
贝叶斯定理到贝叶斯滤波器
贝叶斯定理是一种在已知其他概率的情况下求概率的方法:
首先,对于贝叶斯定理,还是要先了解各个概率所对应的事件。
P(A|B) 是在 B 发生的情况下 A 发生的概率;
P(A) 是 A 发生的概率;
P(B|A) 是在 A 发生的情况下 B 发生的概率;
P(B) 是 B 发生的概率。
贝叶斯法则的原理
根据文氏图,可以很清楚地看到在事件B发生的情况下,事件A发生的概率就是P(A∩B)除以P(B)。
因此,
同理可得,
所以,
即,
这就是条件概率的计算公式。
全概率公式
由于后面要用到,所以除了条件概率以外,这里还要推导全概率公式。
假定样本空间S,是两个事件A与A'的和。

上图中,红色部分是事件A,绿色部分是事件A',它们共同构成了样本空间S。
在这种情况下,事件B可以划分成两个部分。

即
在上一节的推导当中,我们已知
所以,
这就是全概率公式。它的含义是,如果A和A'构成样本空间的一个划分,那么事件B的概率,就等于A和A'的概率分别乘以B对这两个事件的条件概率之和。
将这个公式代入上一节的条件概率公式,就得到了条件概率的另一种写法:
病人分类的例子
让我从一个例子开始讲起,你会看到贝叶斯分类器很好懂,一点都不难。某个医院早上收了六个门诊病人,如下表。
| 症状 | 职业 | 疾病 |
| 打喷嚏 | 护士 | 感冒 |
| 打喷嚏 | 农夫 | 过敏 |
| 头疼 | 建筑工人 | 脑震荡 |
| 头疼 | 建筑工人 | 感冒 |
| 打喷嚏 | 教师 | 感冒 |
| 头疼 | 教师 | 脑震荡 |
现在又来了第七个病人,是一个打喷嚏的建筑工人。请问他患上感冒的概率有多大? 根据贝叶斯定理:
P(A|B) = P(B|A) P(A) / P(B)
可得:
P(感冒|打喷嚏x建筑工人)
= P(打喷嚏x建筑工人|感冒) x P(感冒)
/ P(打喷嚏x建筑工人)
假定"打喷嚏"和"建筑工人"这两个特征是独立的,因此,上面的等式就变成了
P(感冒|打喷嚏x建筑工人)
= P(打喷嚏|感冒) x P(建筑工人|感冒) x P(感冒)
/ P(打喷嚏) x P(建筑工人)
这是可以计算的。
P(感冒|打喷嚏x建筑工人)
= 0.66 x 0.33 x 0.5 / 0.5 x 0.33
= 0.66
因此,这个打喷嚏的建筑工人,有66%的概率是得了感冒。同理,可以计算这个病人患上过敏或脑震荡的概率。比较这几个概率,就可以知道他最可能得什么病。
这就是贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
贝叶斯滤波器
首先,BF是什么?
BF是依据机器人传感器获取的观测数据,利用Bayes公式(概率论)去估计机器人的状态的一种手段。
这里的关键点在于,BF假设了机器人当前的状态服从某一个概率分布,将机器人状态估计问题建模为一个概率分布的估计问题,从而利用概率论的数学工具来解决机器人的状态估计。
那么为什么要用BF呢?
这是因为,机器人的运动模型以及传感器的观测模型常常受到噪声干扰,而这种噪声都是随机性的。这样建模就可以有利于我们把噪声的分布、统计特性给估计出来,从而去除噪声,得到真实观测以及真实状态。
那么,BF具体是怎么对机器人状态估计问题建模的呢?
举一个例子,我做了一只小狗机器人,它身上装了GPS,可以时刻返回小狗机器人的位置。为了遥控它,我还给它装了一个遥控接收装置(根据小狗之前在的位置加上遥控量,也能算出小狗的位置)。但是,我遇到两个问题。一是,我花的钱太少了,买到GPS不太准,本来小狗应该在(5,3)的位置,但是测量的结果却是(5.1,2.8)。二是,小狗机器人接收到指令是前进1米,但是实际走的却可能是0.98米。小狗机器人的观测过程和运动过程中都存在噪声的干扰,这使得我想要知道我的小狗跑到哪里变得很困难,需要借助滤波手段来估计小狗位置。
基于这个例子,由于受到噪声污染,小狗机器人位置和GPS的观测可以被建模为概率分布,以表征其不确定性,即:
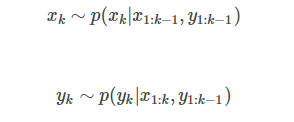
当然,上面这种建模方式是比较一般化的情况,而有些情况下(例如本例),k时刻的状态和观测未必和很久以前的状态与观测有关系,这时可以对这种建模方式进行一定简化。
简化一:状态量的马尔科夫性
假设k时刻小狗的位置只与k-1时刻的小狗的位置有关,由此:

