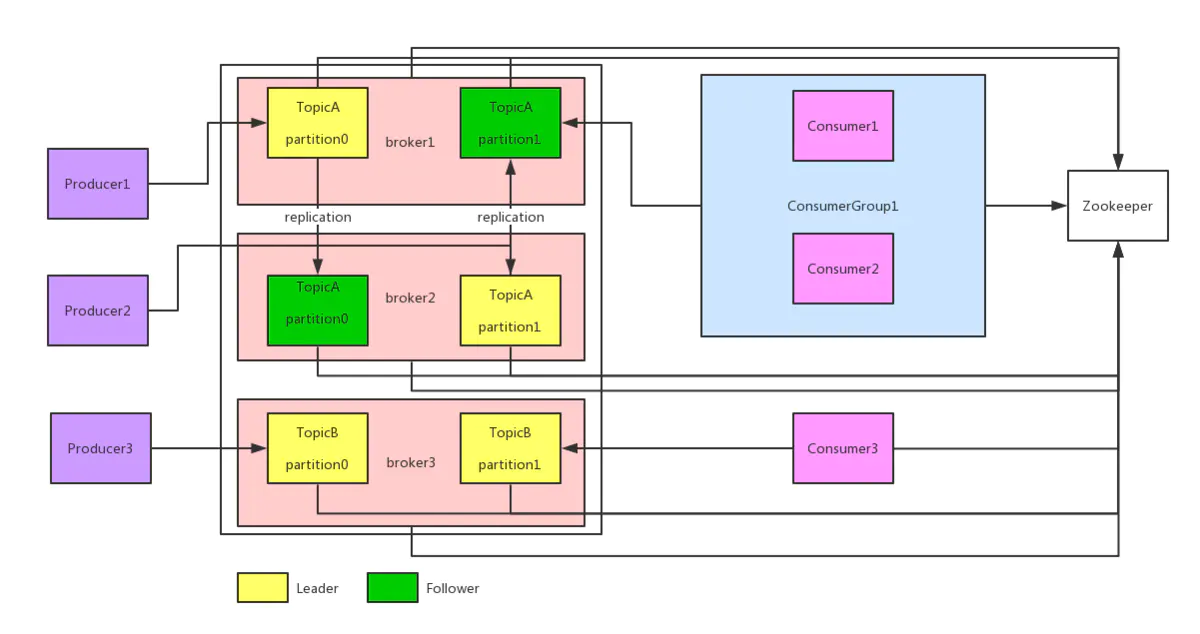
- Producer:生产者,就是向 Broker 发消息的客户端;
- Consumer:消费者,就是从 Broker 取消息的客户端;
- Consumer Group:消费者组,由多个消费者组成。组内每个消费者负责消费不同分区的数据,一个分区的数据只能由一个组内的消费者进行消费,组内消费者之间互不影响;
- Broker:一个 Kafka 服务器就是一个 Broker,一个集群由多个 Broker 组成;
- Topic:主题,可以理解为队列,生成者和消费者都是用的同一个队列;
- Partition:分区,为实现扩展性,一个大的 Topic 可以分散到多个 Broker 上,一个 Topic 可以分为多个 Partition;
- Replica:副本,保证集群中某个节点发生故障时,该节点上的数据不丢失。
二、Ubuntu 下安装 Kafka
1.安装 Java
更新软件包
sudo apt-get update
安装 openjdk-8-jdk
sudo apt-get install openjdk-8-jdk
查看 Java 版本,检查是否安装成功

2.安装 ZooKeeper
1)安装
下载 ZooKeeper:http://mirrors.hust.edu.cn/apache/zookeeper/。
下载好之后解压(注意:3.5.5之后的版本应该下载文件名中带“bin”的压缩包),再执行如下命令:
sudo mv apache-zookeeper-3.5.8-bin /usr/local/zookeeper
cd /usr/local/zookeeper
cp conf/zoo_sample.cfg conf/zoo.cfg
其中有一些配置参数:
- tickTime:Zookeeper 使用的基本时间单元,默认值2000;
- initLimit:Zookeeper 中连接同步的最大时间,默认值为10;
- syncLimit:Zookeeper 中进行心跳检测的最大时间,默认值为5;
- dataDir:数据库更新事物保存的目录;
- clientPort:Zookeeper 服务监听的端口,默认值为2181。
2)配置
修改 /etc/profile 文件,增加如下内容:
export ZOOKEEPER_HOME=/usr/local/zookeeper/
export PATH=$PATH:$ZOOKEEPER_HOME/bin
更新环境变量
source /etc/profile
3)测试
首先进入 bin 目录,开启服务:

