
第一次个人编程作业
https://github.com/fzu-TJT/SEwork1/tree/master
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 10 |
| Development | 开发 | 600 | 700 |
| Analysis | 需求分析 (包括学习新技术) | 200 | 300 |
| Design Spec | 生成设计文档 | 30 | 20 |
| Design Review | 设计复审 | 10 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 300 | 500 |
| Code Review | 代码复审 | 60 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | ||
| Test Repor | 测试报告 | 30 | 20 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 1395 | 1860 |
二、计算模块接口
-
(3.1)计算模块接口的设计与实现过程。
思路:
刚开始看到的时候是没有什么思路的。然后就只好靠baidu编程了。找了些资料后大体有两种比较高效的方法:第一种是DFA算法,第二种是AC自动机。我选择的是第一种方法,DFA算法。DFA算法:DFA即Deterministic Finite Automaton,也就是确定有穷自动机,它是是通过event和当前的state得到下一个state,即event+state=nextstate。我们可以将每个敏感词汇作为状态,例如“讨厌鬼”可拆分为“讨”、“讨厌”、“讨厌鬼” 三个文本片段。如果是多段关键词,则如“匹配算法”、“匹配关键词”以及“信息抽取”。如下图类似树形结构,也正是因为这个结构,使得DFA算法在关键词匹配方面要快于关键词迭代方法(for 循环)。
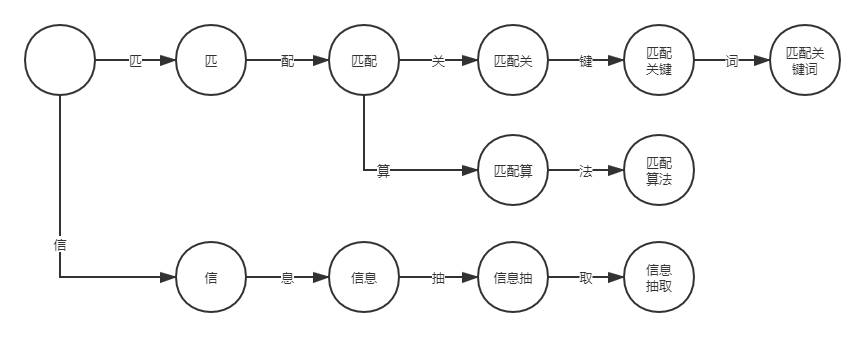
parse(树状化)::构建一个敏感词字典树
view code
def parse(self, path):
with open(path, encoding='UTF-8') as f:
for keyword in f:
keyword=keyword.replace("\n", "")
if isChinese(keyword):
pinyin_list.append(pinyin.get(keyword, format='strip', delimiter=""))
haha_pattern=""
for ch in keyword:
haha_pattern=haha_pattern+ch
haha_pattern+='.{0,20}'
re_pattern_list.append(haha_pattern[:-7])
total_list.append(keyword)
tt_word=keyword
for tt_cha in tt_word:
ttt_word=keyword
#print(pinyin.get(tt_cha, format='strip', delimiter=""))
ttt_word=ttt_word.replace(tt_cha, pinyin.get(tt_cha, format='strip', delimiter=""))
#print(ttt_word)
self.add(ttt_word)
haha_pattern=""
for ch in ttt_word:
haha_pattern=haha_pattern+ch
haha_pattern+='.{0,20}'
re_pattern_list.append(haha_pattern[:-7])
#print(haha_pattern[:-7])
total_list.append(keyword)
else:
hh_pattern=""
for ch in keyword:
hh_pattern=hh_pattern+ch
hh_pattern+='.{0,20}'
