【Python3爬虫】使用异步协程编写爬虫
一、基本概念
进程:进程是一个具有独立功能的程序关于某个数据集合的一次运行活动。进程是操作系统动态执行的基本单元。
线程:一个进程中包含若干线程,当然至少有一个线程,线程可以利用进程所拥有的资源。线程是独立运行和独立调度的基本单元。
协程:协程是一种用户态的轻量级线程。协程无需线程上下文切换的开销,也无需原子操作锁定及同步的开销。
同步:不同程序单元为了完成某个任务,在执行过程中需靠某种通信方式以协调一致,称这些程序单元是同步执行的。
异步:为完成某个任务,不同程序单元之间过程中无需通信协调,也能完成任务的方式,不相关的程序单元之间可以是异步的。
多进程:多进程就是利用 CPU 的多核优势,在同一时间并行地执行多个任务。多进程模式优点就是稳定性高,因为一个子进程崩溃了,不会影响主进程和其他子进程,但是操作系统能同时运行的进程数是有限的。
多线程:多线程模式通常比多进程快一点,但是也快不到哪去,而且,多线程模式致命的缺点就是任何一个线程挂掉都可能直接造成整个进程崩溃,因为所有线程共享进程的内存。
二、异步协程
Python 中使用协程最常用的库莫过于 asyncio,然后我们还需要了解一些概念:
event_loop:事件循环,相当于一个无限循环,我们可以把一些函数注册到这个事件循环上,当满足条件发生的时候,就会调用对应的处理方法。
coroutine:协程对象类型,我们可以将协程对象注册到事件循环中,它会被事件循环调用。我们可以使用 async 关键字来定义一个方法,这个方法在调用时不会立即被执行,而是返回一个协程对象。
task:任务,它是对协程对象的进一步封装,包含了任务的各个状态,比如 running、finished 等。
另外我们还需要了解两个关键字:async(定义一个协程),await(用来挂起阻塞方法的执行)。下面是一个示例:
1 import asyncio 2 3 4 async def show(num): 5 print("Number is {}".format(num)) 6 7 8 cor = show(1) 9 print("Coroutine: ", cor) 10 print("After execute...") 11 task = asyncio.ensure_future(cor) 12 print("Task: ", task) 13 loop = asyncio.get_event_loop() 14 loop.run_until_complete(cor) 15 print("Task: ", task) 16 print("After loop...")
运行结果如下:
Coroutine: <coroutine object show at 0x0000000012ED91A8>
After execute...
Task: <Task pending coro=<show() running at E:/Python/1.py:4>>
Number is 1
Task: <Task finished coro=<show() done, defined at E:/Python/1.py:4> result=None>
After loop...
这里首先使用async定义了一个show方法,传入一个数字然后打印出来,我们调用了这个方法,但是这个方法并没有执行,而是返回了一个Coroutine协程对象。然后我们使用了asyncio的ensure_future()方法,该方法会返回一个task对象,此时task的状态是pending。然后我们使用 get_event_loop() 方法创建了一个事件循环 loop,并调用了run_until_complete() 方法将协程注册到事件循环loop中,然后启动。最后我们才看到了show() 方法打印了输出结果,此时task的状态已经是finished了。
再来看一个例子:
1 import time
2 import asyncio
3
4
5 async def show(num):
6 print("Number is {}".format(num))
7 await asyncio.sleep(1) # 必须加await实现协程 这里asyncio.sleep(1)是一个子协程
8 # time.sleep(1) # time.sleep()不能与await搭配使用
9
10
11 start = time.time()
12 tasks = [asyncio.ensure_future(show(i)) for i in [1, 2, 3, 4, 5]]
