【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验
一、写在前面
之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验。所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对IP的检测。本文介绍的是利用Redis数据库实现的分布式爬虫,Redis是一种常用的菲关系型数据库,常用数据类型包括String、Hash、Set、List和Sorted Set,重要的是Redis支持主从复制,主机能将数据同步到从机,也就能够实现读写分离。因此我们可以利用Redis的特性,借助requests模块发送请求,再解析网页和提取数据,实现一个简单的分布式爬虫。
二、基本环境
Python版本:Python3
Redis版本:5.0
IDE: Pycharm
三、环境配置
由于Windows下的安装配置比较简单,所以这里只说Linux环境下安装和配置Redis(以Ubuntu为例)。
1.安装Redis
1)apt安装:
$ sudo apt-get install redis-server
2)编译安装:
$ wget http://download.redis.io/releases/redis-5.0.0.tar.gz
$ tar -xzvf redis-5.0.0.tar.gz
$ cd redis-5.0.0
$ make
$ make install
2.配置Redis
首先找到redis.conf文件,然后输入命令sudo vi redis.conf,进行如下操作:
注释掉bind 127.0.0.1 # 为了远程连接,这一步还可以将bind 127.0.0.1改为bind 0.0.0.0
protected-mode yes 改为 protected-mode no
daemonized no 改为 daemonized yes
如果6379端口被占用,还需要改一下端口号。除此之外,要远程连接还需要关闭防火墙。
chkconfig firewalld off # 关闭防火墙
systemctl status firewalld # 检查防火墙状态
3.远程连接Redis
使用的命令为redis-cli -h <IP地址> -p <端口号>
注:Windows查看IP地址用ipconfig,Linux查看IP地址用ifconfig。
四、基本思路
这次我爬取的网站为:http://www.shu800.com/,在这个网站的首页里有五大分类,分别是性感美女、清纯可爱、明星模特、动漫美女和丝袜美腿,所以要做的第一件事就是获取这几个分类的URL。然后,对每个分类下的网页进行爬取,通过查看网页元素可以发现如下信息:

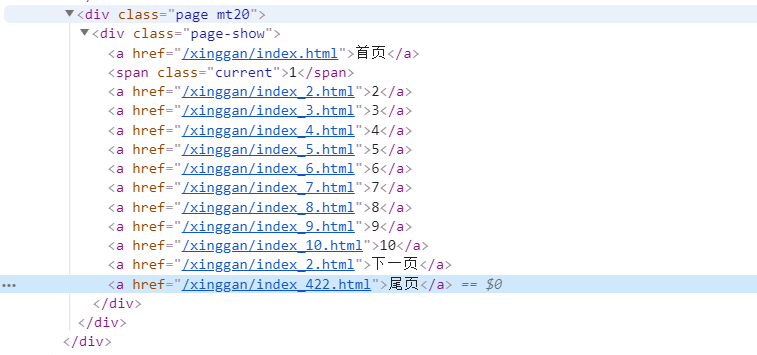
可以很明显地看到每一页的URL都是符合一定规律的,只要获取到了尾页的URL,将其中的页数提取出来,也就能构造每一页的URL了,这就比每次去获取下一页的URL简单多了。而对于每一个图集下的图片,也是用同样的方法得到每一页图片的URL。最后要做的就是从图片网页中将图片的URL提取出来,然后下载保存到本地。
这次分布式爬虫我使用了两台电脑,一台作为主机master,另一台作为从机slave。主机开启Redis服务,爬取每一页图片的URL,并将爬取到的URL保存到Redis的集合中,从机远程连接主机的Redis,监听Redis中是否有URL,如果有URL则提取出来进行下载图片,直至所有URL都被提取和下载。