re_pattern_list.append(hh_pattern[:-7])
English_word_list.append(keyword)
total_list.append(keyword)
self.add(keyword.strip())
for temp_word in pinyin_list:
self.add(temp_word.strip())
hh_pattern=""
for ch in temp_word:
hh_pattern=hh_pattern+ch
hh_pattern+='.{0,20}'
re_pattern_list.append(hh_pattern[:-7])
total_list.append(keyword)
#print(self.keyword_chains)
filter(过滤原文):并完成答案的生成等
view code
def filter(self, message, repl="*"):
if not isinstance(message, str):
message = message.decode('utf-8')
back = message
message = message.lower()
for i in range(len(re_pattern_list)):
message=re.sub(re_pattern_list[i], total_list[i], message)
ret = []
start = 0
fd=open("anss.txt", "a")
tmp_char=""
while start < len(message):
level = self.keyword_chains
step_ins = 0
for char in message[start:]:
if char in level:
step_ins += 1
if self.delimit not in level[char]:
level = level[char]
else:
count_num = start
while(1):
if back[count_num] == message[start + step_ins]:
break
tmp_char=tmp_char+back[count_num]
count_num += 1
ret.append(repl * step_ins)
print("Line", end="")
print(index, end="")#行号 index表示第几行
print("<", end="")
print(message[start:start+step_ins], end="")#敏感词
print(">")
print(tmp_char)
# fd.write("Line")
# fd.write(str(index))
# fd.write("<")
# fd.write(message[start:start+step_ins])
# fd.write(">\n")
temp_str="Line"+str(index)+"<"+message[start:start+step_ins]+"> "+tmp_char+"\n"
tmp_char=""
#print(temp_line[start:start+step_ins])#在文中的表述
SUM_LIST.append(temp_str)
start += step_ins - 1
break
else:
ret.append(message[start])
tmp_char = ""
break
else:
ret.append(message[start])
start += 1
fd.close()
return ''.join(ret)
-
(3.2)计算模块接口部分的性能改进。
通过Spyder下载的profile工具测试得到下图
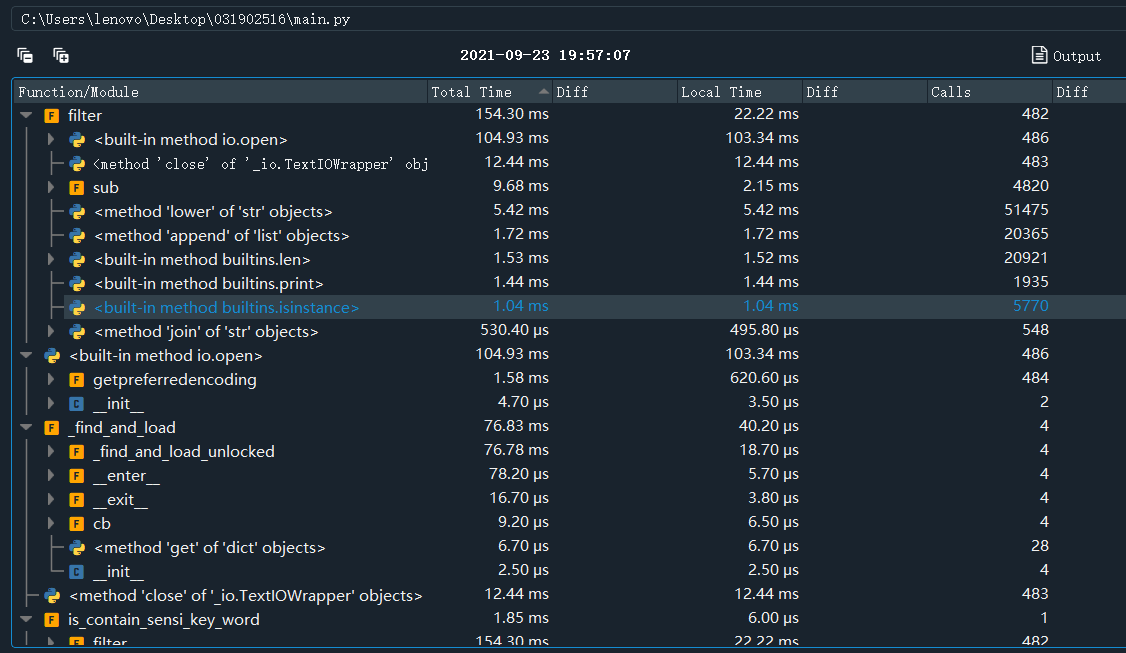
得到耗时最大的函数是DFAFilter类的filter
def filter(self, message, repl="*"):
