【Python3爬虫】你会怎么评价复仇者联盟4?
一、写在前面
最近复仇者联盟4正在热映中,很多人都去电影院观看了电影,那么对于这部电影,看过的人都是怎么评价的呢?这时候爬虫就可以派上用场了!
二、主要思路
首先打开豆瓣电影,然后进入复仇者联盟4的详情页面:https://movie.douban.com/subject/26100958/,下拉页面就可以找到这部电影的短评了:
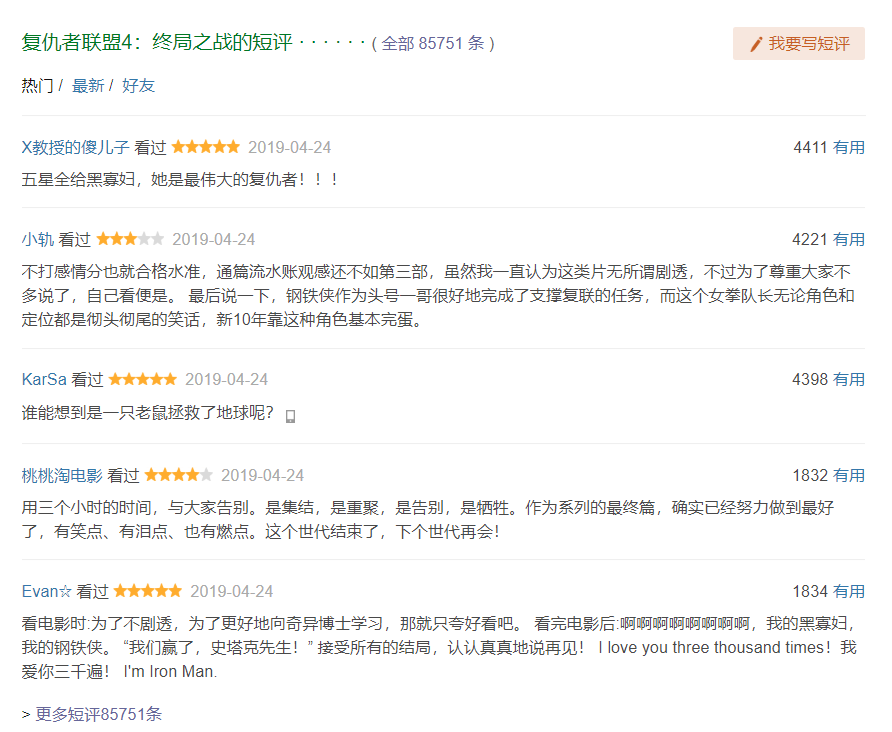
虽然它显示的短评有85751条,但是我们却没有办法获取所有的短评,在未登录的情况下只能看到200条短评,登录之后也只能得到500条短评,可是只有500条怎么够呢?所以我们得想办法得到尽量多的短评,思路为分别选择好评、一般、短评和最新,不过最新的短评只显示100条,所以我们能爬取的短评数量就是1600条。
当我们把短评爬取下来之后,可以先把短评数据保存到数据库中,然后再对这些短评进行分析。这里我选择用MongoDB数据库来保存数据,然后使用SnowNLP进行情感分析,再使用jieba分词和wordcloud生成词云。
三、主要代码
1.模拟登录
这一步是很重要的,我们需要带着登录之后的Cookie去发送请求才能得到数据,当然也可以打开浏览器登录之后复制Cookie,具体怎么做看个人喜好。登录豆瓣的url为:https://accounts.douban.com/passport/login?,抓一下包就知道怎么模拟登录了,并没有什么难度。代码如下:
1 def login(self): 2 """ 3 模拟登录 4 :return: 5 """ 6 url = "https://accounts.douban.com/j/mobile/login/basic" 7 data = { 8 "ck": "", 9 "name": self.username, 10 "password": self.password, 11 "remember": "false", 12 "ticket": "" 13 } 14 res = self.session.post(url, headers=self.headers, data=data) 15 print("登录成功!欢迎用户:", res.json()["payload"]["account_info"]["name"])
2.情感分析
SnowNLP是python中用来处理文本内容的,可以用来分词、标注、文本情感分析等,情感分析是简单的将文本分为两类,积极和消极,返回值为情绪的概率,越接近1为积极,接近0为消极。代码如下:
1 def analyze(self): 2 """ 3 情感分析 4 :return: 5 """ 6 result = self.col.find() 7 comments = [] 8 for i in result: 9 comments.append(i["评论"]) 10 sentiments_list = [] 11 for i in comments: 12 s = SnowNLP(i) 13 