简化二:观测量的条件独立性
假设k时刻GPS的位置的值只与k时刻小狗的位置有关,由此:
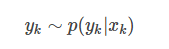
上述两个简化的含义非常直观,通常的机器人状态估计问题基本能进行这样的简化。
当然,机器人状态估计不一定只能用求解概率分布的方法。最小二乘(观测与状态误差最小)也是常用的方法,卡尔曼滤波最早实际上是从最小二乘法的基础上推导出来的。
BF基本方程
首先,我们需要明确BF的目标是什么?
估计机器人状态的概率分布。在小狗的例子中,就是通过手头信息估计出k时刻小狗位置的概率分布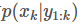 。而我们手头的信息就包括,1到k-1时刻小狗的位置
。而我们手头的信息就包括,1到k-1时刻小狗的位置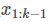 以及1到k时刻 GPS的测量值
以及1到k时刻 GPS的测量值 。
。
批处理方法
因此,我们首先想到的方法大概是:
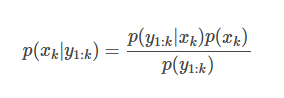
这种方法也就是所谓的批处理贝叶斯方法。但是这种方法每次都要拿所有的测量值来重新计算概率分布,对于计算机是个沉重的负担。因此,有了改进的基于递归的贝叶斯滤波方法。
递归方法
事实上,在k时刻,我们除了GPS的测量值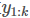 以外,
以外,
还有k-1时刻对小狗位置的估计 。(需要注意,当k=1时,由于k-1=0时刻没有观测值,小狗位置的概率分布
。(需要注意,当k=1时,由于k-1=0时刻没有观测值,小狗位置的概率分布 比较特殊,与观测无关。这个分布由人为给定,被当做小狗位置的先验分布。)
比较特殊,与观测无关。这个分布由人为给定,被当做小狗位置的先验分布。)
因此,我们根据k-1时刻的小狗位置分布和k时刻的GPS观测可以利用递归的方法得到k时刻的位置分布,这也就是BF的核心。估计k时刻小狗位置的计算过程包括两步,如下:
1-Step:预测
这一步是用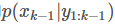 去得到
去得到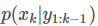 ,注意这里并没有用到k时刻的观测值。
,注意这里并没有用到k时刻的观测值。

其中, 代表了状态由k-1时刻到k时刻的转移概率,也就是上文中介绍了简化了的小狗动态模型,这里的不确定性是由小狗运动过程中的噪声引入的。
代表了状态由k-1时刻到k时刻的转移概率,也就是上文中介绍了简化了的小狗动态模型,这里的不确定性是由小狗运动过程中的噪声引入的。
这一步之所以称为预测步,可以理解为,在已知k-1时刻机器人位置的情况下,根据机器人本身运动学模型(通常是状态方程),去预测k时刻机器人的位置。![]() 在这里被作为先验分布,p(xk|y1:k−1)p(xk|y1:k−1)是由机器人运动学模型预测得到的预测分布。
在这里被作为先验分布,p(xk|y1:k−1)p(xk|y1:k−1)是由机器人运动学模型预测得到的预测分布。
2-Step:更新
这一步是用观测值ykyk去更新预测分布![]() ,从而得到k时刻机器人位置的后验分布
,从而得到k时刻机器人位置的后验分布![]() 。
。

其中,![]() 代表了依据k时刻状态
代表了依据k时刻状态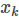 观测到
观测到 的概率,也就是小狗机器人GPS的观测模型,这里的不确定性是由GPS观测过程中的噪声引入的。
的概率,也就是小狗机器人GPS的观测模型,这里的不确定性是由GPS观测过程中的噪声引入的。
这一步之所以称为更新是因为这步中用到了k时刻的观测量,从而将原本的预测分布![]() 更新为了后验分布
更新为了后验分布![]() 。而这个后验分布,将作为估计k+1时刻小狗机器人位置的先验分布,从而开始下一轮的递归解算。
。而这个后验分布,将作为估计k+1时刻小狗机器人位置的先验分布,从而开始下一轮的递归解算。
总结
BF的整个过程可以描述为,首先选定一个最初状态的先验分布![]() ,进行预测步,得到k=1的预测分布,再用k=1的观测去更新预测分布得到k=1的后验分布,然后将这个后验分布作为先验分布,去预测k=2的预测分布,然后以此类推。。。
,进行预测步,得到k=1的预测分布,再用k=1的观测去更新预测分布得到k=1的后验分布,然后将这个后验分布作为先验分布,去预测k=2的预测分布,然后以此类推。。。
参考资料:
机器学习(10)之趣味案例理解朴素贝叶斯
https://mp.weixin.qq.com/s/s0v_afLVqtJhZyn3qHlseQ
可怕的贝叶斯:
http://dy.163.com/v2/article/detail/CU0MJOCV05118CTM.html
算法——贝叶斯:
https://www.cnblogs.com/skyme/p/3564391.html
贝叶斯滤波器:
http://blog.csdn.net/qq_30159351/article/details/53395515
机器人运动估计系列(番外篇)——从贝叶斯滤波到卡尔曼
http://blog.csdn.net/handsome_for_kill/article/details/78997533
贝叶斯相关文稿:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号