if not isinstance(message, str):
message = message.decode('utf-8')
message = message.lower()
for i in range(len(re_pattern_list)):
message=re.sub(re_pattern_list[i], total_list[i], message)
ret = []
start = 0
fd=open("MyAnswer.txt", "a")
while start < len(message):
level = self.keyword_chains
step_ins = 0
for char in message[start:]:
if char in level:
step_ins += 1
if self.delimit not in level[char]:
level = level[char]
else:
ret.append(repl * step_ins)
print("Line", end="")
print(index, end="")#行号 index表示第几行
print("<", end="")
print(message[start:start+step_ins], end="")#敏感词
print(">")
# fd.write("Line")
# fd.write(str(index))
# fd.write("<")
# fd.write(message[start:start+step_ins])
# fd.write(">\n")
temp_str="Line"+str(index)+"<"+message[start:start+step_ins]+">\n"
#print(temp_line[start:start+step_ins])#在文中的表述
SUM_LIST.append(temp_str)
start += step_ins - 1
break
else:
ret.append(message[start])
break
else:
ret.append(message[start])
start += 1
fd.close()
return ''.join(ret)
对于改进方法的话,鉴于本人水平有限,尚在努力寻找方法,有方法一定会更新的。
-
(3.3)计算模块部分单元测试展示。
单元测试代码如下。
view code
import main
import unittest
class MyTestCase(unittest.TestCase):
def test_FilterSensitiveWords(self):
#构造数据
path = "words1.txt"
f.ReadSensitiveWords(path)
answer = []
for i in range(1,7):
sen_count,answer = f.FilterSensitiveWords(i,org[i-1],answer)
self.assertEqual(ans,answer)
if __name__ == '__main__':
unittest.main()
自己构造测试文本截图如下:
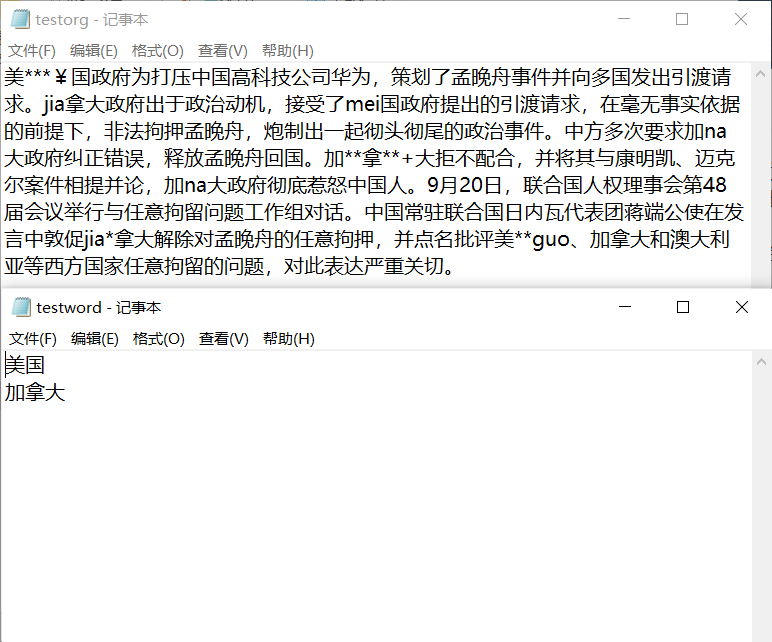
测试文本截图如下:
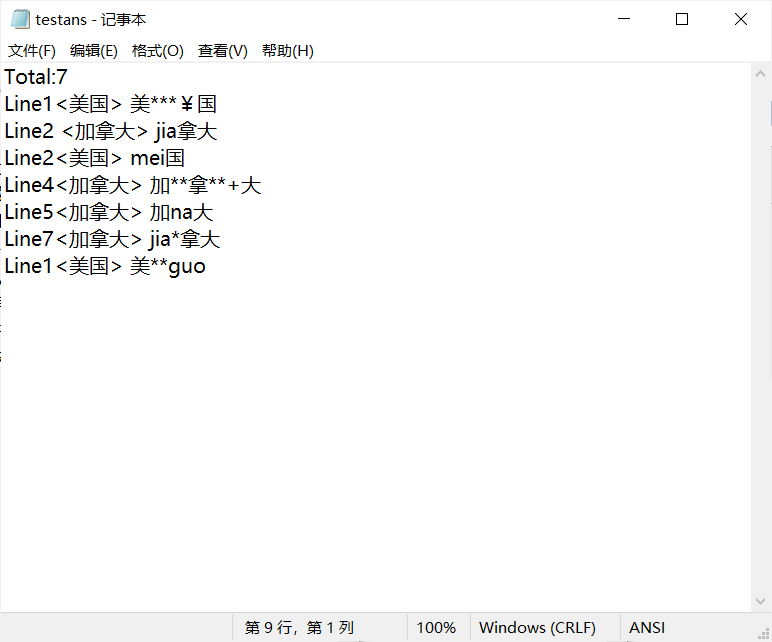
-
(3.4)计算模块部分异常处理说明。
异常处理说明目前考虑到的只有关于I/O错误的情况,具体代码如下。
if len(sys.argv) != 4:
print("I/O error")
三、心得
-
(4.1)在完成本次作业过程的心得体会
学了好多东西,刚开始的时候啥也不会,
心态炸裂。一步一步查资料,一步一步改进。重新温顾了GitHub传代码的方法,学习了dfa算法等等。本次作业我也学到了很多我以前没有用过的东西,比如性能分析、单元检测等以前没有用过的东西,但是遗憾的是还是有一点小问题没有改进,会持续改进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号