再启动 CLI 连接服务:

3.安装 Kafka
1)安装
下载 Kafka:http://kafka.apache.org/downloads。

下载好之后解压,再执行如下命令:
sudo mv kafka_2.13-2.5.0/ /usr/local/kafka
cd /usr/local/kafka
2)测试
由于前面已经启动了 Zookeeper 服务,所以这里只需要执行如下命令来开启 Kafka 服务:
bin/kafka-server-start.sh config/server.properties
通过输出信息可以看到 Kafka 服务已经成功开启了,截图如下:

但这样开启之后是阻塞的了,我们可以在中间加一个“-daemon”即开一个守护进程来运行,则命令如下:
bin/kafka-server-start.sh -daemon config/server.properties
创建一个主题,用一个分区和一个副本创建一个名为“mytopic”的主题:
bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic mytopic
![]()
这样就已经创建成功了,然后可以使用如下命令查看主题:
bin/kafka-topics.sh --list --zookeeper 127.0.0.1:2181
Kafka 有一个命令行服务端,它将从文件或标准输入中获取输入,并将其作为消息发送到 Kafka 集群。默认情况下,每行将作为单独的消息发送:
bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic mytopic

同样的,Kafka 还有一个命令行客户端,可以从 Kafka 集群中获取消息:
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic mytopic --from-beginning

三、kafka-python 使用
1.安装 kafka-python
pip3 install kafka-python
2.创建 Consumer
Consumer 消费者负责从 Kafka 中获取消息进行处理,需要实例化 KafkaConsumer 这个类。
1 from kafka import KafkaConsumer 2 3 4 consumer = KafkaConsumer("test", bootstrap_servers=["localhost:9092"]) 5 for msg in consumer: 6 print(msg)
3.创建 Producer
Producer 生产者负责向 Kafka 生产和发送消息,需要实例化 KafkaProducer 这个类。
1 from kafka import KafkaProducer 2 3 4 producer = KafkaProducer(bootstrap_servers="localhost:9092") 5 for i in range(10): 6 producer.send("test", "Hello {}".format(i).encode("utf-8")) 7 producer.close()
4.运行测试
先运行消费者程序,再运行生产者程序,消费者一直在监听,等到生产者发送消息,消费者就把消息取出,运行结果如下:
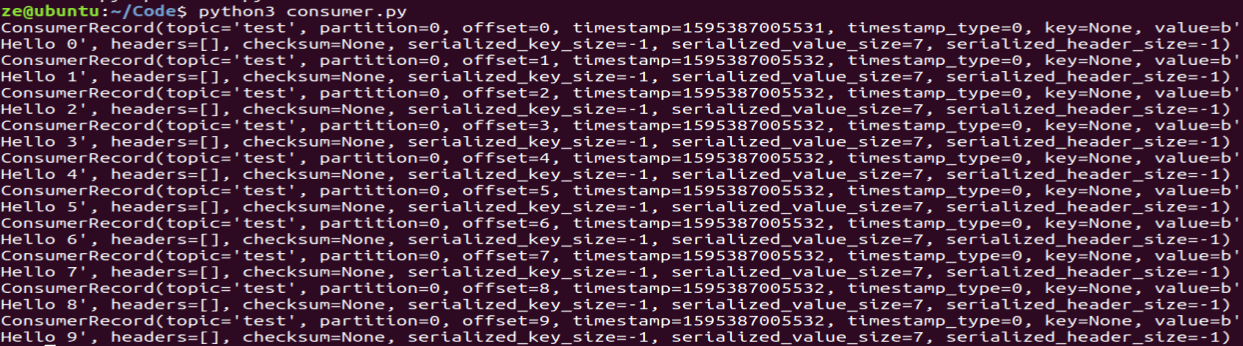
可以看到其中每个消息都包含了主题、分区、消息内容、时间戳等信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号