13
14 loop = asyncio.get_event_loop()
15 loop.run_until_complete(asyncio.wait(tasks))
16 end = time.time()
17 print("Cost time: ", end - start)
这里我们有多个任务组成了一个列表tasks,然后我们将tasks添加到事件循环中,等到执行完毕了打印出所花费的时间。当我们使用await asyncio.sleep(1)的时候,结果如下:
Number is 1
Number is 2
Number is 3
Number is 4
Number is 5
Cost time: 1.0040574073791504
使用time,sleep(1)的时候结果如下:
Number is 1
Number is 2
Number is 3
Number is 4
Number is 5
Cost time: 5.001286029815674
结果很明显了,前者所花费的时间更少,原因在于await会将asyncio.sleep(1)这个协程暂时挂起阻塞,第一个任务(show(1))运行到这里的时候就会挂起,然后执行下一个任务(show(2)),以此类推,等到所有的任务都执行完毕,再执行asyncio.sleep(1),所以最后花费的时间就是一秒多一点了。
三、编写爬虫
1、aiohttp
要利用协程来写网络爬虫,还需要使用一个第三方库--aiohttp,aiohttp是一个支持异步请求的库,利用它和 asyncio配合我们可以非常方便地实现异步请求操作。没有安装的可以使用pip install aiohttp进行安装,其官方文档的链接是:https://aiohttp.readthedocs.io/en/stable/,需要注意的是aiohttp支持的python版本是3.5.3+,如果运行出错的话建议先检查下你的python版本。先来看看官网上给出的例子吧:
1 import aiohttp 2 import asyncio 3 4 async def fetch(session, url): 5 async with session.get(url) as response: 6 return await response.text() 7 8 async def main(): 9 async with aiohttp.ClientSession() as session: 10 html = await fetch(session, 'http://python.org') 11 print(html) 12 13 loop = asyncio.get_event_loop() 14 loop.run_until_complete(main())
首先是导入我们需要的模块,然后定义了一个fetch方法,传入的参数是一个session和一个url,然后使用session的get()方法去请求这个链接,并返回结果。在main方法中,首先引用了aiohttp里的ClientSession类,建立 了一个session对象,然后将这个session和一个链接传入到fetch方法中,最后将fetch方法返回的结果打印出来。
2、具体步骤
这次写的爬虫实现了对崔庆才的个人博客上的文章基本信息的爬取,包括标题、链接、浏览的数目、评论的数目以及喜欢的人数,最后分别将浏览数、评论数以及喜欢数排前十的文章统计出来并绘制出图表。
首先进入崔庆才个人博客,可以看到一页有二十篇文章,把页面下拉,就会出现更多的文章,显然这是动态加载的,于是我们打开开发者工具,继续下拉页面,然后在XHR选项中看到了我们需要的内容:

不停地下拉页面,会发现最后数字会定格在35,也就是说总共有35页,每页的链接都形如https://cuiqingcai.com/page/2,这样的话我们爬取的话就简单多了。基本思路是将所有链接组成一个列表,然后利用aiohttp去请求网页并返回结果,然后我们再对结果进行解析,对于解析得到的结果,保存在MongoDB数据库中。然后再对数据进行一下简单的分析,并绘制图表,结果如下:

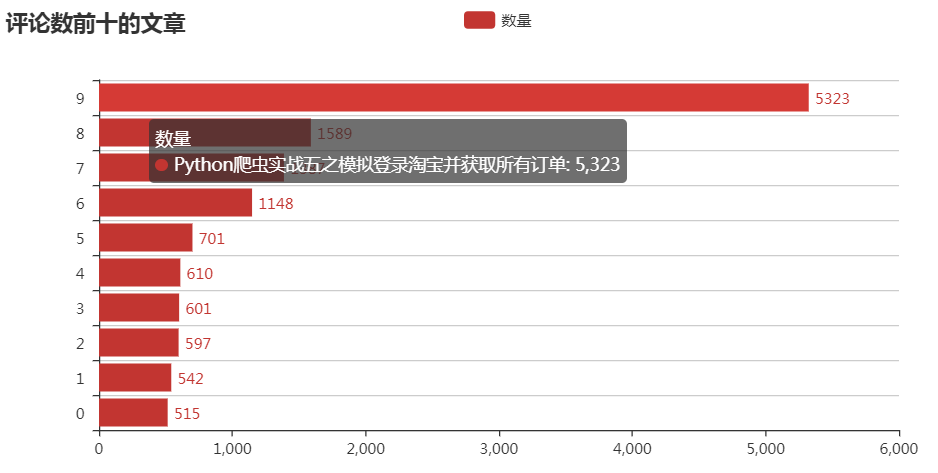
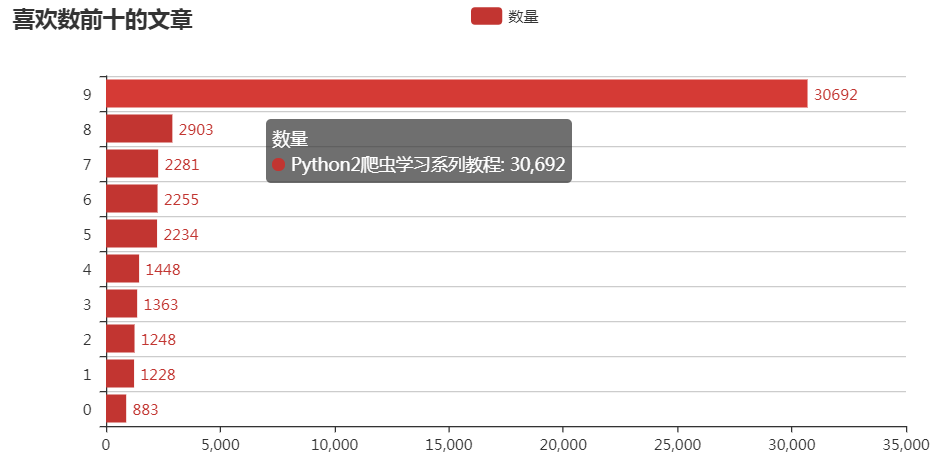
完整代码已上传到GitHub!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号