五、主要代码
1.第一段代码是爬取每个页面里的美女图集的URL,并且把这些URL保存到数据库中,这里使用的是Redis中的集合,通过使用集合能够达到URL去重的目的,代码如下:
1 def get_page(url):
2 """
3 爬取每个页面下的美女图集的URL
4 :param url: 页面URL
5 :return:
6 """
7 try:
8 r = Redis(host="localhost", port=6379, db=1) # 连接Redis
9 time.sleep(random.random())
10 res = requests.get(url, headers=headers)
11 res.encoding = "utf-8"
12 et = etree.HTML(res.text)
13 href_list = et.xpath('/html/body/div[5]/div[1]/div[1]/div[2]/ul/li/a/@href')
14 for href in href_list:
15 href = "http://www.shu800.com" + href
16 r.sadd("href", href) # 保存到数据库中
17 except requests.exceptions:
18 headers["User-Agent"] = ua.random
19 get_page(url)
2.第二段代码是从机监听Redis中是否有URL的代码,如果没有URL,等待五秒钟再运行,因为如果不稍作等待就直接运行,很容易超过Python的递归深度,所以我设置了一个等待五秒钟再运行。反之,如果有URL被添加到Redis中,就要将URL提取出来进行爬取,使用的方法是redis模块里的spop()方法,该方法会从Redis的集合中返回一个元素。需要注意的是,URL被提取出来后要先转成str。
1 def get_urls():
2 """
3 监听Redis中是否有URL,如果没有就一直运行,如果有就提取出来进行爬取
4 :return:
5 """
6 if b"href" in r.keys():
7 while True:
8 try:
9 url = r.spop("href")
10 url = url.decode("utf-8") # unicode转str
11 print("Crawling URL: ", url)
12 get_image(url)
13 get_img_page(url)
14 except:
15 if b"href" not in r.keys(): # 爬取结束,退出程序
16 break
17 else:
18 continue
19 else:
20 time.sleep(5)
21 get_urls()
六、运行结果
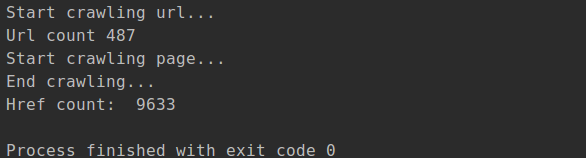
下图是在主机master上运行的截图,这里爬取到的图集总共有9633个:
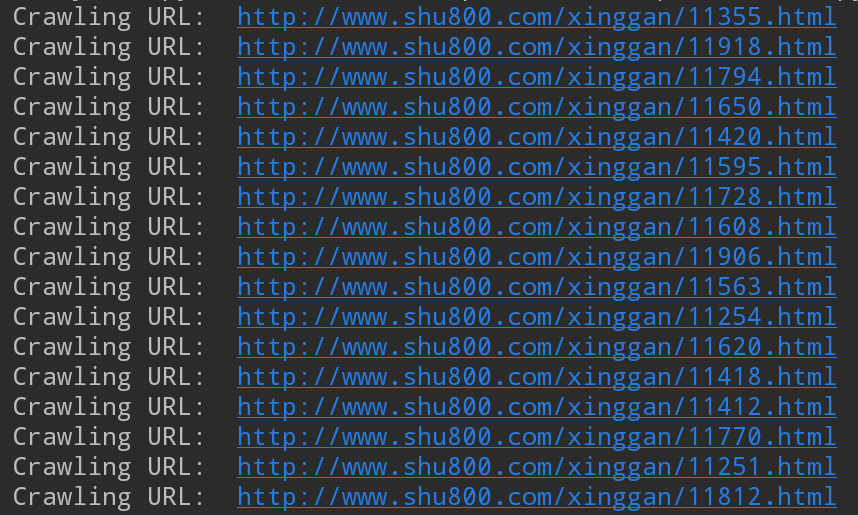
从机slave会不断地从Redis数据库中提取URL来爬取,下图是运行时的截图:
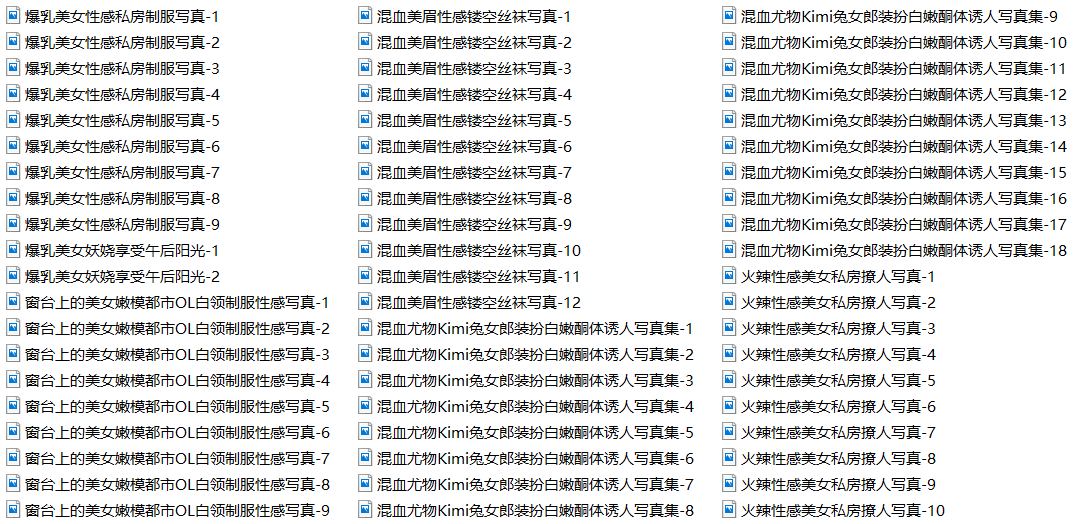
打开文件夹看看爬下来的图片都有什么(都是这种标题,有点难顶啊...):
完整代码已上传到GitHub!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号