sentiments_list.append(s.sentiments) 14 plt.hist(sentiments_list, bins=np.arange(0, 1, 0.01), facecolor="g") 15 plt.xlabel('Sentiments Probability') 16 plt.ylabel('Quantity') 17 plt.title('Analysis of Sentiments') 18 plt.savefig("Sentiments.png") 19 print("情感分析完毕,生成图片Sentiments.png")
3.生成词云
首先要用jieba对评论进行分词,然后我们要设置一些停用词,比如标点符号、“你”、“我”、“一部”、“电影”等词语,最后使用wordcloud模块生成词云图片。代码如下:
1 def generate(self): 2 """ 3 生成词云 4 :return: 5 """ 6 result = self.col.find() 7 comments = [] 8 for i in result: 9 comments.append(i["评论"]) 10 text = jieba.cut("\n".join(comments)) 11 12 # 文本清洗,去除标点符号和长度为1的词 13 with open("stopwords.txt", "r", encoding='utf-8') as f: 14 stopwords = set(f.read().split("\n")) 15 stopwords.update({"一部", "一场", "电影", "小时", "分钟"}) 16 # 使用图片 17 mask = np.array(Image.open("Avengers.jpg")) 18 19 # 生成词云 20 wc = WordCloud( 21 mask=mask, 22 stopwords=stopwords, 23 font_path="font.ttf", 24 max_font_size=200, 25 min_font_size=20, 26 max_words=100, 27 width=1200, 28 height=800 29 ) 30 wc.generate(' '.join(text)) 31 wc.to_file('Avengers.png') 32 print("词云已生成,保存为Avengers.png。")
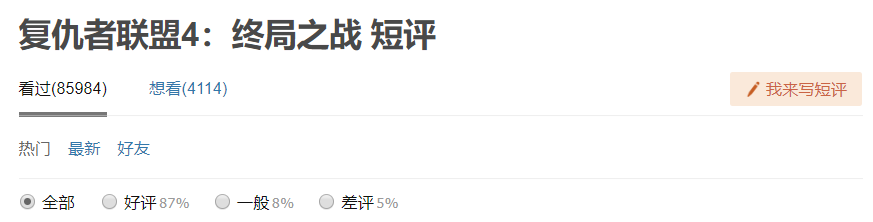
四、运行结果
首先是进入MongoDB数据库查看数据:
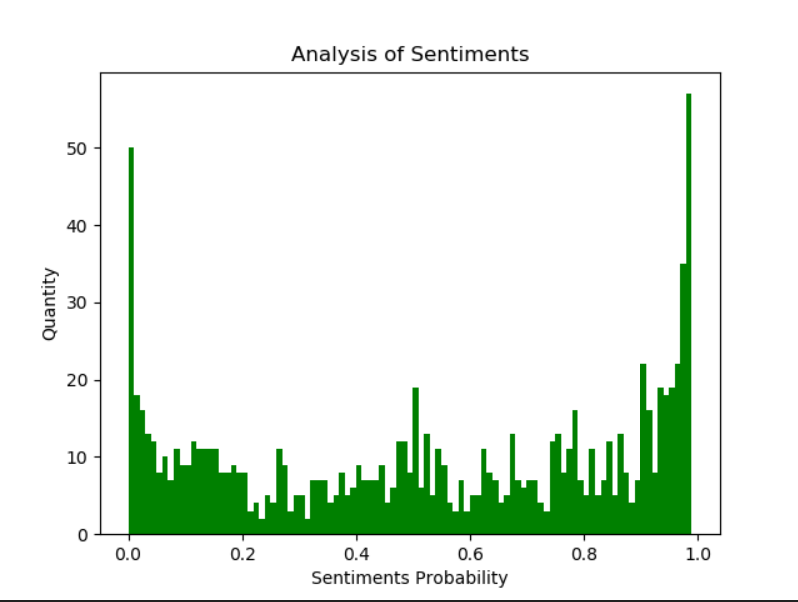
然后是使用SnowNLP进行情感分析得到的结果,可见很多人都是很喜欢复仇者联盟4的:
最后是生成的词云:

那么,对于看了电影的你,你会怎么评价这部电影呢?如果你没有看过,会不会想要买一张电影票去看看呢?
完整代码已上传到GitHub!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号